DASS最新论文整理@2023.12
CVPR 2023?
论文来源:https://openaccess.thecvf.com/CVPR2023?day=all
1 Planning-oriented Autonomous Driving??面向规划的自动驾驶 (Best papper)
项目地址:https://opendrivelab.github.io/UniAD/
现代自动驾驶系统的特点是按顺序执行模块化任务,即感知、预测和规划。为了执行广泛多样的任务并实现高级智能,现代方法要么为单个任务部署独立模型,要么设计具有独立头部的多任务范例。然而,他们可能会遭受累积错误或任务协调不足的困扰。相反,我们认为应该设计和优化一个有利的框架来追求最终目标,即自动驾驶汽车的规划。以此为导向,我们重新审视感知和预测中的关键组成部分,并对任务进行优先排序,以便所有这些任务都有助于规划。我们介绍统一自动驾驶(UniAD),一个最新的综合框架,将全栈驾驶任务整合到一个网络中。它经过精心设计,可以充分利用每个模块的优势,并从全局角度为代理交互提供互补的特征抽象。任务通过统一的查询接口进行通信,以促进彼此进行规划。我们在具有挑战性的 nuScenes 基准测试中实例化了 UniAD。通过广泛的消融,使用这种理念的有效性通过在所有方面都大大优于以前的最先进技术得到证明。
【这篇文章重点看看,看看能蹭多少热度,毕竟是BEST PAPPER】?
动态实例引导自适应:一种测试时域自适应语义分割的向后自由方法?
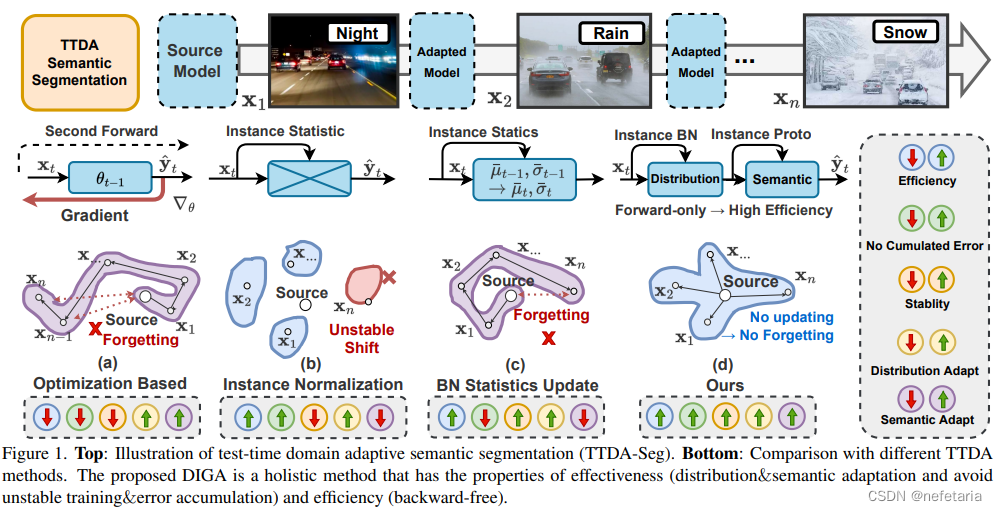
In this paper, we study the application of Test-time domain adaptation in semantic segmentation (TTDA-Seg) where both efficiency and effectiveness are crucial. Existing methods either have low efficiency (e.g., backward optimization) or ignore semantic adaptation (e.g., distribution alignment). Besides, they would suffer from the accumulated errors caused by unstable optimization and abnormal distributions. To solve these problems, we propose a novel backward-free approach for TTDA-Seg, called Dynamically Instance-Guided Adaptation (DIGA). Our principle is utilizing each instance to dynamically guide its own adaptation in a non-parametric way, which avoids the error accumulation issue and expensive optimizing cost. Specifically, DIGA is composed of a distribution adaptation module (DAM) and a semantic adaptation module (SAM), enabling us to jointly adapt the model in two indispensable aspects. DAM mixes the instance and source BN statistics to?encourage the model to capture robust representation. SAM combines the historical prototypes with instance-level prototypes to adjust semantic predictions, which can be associated with the parametric classifier to mutually benefit the final results. Extensive experiments evaluated on five target domains demonstrate the effectiveness and efficiency of the proposed method. Our DIGA establishes new state-of-theart performance in TTDA-Seg. Source code is available at: https://github.com/Waybaba/DIGA.?
在本文中,我们研究了测试时域自适应在语义分割中的应用,其中效率和有效性至关重要。现有方法要么效率低(例如,向后优化),要么忽略语义自适应(例如,分布对齐)。此外,它们还将遭受由不稳定的优化和异常分布引起的累积误差。为了解决这些问题,我们提出了一种新的TTDA Seg的向后自由方法,称为动态实例引导自适应(DIGA)。我们的原理是利用每个实例以非参数的方式动态引导其自身的自适应,这避免了误差累积问题和昂贵的优化成本。具体来说,DIGA由分布自适应模块(DAM)和语义自适应模块(SAM)组成,使我们能够在两个不可或缺的方面对模型进行联合自适应。DAM混合了实例和源BN统计数据,以鼓励模型捕获稳健的表示。SAM将历史原型与实例级原型相结合,以调整语义预测,语义预测可以与参数分类器相关联,从而使最终结果互惠互利。在五个目标域上进行的大量实验验证了该方法的有效性和效率。我们的DIGA在TTDA Seg建立了新的最先进的性能。源代码位于:https://github.com/waybaba/diga.?
3?Rethinking Federated Learning With Domain Shift: A Prototype View
基于领域转换的联合学习反思:原型视角
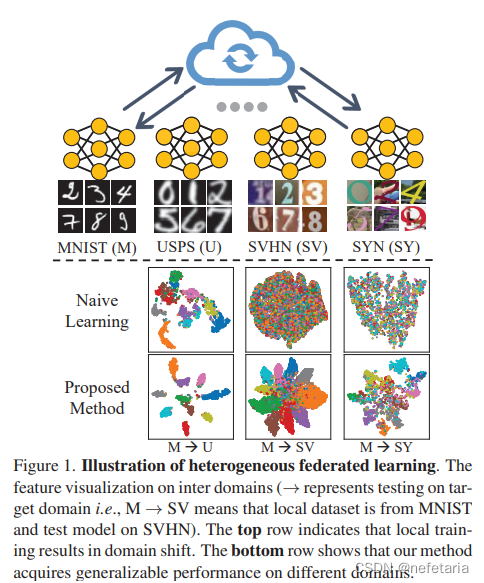
?Federated learning shows a bright promise as a privacypreserving collaborative learning technique. However, prevalent solutions mainly focus on all private data sampled from the same domain. An important challenge is that when distributed data are derived from diverse domains. The private model presents degenerative performance on other domains (with domain shift). Therefore, we expect that the global model optimized after the federated learning process stably provides generalizability performance on multiple domains. In this paper, we propose Federated Prototypes Learning (FPL) for federated learning under domain shift. The core idea is to construct cluster prototypes and unbiased prototypes, providing fruitful domain knowledge and a fair convergent target. On the one hand, we pull the sample embedding closer to cluster prototypes belonging to the same semantics than cluster prototypes from distinct classes. On the other hand, we introduce consistency regularization to align the local instance with the respective unbiased prototype. Empirical results on Digits and Office Caltech tasks demonstrate the effectiveness of the proposed solution and the efficiency of crucial modules.
联合学习作为一种保密的协作学习技术显示出光明的前景。然而,流行的解决方案主要关注从同一域采样的所有私有数据。一个重要的挑战是,当分布式数据来自不同的域时。私有模型在其他域上呈现退化性能(具有域偏移)。因此,我们期望在联合学习过程之后优化的全局模型在多个领域上稳定地提供可推广性性能。在本文中,我们提出了用于领域转移下的联邦学习的联邦原型学习(FPL)。核心思想是构建集群原型和无偏原型,提供富有成果的领域知识和公平的收敛目标。一方面,与来自不同类的集群原型相比,我们将样本嵌入更接近属于相同语义的集群原型。另一方面,我们引入一致性正则化来将局部实例与各自的无偏原型对齐。Digits和Office Caltech任务的实证结果证明了所提出的解决方案的有效性和关键模块的效率。
【联邦学习是一个可以考虑的点,用在遥感无人机图像中合适】
4?HGFormer: Hierarchical Grouping Transformer for Domain Generalized Semantic Segmentation?
HGFormer:用于领域广义语义分割的分层分组转换器?

Current semantic segmentation models have achieved great success under the independent and identically distributed (i.i.d.) condition. However, in real-world applications, test data might come from a different domain than training data. Therefore, it is important to improve model robustness against domain differences. This work studies semantic segmentation under the domain generalization setting, where a model is trained only on the source domain and tested on the unseen target domain. Existing works show that Vision Transformers are more robust than CNNs and show that this is related to the visual grouping property of self-attention. In this work, we propose a novel hierarchical grouping transformer (HGFormer) to explicitly group pixels to form part-level masks and then whole-level masks. The masks at different scales aim to segment out both parts and a whole of classes. HGFormer combines mask classification results at both scales for class label prediction. We assemble multiple interesting cross-domain settings by using seven public semantic segmentation datasets. Experiments show that HGFormer yields more robust semantic segmentation results than per-pixel classification methods and flat-grouping transformers, and outperforms previous methods significantly. Code will be available at https: //github.com/dingjiansw101/HGFormer.
当前的语义分割模型在独立同分布(i.i.d.)条件下取得了巨大的成功。然而,在现实世界的应用程序中,测试数据可能与训练数据来自不同的领域。因此,提高模型对领域差异的鲁棒性是很重要的。这项工作研究了领域泛化设置下的语义分割,其中模型仅在源领域上训练,并在看不见的目标领域上测试。已有研究表明,视觉转换器比细胞神经网络更健壮,这与自我注意的视觉分组特性有关。在这项工作中,我们提出了一种新的分层分组变换器(HGFormer)来显式地对像素进行分组,以形成部分级掩码,然后形成整个级掩码。不同规模的面具旨在将类的部分和整体分割开来。HGFormer将两个尺度上的掩码分类结果相结合,用于类标签预测。我们使用七个公共语义分割数据集来组装多个有趣的跨领域设置。实验表明,与每像素分类方法和平面分组变换器相比,HGFormer产生了更稳健的语义分割结果,并且显著优于以前的方法。代码将在https://github.com/dingjiansw101/HGFormer上提供。
【跑一下这个代码,用ViT做的,看一下这篇文章的国自然项目】
5?Cross-Domain Image Captioning With Discriminative Finetuning
具有判别式微调的跨域图像字幕

Neural captioners are typically trained to mimic humangenerated references without optimizing for any specific communication goal, leading to problems such as the generation of vague captions. In this paper, we show that fine-tuning an out-of-the-box neural captioner with a selfsupervised discriminative communication objective helps to recover a plain, visually descriptive language that is more informative about image contents. Given a target image, the system must learn to produce a description that enables an out-of-the-box text-conditioned image retriever to identify such image among a set of candidates. We experiment with the popular ClipCap captioner, also replicating the main results with BLIP. In terms of similarity to groundtruth human descriptions, the captions emerging from discriminative finetuning lag slightly behind those generated by the non-finetuned model, when the latter is trained and tested on the same caption dataset. However, when the model is used without further tuning to generate captions for out-of-domain datasets, our discriminatively-finetuned captioner generates descriptions that resemble human references more than those produced by the same captioner wihtout finetuning. We further show that, on the Conceptual Captions dataset, discriminatively finetuned captions are more helpful than either vanilla ClipCap captions or ground-truth captions for human annotators tasked with an image discrimination task.1?
神经字幕器通常被训练为模仿人工生成的参考,而不针对任何特定的通信目标进行优化,这会导致诸如模糊字幕的生成等问题。在本文中,我们展示了将开箱即用的神经字幕机与自监督的判别式通信目标进行微调,有助于恢复一种简单、直观的描述性语言,该语言对图像内容的信息更丰富。给定目标图像,系统必须学习生成描述,该描述使得开箱即用的文本条件图像检索器能够在一组候选图像中识别这样的图像。我们用流行的ClipCap字幕进行了实验,也用BLIP复制了主要结果。就与基本事实人类描述的相似性而言,当非微调模型在同一字幕数据集上进行训练和测试时,从有区别的微调中产生的字幕略落后于非微调模型产生的字幕。然而,当在没有进一步调整的情况下使用该模型来为域外数据集生成字幕时,我们的有区别的微调字幕器生成的描述更像人类参考,而不是由相同的字幕器在没有微调的情况下生成的描述。我们进一步表明,在概念字幕数据集上,对于承担图像辨别任务的人类注释者来说,有区别的微调字幕比普通的ClipCap字幕或基本事实字幕更有帮助。1
6?DaFKD: Domain-Aware Federated Knowledge Distillation?
DaFKD:领域感知的联邦知识提取

Federated Distillation (FD) has recently attracted increasing attention for its efficiency in aggregating multiple diverse local models trained from statistically heterogeneous data of distributed clients. Existing FD methods generally treat these models equally by merely computing the average of their output soft predictions for some given input distillation sample, which does not take the diversity across all local models into account, thus leading to degraded performance of the aggregated model, especially when some local models learn little knowledge about the sample. In this paper, we propose a new perspective that treats the local data in each client as a specific domain and design a novel domain knowledge aware federated distillation method, dubbed DaFKD, that can discern the importance of each model to the distillation sample, and thus is able to optimize the ensemble of soft predictions from diverse models. Specifically, we employ a domain discriminator for each client, which is trained to identify the correlation factor between the sample and the corresponding domain. Then, to facilitate the training of the domain discriminator while saving communication costs, we propose sharing its partial parameters with the classification model. Extensive experiments on various datasets and settings show that the proposed method can improve the model accuracy by up to 6.02% compared to state-of-the-art baselines.
联合蒸馏(FD)最近因其在聚合从分布式客户端的统计异构数据中训练的多个不同的局部模型方面的效率而引起了越来越多的关注。现有的FD方法通常只通过计算某些给定输入蒸馏样本的输出软预测的平均值来平等地对待这些模型,这没有考虑所有局部模型的多样性,从而导致聚合模型的性能下降,特别是当一些局部模型对样本知之甚少时。在本文中,我们提出了一种新的视角,将每个客户端中的本地数据视为一个特定的领域,并设计了一种新颖的领域知识感知联合蒸馏方法,称为DaFKD,该方法可以识别每个模型对蒸馏样本的重要性,从而能够优化来自不同模型的软预测集合。具体来说,我们为每个客户端使用一个域鉴别器,该鉴别器经过训练以识别样本和相应域之间的相关因素。然后,为了便于域鉴别器的训练,同时节省通信成本,我们建议将其部分参数与分类模型共享。在各种数据集和设置上的大量实验表明,与最先进的基线相比,所提出的方法可以将模型精度提高6.02%。
7?Style Projected Clustering for Domain Generalized Semantic Segmentation
用于领域广义语义分割的风格投影聚类

Existing semantic segmentation methods improve generalization capability, by regularizing various images to a canonical feature space. While this process contributes to generalization, it weakens the representation inevitably. In contrast to existing methods, we instead utilize the difference between images to build a better representation space, where the distinct style features are extracted and stored as the bases of representation. Then, the generalization to unseen image styles is achieved by projecting features to this known space. Specifically, we realize the style projection as a weighted combination of stored bases, where the similarity distances are adopted as the weighting factors. Based on the same concept, we extend this process to the decision part of model and promote the generalization of semantic prediction. By measuring the similarity distances to semantic bases (i.e., prototypes), we replace the common deterministic prediction with semantic clustering. Comprehensive experiments demonstrate the advantage of proposed method to the state of the art, up to 3.6% mIoU improvement in average on unseen scenarios. Code and models are available at https://gitee.com/mindspore/ models/tree/master/research/cv/SPC-Net.?
现有的语义分割方法通过将各种图像正则化到规范特征空间来提高泛化能力。虽然这一过程有助于概括,但它不可避免地削弱了代表性。与现有的方法相反,我们利用图像之间的差异来构建更好的表示空间,在该空间中提取并存储不同的风格特征作为表示的基础。然后,通过将特征投影到这个已知空间来实现对看不见的图像样式的泛化。具体来说,我们将风格投影实现为存储基的加权组合,其中相似距离被用作加权因子。基于相同的概念,我们将这一过程扩展到模型的决策部分,促进了语义预测的泛化。通过测量到语义基础(即原型)的相似性距离,我们用语义聚类取代了常见的确定性预测。综合实验证明了所提出的方法对现有技术的优势,在看不见的场景下,平均mIoU提高了3.6%。代码和型号可在 https://gitee.com/mindspore/ models/tree/master/research/cv/SPC-Net.?
8??Revisiting Prototypical Network for Cross Domain Few-Shot Learning
用于跨领域少镜头学习的原型网络修正

Prototypical Network is a popular few-shot solver that aims at establishing a feature metric generalizable to novel few-shot classification (FSC) tasks using deep neural networks. However, its performance drops dramatically when generalizing to the FSC tasks in new domains. In this study, we revisit this problem and argue that the devil lies in the simplicity bias pitfall in neural networks. In specific, the network tends to focus on some biased shortcut features (e.g., color, shape, etc.) that are exclusively sufficient to distinguish very few classes in the meta-training tasks within a pre-defined domain, but fail to generalize across domains as some desirable semantic features. To mitigate this problem, we propose a Local-global Distillation Prototypical Network (LDP-net). Different from the standard Prototypical Network, we establish a two-branch network to classify the query image and its random local crops, respectively. Then, knowledge distillation is conducted among these two branches to enforce their class affiliation consistency. The rationale behind is that since such global-local semantic relationship is expected to hold regardless of data domains, the local-global distillation is beneficial to exploit some cross-domain transferable semantic features for feature metric establishment. Moreover, such local-global semantic consistency is further enforced among different images of the same class to reduce the intra-class semantic variation of the resultant feature. In addition, we propose to update the local branch as Exponential Moving Average (EMA) over training episodes, which makes it possible to better distill cross-episode knowledge and further enhance the generalization performance. Experiments on eight crossdomain FSC benchmarks empirically clarify our argument and show the state-of-the-art results of LDP-net. Code is available in https://github.com/NWPUZhoufei/LDP-Net?
原型网络是一种流行的少镜头求解器,旨在使用深度神经网络建立可推广到新型少镜头分类(FSC)任务的特征度量。然而,当将其推广到新领域中的FSC任务时,其性能会急剧下降。在这项研究中,我们重新审视了这个问题,并认为魔鬼在于神经网络中的简单性偏见陷阱。具体而言,网络倾向于关注一些有偏见的快捷方式特征(例如,颜色、形状等),这些特征完全足以区分预定义域内元训练任务中的极少数类,但无法跨域概括为一些所需的语义特征。为了缓解这个问题,我们提出了一个局部全局蒸馏原型网络(LDP-net)。与标准的原型网络不同,我们建立了一个双分支网络,分别对查询图像及其随机局部作物进行分类。然后,在这两个分支之间进行知识提炼,以增强它们的类隶属一致性。其背后的原理是,由于这种全局-局部语义关系预计无论数据域如何都会保持,因此局部-全局提取有利于利用一些跨域可转移的语义特征来建立特征度量。此外,在同一类的不同图像之间进一步加强这种局部全局语义一致性,以减少结果特征的类内语义变化。此外,我们建议在训练集上将局部分支更新为指数移动平均(EMA),这使得更好地提取跨集知识并进一步提高泛化性能成为可能。在八个跨域FSC基准上的实验从经验上澄清了我们的论点,并展示了LDP网络的最新结果。代码在中可用https://github.com/nwpuzhoufei/ldp-net
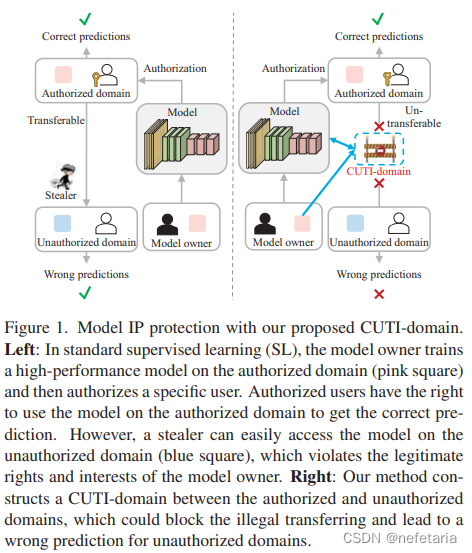
9??Model Barrier: A Compact Un-Transferable Isolation Domain for Model Intellectual Property Protection
模型屏障:模型知识产权保护的一个紧凑的不可转移隔离域
 ??
??
As scientific and technological advancements result from human intellectual labor and computational costs, protecting model intellectual property (IP) has become increasingly important to encourage model creators and owners. Model IP protection involves preventing the use of welltrained models on unauthorized domains. To address this issue, we propose a novel approach called Compact UnTransferable Isolation Domain (CUTI-domain), which acts as a barrier to block illegal transfers from authorized to unauthorized domains. Specifically, CUTI-domain blocks cross-domain transfers by highlighting the private style features of the authorized domain, leading to recognition failure on unauthorized domains with irrelevant private style features. Moreover, we provide two solutions for using CUTI-domain depending on whether the unauthorized domain is known or not: target-specified CUTI-domain and target-free CUTI-domain. Our comprehensive experimental results on four digit datasets, CIFAR10 & STL10, and VisDA-2017 dataset demonstrate that CUTI-domain can be easily implemented as a plug-and-play module with different backbones, providing an efficient solution for model IP protection?
由于科学技术进步源于人类的智力劳动和计算成本,保护模型知识产权对鼓励模型创建者和所有者变得越来越重要。模型IP保护涉及防止在未经授权的域上使用训练有素的模型。为了解决这个问题,我们提出了一种新的方法,称为紧凑的不可传输隔离域(CUTI域),它充当了阻止从授权域到未授权域的非法传输的屏障。具体而言,CUTI域通过突出授权域的私有风格特征来阻止跨域传输,导致对具有无关私有风格特征的未授权域的识别失败。此外,根据未经授权的域是否已知,我们提供了两种使用CUTI域的解决方案:目标指定的CUTI域和无目标的CUTI域名。我们在四位数数据集CIFAR10&STL10和VisDA-2017数据集上的综合实验结果表明,CUTI域可以很容易地实现为具有不同骨干的即插即用模块,为模型IP保护提供了一个有效的解决方案
?10?Towards Professional Level Crowd Annotation of Expert Domain Data
面向专业级的专家领域数据群注释
 ?
?
Image recognition on expert domains is usually finegrained and requires expert labeling, which is costly. This limits dataset sizes and the accuracy of learning systems. To address this challenge, we consider annotating expert data with crowdsourcing. This is denoted as PrOfeSsional lEvel cRowd (POSER) annotation. A new approach, based on semi-supervised learning (SSL) and denoted as SSL with human filtering (SSL-HF) is proposed. It is a human-inthe-loop SSL method, where crowd-source workers act as filters of pseudo-labels, replacing the unreliable confidence thresholding used by state-of-the-art SSL methods. To enable annotation by non-experts, classes are specified implicitly, via positive and negative sets of examples and augmented with deliberative explanations, which highlight regions of class ambiguity. In this way, SSL-HF leverages the strong low-shot learning and confidence estimation ability of humans to create an intuitive but effective labeling experience. Experiments show that SSL-HF significantly outperforms various alternative approaches in several benchmarks.?
专家域上的图像识别通常是细粒度的,并且需要专家标记,这是昂贵的。这限制了数据集的大小和学习系统的准确性。为了应对这一挑战,我们考虑通过众包来注释专家数据。这表示为PrOfeSessional lEvel cRowd(POSER)注释。提出了一种基于半监督学习(SSL)的新方法,称为带人工滤波的SSL(SSL-HF)。这是一种人在环SSL方法,众源工作者充当伪标签的过滤器,取代了最先进的SSL方法使用的不可靠的置信阈值。为了能够由非专家进行注释,类是通过积极和消极的示例集隐式指定的,并通过深思熟虑的解释来增强,这些解释突出了类模糊的区域。通过这种方式,SSL-HF利用人类强大的低阶学习和置信度估计能力,创造直观但有效的标记体验。实验表明,SSL-HF在几个基准测试中显著优于各种替代方法。
【伪标签处理的文章,看一下的】
?11?Learning Adaptive Dense Event Stereo From the Image Domain
从图像域学习自适应密集事件立体
 ?
?
Recently, event-based stereo matching has been studied due to its robustness in poor light conditions. However, existing event-based stereo networks suffer severe performance degradation when domains shift. Unsupervised domain adaptation (UDA) aims at resolving this problem without using the target domain ground-truth. However, traditional UDA still needs the input event data with groundtruth in the source domain, which is more challenging and costly to obtain than image data. To tackle this issue, we propose a novel unsupervised domain Adaptive Dense Event Stereo (ADES), which resolves gaps between the different domains and input modalities. The proposed ADES framework adapts event-based stereo networks from abundant image datasets with ground-truth on the source domain to event datasets without ground-truth on the target domain, which is a more practical setup. First, we propose a self-supervision module that trains the network on the target domain through image reconstruction, while an artifact prediction network trained on the source domain assists in removing intermittent artifacts in the reconstructed image. Secondly, we utilize the feature-level normalization scheme to align the extracted features along the epipolar line. Finally, we present the motion-invariant consistency module to impose the consistent output between the perturbed motion. Our experiments demonstrate that our approach achieves remarkable results in the adaptation ability of event-based stereo matching from the image domain.?
最近,基于事件的立体匹配由于其在弱光条件下的鲁棒性而被研究。然而,当域发生变化时,现有的基于事件的立体声网络的性能会严重下降。无监督域自适应(UDA)旨在解决这一问题,而不使用目标域的地面实况。然而,传统的UDA仍然需要源域中具有地面实况的输入事件数据,这比图像数据更具挑战性和成本更高。为了解决这个问题,我们提出了一种新的无监督域自适应密集事件立体(ADES),它解决了不同域和输入模态之间的差距。所提出的ADES框架将基于事件的立体网络从源域上具有地面实况的丰富图像数据集调整为目标域上没有地面实况的事件数据集,这是一种更实用的设置。首先,我们提出了一个自监督模块,该模块通过图像重建在目标域上训练网络,而在源域上训练的伪影预测网络有助于去除重建图像中的间歇性伪影。其次,我们利用特征级归一化方案将提取的特征沿着核线对齐。最后,我们提出了运动不变一致性模块,以在扰动运动之间施加一致输出。我们的实验表明,我们的方法在基于事件的立体匹配从图像域的自适应能力方面取得了显著的效果。
12?CLIP the Gap: A Single Domain Generalization Approach for Object Detection
CLIP the Gap:一种用于目标检测的单域泛化方法
Single Domain Generalization (SDG) tackles the problem of training a model on a single source domain so that it generalizes to any unseen target domain. While this has been well studied for image classification, the literature on SDG object detection remains almost non-existent. To address the challenges of simultaneously learning robust object localization and representation, we propose to leverage a pre-trained vision-language model to introduce semantic domain concepts via textual prompts. We achieve this via a semantic augmentation strategy acting on the features extracted by the detector backbone, as well as a text-based classification loss. Our experiments evidence the benefits of our approach, outperforming by 10% the only existing SDG object detection method, Single-DGOD [52], on their own diverse weather-driving benchmark.
单域泛化(SDG)解决了在单个源域上训练模型,使其泛化到任何看不见的目标域的问题。虽然这已经在图像分类中得到了很好的研究,但关于SDG目标检测的文献几乎不存在。为了解决同时学习鲁棒对象定位和表示的挑战,我们建议利用预先训练的视觉语言模型,通过文本提示引入语义域概念。我们通过作用于检测器主干提取的特征的语义增强策略以及基于文本的分类损失来实现这一点。我们的实验证明了我们的方法的优势,在其不同的天气驱动基准上,我们的方法比唯一现有的SDG对象检测方法单一DGOD[52]高出10%。
13?AutoLabel: CLIP-Based Framework for Open-Set Video Domain Adaptation
AutoLabel:基于CLIP的开放集视频域自适应框架
Open-set Unsupervised Video Domain Adaptation (OUVDA) deals with the task of adapting an action recognition model from a labelled source domain to an unlabelled target domain that contains "target-private" categories, which are present in the target but absent in the source. In this work we deviate from the prior work of training a specialized open-set classifier or weighted adversarial learning by proposing to use pre-trained Language and Vision Models (CLIP). The CLIP is well suited for OUVDA due to its rich representation and the zero-shot recognition capabilities. However, rejecting target-private instances with the CLIP's zero-shot protocol requires oracle knowledge about the target-private label names. To circumvent the impossibility of the knowledge of label names, we propose AutoLabel that automatically discovers and generates object-centric compositional candidate target-private class names. Despite its simplicity, we show that CLIP when equipped with AutoLabel can satisfactorily reject the target-private instances, thereby facilitating better alignment between the shared classes of the two domains. The code is available.?
开放集无监督视频域自适应(OUVDA)处理将动作识别模型从标记的源域自适应到包含“目标专用”类别的未标记的目标域的任务,这些类别存在于目标中,但不存在于源中。在这项工作中,我们建议使用预先训练的语言和视觉模型(CLIP),从而偏离了先前训练专门的开集分类器或加权对抗性学习的工作。CLIP非常适合OUVDA,因为它具有丰富的表示和零样本识别功能。然而,使用CLIP的零样本协议拒绝目标私有实例需要了解有关目标私有标签名称的oracle知识。为了避免标签名称知识的不可能性,我们提出了自动标签,它可以自动发现并生成以对象为中心的组合候选目标私有类名。尽管它很简单,但我们展示了CLIP在配备AutoLabel时可以令人满意地拒绝目标私有实例,从而促进两个域的共享类之间更好地对齐。代码可用。
【模仿下这个篇文章用CLIP的理由】
14?Domain Generalized Stereo Matching via Hierarchical Visual Transformation
Recently, deep Stereo Matching (SM) networks have shown impressive performance and attracted increasing attention in computer vision. However, existing deep SM networks are prone to learn dataset-dependent shortcuts, which fail to generalize well on unseen realistic datasets. This paper takes a step towards training robust models for the domain generalized SM task, which mainly focuses on learning shortcut-invariant representation from synthetic data to alleviate the domain shifts. Specifically, we propose a Hierarchical Visual Transformation (HVT) network to 1) first transform the training sample hierarchically into new domains with diverse distributions from three levels: Global, Local, and Pixel, 2) then maximize the visual discrepancy between the source domain and new domains, and minimize the cross-domain feature inconsistency to capture domain-invariant features. In this way, we can prevent the model from exploiting the artifacts of synthetic stereo images as shortcut features, thereby estimating the disparity maps more effectively based on the learned robust and shortcut-invariant representation. We integrate our proposed HVT network with SOTA SM networks and evaluate its effectiveness on several public SM benchmark datasets. Extensive experiments clearly show that the HVT network can substantially enhance the performance of existing SM networks in synthetic-to-realistic domain generalization.
近年来,深度立体匹配(SM)网络在计算机视觉中表现出了令人印象深刻的性能,并引起了越来越多的关注。然而,现有的深度SM网络倾向于学习依赖于数据集的快捷方式,无法在看不见的真实数据集上很好地推广。本文朝着训练域广义SM任务的鲁棒模型迈出了一步,该任务主要侧重于从合成数据中学习快捷不变表示,以缓解域偏移。具体而言,我们提出了一种分层视觉变换(HVT)网络:1)首先将训练样本分层变换到具有三个级别的不同分布的新域:全局、局部和像素;2)然后最大化源域和新域之间的视觉差异,并最小化跨域特征的不一致性,以捕获域不变特征。通过这种方式,我们可以防止模型利用合成立体图像的伪影作为快捷特征,从而基于所学习的鲁棒和快捷不变表示更有效地估计视差图。我们将我们提出的HVT网络与SOTA SM网络集成,并在几个公共SM基准数据集上评估其有效性。大量实验清楚地表明,HVT网络可以显著提高现有SM网络在合成到现实领域泛化方面的性能。
15?DA-DETR: Domain Adaptive Detection Transformer With Information Fusion
The recent detection transformer (DETR) simplifies the object detection pipeline by removing hand-crafted designs and hyperparameters as employed in conventional two-stage object detectors. However, how to leverage the simple yet effective DETR architecture in domain adaptive object detection is largely neglected. Inspired by the unique DETR attention mechanisms, we design DA-DETR, a domain adaptive object detection transformer that introduces information fusion for effective transfer from a labeled source domain to an unlabeled target domain. DA-DETR introduces a novel CNN-Transformer Blender (CTBlender) that fuses the CNN features and Transformer features ingeniously for effective feature alignment and knowledge transfer across domains. Specifically, CTBlender employs the Transformer features to modulate the CNN features across multiple scales where the high-level semantic information and the low-level spatial information are fused for accurate object identification and localization. Extensive experiments show that DA-DETR achieves superior detection performance consistently across multiple widely adopted domain adaptation benchmarks.?
最近的检测转换器(DETR)通过去除传统的两级对象检测器中使用的手工设计和超参数,简化了对象检测流水线。然而,如何在域自适应对象检测中利用简单而有效的DETR架构在很大程度上被忽视了。受独特的DETR注意力机制的启发,我们设计了DA-DETR,这是一种域自适应对象检测转换器,它引入了信息融合,用于从标记的源域到未标记的目标域的有效转移。DA-DETR引入了一种新颖的CNN Transformer Blender(CTBLER),它巧妙地融合了CNN特征和Transformer特征,实现了跨领域的有效特征对齐和知识转移。具体地说,CTBlender使用Transformer特征来在多个尺度上调制CNN特征,其中高级语义信息和低级空间信息被融合以用于精确的对象识别和定位。大量实验表明,DA-DETR在多个广泛采用的领域自适应基准上一致地实现了卓越的检测性能。
16?Patch-Mix Transformer for Unsupervised Domain Adaptation: A Game Perspective
Endeavors have been recently made to leverage the vision transformer (ViT) for the challenging unsupervised domain adaptation (UDA) task. They typically adopt the cross-attention in ViT for direct domain alignment. However, as the performance of cross-attention highly relies on the quality of pseudo labels for targeted samples, it becomes less effective when the domain gap becomes large. We solve this problem from a game theory's perspective with the proposed model dubbed as PMTrans, which bridges source and target domains with an intermediate domain. Specifically, we propose a novel ViT-based module called PatchMix that effectively builds up the intermediate domain, i.e., probability distribution, by learning to sample patches from both domains based on the game-theoretical models. This way, it learns to mix the patches from the source and target domains to maximize the cross entropy (CE), while exploiting two semi-supervised mixup losses in the feature and label spaces to minimize it. As such, we interpret the process of UDA as a min-max CE game with three players, including the feature extractor, classifier, and PatchMix, to find the Nash Equilibria. Moreover, we leverage attention maps from ViT to re-weight the label of each patch by its importance, making it possible to obtain more domain-discriminative feature representations. We conduct extensive experiments on four benchmark datasets, and the results show that PMTrans significantly surpasses the ViT-based and CNN-based SoTA methods by +3.6% on Office-Home, +1.4% on Office-31, and +17.7% on DomainNet, respectively. https://vlis2022.github.io/cvpr23/PMTrans?
最近,人们努力利用视觉转换器(ViT)来完成具有挑战性的无监督领域自适应(UDA)任务。它们通常采用ViT中的交叉注意力进行直接域对齐。然而,由于交叉注意力的性能高度依赖于目标样本的伪标签的质量,因此当域间隙变大时,其效果会变差。我们从博弈论的角度解决了这个问题,提出了一个称为PMTrans的模型,该模型将源域和目标域与中间域连接起来。具体而言,我们提出了一种新的基于ViT的模块,称为PatchMix,该模块通过学习基于博弈论模型对两个领域的补丁进行采样,有效地建立了中间领域,即概率分布。通过这种方式,它学习混合来自源域和目标域的补丁,以最大化交叉熵(CE),同时利用特征和标签空间中的两个半监督混合损失将其最小化。因此,我们将UDA的过程解释为一个由三个参与者(包括特征提取器、分类器和PatchMix)组成的最小-最大CE游戏,以找到纳什均衡。此外,我们利用ViT的注意力图,根据其重要性重新加权每个补丁的标签,从而有可能获得更多的领域判别特征表示。我们在四个基准数据集上进行了广泛的实验,结果表明,PMTrans在Office Home上显著优于基于ViT和基于CNN的SoTA方法,分别提高了+3.6%、+1.4%和+17.7%。https://vlis2022.github.io/cvpr23/PMTrans
【大模型相关的,看一下】
17?Upcycling Models Under Domain and Category Shift
Deep neural networks (DNNs) often perform poorly in the presence of domain shift and category shift. How to upcycle DNNs and adapt them to the target task remains an important open problem. Unsupervised Domain Adaptation (UDA), especially recently proposed Source-free Domain Adaptation (SFDA), has become a promising technology to address this issue. Nevertheless, most existing SFDA methods require that the source domain and target domain share the same label space, consequently being only applicable to the vanilla closed-set setting. In this paper, we take one step further and explore the Source-free Universal Domain Adaptation (SF-UniDA). The goal is to identify "known" data samples under both domain and category shift, and reject those "unknown" data samples (not present in source classes), with only the knowledge from standard pre-trained source model. To this end, we introduce an innovative global and local clustering learning technique (GLC). Specifically, we design a novel, adaptive one-vs-all global clustering algorithm to achieve the distinction across different target classes and introduce a local k-NN clustering strategy to alleviate negative transfer. We examine the superiority of our GLC on multiple benchmarks with different category shift scenarios, including partial-set, open-set, and open-partial-set DA. More remarkably, in the most challenging open-partial-set DA scenario, GLC outperforms UMAD by 14.8% on the VisDA benchmark.
?深度神经网络在存在领域转移和类别转移的情况下往往表现不佳。如何升级DNN并使其适应目标任务仍然是一个重要的悬而未决的问题。无监督域自适应(UDA),特别是最近提出的无源域自适应(SFDA),已成为解决这一问题的一种很有前途的技术。然而,大多数现有的SFDA方法要求源域和目标域共享相同的标签空间,因此仅适用于普通闭集设置。在本文中,我们进一步探索了无源通用域自适应(SF-UniDA)。目标是在域和类别转换下识别“已知”数据样本,并拒绝那些“未知”数据样本(不存在于源类中),只使用来自标准预训练源模型的知识。为此,我们引入了一种创新的全局和局部聚类学习技术(GLC)。具体来说,我们设计了一种新的自适应全局聚类算法,以实现不同目标类之间的区分,并引入了一种局部k-NN聚类策略来减轻负迁移。我们检验了我们的GLC在不同类别转换场景的多个基准上的优势,包括偏集、开集和开偏集DA。更值得注意的是,在最具挑战性的开偏集DA-场景中,GLC在VisDA基准上比UMAD高14.8%。
【类别级的,看看这个思路能不能用上?】?
18?Domain Expansion of Image Generators
?Can one inject new concepts into an already trained generative model, while respecting its existing structure and knowledge? We propose a new task -- domain expansion -- to address this. Given a pretrained generator and novel (but related) domains, we expand the generator to jointly model all domains, old and new, harmoniously. First, we note the generator contains a meaningful, pretrained latent space. Is it possible to minimally perturb this hard-earned representation, while maximally representing the new domains? Interestingly, we find that the latent space offers unused, "dormant" axes, which do not affect the output. This provides an opportunity -- by "repurposing" these axes, we are able to represent new domains, without perturbing the original representation. In fact, we find that pretrained generators have the capacity to add several -- even hundreds -- of new domains! Using our expansion technique, one "expanded" model can supersede numerous domain-specific models, without expanding model size. Additionally, using a single, expanded generator natively supports smooth transitions between and composition of domains.
一个人能否在尊重其现有结构和知识的同时,将新概念注入已经训练好的生成模型?我们提出了一个新的任务——域扩展——来解决这个问题。给定一个预训练的生成器和新的(但相关的)域,我们将生成器扩展为和谐地联合建模所有域,无论新旧。首先,我们注意到生成器包含一个有意义的、预先训练的潜在空间。有可能在最大限度地表示新域的同时,最小限度地干扰这种来之不易的表示吗?有趣的是,我们发现潜在空间提供了未使用的“休眠”轴,这些轴不会影响输出。这提供了一个机会——通过“重新调整”这些轴的用途,我们能够在不干扰原始表示的情况下表示新的域。事实上,我们发现经过预训练的生成器有能力添加几个甚至数百个新域!使用我们的扩展技术,一个“扩展”模型可以取代许多特定领域的模型,而无需扩展模型大小。此外,使用单个扩展生成器本机支持域之间的平滑转换和域的组合。
【使用生成模型处理域适应问题的文章,看看怎么借鉴下】
19?
FREDOM: Fairness Domain Adaptation Approach to Semantic Scene Understanding
Although Domain Adaptation in Semantic Scene Segmentation has shown impressive improvement in recent years, the fairness concerns in the domain adaptation have yet to be well defined and addressed. In addition, fairness is one of the most critical aspects when deploying the segmentation models into human-related real-world applications, e.g., autonomous driving, as any unfair predictions could influence human safety. In this paper, we propose a novel Fairness Domain Adaptation (FREDOM) approach to semantic scene segmentation. In particular, from the proposed formulated fairness objective, a new adaptation framework will be introduced based on the fair treatment of class distributions. Moreover, to generally model the context of structural dependency, a new conditional structural constraint is introduced to impose the consistency of predicted segmentation. Thanks to the proposed Conditional Structure Network, the self-attention mechanism has sufficiently modeled the structural information of segmentation. Through the ablation studies, the proposed method has shown the performance improvement of the segmentation models and promoted fairness in the model predictions. The experimental results on the two standard benchmarks, i.e., SYNTHIA -> Cityscapes and GTA5 -> Cityscapes, have shown that our method achieved State-of-the-Art (SOTA) performance.
尽管近年来语义场景分割中的领域自适应有了显著的改进,但领域自适应中的公平问题尚未得到很好的定义和解决。此外,当将分割模型部署到与人类相关的现实世界应用程序(例如自动驾驶)中时,公平性是最关键的方面之一,因为任何不公平的预测都可能影响人类安全。在本文中,我们提出了一种新的用于语义场景分割的公平域自适应(FREDOM)方法。特别是,根据拟议的公平目标,将在公平对待阶级分布的基础上引入一个新的适应框架。此外,为了对结构依赖的上下文进行一般建模,引入了一种新的条件结构约束来增强预测分割的一致性。由于所提出的条件结构网络,自注意机制对分割的结构信息进行了充分的建模。通过消融研究,该方法提高了分割模型的性能,提高了模型预测的公平性。在两个标准基准(即SYNTHIA->Cityscapes和GTA5->Cityscape)上的实验结果表明,我们的方法实现了最先进的性能。
【看看这篇,非常相关】
Domain generalization (DG) is a principal task to evaluate the robustness of computer vision models. Many previous studies have used normalization for DG. In normalization, statistics and normalized features are regarded as style and content, respectively. However, it has a content variation problem when removing style because the boundary between content and style is unclear. This study addresses this problem from the frequency domain perspective, where amplitude and phase are considered as style and content, respectively. First, we verify the quantitative phase variation of normalization through the mathematical derivation of the Fourier transform formula. Then, based on this, we propose a novel normalization method, PCNorm, which eliminates style only as the preserving content through spectral decomposition. Furthermore, we propose advanced PCNorm variants, CCNorm and SCNorm, which adjust the degrees of variations in content and style, respectively. Thus, they can learn domain-agnostic representations for DG. With the normalization methods, we propose ResNet-variant models, DAC-P and DAC-SC, which are robust to the domain gap. The proposed models outperform other recent DG methods. The DAC-SC achieves an average state-of-the-art performance of 65.6% on five datasets: PACS, VLCS, Office-Home, DomainNet, and TerraIncognita.
领域泛化(DG)是评估计算机视觉模型鲁棒性的主要任务。以前的许多研究都对DG使用了归一化。在规范化中,统计和规范化特征分别被视为风格和内容。然而,由于内容和样式之间的边界不清楚,因此在删除样式时会出现内容变化问题。这项研究从频域的角度解决了这个问题,振幅和相位分别被视为风格和内容。首先,我们通过傅立叶变换公式的数学推导来验证归一化的定量相位变化。然后,在此基础上,我们提出了一种新的归一化方法PCNorm,该方法通过谱分解来消除仅作为保留内容的风格。此外,我们提出了先进的PCNorm变体CCNorm和SCNorm,它们分别调整内容和风格的变化程度。因此,他们可以学习DG的领域不可知表示。利用归一化方法,我们提出了对域间隙具有鲁棒性的ResNet变体模型DAC-P和DAC-SC。所提出的模型优于其他最近的DG方法。DAC-SC在五个数据集上实现了65.6%的平均最先进性能:PACS、VLCS、Office Home、DomainNet和TerraIncognita。
21?MIC: Masked Image Consistency for Context-Enhanced Domain Adaptation
In unsupervised domain adaptation (UDA), a model trained on source data (e.g. synthetic) is adapted to target data (e.g. real-world) without access to target annotation. Most previous UDA methods struggle with classes that have a similar visual appearance on the target domain as no ground truth is available to learn the slight appearance differences. To address this problem, we propose a Masked Image Consistency (MIC) module to enhance UDA by learning spatial context relations of the target domain as additional clues for robust visual recognition. MIC enforces the consistency between predictions of masked target images, where random patches are withheld, and pseudo-labels that are generated based on the complete image by an exponential moving average teacher. To minimize the consistency loss, the network has to learn to infer the predictions of the masked regions from their context. Due to its simple and universal concept, MIC can be integrated into various UDA methods across different visual recognition tasks such as image classification, semantic segmentation, and object detection. MIC significantly improves the state-of-the-art performance across the different recognition tasks for synthetic-to-real, day-to-nighttime, and clear-to-adverse-weather UDA. For instance, MIC achieves an unprecedented UDA performance of 75.9 mIoU and 92.8% on GTA-to-Cityscapes and VisDA-2017, respectively, which corresponds to an improvement of +2.1 and +3.0 percent points over the previous state of the art. The implementation is available at https://github.com/lhoyer/MIC.?
在无监督领域自适应(UDA)中,在源数据(例如合成数据)上训练的模型适用于目标数据(例如真实世界),而无需访问目标注释。大多数以前的UDA方法都很难处理在目标域上具有相似视觉外观的类,因为没有基本事实可用于学习轻微的外观差异。为了解决这个问题,我们提出了一个掩蔽图像一致性(MIC)模块,通过学习目标域的空间上下文关系来增强UDA,作为鲁棒视觉识别的额外线索。MIC加强了掩蔽目标图像的预测和伪标签之间的一致性,其中随机补丁被保留,伪标签是由指数移动平均教师基于完整图像生成的。为了最大限度地减少一致性损失,网络必须学会从其上下文推断掩蔽区域的预测。由于其简单而通用的概念,MIC可以集成到不同视觉识别任务(如图像分类、语义分割和对象检测)的各种UDA方法中。MIC显著提高了从合成到真实、从白天到晚上以及从晴朗到恶劣天气的UDA的不同识别任务的最先进性能。例如,MIC在GTA到Cityscapes和VisDA-2017上分别实现了75.9 mIoU和92.8%的前所未有的UDA性能,这与之前的技术水平相比提高了+2.1和+3.0个百分点相对应https://github.com/lhoyer/MIC.
【相关度高,看一下这个】
22?Guiding Pseudo-Labels With Uncertainty Estimation for Source-Free Unsupervised Domain Adaptation
Standard Unsupervised Domain Adaptation (UDA) methods assume the availability of both source and target data during the adaptation. In this work, we investigate Source-free Unsupervised Domain Adaptation (SF-UDA), a specific case of UDA where a model is adapted to a target domain without access to source data. We propose a novel approach for the SF-UDA setting based on a loss reweighting strategy that brings robustness against the noise that inevitably affects the pseudo-labels. The classification loss is reweighted based on the reliability of the pseudo-labels that is measured by estimating their uncertainty. Guided by such reweighting strategy, the pseudo-labels are progressively refined by aggregating knowledge from neighbouring samples. Furthermore, a self-supervised contrastive framework is leveraged as a target space regulariser to enhance such knowledge aggregation. A novel negative pairs exclusion strategy is proposed to identify and exclude negative pairs made of samples sharing the same class, even in presence of some noise in the pseudo-labels. Our method outperforms previous methods on three major benchmarks by a large margin. We set the new SF-UDA state-of-the-art on VisDA-C and DomainNet with a performance gain of +1.8% on both benchmarks and on PACS with +12.3% in the single-source setting and +6.6% in multi-target adaptation. Additional analyses demonstrate that the proposed approach is robust to the noise, which results in significantly more accurate pseudo-labels compared to state-of-the-art approaches.
标准无监督域自适应(UDA)方法假设自适应过程中源数据和目标数据都可用。在这项工作中,我们研究了无源无监督域自适应(SF-UDA),这是UDA的一种特殊情况,其中模型在不访问源数据的情况下自适应到目标域。我们提出了一种基于损失重加权策略的SF-UDA设置的新方法,该策略对不可避免地影响伪标签的噪声具有鲁棒性。分类损失是基于伪标签的可靠性重新加权的,该可靠性是通过估计其不确定性来测量的。在这种重新加权策略的指导下,通过聚集来自相邻样本的知识来逐步细化伪标签。此外,利用自监督对比框架作为目标空间正则化器来增强这种知识聚合。提出了一种新的负对排除策略,即使在伪标签中存在一些噪声的情况下,也可以识别和排除由共享同一类的样本组成的负对。我们的方法在三个主要的基准测试中大大优于以前的方法。我们在VisDA-C和DomainNet上设置了最先进的新SF-UDA,在两个基准测试和PACS上的性能增益均为+1.8%,在单源设置中为+12.3%,在多目标自适应中为+6.6%。额外的分析表明,所提出的方法对噪声是鲁棒的,与最先进的方法相比,这导致了更准确的伪标签。
23?MDL-NAS: A Joint Multi-Domain Learning Framework for Vision Transformer
In this work, we introduce MDL-NAS, a unified framework that integrates multiple vision tasks into a manageable supernet and optimizes these tasks collectively under diverse dataset domains. MDL-NAS is storage-efficient since multiple models with a majority of shared parameters can be deposited into a single one. Technically, MDL-NAS constructs a coarse-to-fine search space, where the coarse search space offers various optimal architectures for different tasks while the fine search space provides fine-grained parameter sharing to tackle the inherent obstacles of multi-domain learning. In the fine search space, we suggest two parameter sharing policies, i.e., sequential sharing policy and mask sharing policy. Compared with previous works, such two sharing policies allow for the partial sharing and non-sharing of parameters at each layer of the network, hence attaining real fine-grained parameter sharing. Finally, we present a joint-subnet search algorithm that finds the optimal architecture and sharing parameters for each task within total resource constraints, challenging the traditional practice that downstream vision tasks are typically equipped with backbone networks designed for image classification. Experimentally, we demonstrate that MDL-NAS families fitted with non-hierarchical or hierarchical transformers deliver competitive performance for all tasks compared with state-of-the-art methods while maintaining efficient storage deployment and computation. We also demonstrate that MDL-NAS allows incremental learning and evades catastrophic forgetting when generalizing to a new task.
?在这项工作中,我们介绍了MDL-NAS,这是一个统一的框架,它将多个视觉任务集成到一个可管理的超网中,并在不同的数据集域下共同优化这些任务。MDL-NAS具有存储效率,因为具有大多数共享参数的多个模型可以存放在一个模型中。从技术上讲,MDL-NAS构建了一个从粗到细的搜索空间,其中粗搜索空间为不同的任务提供了各种最佳架构,而细搜索空间提供了细粒度的参数共享,以解决多领域学习的固有障碍。在精细搜索空间中,我们提出了两种参数共享策略,即顺序共享策略和掩码共享策略。与以往的工作相比,这两种共享策略允许在网络的每一层部分共享和不共享参数,从而实现了真正的细粒度参数共享。最后,我们提出了一种联合子网搜索算法,该算法在总资源约束下为每个任务找到最佳架构和共享参数,挑战了下游视觉任务通常配备用于图像分类的骨干网络的传统做法。通过实验,我们证明,与最先进的方法相比,配备了非分层或分层转换器的MDL-NAS系列在所有任务中都能提供有竞争力的性能,同时保持高效的存储部署和计算。我们还证明,MDL-NAS允许增量学习,并在推广到新任务时避免灾难性遗忘。
【大模型增量学习相关,看一看】
24?OSAN: A One-Stage Alignment Network To Unify Multimodal Alignment and Unsupervised Domain Adaptation
Extending from unimodal to multimodal is a critical challenge for unsupervised domain adaptation (UDA). Two major problems emerge in unsupervised multimodal domain adaptation: domain adaptation and modality alignment. An intuitive way to handle these two problems is to fulfill these tasks in two separate stages: aligning modalities followed by domain adaptation, or vice versa. However, domains and modalities are not associated in most existing two-stage studies, and the relationship between them is not leveraged which can provide complementary information to each other. In this paper, we unify these two stages into one to align domains and modalities simultaneously. In our model, a tensor-based alignment module (TAL) is presented to explore the relationship between domains and modalities. By this means, domains and modalities can interact sufficiently and guide them to utilize complementary information for better results. Furthermore, to establish a bridge between domains, a dynamic domain generator (DDG) module is proposed to build transitional samples by mixing the shared information of two domains in a self-supervised manner, which helps our model learn a domain-invariant common representation space. Extensive experiments prove that our method can achieve superior performance in two real-world applications. The code will be publicly available.
从单一模式扩展到多模式是无监督领域自适应(UDA)的一个关键挑战。在无监督的多模式领域自适应中出现了两个主要问题:领域自适应和模态对齐。处理这两个问题的直观方法是在两个独立的阶段完成这些任务:调整模态,然后进行领域自适应,反之亦然。然而,在大多数现有的两阶段研究中,领域和模式并不相关,它们之间的关系也没有得到充分利用,从而可以相互提供补充信息。在本文中,我们将这两个阶段统一为一个阶段,以同时调整领域和模式。在我们的模型中,提出了一个基于张量的对齐模块(TAL)来探索域和模态之间的关系。通过这种方式,领域和模式可以充分互动,并引导它们利用互补信息以获得更好的结果。此外,为了在域之间建立桥梁,提出了一个动态域生成器(DDG)模块,通过以自监督的方式混合两个域的共享信息来构建过渡样本,这有助于我们的模型学习域不变的公共表示空间。大量实验证明,我们的方法可以在两个真实世界的应用中获得优越的性能。该代码将公开。
Unsupervised Domain Adaptation (UDA) of semantic segmentation transfers labeled source knowledge to an unlabeled target domain by relying on accessing both the source and target data. However, the access to source data is often restricted or infeasible in real-world scenarios. Under the source data restrictive circumstances, UDA is less practical. To address this, recent works have explored solutions under the Source-Free Domain Adaptation (SFDA) setup, which aims to adapt a source-trained model to the target domain without accessing source data. Still, existing SFDA approaches use only image-level information for adaptation, making them sub-optimal in video applications. This paper studies SFDA for Video Semantic Segmentation (VSS), where temporal information is leveraged to address video adaptation. Specifically, we propose Spatio-Temporal Pixel-Level (STPL) contrastive learning, a novel method that takes full advantage of spatio-temporal information to tackle the absence of source data better. STPL explicitly learns semantic correlations among pixels in the spatio-temporal space, providing strong self-supervision for adaptation to the unlabeled target domain. Extensive experiments show that STPL achieves state-of-the-art performance on VSS benchmarks compared to current UDA and SFDA approaches. Code is available at: https://github.com/shaoyuanlo/STPL
语义分割的无监督领域自适应(UDA)通过访问源数据和目标数据,将标记的源知识转移到未标记的目标领域。然而,在现实世界中,对源数据的访问往往受到限制或不可行。在源数据限制的情况下,UDA不太实用。为了解决这一问题,最近的工作探索了无源域自适应(SFDA)设置下的解决方案,该设置旨在在不访问源数据的情况下将源训练模型自适应到目标域。尽管如此,现有的SFDA方法仅使用图像级信息进行自适应,使其在视频应用中处于次优状态。本文研究了用于视频语义分割(VSS)的SFDA,其中利用时间信息来解决视频自适应问题。具体而言,我们提出了时空像素级(STPL)对比学习,这是一种充分利用时空信息的新方法,可以更好地解决缺乏源数据的问题。STPL显式学习时空空间中像素之间的语义相关性,为适应未标记的目标域提供强大的自我监督。大量实验表明,与当前的UDA和SFDA方法相比,STPL在VSS基准测试上实现了最先进的性能。代码位于:https://github.com/shaoyuanlo/STPL
26?Semi-Supervised Domain Adaptation With Source Label Adaptation
Semi-Supervised Domain Adaptation (SSDA) involves learning to classify unseen target data with a few labeled and lots of unlabeled target data, along with many labeled source data from a related domain. Current SSDA approaches usually aim at aligning the target data to the labeled source data with feature space mapping and pseudo-label assignments. Nevertheless, such a source-oriented model can sometimes align the target data to source data of the wrong classes, degrading the classification performance. This paper presents a novel source-adaptive paradigm that adapts the source data to match the target data. Our key idea is to view the source data as a noisily-labeled version of the ideal target data. Then, we propose an SSDA model that cleans up the label noise dynamically with the help of a robust cleaner component designed from the target perspective. Since the paradigm is very different from the core ideas behind existing SSDA approaches, our proposed model can be easily coupled with them to improve their performance. Empirical results on two state-of-the-art SSDA approaches demonstrate that the proposed model effectively cleans up the noise within the source labels and exhibits superior performance over those approaches across benchmark datasets. Our code is available at https://github.com/chu0802/SLA.
半监督域自适应(SSDA)涉及学习用一些标记的和许多未标记的目标数据以及来自相关域的许多标记的源数据对看不见的目标数据进行分类。当前的SSDA方法通常旨在通过特征空间映射和伪标签分配将目标数据与标记的源数据对齐。然而,这种面向源的模型有时会将目标数据与错误类的源数据对齐,从而降低分类性能。本文提出了一种新的源自适应范式,使源数据与目标数据相匹配。我们的关键思想是将源数据视为理想目标数据的噪声标记版本。然后,我们提出了一个SSDA模型,该模型借助于从目标角度设计的强大的清洁器组件来动态地清除标签噪声。由于该范式与现有SSDA方法背后的核心思想非常不同,我们提出的模型可以很容易地与它们相结合,以提高它们的性能。对两种最先进的SSDA方法的经验结果表明,所提出的模型有效地清除了源标签内的噪声,并在基准数据集上表现出优于这些方法的性能。我们的代码可在https://github.com/chu0802/SLA.
一下内容之后整理到对的地方
看看这篇2019的一篇论文:?
Drivingstereo: A large-scale dataset for stereo matching in autonomous driving scenarios.
补充:CVPR2022 :
Class-Balanced Pixel-Level Self-Labeling for Domain Adaptive Semantic Segmentation?
Domain adaptive semantic segmentation aims to learn a model with the supervision of source domain data, and produce satisfactory dense predictions on unlabeled target domain. One popular solution to this challenging task is self-training, which selects high-scoring predictions on target samples as pseudo labels for training. However, the produced pseudo labels often contain much noise because the model is biased to source domain as well as majority categories. To address the above issues, we propose to di-rectly explore the intrinsic pixel distributions of target do-main data, instead of heavily relying on the source domain. Specifically, we simultaneously cluster pixels and rectify pseudo labels with the obtained cluster assignments. This process is done in an online fashion so that pseudo labels could co-evolve with the segmentation model without extra training rounds. To overcome the class imbalance problem on long-tailed categories, we employ a distribution align-ment technique to enforce the marginal class distribution of cluster assignments to be close to that of pseudo labels. The proposed method, namely Class-balanced Pixel-level Self-Labeling (CPSL), improves the segmentation performance on target domain over state-of-the-arts by a large margin, especially on long-tailed categories. The source code is available at ht tps: / / gi thub. com/lslrh/CPSL.?
域自适应语义分割旨在在源域数据的监督下学习模型,并在未标记的目标域上产生令人满意的密集预测。这项具有挑战性的任务的一个流行解决方案是自训练,它选择目标样本上的高分预测作为训练的伪标签。然而,由于模型偏向于源域和大多数类别,因此生成的伪标签通常包含大量噪声。为了解决上述问题,我们建议直接探索目标do主数据的内在像素分布,而不是严重依赖于源域。具体来说,我们同时对像素进行聚类,并用获得的聚类分配校正伪标签。这一过程是以在线方式完成的,因此伪标签可以与分割模型共同进化,而无需额外的训练回合。为了克服长尾类别上的类不平衡问题,我们使用分布对齐技术来强制集群分配的边际类分布接近伪标签的边缘类分布。所提出的方法,即类平衡像素级自标记(CPSL),大大提高了目标域的分割性能,特别是在长尾类别上。源代码可在ht-tps://gi thub获得。com/lslrh/CPSL。?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【Docker】如何编写Dockerfile,深入理解 Dockerfile:构建精简且高效的容器镜像
- 【ROS2】ROS2使用C++实现简单服务端
- UniApp调试支付宝沙箱(安卓)
- 笨蛋学Java-基础复习
- 25、新加坡南洋理工、新加坡国立大学提出FBCNet:完美融合FBCSP的CNN,EEG解码SOTA水准![抱歉老师,我太想进步了!]
- 第12章_集合框架(Collection接口,Iterator接口,List,Set,Map,Collections工具类)
- 9个简单有效的用户需求分析方法,让你的产品更符合用户心理预期
- 恭喜:ChatGPT之父与相恋多年的男友结婚,并希望早日生娃。。。
- 遥感论文 | ISPRS | 图神经网络也能做城市街道功能感知?纯视觉方案,效果可观!
- 精华整理几十个Python数据科学、机器学习、深度学习、神经网络、人工智能方面的核心库以及详细使用实战案例,轻松几行代码训练自己的专有人工智能模型