MySql 性能优化神器之 explain 详解
目录
一. 前言
? ? 数据库是程序员必备的一项基本技能,基本每次面试必问。对于刚出校门的程序员,你只要学会如何使用就行了,但越往后工作越发现,仅仅会写 sql 语句是万万不行的。写出的 sql,如果性能不好,达不到要求,可能会阻塞整个系统,那对于整个系统来讲是致命的。
? ? 所以如何判断你的 sql 写的好不好呢?毕竟只有先知道 sql 写的好不好,才能再去考虑如何优化的问题。MySql 官方就给我们提供了很多 sql 分析的工具,这里我们主要说一下 EXPLAIN。
以下是基于 MySQL5.7.28 版本进行分析的,不同版本之间略有差异。

二. explain 详解
2.1. 概念
? ? 使用 EXPLAIN 关键字可以模拟优化器执行 sql 语句,从而知道 MySql 是如何处理你的语句,分析你的查询语句或者表结构的性能瓶颈。
用法:EXPLAIN + sql 语句
EXPLAIN 执行后返回的信息如下:

各个字段的大致含义如下:
| 字段 | 含义 |
|---|---|
| id | SELECT 查询的标识符。每个 SELECT 都会自动分配一个唯一的标识符 |
| select_type | SELECT 查询的类型。 |
| table | 查询的是哪个表 |
| partitions | 匹配的分区 |
| type | join 类型 |
| possible_keys | 此次查询中可能选用的索引 |
| key | 此次查询中确切使用到的索引 |
| ken_len | 查询优化器使用了索引的字节数 |
| ref | 哪个字段或常数与 key 一起被使用 |
| rows | 显示此查询一共扫描了多少行。这个是一个估计值 |
| filtered | 表示此查询条件所过滤的数据的百分比 |
| Extra | 额外的信息 |
2.2. 数据准备
新建一个数据库 test,执行下面的 sql 语句:
CREATE TABLE t1(id INT(10) AUTO_INCREMENT,content VARCHAR(100) NULL , PRIMARY KEY (id));
CREATE TABLE t2(id INT(10) AUTO_INCREMENT,content VARCHAR(100) NULL , PRIMARY KEY (id));
CREATE TABLE t3(id INT(10) AUTO_INCREMENT,content VARCHAR(100) NULL , PRIMARY KEY (id));
CREATE TABLE t4(id INT(10) AUTO_INCREMENT,content VARCHAR(100) NULL , PRIMARY KEY (id));
INSERT INTO t1(content) VALUES(CONCAT('t1_',FLOOR(1+RAND()*1000)));
INSERT INTO t2(content) VALUES(CONCAT('t2_',FLOOR(1+RAND()*1000)));
INSERT INTO t3(content) VALUES(CONCAT('t3_',FLOOR(1+RAND()*1000)));
INSERT INTO t4(content) VALUES(CONCAT('t4_',FLOOR(1+RAND()*1000)));下面一一解释各列的含义。
2.3. id
? ? select 查询的序列号,包含一组数字,表示查询中执行 select 子句的顺序或操作表的顺序。大致分为下面几种情况:
2.3.1.?id 相同,执行顺序由上至下

上面的查询语句,三个 id 都为1,具有相同的优先级,执行顺序由上而下,具体执行顺序由优化器决定,这里执行顺序为 t1,t2,t3。
2.3.2.?id 不同,数字越大优先级越高

如果 sql 中存在子查询,那么 id 的序号会递增,id 越大越先被执行。如上图,执行顺序是 t3、t1、t2,也就是说,最里面的子查询最先执行,由里往外执行。
在我测试的时候,无意中发现,下面的语句,一个使用的是 IN 关键字,一个使用的 = 运算符,但使用 EXPLAIN 执行后,结果天壤之别。
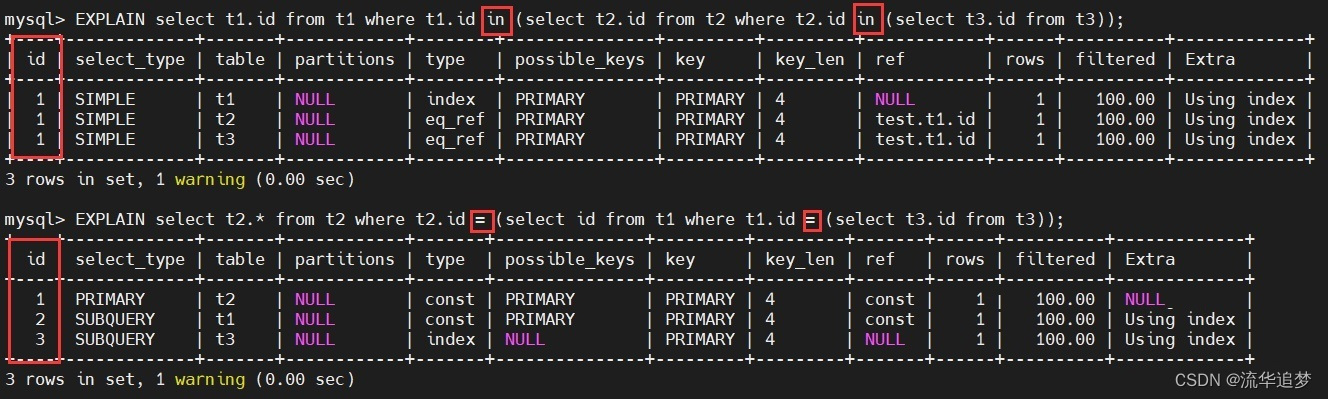
这说明使用 IN 嵌套子查询,它是按顺序来执行的,也就是说每执行一次最外层子查询,里面的子查询都会被重复执行,这好像和我的理解差很多啊(我一直以为是先执行最里面的子查询,再执行外面的)。
注:千万别用 IN,使用 JOIN 或者 EXISTS 代替它。
2.3.3.?id 存在相同的和不同的
在上面语句的基础上,增加一个 IN 的子查询,执行结果如下:

执行顺序为 t3、t1、t2、t4。值越大的越先执行,相同值的从上往下执行。
2.4. select_type
? ? select_type 表示查询的类型,主要是为了区分普通查询、子查询、联合查询等复杂查询。分为以下几种类型:
| 查询类型 | 含义 |
|---|---|
| SIMPLE | 简单的 select 查询,查询中不包含子查询或者 UNION。 |
| PRIMARY | 查询中若包含任何复杂的子查询,那么最外层的查询被标记为 PRIMARY。 |
| DERIVED | 在 from 子句中包含的子查询被标记为 DERIVED(衍生),MySql 会递归执行这些子查询,把结果放在临时表中。 |
| SUBQUERY | 在 select 或 where 子句中包含了子查询,该子查询被标记为 SUBQUERY。 |
| UNION | 若第二个 select 查询语句出现在 UNION 之后,则被标记为 UNION。若 UNION 包含在 FROM 子句的子查询中,外层 SELECT 将被标记为:DERIVED |
| UNION RESULT | 从 UNION 表获取结果的 SELECT。 |
上面的前三种在上一小节已经出现过了,看看后面这三种:

可以看到 id 列出现了一个 NULL,这是上面没讲到的。一般来说,特殊情况下,如果某行语句引用了其他多行结果集的并集,则该值可以为 NULL。
2.5. table
? ? 这个没啥好讲的,表示这个查询是基于哪种表的。并不一定是真实存在的表,比如上面出现的DERIVED 和 <union1,2>,一般来说会出现下面的取值:
- <union a,b>:输出结果中编号为 a 的行与编号为 b 的行的结果集的并集。
- <derived a>:输出结果中编号为 a 的行的结果集,derived 表示这是一个派生结果集,如 FROM 子句中的查询。
- <subquery a>:输出结果中编号为 a 的行的结果集,subquery 表示这是一个物化子查询。
2.6. partitions
? ? 查询时匹配到的分区信息,对于非分区表值为 NULL,当查询的是分区表时,partitions 显示分区表命中的分区情况。
根据官方文档,在创建表的时候,指定不同分区存放的 id 值范围不同:
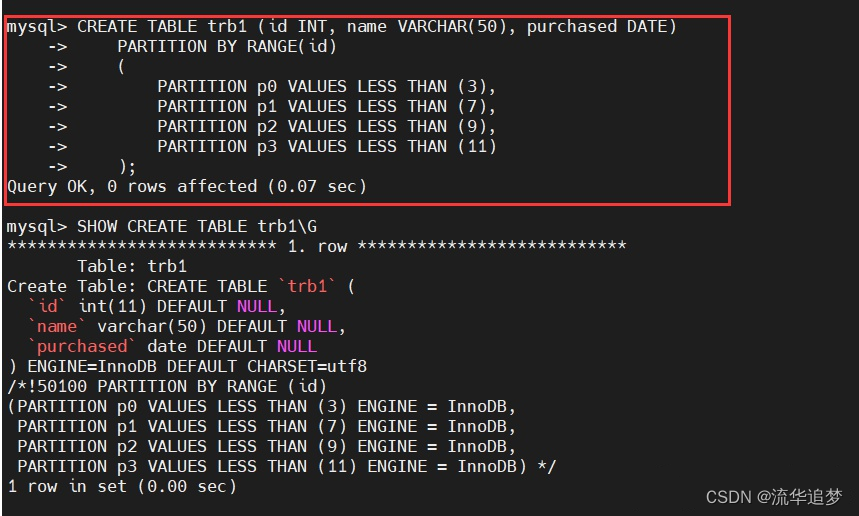
插入测试数据,让 id 值分布在四个分区内:
INSERT INTO trb1 VALUES
(1, 'desk organiser', '2003-10-15'),
(2, 'CD player', '1993-11-05'),
(3, 'TV set', '1996-03-10'),
(4, 'bookcase', '1982-01-10'),
(5, 'exercise bike', '2004-05-09'),
(6, 'sofa', '1987-06-05'),
(7, 'popcorn maker', '2001-11-22'),
(8, 'aquarium', '1992-08-04'),
(9, 'study desk', '1984-09-16'),
(10, 'lava lamp', '1998-12-25');?执行查询输出结果:
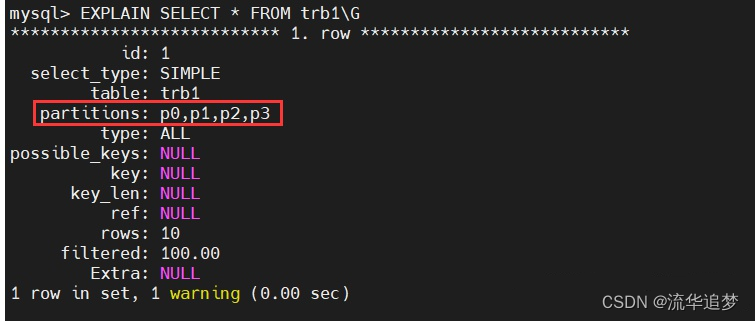

2.7. type
? ? type 是查询的访问类型,是较为重要的一个指标,性能从最好到最坏依次是 system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL。
一般来说,得保证查询至少到达 range 级别,最好能达到 ref。
2.7.1. system
当表仅存在一行记录时(系统表),数据量很少,速度很快,这是一种很特殊的情况,不常见。
2.7.2.?const
当你的查询条件是一个主键或者唯一索引(UNION INDEX)并且值是常量的时候,查询速度非常快,因为只需要读一次表。


2.7.3.?eq_ref
? ? 除了 system 和 const,性能最好的就是 eq_ref 了。唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描。

2.7.4. ref
? ? 非唯一性索引扫描,返回匹配某个单独值的所有行。区别于 eq_ref,ref 表示使用除 PRIMARY KEY 和 UNIQUE index 之外的索引,即非唯一索引,查询的结果可能有多个。可以使用 = 运算符或者 <=> 运算符。
在 t2 表的 content 列加上普通索引:
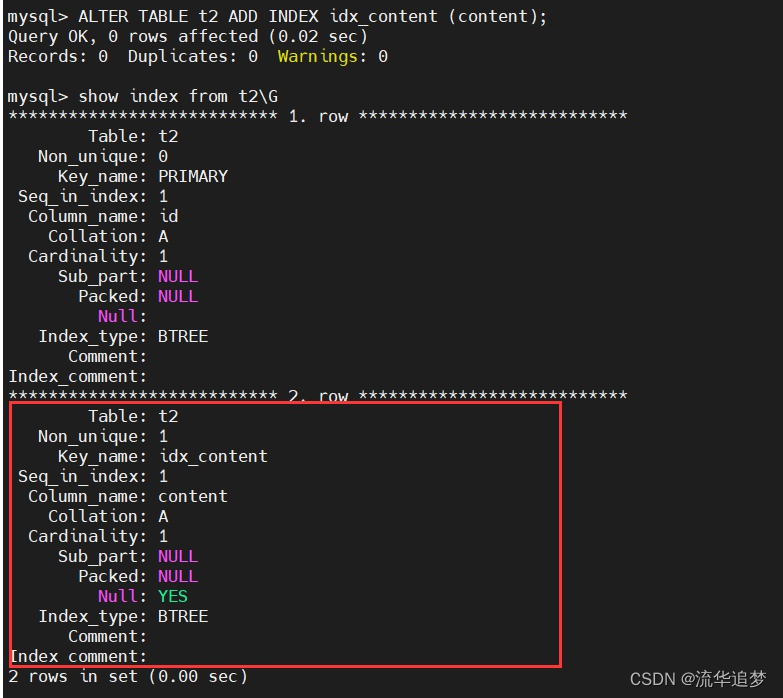
进行查询:

2.7.5.?fulltext
查询时使用 fulltext 索引。
2.7.6.?ref_or_null
对于某个字段既需要关联条件,也需要 null 值的情况下。查询优化器会选择用 ref_or_null 连接查询。

2.7.7.?index_merge
在查询过程中需要多个索引组合使用,通常出现在有 or 关键字的 sql 中。
2.7.8.?unique_subquery
? ? 该联接类型类似于 index_subquery。子查询中的唯一索引。在某些 in 子查询里,用于替换eq_ref,比如下面的查询语句:
value IN (SELECT primary_key FROM single_table WHERE some_expr)
2.7.9.?index_subquery
? ? 利用索引来关联子查询,不再全表扫描。用于非唯一索引,子查询可以返回重复值。类似于unique_subquery,但用于非唯一索引。比如下面的查询语句:
value IN (SELECT key_column FROM single_table WHERE some_expr)
2.7.10.?range
? ? 只检索给定范围的行,使用一个索引来选择行。key 列显示使用了哪个索引,一般就是在你的where 语句中出现了 between、<、>、in 等的查询,这种范围扫描索引扫描比全表扫描要好,因为它只需要开始于索引的某一点,而结束语另一点,不用扫描全部索引。
举个例子,t3 表中 id 字段为主键,有 PRIMARY 索引,content 字段没有建立索引,查询时使用 id 作为条件,结果如下:

使用 content 作为条件,结果如下:

所以,只有对设置了索引的字段,做范围检索 type 才是 range。
2.7.11.?index
? ? sql 语句使用了索引,但没有通过索引进行过滤,一般是使用了覆盖索引或者利用索引进行了排序分组。
? ? index 和 ALL 都是读全表,区别在于 index 是遍历索引树读取,ALL 是从硬盘读取。index 通常比 ALL 更快,因为索引文件通常比数据文件小。
举个例子,查询 t3 表主键 id,结果如下:

2.7.12. ALL
全表扫描,性能最差。

2.8.?possible_keys
? ? 查询时可能使用的索引,一个或多个。查询涉及到的字段上若存在索引,则该索引将被列出。注意是可能,实际查询时不一定会用到。
2.9. key
? ? 查询时实际使用的索引,没有使用索引则为 NULL。查询时若使用了覆盖索引,则该索引只出现在 key 字段中。
举个例子,trb1 表中有一个组合索引(age, name),那么当你的查询列和索引的个数和顺序一致时,查询结果如下:

2.10.?key_len
? ? 表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好。
? ? key_len 显示的值是索引字段可能的最大长度,并非实际使用长度,即 key_len 是根据表定义计算得到,不是通过表内检索。
? ? key_len 字段能够帮你检查是否充分的利用上了索引。ken_len 越长,说明索引使用的越充分。
注意:key_len 只计算 where 条件中用到的索引长度,而排序和分组即便是用到了索引,也不会计算到 key_len 中。
举个例子,有表 trb1,存在以下字段,以及一个组合索引 idx_age_name:

下面查询语句的执行结果:



key_len 的值为153、158、null。如何计算:
- 先看索引上字段的类型+长度。比如 int=4; varchar(50) = 50; char(50) = 50。
- 如果是 varchar 或者 char 这种字符串字段,视字符集要乘不同的值,比如 utf-8 要乘3,GBK 要乘2。
- varchar 这种动态字符串要加 2 个字节。
- 允许为空的字段要加 1 个字节。
第一条:key_len = name 的字节长度 = 50 * 3 + 2 + 1 = 153。
第二条:key_len = age 的字节长度 + name 的字节长度= 4 +1 + (50*3 + 2 + 1)= 5 + 153 = 158。(使用的索引更充分,查询结果更精确,但消耗更大)。
第三条:索引失效了。
| 列类型 | key_len | 备注 |
|---|---|---|
| id int | key_len = 4 + 1 = 5 | 允许 null,加 1 byte |
| id int not null | key_len = 4 | 不允许 null |
| name char(50) utf8 | key_len = 50 * 3 + 1 | 允许 null |
| name varchar(50) not null utf8 | key_len = 50 * 3 + 2 | 动态列类型,加 2 byte |
| name varchar(50) utf8 | key_len = 50 * 3 + 2 + 1 | 动态列类型,加 2 byte,允许 null,加 1 byte |
2.11. ref
显示索引的哪一列被使用了,常见的取值有:const, func,null,字段名。
- 当使用常量等值查询,显示 const;
- 当关联查询时,会显示相应关联表的关联字段;
- 如果查询条件使用了表达式、函数,或者条件列发生内部隐式转换,可能显示为 func;
- 其他情况 null。
举个例子,t3 表的 content 字段有普通索引,下面的查询语句结果如下:

2.12.?rows
rows 列表示 MySql 认为它执行查询时可能需要读取的行数,一般情况下这个值越小越好!
2.13.?filtered
? ? filtered 是一个百分比的值,表示符合条件的记录数的百分比。简单点说,这个字段表示存储引擎返回的数据在经过过滤后,剩下满足条件的记录数量的比例。
? ? 在 MySQL.5.7 版本以前想要显示 filtered 需要使用 explain extended 命令。MySQL.5.7 后,默认 explain 直接显示 partitions 和 filtered 的信息。
2.14. Extra
其他额外的信息。
2.14.1.?Using filesort
? ? 说明 MySql 会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。MySql 中无法利用索引完成的排序操作称为“文件排序”。
举个例子,trb1 表建立一个组合索引:
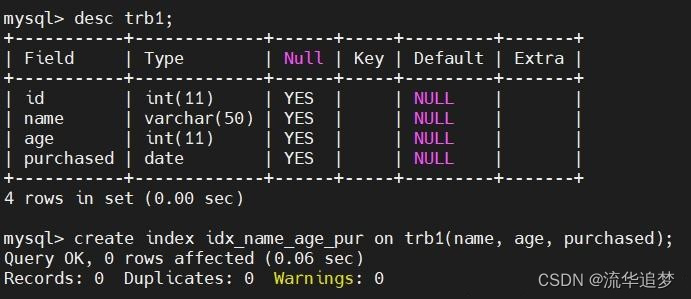
下面的查询出现 filesort:

按照组合索引的顺序,是 name、age、purchased,而上面的查询语句,没有使用中间的 age,所以在 order by 的时候索引失效了。通常这种情况是需要进行优化的。
修改一下上面的 sql 语句,让索引不失效:

2.14.2.?Using temporary
? ? 使了用临时表保存中间结果,MySql 在对查询结果排序时使用临时表。常见于排序 order by 和分组查询 group by。

这条 sql 语句用了临时表,又用了文件排序,在数据量非常大的时候效率是很低的,需要进行优化。

所以在使用 group by 和 order by 的时候,列的数量和顺序尽量和索引的一样。
2.14.3.?Using index
? ? Using index 表示相应的 select 操作中使用了覆盖索引(Covering Index),避免访问了表的数据行,可以提高效率。
? ? 如果同时出现 using where,表明索引被用来执行索引键值的查找。如果没有同时出现 using where,表明索引只是用来读取数据而非利用索引执行查找。
还是使用上面的 trb1 表举例子:

只出现了 Using index,说明索引用来读取数据而不是执行查找。

出现了 Using where,说明索引被用来执行查找。
2.14.4.?Using where
表示查询时有索引被用来进行 where 过滤。
2.14.5.?Using join buffer
查询时使用了连接缓存。
2.14.6.?impossible where
查询语句的 where 条件总是为 false,举个例子:

一般情况下不会出现这种。
关于 Extra 字段,有很多取值,这里就不一一列举了,具体可以看官方文档:《EXPLAIN Output Format》。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- React快速入门
- VMnet1、VMnet8到底是什么?
- Mendeley Word 文献引用
- 毕设之-消息系统设计(websocket+netty)
- Open CASCADE学习|向量运算
- 四、Makefile总述
- 【数据库系统概论】第3章-关系数据库标准语言SQL(3)
- java 发邮件
- 求职开挂-用Chatgpt回答面试官的提问和帮助写代码可行不?
- 已解决java.lang.NoSuchFieldException异常的正确解决方法,亲测有效!!!