基于时空模型的视频异常检测
假设存在一个运动区域,规则要求只能进行特定的运动项目。 出于安全原因或因为业主不喜欢而禁止进行任何其他活动:)。 我们要解决的问题是:如果我们知道正确行为的列表,我们是否可以创建一个视频监控系统,在出现不常见的行为发出通知? 这无非是一个异常检测(anomaly detection)问题,即在我们生活或工作的环境中发现异常事件发生的地方,而正常情况下事情进展顺利。
解决异常检测任务的流行方法是通过无监督或半监督方法。 其原理很简单:我们通过过拟合正常发生的情况来训练模型,这通常意味着一切都会定期发生,没有或有非常罕见的异常事件。 例如,使用自编码器(autoencoder),我们能够重建原始源。 因此,查看重建误差,如果低于某个阈值,我们就观察到正常事件,否则,我们检测到异常。
NSDT工具推荐:?Three.js AI纹理开发包?-?YOLO合成数据生成器?-?GLTF/GLB在线编辑?-?3D模型格式在线转换?-?可编程3D场景编辑器?-?REVIT导出3D模型插件?-?3D模型语义搜索引擎?-?Three.js虚拟轴心开发包
这个帖子很有趣。 它旨在利用 LSTM 卷积自动编码器解决类似的问题。 一旦在非异常事件上从头开始训练模型,在推理时,它的目标是重建原始剪辑并直接在像素 (2+1) 维时空上计算重建误差。
在本文中我想描述另一种方法。 利用预训练的时空模型(space-time model)来解决动作分类任务,我提取剪辑视频的嵌入向量,并通过将其传递给自编码器,对完整模型进行微调以重建该向量。 这个想法是将重建阶段从像素(2+1)维空间转移到嵌入空间,将寻找视频帧之间所有可能的时空相关性的任务留给时空模型。
为了执行此练习,我将使用?UCF 运动动作数据集,其中总共包含 150 个分辨率为 720 x 480 的视频剪辑,分为 10 个不同的运动动作。 我将剪辑分成两组。 第一组有7个类别,包含允许的体育动作。 其余3个模拟非法异常行为,我将开发的系统必须能够识别为异常事件。
你可以在此?GitHub 存储库中找到本文的完整代码。
1、数据集属性
我已经在这篇文章中讨论了UCF数据集,其中我使用 PytorchVideo 分析了视频分类任务。
该数据集包括以下 10 个动作:跳水、高尔夫挥杆、踢腿、举重、骑马、跑步、滑板、秋千凳、侧秋千、行走。 上一篇文章详细讨论了许多预处理步骤。 这里,我只是列出了脚本?preprocess_dataset_ucf_action_sport.py?中执行的主要步骤
- 将 .avi 文件转换为 .mp4 格式
- 将 Golf-Swing-Back、Golf-Swing-Front 和 Golf-Swing-Side 分组为 Golf-Swing; 将Kicking-Front和Kicking-Side分组为Kicking
- 删除那些已损坏或持续时间为零的 .mp4 剪辑
- 将异常集中的前走、举重和前滑板动作分组。 将剩余的片段分为训练、验证和测试
- 将每个类别的训练和验证剪辑分别增加到 200 个和 10 个剪辑。 这样我就平衡了每个类的训练样本数量
- 为训练、验证、测试和异常的每个最终数据集生成相应的 .csv 数据框,以收集每个剪辑的路径和标签
- 执行预处理步骤后,剪辑视频在每个不同数据集上的分布如图1所示。
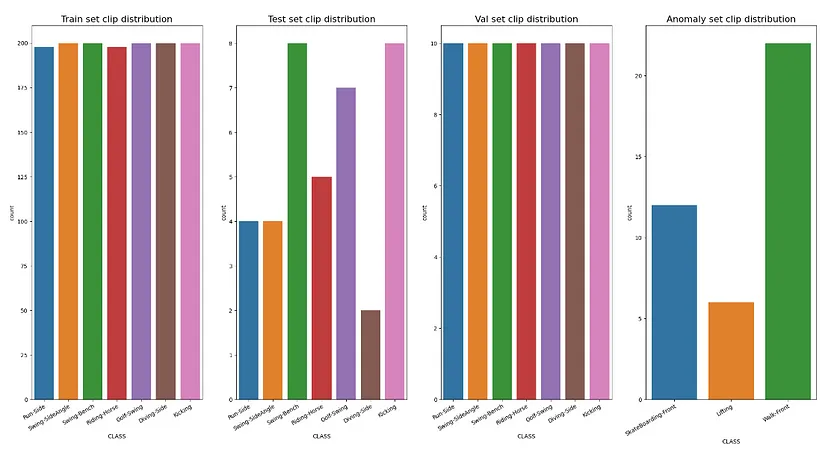
图 1:训练、测试、验证和异常数据集中按类别分组的剪辑数量分布
2、预训练时空模型
对于时空模型,我指的是那些针对动作识别任务进行预训练的模型。 近年来该领域取得了许多进展,因此,为了执行此练习,我选择了三种不同的架构,即 R(2+1)D、SlowFast 3D ResNet 和 TimeSformer,所有这些架构都在 Kinetics-400数据集进行了预训练。 如下面取自模型脚本的代码片段所示,我下载了架构及其相应的权重,并在分类器头之前剪切了每个模型。 这样,对于输入中的每个视频,前向函数提取其相应的嵌入向量。
class Identity(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return x
class TimeSformer(nn.Module):
def __init__(self):
super().__init__()
self.base_model = TimesformerModel.from_pretrained("facebook/timesformer-base-finetuned-k400")
def forward(self, x):
x = self.base_model(x)
x = x.last_hidden_state
# the output of the timsformer is [B, T, E], with B the batch size, T the number of the sequence tokens and E the embedding dimensions
# take just the first component of the second dimension, namely the embedding tensor relative to the classification token for all the tensors in the batch
x = x[:, 0, :]
return x
class R2plus1d_18(nn.Module):
def __init__(self):
super().__init__()
self.base_model = models.video.r2plus1d_18(weights=R2Plus1D_18_Weights.DEFAULT)
self.base_model.fc = Identity()
def forward(self, x):
x = self.base_model(x)
return x
class R3D_slowfast(nn.Module):
def __init__(self):
super().__init__()
self.base_model = torch.hub.load("facebookresearch/pytorchvideo", "slowfast_r50", pretrained=True)
self.base_model.blocks[6].proj = Identity()
def forward(self, x):
x = self.base_model(x)
return x在继续之前,我想对三个预训练的时空模型进行简要描述。
3、R(2+1)D 残差网络
在论文“A Closer Look at Spatiotemporal Convolutions for Action Recognition”[4]中,作者评估了残差学习框架内用于动作识别的不同时空卷积架构。
乍一看,3D 卷积网络看起来像是处理视频剪辑的理想架构。 它们保存时间信息并通过网络各层传播它。 如图[2]所示,使用大小为 t × d × d 的滤波器进行全 3D 卷积,其中 t 表示时间范围,d 是空间宽度和高度,因此滤波器在时间和时间上都进行卷积。 空间维度。
另一种时空变体是“(2+1)D”卷积块,它将 3D 卷积显式分解为两个独立且连续的操作:2D 空间卷积和 1D 时间卷积。 如图2所示,第 i 个块中大小为 Ni?1 × t × d × d 的 N_i 3D 卷积滤波器被替换为由 M_i 2D 卷积滤波器组成的 (2+1)D 块 大小为 Ni?1 × 1 × d × d 和 N_i 个大小为 Mi × t × 1 × 1 的时间卷积滤波器。超参数 M_i 确定信号在空间和时间卷积之间投影的中间子空间的维数,及其 值是固定的,以便 (2+1)D 块中的参数数量与完整 3D 卷积块中的参数数量相匹配。
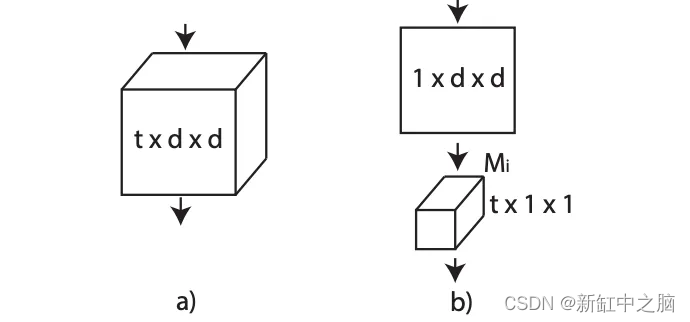
图2: 3D 与 (2+1)D 卷积
与全 3D 卷积相比,(2+1)D 分解具有两个优点。 首先,尽管没有改变参数的数量,但由于每个块中 2D 和 1D 卷积之间的额外 ReLU,它使网络中的非线性数量增加了一倍。 此外,相同层的训练误差更小。 图3对此进行了说明,其中显示了具有 18 层和 34 层的 R3D 和 R(2+1)D 的训练和测试误差。 可以看出,对于相同数量的层(和参数),与 R3D 相比,R(2+1)D 不仅产生更低的测试误差,而且产生更低的训练误差。

图 3:R(2+1)D 和 R3D 的训练和测试误差。 报告了 18 层(左)和 34 层(右)ResNet 的结果
在我的应用程序中,我考虑 R(2+1)D ResNet18 模型,在 8×112×112 视频剪辑上运行并提取维度 512 的嵌入向量。
4、SlowFast 3D ResNet
“SlowFast Networks for Video Recognition” 论文假设剪辑视频中的时空方向的可能性并不相同。 例如,在挥动动作的整个过程中,挥手不会改变其作为“手”的身份,并且一个人始终处于“人”类别中,即使他/她可以从步行过渡到跑步。 由于视觉内容的分类空间语义往往演化缓慢,因此其识别刷新也相对缓慢。 另一方面,所执行的动作可以比他们的主体身份发展得更快,例如拍手、挥手、摇晃、行走或跳跃。 在这种情况下,可能需要使用快速刷新帧来有效地建模潜在的快速变化的运动。
根据这些观察结果,形成了双路 SlowFast 模型。 如图4所示,慢速路径旨在捕获图像或少数稀疏帧可以给出的语义信息,并且它以低帧速率和慢刷新速度运行。 相比之下,快速路径通过以快速刷新速度和高时间分辨率运行来负责捕获快速变化的运动。
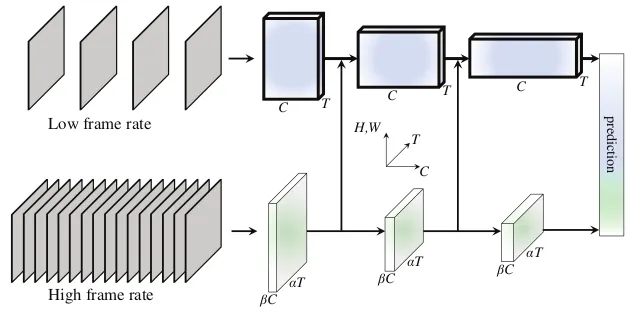
图 4:SlowFast 网络
慢速路径可以是任何将视频剪辑作为时空体积工作的卷积模型。 简而言之,它在输入帧上有一个很大的时间跨度。 快速路径具有较小的时间跨度,因此如果 T 是慢速路径的帧,则 alphaT(其中 alpha>1)是快速路径工作的帧。 此外,Fast 路径在分类之前直到全局池化层才具有时间下采样层,因此特征张量沿时间维度始终具有 alphaT 帧。 最后,虽然快速通道是一种类似于慢速通道的卷积网络,但它的通道比率为 beta,且 beta<1。 这使得快速路径比慢速路径的计算效率更高。
在我的应用程序中,我考虑了 SlowFast ResNet50 模型,该模型分别针对慢速和快速模式对 (8×256×256, 32×256×256) 视频剪辑进行操作,并产生维度 2304 的嵌入向量。
5、TimeSFormer
在过去的几年里,基于自注意力的方法的出现使自然语言处理(NLP)领域发生了革命性的变化。 该机制也已应用于视觉变换模型(ViT)的图像识别和分类领域。 将其应用于视频只是时间问题。
TimeSformer 架构在论文“Is Space-Time Attention All You Need for Video Understanding?”中介绍,是一种无卷积的视频分类方法,专门建立在空间和时间上的自注意力基础上。 该方法通过直接从帧级补丁序列进行时空特征学习,将标准 Transformer 架构适应视频。 与 ViT 一样,每个补丁都线性映射到嵌入中并使用位置信息进行增强。 这使得可以将得到的向量序列解释为令牌嵌入,可以将其馈送到 Transformer 编码器,类似于根据 NLP 中的单词计算的令牌特征。
论文研究了五种时空自注意力方案,如图5所示。 最有效的时空注意力架构被称为“分割时空注意力”(用 T+S 表示),其中时间注意力和空间注意力依次单独应用。 首先,通过将每个补丁(p,t)与其他帧中相同空间位置处的所有补丁进行比较来计算时间注意力。 因此,评估给定固定时间同一帧中该补丁与所有其他补丁之间的注意力。

图 5:五种时空自注意力方案的可视化。 每个视频剪辑都被视为大小为 16 × 16 像素的帧级补丁序列。 为了便于说明,蓝色表示查询补丁,非蓝色表示每个方案下的自注意力时空邻域。 没有颜色的补丁不用于蓝色补丁的自注意力计算。
TimeSformer 具有三种变体。 默认版本运行 8×224×224 视频剪辑。 TimeSformer-HR 是一种高空间分辨率变体,可处理 16 × 448 × 448 视频剪辑。 最后,TimeSformer-L 是一种远程配置,可处理 96 × 224 × 224 视频剪辑。
在我的应用程序中,我考虑默认版本,在 8×224×224 视频剪辑上运行并产生维度 768 的嵌入向量。
表 1 显示了三种不同架构的 Kinetics-400 验证集的结果。
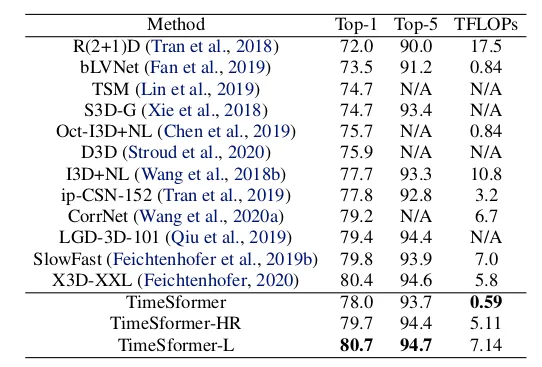
表 1:Kinetics-400 上预训练模型的准确度值。
6、异常检测算法

图 6:异常检测模型的架构
我想在本练习中研究的异常检测模型由两个主要部分组成。 如图6所示,第一个组件是预训练的时空模型。 它将帧序列作为输入并返回相应的嵌入向量。 接下来,自动编码器将嵌入向量作为输入,并旨在在其输出处重建它。
以下代码片段取自?model.py?脚本,详细显示了如何构建完整的网络。 这是通过实例化 SpaceTimeAutoencoder 类来获得的。 时空模型的选择以及自动编码器的属性,即隐藏层的数量及其对应的节点,可以通过配置来设置。 在实验中,我将设置三个隐藏层,其中隐藏潜在空间的维度为 128。此外,在创建时空模型的时刻,我冻结了时空模型的权重,推迟了后续阶段的任何微调。
class Encoder(nn.Module):
def __init__(self, init_dim, num_autoencoder_layers, dim_autoencoder_layers, dropout):
super(Encoder, self).__init__()
self.init_dim = init_dim
self.num_autoencoder_layers = num_autoencoder_layers
self.dim_autoencoder_layers = dim_autoencoder_layers
self.layer_1 = nn.Linear(self.init_dim, dim_autoencoder_layers[0])
self.layer_2 = nn.Linear(dim_autoencoder_layers[0], dim_autoencoder_layers[1])
self.layer_3 = None
if num_autoencoder_layers == 3:
self.layer_3 = nn.Linear(dim_autoencoder_layers[1], dim_autoencoder_layers[2])
self.dropout = nn.Dropout(dropout)
self.relu = nn.ReLU()
self.batchNorm1 = nn.BatchNorm1d(init_dim)
def forward(self, x):
x = self.batchNorm1(x)
x = self.layer_1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.layer_2(x)
x = self.relu(x)
if self.num_autoencoder_layers == 3:
x = self.dropout(x)
x = self.layer_3(x)
x = self.relu(x)
return x
class Decoder(nn.Module):
def __init__(self, init_dim, num_autoencoder_layers, dim_autoencoder_layers, dropout):
super(Decoder, self).__init__()
self.init_dim = init_dim
self.num_autoencoder_layers = num_autoencoder_layers
self.dim_autoencoder_layers = dim_autoencoder_layers
self.layer_3 = None
if num_autoencoder_layers == 3:
self.layer_3 = nn.Linear(dim_autoencoder_layers[2], dim_autoencoder_layers[1])
self.layer_2 = nn.Linear(dim_autoencoder_layers[1], dim_autoencoder_layers[0])
self.layer_1 = nn.Linear(dim_autoencoder_layers[0], self.init_dim)
self.dropout = nn.Dropout(dropout)
self.relu = nn.ReLU()
def forward(self, x):
if self.num_autoencoder_layers == 3:
x = self.layer_3(x)
x = self.relu(x)
x = self.dropout(x)
x = self.layer_2(x)
x = self.relu(x)
x = self.dropout(x)
x = self.layer_1(x)
return x
class SpaceTimeAutoencoder(nn.Module):
def __init__(self, model_config):
super().__init__()
self.init_dim = model_config['init_dim']
self.name_time_model = model_config['name_time_model']
self.freeze_layers = model_config.get("freeze_layers", 1.0) > 0.0
self.num_autoencoder_layers = model_config['num_autoencoder_layers']
dim_autoencoder_layers = model_config['dim_autoencoder_layers'].split(",")
self.dim_autoencoder_layers = [int(i) for i in dim_autoencoder_layers]
self.dropout = model_config['dropout']
self.base_model = None
if self.name_time_model == "timesformer":
self.base_model = TimeSformer()
elif self.name_time_model == "r2plus1d_18":
self.base_model = R2plus1d_18()
elif self.name_time_model == "3d_slowfast":
self.base_model = R3D_slowfast()
if self.freeze_layers:
print("Freeze layers of base model")
self.freeze_layers_base_model()
self.encoder = Encoder(self.init_dim, self.num_autoencoder_layers, self.dim_autoencoder_layers, self.dropout)
self.decoder = Decoder(self.init_dim, self.num_autoencoder_layers, self.dim_autoencoder_layers, self.dropout)
def freeze_layers_base_model(self):
for name, param in self.base_model.named_parameters():
param.requires_grad = False
def forward(self, x):
embedding = self.base_model(x)
latent = self.encoder(embedding)
rec_embedding = self.decoder(latent)
return embedding, rec_embedding, latentDataset?类管理训练、验证和测试阶段中发生的加载和转换步骤。 对于每个剪辑,通过?UniformTemporalSubsample?对象,在剪辑的持续时间内选择预定数量的均匀分隔的帧。 因此,帧被标准化并调整大小。 仅对于 SlowFast 模型,帧由 PackPatway 类分隔在两个列表中。 第一个用于慢速路径,第二个用于快速分量,相对于第一个帧具有多个 alpha 帧。 对于 R(2+1)D 和 SlowFast 模型,加载的帧张量具有尺寸 (C, N, H, W),其中 C 是颜色通道,N 是帧数,H 和 W 是高度和宽度 。 相反,我必须排列 TimeSformer 模型的 C 和 N 维度,如 getitem 函数所示。
class PackPathway(torch.nn.Module):
"""
Transform for converting video frames as a list of tensors.
"""
def __init__(self, alpha_slowfast):
super().__init__()
self.alpha_slowfast = alpha_slowfast
def forward(self, frames: torch.Tensor):
fast_pathway = frames
# Perform temporal sampling from the fast pathway.
slow_pathway = torch.index_select(
frames,
1,
torch.linspace(
0, frames.shape[1] - 1, frames.shape[1] // self.alpha_slowfast
).long(),
)
frame_list = [slow_pathway, fast_pathway]
return frame_list
class Dataset(torch.utils.data.Dataset):
def __init__(self, df_dataset, data_cfg, dataset_path, is_train=False, is_slowfast=False) -> None:
super().__init__()
self.df_dataset = df_dataset
self.dataset_path = dataset_path
self.data_cfg = data_cfg
self.num_frames_to_sample = self.data_cfg["num_frames_to_sample"]
self.mean = [float(i) for i in self.data_cfg["mean"]]
self.std = [float(i) for i in self.data_cfg["std"]]
self.min_size = self.data_cfg["min_size"]
self.max_size = self.data_cfg["max_size"]
self.resize_to = self.data_cfg["resize_to"]
self.permute_color_frame = self.data_cfg.get("permute_color_frame", 1.0) > 0.0
self.is_train = is_train
self.is_slowfast = is_slowfast
self.alpha_slowfast = data_cfg.get("alpha_slowfast", None)
if not self.is_slowfast:
if is_train:
self.transform = ApplyTransformToKey(
key="video",
transform=Compose(
[
UniformTemporalSubsample(self.num_frames_to_sample),
Lambda(lambda x: x / 255.0),
Normalize(self.mean, self.std),
RandomShortSideScale(min_size=self.min_size, max_size=self.max_size),
RandomCrop(self.resize_to),
]
),
)
else:
self.transform = ApplyTransformToKey(
key="video",
transform=Compose(
[
UniformTemporalSubsample(self.num_frames_to_sample),
Lambda(lambda x: x / 255.0),
Normalize(self.mean, self.std),
Resize((self.resize_to, self.resize_to))
]
),
)
else:
if is_train:
self.transform = ApplyTransformToKey(
key="video",
transform=Compose(
[
UniformTemporalSubsample(self.num_frames_to_sample),
Lambda(lambda x: x / 255.0),
Normalize(self.mean, self.std),
RandomShortSideScale(min_size=self.min_size, max_size=self.max_size),
RandomCrop(self.resize_to),
PackPathway(self.alpha_slowfast)
]
),
)
else:
self.transform = ApplyTransformToKey(
key="video",
transform=Compose(
[
UniformTemporalSubsample(self.num_frames_to_sample),
Lambda(lambda x: x / 255.0),
Normalize(self.mean, self.std),
Resize((self.resize_to, self.resize_to)),
PackPathway(self.alpha_slowfast)
]
),
)
def __len__(self):
return len(self.df_dataset)
def __getitem__(self, idx):
video_path = os.path.join(self.dataset_path, self.df_dataset.iloc[idx]["PATH"])
label = self.df_dataset.iloc[idx]["LABEL"]
class_name = self.df_dataset.iloc[idx]["CLASS"]
video = EncodedVideo.from_path(video_path)
start_time = 0
# follow this post for clip duration https://towardsdatascience.com/using-pytorchvideo-for-efficient-video-understanding-24d3cd99bc3c
clip_duration = int(video.duration)
end_sec = start_time + clip_duration
video_data = video.get_clip(start_sec=start_time, end_sec=end_sec)
video_data = self.transform(video_data)
video_tensor = video_data["video"]
if self.permute_color_frame:
# permute the color channel with the number of frame channel from (C, N, H, W) to (N, C, H, W)
video_tensor = torch.permute(video_tensor, (1, 0, 2, 3))
return video_tensor, label, class_name7、培训与评估
加载配置文件后,如?train_test_autoencoder.py?脚本的以下代码部分所示,训练过程开始实例化训练、验证、测试和异常数据集的数据加载器。 因此,我创建了模型、Adam 优化器和 Step 学习率调度器。 作为优化标准,我设置了 MSELoss 函数,该函数将在输入中接收时空模型提取的嵌入向量和自动编码器获得的重构嵌入向量。 实际上,对于训练数据集,随着重建的嵌入向量接近时空模型生成的嵌入向量,问题的解决会好得多。 另一方面,对于异常情况,重建误差必须足够高。
# create the dataloaders
train_loader, val_loader, test_loader, anomaly_loader = create_loaders(df_dataset_train=df_dataset_train,
df_dataset_val=df_dataset_val,
df_dataset_test=df_dataset_test,
df_dataset_anomaly=df_dataset_anomaly,
data_cfg=cfg["data"],
dataset_path=dataset_path,
batch_size=batch_size,
is_slowfast=is_slowfast)
# set the device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("device: {}".format(device))
# create the model
model = SpaceTimeAutoencoder(cfg["model"]).to(device)
checkpoint_dir = saving_dir_model
# Set optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# set the scheduler
scheduler = torch.optim.lr_scheduler.StepLR(optimizer=optimizer,
step_size=scheduler_step_size,
gamma=lr_factor)
# set the loss
criterion = nn.MSELoss(reduction='sum')之后,我调用 train_model 函数。 对于每个时期,我首先检查时空模型的权重是否必须全局或部分解冻,因此我迭代训练和验证数据集。 每次重建错误在验证集上得到改善时,我都会保存一个新的最佳检查点。
def train_model(cfg,
device,
model,
criterion,
optimizer,
lr_scheduler,
train_loader,
val_loader,
best_epoch,
num_epoch,
best_val_epoch_loss,
checkpoint_dir,
saving_dir_experiments,
epoch_start_unfreeze=None,
layer_start_unfreeze=None,
aws_bucket=None,
aws_directory=None,
scheduler_type=None):
train_losses = []
val_losses = []
print("Start training")
freezed = True
for epoch in range(best_epoch, num_epoch):
if epoch_start_unfreeze is not None and epoch >= epoch_start_unfreeze and freezed:
print("****************************************")
print("Unfreeze the base model weights")
if layer_start_unfreeze is not None:
print("unfreeze the layers greater and equal to layer_start_unfreeze: ", layer_start_unfreeze)
#in this case unfreeze only the layers greater and equal the unfreezing_block layer
for i, properties in enumerate(model.named_parameters()):
if i >= layer_start_unfreeze:
#print("Unfreeze model layer: {} - name: {}".format(i, properties[0]))
properties[1].requires_grad = True
else:
# in this case unfreeze all the layers of the model
print("unfreeze all the layer of the model")
for name, param in model.named_parameters():
param.requires_grad = True
freezed = False
print("*****************************************")
print("Model layer info after unfreezing")
print("Check layers properties")
for i, properties in enumerate(model.named_parameters()):
print("Model layer: {} - name: {} - requires_grad: {} ".format(i, properties[0],
properties[1].requires_grad))
print("*****************************************")
pytorch_total_params = sum(p.numel() for p in model.parameters())
pytorch_total_trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print("pytorch_total_params: ", pytorch_total_params)
print("pytorch_total_trainable_params: ", pytorch_total_trainable_params)
print("*****************************************")
# define empty lists for the values of the loss of train and validation obtained in the batch of the current epoch
# then at the end I take the average and I get the final values of the whole era
train_epoch_losses = []
val_epoch_losses = []
# cycle on all train batches of the current epoch by executing the train_batch function
for inputs, _, _ in tqdm(train_loader, desc=f"epoch {str(epoch)} | train"):
if cfg['model']['name_time_model'] == "3d_slowfast":
inputs = [i.to(device) for i in inputs]
else:
inputs = inputs.to(device)
batch_loss = train_batch(inputs, model, optimizer, criterion)
train_epoch_losses.append(batch_loss)
torch.cuda.empty_cache()
train_epoch_loss = np.array(train_epoch_losses).mean()
# cycle on all batches of val of the current epoch by calculating the accuracy and the loss function
for inputs, _, _ in tqdm(val_loader, desc=f"epoch {str(epoch)} | val"):
if cfg['model']['name_time_model'] == "3d_slowfast":
inputs = [i.to(device) for i in inputs]
else:
inputs = inputs.to(device)
validation_loss = val_loss(inputs, model, criterion)
val_epoch_losses.append(validation_loss)
torch.cuda.empty_cache()
val_epoch_loss = np.mean(val_epoch_losses)
wandb.log({'Learning Rate': optimizer.param_groups[0]['lr'],
'Train Loss': train_epoch_loss,
'Valid Loss': val_epoch_loss})
print("Epoch: {} - LR:{} - Train Loss: {:.4f} - Val Loss: {:.4f}".format(int(epoch), optimizer.param_groups[0]['lr'], train_epoch_loss, val_epoch_loss))
train_losses.append(train_epoch_loss)
val_losses.append(val_epoch_loss)
if best_val_epoch_loss > val_epoch_loss:
print("We have a new best model! Save the model")
# update best_val_epoch_loss
best_val_epoch_loss = val_epoch_loss
save_obj = {
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
'scheduler': lr_scheduler.state_dict(),
'epoch': epoch,
'best_eval_loss': best_val_epoch_loss
}
print("Save best checkpoint at: {}".format(os.path.join(checkpoint_dir, 'best.pth')))
torch.save(save_obj, os.path.join(checkpoint_dir, 'best.pth'), _use_new_zipfile_serialization=False)
print("Save latest checkpoint at: {}".format(os.path.join(checkpoint_dir, 'latest.pth')))
torch.save(save_obj, os.path.join(checkpoint_dir, 'latest.pth'), _use_new_zipfile_serialization=False)
else:
print("Save the current model")
save_obj = {
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
'scheduler': lr_scheduler.state_dict(),
'epoch': epoch,
'best_eval_loss': best_val_epoch_loss
}
print("Save latest checkpoint at: {}".format(os.path.join(checkpoint_dir, 'latest.pth')))
torch.save(save_obj, os.path.join(checkpoint_dir, 'latest.pth'), _use_new_zipfile_serialization=False)
if scheduler_type == "ReduceLROnPlateau":
print("lr_scheduler.step(val_epoch_loss)")
lr_scheduler.step(val_epoch_loss)
else:
print("lr_scheduler.step()")
lr_scheduler.step()
if aws_bucket is not None and aws_directory is not None:
print('Upload on S3')
multiup(aws_bucket, aws_directory, saving_dir_experiments)
torch.cuda.empty_cache()
gc.collect()
print("---------------------------------------------------------")
print("End training")
return
def train_batch(inputs, model, optimizer, criterion):
model.train()
target, outputs, latent = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
optimizer.zero_grad()
return loss.item()
@torch.no_grad()
def val_loss(inputs, model, criterion):
model.eval()
target, outputs, latent = model(inputs)
val_loss = criterion(outputs, target)
return val_loss.item()因此,在训练结束时,我评估训练、验证、测试和异常数据集的最佳模型。 对于每个视频,我找到相应嵌入向量的重建误差。 它保存在 Pandas 数据框中,以便检查按不同数据集分组的错误分布。
8、实验与结果
对于每个时空模型,我训练了两种配置。 在第一个中,仅训练自动编码器,而时空模型则保持冻结。 在第二个中,除了自动编码器之外,我还解冻了时空模型的最后一层,将其权重微调到我的自定义数据集。 也就是说,对于 R(2+1)D,我解锁了 110 层中的最后 12 层,对于 SlowFast,我解锁了 329 层中的最后 30 层,对于 TimeSformer,我解锁了 246 层中的最后 22 层。
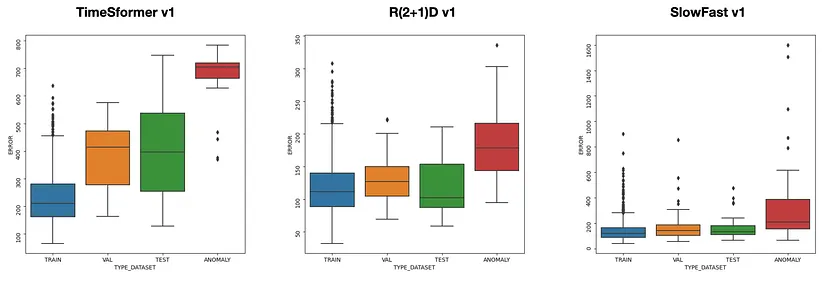
图 7:时空模型冻结的三种架构的训练集、验证集和测试集的重建误差分布
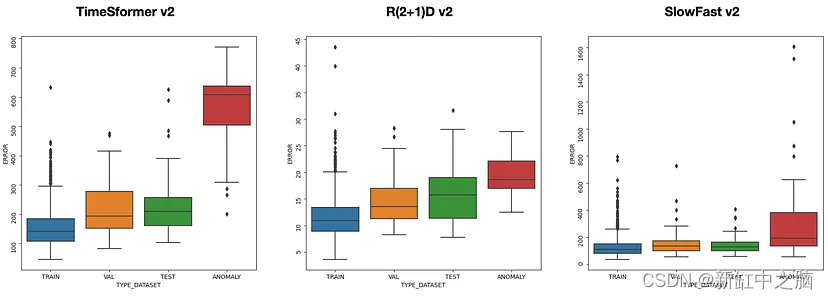
图 8:三种架构的训练、验证和测试集中的重建误差分布,时空模型仅在最后一层进行微调
在图7和图8中,我展示了两种不同配置中的每个最佳模型的重建误差如何分布在训练、验证、测试和异常数据集上。 因为这里提出的方法的目标是最小化训练集、验证集和测试集中的重建误差,并最大化异常数据集上的重建误差,所以最适合此要求的架构是使用 TimeSformer 作为时空模型的自动编码器。 在这种情况下,对于两种配置,异常数据集的误差分布集中在较高的值上,并且与其他数据集的重叠较少。
最后一步是修复分离阈值,以便在推理时我可以区分剪辑视频是否正常。 为此,查看图7和8中的箱线图,我在脚本test_anomaly_clips.py的函数evaluate_anomaly_accuracy上尝试不同的值,选择将最大数量的异常剪辑识别为异常并将正常剪辑混淆为 尽可能少的异常。
def evaluate_anomaly_accuracy(model, transform, path_datset, thershold_err, thershold_dist, file_result, embedding_centroids=None, invert_accuracy=False, is_slowfast=False):
counter_anomaly_error = 0
counter_non_anomaly_error = 0
with torch.no_grad():
for subdir, dirs, files in os.walk(path_datset):
for dir in dirs:
path_subdir = os.path.join(path_datset, dir)
for file in os.listdir(path_subdir):
video_path = os.path.join(path_subdir, file)
tensor_video = load_video(video_path, permute_color_frame, transform)
if is_slowfast:
tensor_video = [i.to(device)[None, ...] for i in tensor_video]
else:
tensor_video = tensor_video[None].to(device)
# reconstructed embedding
emb, rec_emb, _ = model(tensor_video)
error = loss(emb, rec_emb).item()
# chech the reconstructing error
if error >= thershold_err:
counter_anomaly_error += 1
else:
counter_non_anomaly_error += 1
file_result.write('\n')
file_result.write('*************************************************************\n')
file_result.write("RESULT ANOMALY WITH RECONSTRUCTION ERROR\n")
file_result.write('*************************************************************\n')
total_clip = counter_anomaly_error + counter_non_anomaly_error
anomaly_accuracy = counter_anomaly_error/total_clip
file_result.write("total_clip: {}\n".format(total_clip))
file_result.write("counter_anomaly_error: {}\n".format(counter_anomaly_error))
if invert_accuracy:
file_result.write("non anomaly_accuracy: {}\n".format(1-anomaly_accuracy))
else:
file_result.write("anomaly_accuracy: {}\n".format(anomaly_accuracy))
file_result.write('\n')
return embedding_centroids, file_result在表 2 中,我显示了最佳结果和相应的阈值。 对于异常数据集,准确度值是检测为异常的视频剪辑数量与异常剪辑总数之间的比率。 对于其他数据集,准确度值为 1 减去检测为异常的视频剪辑数量与非异常剪辑总数之比。
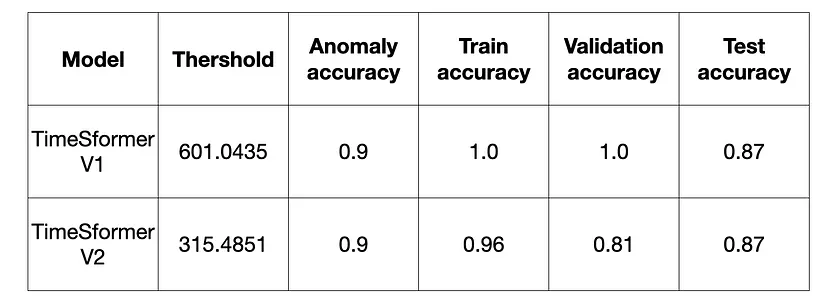
表 2:所选阈值在不同数据集上的准确度结果
原文链接:基于时空模型的异常检测 - BimAnt
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 项目中Ant Design Pro业务问题解决方案
- 【每日一题】466. 统计重复个数-2024.1.2
- Linux性能调优技术概览
- Jetson Orin Nano安装OpenCV带cuda加速版本的全过程
- C++基础普及:如何学好常用的数据结构
- QSY-21 NHS ,淬灭剂QXY21酯,可与Cy5或其他光谱相似的荧光染料配对
- 支持向量机(Support Vector Machines,SVM)
- 2024年美赛数学建模思路 - 案例:退火算法
- 低代码开发平台:数字化转型的助推器与未来趋势
- 喜讯!云起无垠获评“德勤海淀明日之星”