云原生技术专题 | 解密2023年云原生的安全优化升级,告别高危漏洞、与数据泄露说“再见”(安全管控篇)
背景介绍
2023年,我们见证了科技领域的蓬勃发展,每一次技术革新都为我们带来了广阔的发展前景。作为后端开发者,我们深受其影响,不断迈向未来。
随着数字化浪潮的席卷,各种架构设计理念相互交汇,共同塑造了一个充满竞争和创新的技术时代。微服务、云原生、Serverless、事件驱动、中台、容灾等多样化的架构思想,都在竞相定义未来技术的标准。然而,哪种将成为引领时代的主流趋势,仍是一个未知数。尽管如此,种种迹象表明,云原生的主题正在逐渐深入人心。让我们一起分析和探讨云原生技术和架构安全体系的升级和改良,以期发现新的技术趋势和见解。
云计算的下一站,就是云原生,IT架构的下一站,就是云原生架构。
云原生
也许一些读者对云原生的概念仍感到陌生或存有疑问,让我们先来简要介绍一下云原生技术及其架构的主要功能和作用。
云原生是什么
云原生是一种行为方式和设计理念,其本质在于提高云上资源利用率和应用交付效率的行为或方式都可以被归纳为云原生。
云原生的目标
云原生技术帮助组织在公有云、私有云和混合云等新型动态环境中构建和运行可弹性扩展的应用。通过云原生,可以构建容错性强、易于管理和便于监控的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统进行频繁且可预测的重大变更。
在这里,我们用一个图来勾勒一下,从而加深一下大家的对于云原生技术的印象,如下图所示:

云原生的4大基本要素
云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API。但是对于声明式API而言,它的作用主要作为功能层面,因此暂时没有把他归并为云原生的基本要素当中。
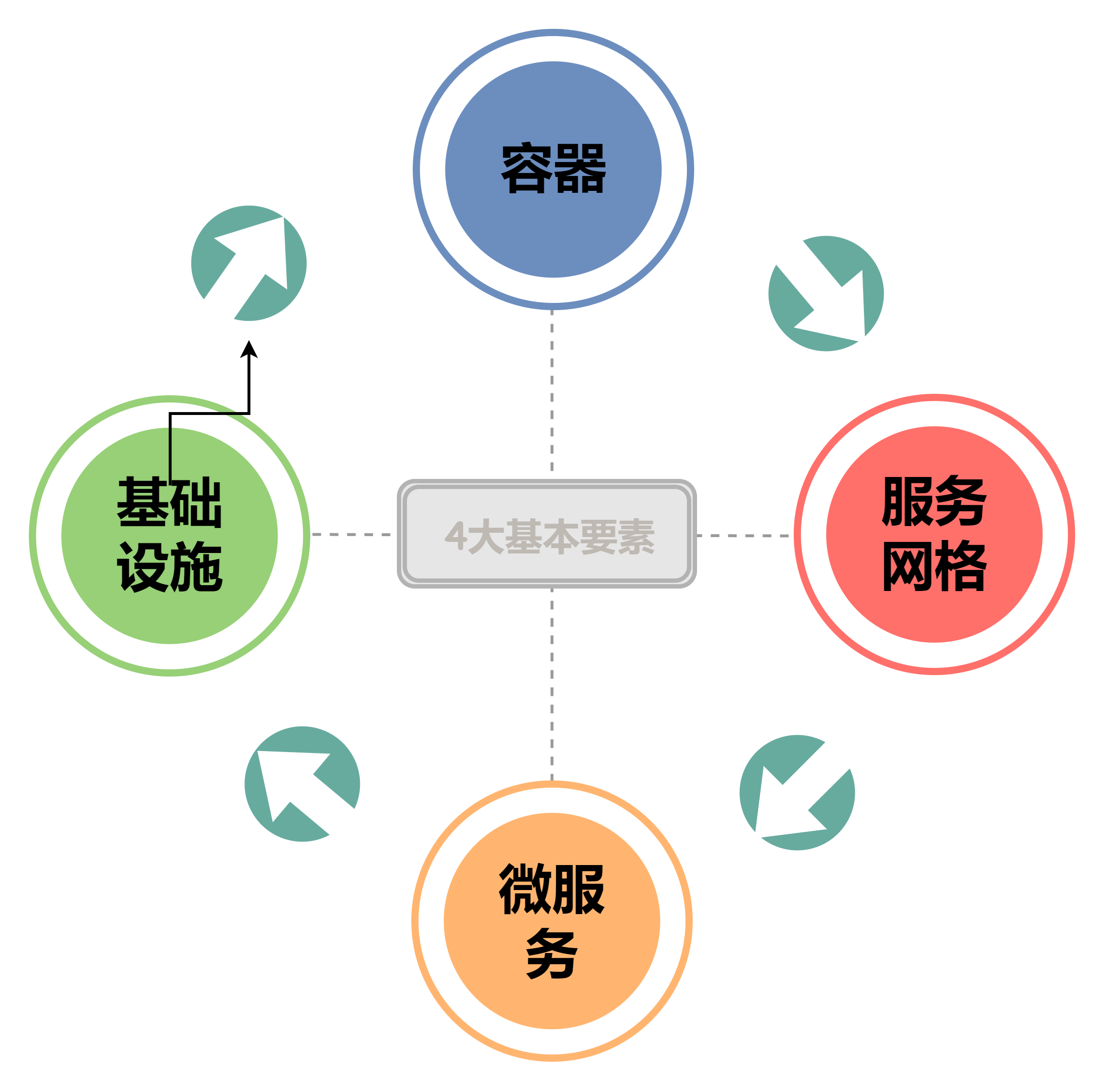
特别是Kubernetes开启了云原生的序幕,服务网格 Istio 的出现,引领了后 Kubernetes 时代的微服务,serverless 的再次兴起,使得云原生从基础设施层不断向应用架构层挺进,我们正处于一个云原生的新时代。
好的!通过上面的内容相信您已经对云原生及其技术有了一定的了解。不再赘述有关云原生的基础内容,如果您感兴趣,可以阅读相关的云原生官方指南。接下来我们直接进入主题。
云原生的安全探索
Kubernetes被认为是目前最广泛和最重要的开源容器编排系统,主要用于自动部署、扩展和管理容器化应用程序。

然而,Kubernetes集群的安全问题可能非常复杂,并经常被滥用,尤其是由于错误的配置可能带来潜在威胁。因此我们将总结和归纳具体的安全配置,希望可以帮助大家建立更安全的Kubernetes体系,主要集中一下几个方向,如图所示。

K8s Pod安全
Pod是Kubernetes 中最小的可部署单元,由一个或多个容器组成。通常情况下,Pod是网络行为者在利用容器时的初始执行环境。因此,应加固Pod以增加利用难度,并限制成功入侵的影响,接下来我们主要会从一下这几个方面进行入手分析说明。
管控容器访问用户
通常情况下,许多容器服务会以特权的root用户身份运行,这可能导致应用程序在容器内被授予了不必要的特权,从而造成了安全问题以及容器资源被破坏。
解决方案:采用非root容器和无root容器引擎,使用构建的容器,以非root用户身份运行应用程序,可以防止使用root权限执行,从而限制容器受损的影响。
非root容器
容器引擎允许容器以非root用户和非root组成员身份运行应用程序。通常情况下,这种非默认设置是在构建容器镜像的时候配置的,我们采用一个Dockerfile文件进行设定。
非root用户指的是在操作系统中没有超级用户(root)权限的用户。
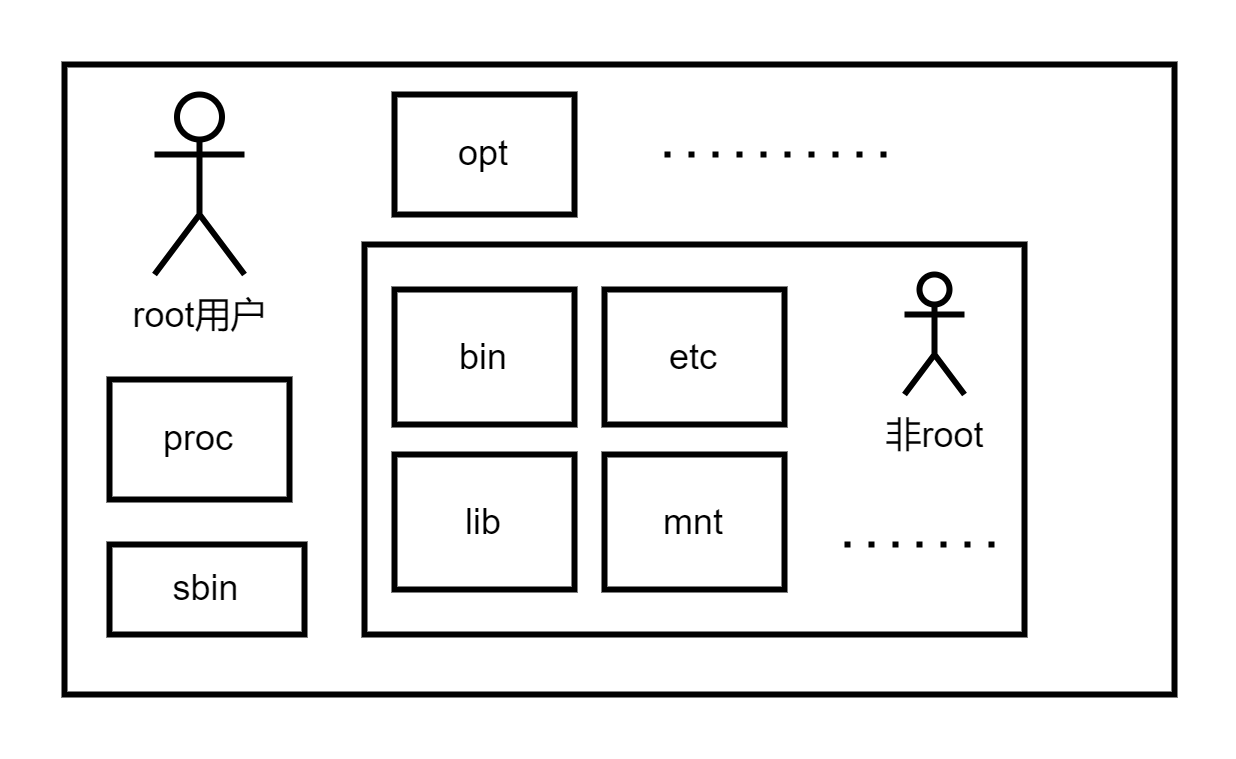
非root应用的Dockerfile
下面是一个示例 Dockerfile,它演示了以非 root 用户身份运行一个应用的情况。
FROM ubuntu:latest
# 升级和安装 make 工具
RUN apt update && apt install -y make
# 从名为 temp 的文件夹复制源代码,并使用 make 工具构建应用程序。
COPY ./temp /temp
RUN make /temp
# 创建新用户(test)和用户组(teG),然后切换到用户上下文。
RUN useradd test && groupadd teG
USER test:teG
# 设置容器的默认入口
CMD /temp/app
副作用或影响
采用对运行时环境产生重大影响,因此应该对应用程序进行全面测试,以确保其兼容性。
无root容器引擎为容器本身就是支持非root用户进行访问和运行容器应用,与非root相比,少了很多兼容以及权限限制问题,也就是非root用户的影响和副作用问题,本质就是加入了一个权限控制安全层,保护了容器本身不会被root权限进行过严重的破坏,但是由于无root模式,本人并没有进行测试和验证,再次只是基于大家一个方案和考量。
管控容器文件系统
默认情况下,容器被允许在自己的上下文中以无限制的方式执行。这意味着在容器中获得执行权限的网络行为者可以创建文件、下载脚本并修改应用程序。
解决方案:Kubernetes提供了一种方法来锁定容器的文件系统,以减少许多潜在的安全风险。
只读文件系统的部署yml文件
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: app
name: app
spec:
selector:
matchLabels:
app: app
template:
metadata:
labels:
app: app
name: app
spec:
containers:
- command: ["sleep"]
args: ["999"]
image: ubuntu:latest
name: web
securityContext:
readOnlyRootFilesystem: true #使容器的文件系统成为只读
volumeMounts:
- mountPath: /writeable/location/file #创建一个可写卷
name: volName
volumes:
- emptyDir: {}
name: volName
上面的配置实现了一个具有可写目录的不可变容器。
副作用或影响
影响合法的容器应用程序,并可能导致崩溃或异常行为。为了防止损害合法的应用程序,Kubernetes管理员可以为应用程序需要写访问的特定目录挂载二级读 / 写文件系统。
网络隔离
针对容器用户和资源的管理方案可以显著降低资源相关的容器风险,并加强管控。接下来,我们将针对网络隔离进行严格把控,以确保对外部通信的严格管理。
集群网络策略
集群网络是Kubernetes的核心概念,包括容器、Pod、服务和外部服务之间的通信。因此,必须考虑网络优化。
默认情况下,很少使用网络策略来隔离资源,以防止集群在横向移动或升级时受到破坏。为了限制网络参与者在集群内的横向移动和升级,资源隔离和加密是有效的方法,总体归纳为一下三种:

网络策略和防火墙
网络策略用于控制Pod、命名空间和外部IP地址之间的流量。
默认情况下,Pod和命名空间没有应用网络策略,这导致流入和流出Pod网络的流量没有限制。通过应用网络策略到Pod或Pod命名空间,可以实现对 Pod 的隔离。
注意:如果Pod选择了网络策略,它将拒绝任何与该策略对象不允许的连接。
隔离流量控制
创建网络策略,需要一个支持 NetworkPolicy API 的网络插件。使用podSelector 和 / 或namespaceSelector选项来选择 Pod。
在这里我们可以简单举一个网络策略案例:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-access
namespace: testRule #这可以是任何一个命名空间
spec:
podSelector:
matchLabels:
app: nginx
ingress:
- from:
- podSelector:
matchLabels:
access: "true"
tips:通常情况下,使用选择Pod的默认策略来拒绝所有入口和出口流量,并确保任何未选择的Pod被隔离,额外的策略可以放松这些允许连接的限制。
命名空间
上面提到了命名空间namespace,那我们就来简单的介绍一下命名空间吧。
命名空间是将集群资源划分给多个人、团队或应用程序的一种方式。
默认情况下,命名空间不会自动隔离。然而,命名空间确实为范围分配了标签,这可以通过 RBAC 和网络策略来指定授权规则。除了网络隔离外,资源策略还可以限制存储和计算资源,从而更好地控制命名空间中的 Pod。
下面是K8s自带的三个命名空间:

-
kube-system:用于存放 Kubernetes 组件的命名空间,例如 kube-proxy、kube-dns 和 kube-scheduler 等。这些组件对集群的正常运行至关重要。
-
kube-public:用于存放公有资源的命名空间,这些资源可以被整个集群中的所有用户访问。例如,集群级的配置信息和公共服务的凭证。
-
default:用于存放用户资源的命名空间,这是集群中大多数应用程序和服务所在的命名空间。如果没有显式地指定命名空间,新创建的资源将被放置在 default 命名空间中。
创建一个命名空间。
kubectl create namespace <insert-namespace-name-here>
要使用 YAML 文件创建命名空间,创建一个名为 my-namespace.yaml 的新文件,内容如下:
apiVersion: v1
kind: Namespace
metadata:
name: <insert-namespace-name-here>
结合命名空间进行资源策略管控
上面介绍了网络策略,通过它可以对网络请求流量进行管控,从而降低系统安全风险。命名空间的隔离机制可以建立资源隔离的控制。然而,实际场景中命名空间的隔离并不是命名空间本身的能力,而是通过绑定资源策略来实现的。
我们的方案是通过LimitRange和ResourceQuota限制命名空间或节点的资源使用的策略。
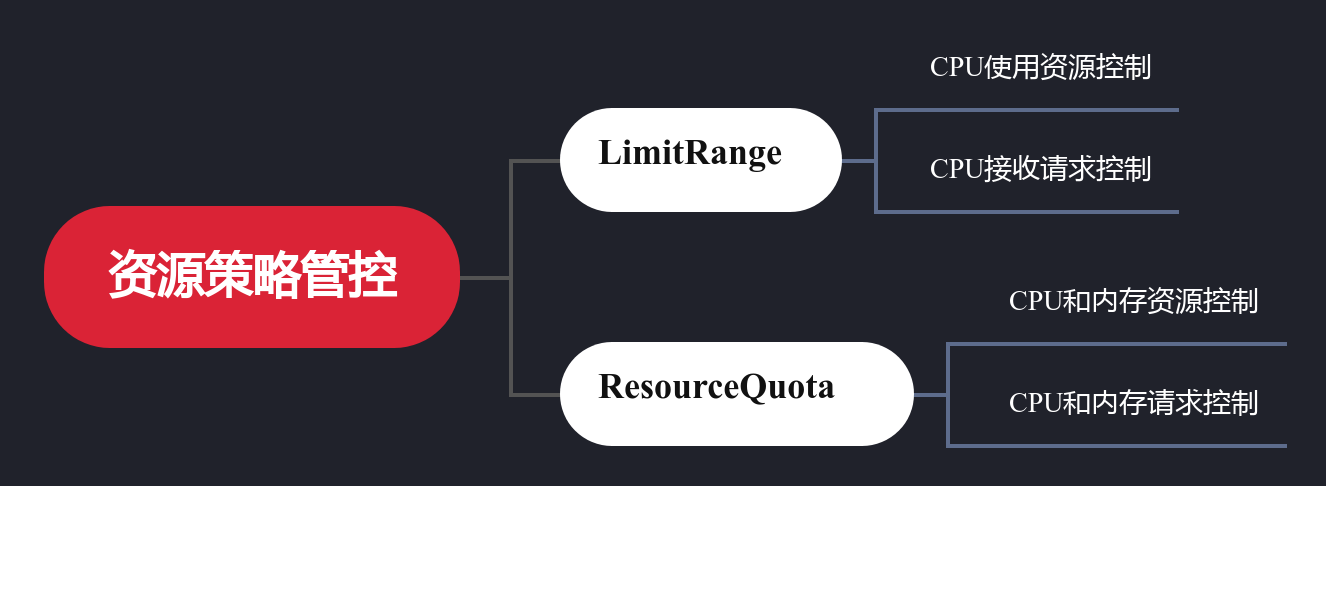
LimitRange管控机制
我们通过使用LimitRange策略用于限制特定命名空间中每个 Pod 或容器的单个资源。它可以通过强制执行最大计算和存储资源来控制资源的使用。
apiVersion: v1
kind: LimitRange
metadata:
name: cpu_control
spec:
limits
- default:
cpu: 1
defaultRequest:
cpu: 0.5
max:
cpu: 2
min:
cpu: 0.5
type: Container
每个命名空间只能创建LimitRange 约束,在其范围内,每个容器可以指定一个 LimitRange,其中包含默认的资源请求和限制,以及最小和最大的请求。LimitRange可以应用于命名空间,使用:
kubectl apply -f <example-LimitRange>.yaml --namespace=<Enter-Namespace>
在应用了这个 LimitRange 配置的例子后,如果没有指定,命名空间中创建的所有容器都会被分配到默认的CPU 请求和限制。命名空间中的所有容器的CPU请求必须大于或等于最小值,小于或等于最大 CPU 值,否则容器将不会被实例化。
ResourceQuotas管控机制
ResourceQuotas是对整个命名空间的资源使用总量的限制,例如对 CPU 和内存使用总量的限制。如果用户试图创建一个违反LimitRange或ResourceQuota策略的 Pod,则 Pod 创建失败。
针对于我自己常用的情况下的资源配额分配(内存请求、内存限制、CPU 请求和 CPU 限制)
apiVersion: v1
kind: ResourceQuota
metadata:
name: cpu-mem-resourcequota
spec:
hard:
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi
- 容器的总内存请求不应超过 1 GiB
- 容器的总内存限制不应超过 2 GiB
- 容器的CPU请求总量不应超过 1 个 CPU
- 容器的总CPU限制不应超过 2 个 CPU
应用这个ResourceQuota
kubectl apply -f example-cpu-mem-resourcequota.yaml -- namespace=<insert-namespace-here>
确保控制平面的安全(建议)
控制平面是 Kubernetes 的核心,因此Kubernetes API 服务器不应该暴露在互联网或不信任的网络中,故此确保控制平面的安全而言,我没有别的可说的,直接阻止外界对于访问就行了。

毕竟它也用不到,但是内部通信即使用了默认策略也必须可以互相通信,否则控制平台,就没有意义了,因此网络策略可以应用于 kube-system 命名空间,以限制互联网对 kube-system 的访问。
流量和敏感数据进行加密
分发证书给节点,以确保安全通信
在 Kubernetes 集群中,所有流量(包括组件、节点和控制平面之间的流量)都使用TLS 1.2或1.3加密。加密可以在安装过程中进行设置,也可以在安装后使用 TLS 引导创建证书并分发给节点。
敏感信息的控制访问
Secret提高了访问控制
Kubernetes应该使用Secret维护敏感信息,如密码、OAuth 令牌和SSH密钥。YAML文件、容器镜像或环境变量中存储密码或令牌相比,任何有API权限的人都可以检索到。
Kubernetes将Secret存储为未加密的base64编码字符串,将敏感信息存储在Secret中可以通过对secret资源应用RBAC策略来限制访问,从而提高了访问控制。
认证授权
哈哈,先休息一下,消化一下上面的内容,等待姊妹篇在学习。

日志审计
哈哈,先休息一下,消化一下上面的内容,等待姊妹篇在学习。
个人感悟
未来十年,云计算将无处不在,像水电煤一样成为数字经济时代的基础设施,云原生让云计算变得标准、开放、简单高效、触手可及。如何更好地拥抱云计算、拥抱云原生架构、用技术加速创新,将成为企业数字化转型升级成功的关键。
本章内容,暂时总结分析到这里,希望大家等待我的姊妹篇:【云原生技术专题 | 解密2023年云原生的安全优化升级,告别高危漏洞、与数据泄露说“再见”(信息审计篇)】
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 提高客户满意度和市场竞争力常用的ChatGPT通用提示词模板
- VC++中使用OpenCV对原图像中的四边形区域做透视变换
- FastSAM 分割一切 速度可以比 SAM 快 50 倍
- 虚拟机Ubuntu系统中使用catkin build系统卡死
- windows下Node版本的切换方式
- js对象方法大全(开发必会)
- unity SqLite读取行和列
- 矿泉水除硝酸盐工艺新进展
- 人工智能在现代科技中的应用和未来发展趋势。
- pybind11:实现ndarray转C++原生数组