pytorch04:网络模型创建
目录
一、模型创建过程

1.1 以LeNet网络为例

网络代码如下:
class LeNet(nn.Module):
def __init__(self, classes):
super(LeNet, self).__init__() # 调用父类方法,作用是调用nn.Module类的构造函数,
# 确保LeNet类被正确地初始化,并继承了nn.Module 的所有属性和方法
self.conv1 = nn.Conv2d(3, 6, 5) # 卷积层
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 全连接层
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, classes)
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.max_pool2d(out, 2)
out = F.relu(self.conv2(out))
out = F.max_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = F.relu(self.fc1(out))
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out
1.2 LeNet结构

LeNet:conv1–>pool1–>conv2–>pool2–>fc1–>fc2–>fc3
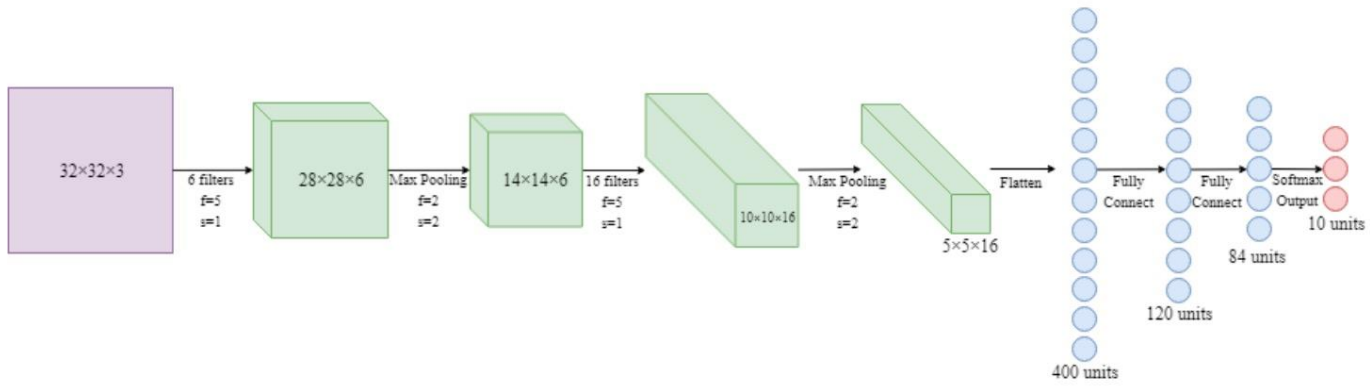
1.3 nn.Module
Module是nn模块中的功能,nn模块还有Parameter、functional等模块。

nn.Module主要有以下参数:
? parameters : 存储管理nn.Parameter类
? modules : 存储管理nn.Module类
? buffers:存储管理缓冲属性,如BN层中的running_mean
二、网络层容器(Containers)

2.1 nn.Sequential
nn.Sequential 是 nn.module的容器,也是最常用的容器,用于按顺序包装一组网络层
? 顺序性:各网络层之间严格按照顺序构建
? 自带forward():自带的forward里,通过for循环依次执行前向传播运算
2.1.1 常规方法实现
LeNet网络由两部分构成,中间的卷积池化特征提取部分(features),以及最后的分类部分(classifier)。

具体代码如下:
class LeNetSequential(nn.Module):
def __init__(self, classes):
super(LeNetSequential, self).__init__()
self.features = nn.Sequential( #特征提取部分
nn.Conv2d(3, 6, 5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, 5),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),)
self.classifier = nn.Sequential( #分类部分
nn.Linear(16*5*5, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, classes),)
def forward(self, x):
x = self.features(x)
x = x.view(x.size()[0], -1)
x = self.classifier(x)
return x
打印网络层:

2.1.2 OrderedDict方法实现
使用有序字典的方法构建Sequential
代码如下:
class LeNetSequentialOrderDict(nn.Module):
def __init__(self, classes):
super(LeNetSequentialOrderDict, self).__init__()
self.features = nn.Sequential(OrderedDict({
'conv1': nn.Conv2d(3, 6, 5),
'relu1': nn.ReLU(inplace=True),
'pool1': nn.MaxPool2d(kernel_size=2, stride=2),
'conv2': nn.Conv2d(6, 16, 5),
'relu2': nn.ReLU(inplace=True),
'pool2': nn.MaxPool2d(kernel_size=2, stride=2),
}))
self.classifier = nn.Sequential(OrderedDict({
'fc1': nn.Linear(16 * 5 * 5, 120),
'relu3': nn.ReLU(),
'fc2': nn.Linear(120, 84),
'relu4': nn.ReLU(inplace=True),
'fc3': nn.Linear(84, classes),
}))
def forward(self, x):
x = self.features(x)
x = x.view(x.size()[0], -1)
x = self.classifier(x)
return x
先看一下Sequential函数中init初始化的两种方法,当我们使用OrderedDict方法时,会进行判断,使用self.add_module(key, module)方法将字典中的key和value取出来添加到Sequential中。
class Sequential(Module):
def __init__(self, *args):
super().__init__()
if len(args) == 1 and isinstance(args[0], OrderedDict):
for key, module in args[0].items():
self.add_module(key, module)
else:
for idx, module in enumerate(args):
self.add_module(str(idx), module)
通过这种方法构建可以给每一网络层添加一个名称,网络输出结果如下:

2.2 nn.ModuleList
nn.ModuleList是 nn.module的容器,用于包装一组网络层,以迭代方式调用网络层
主要方法:
? append():在ModuleList后面添加网络层
? extend():拼接两个ModuleList
? insert():指定在ModuleList中位置插入网络层
使用列表生成式,通过一行代码就能构建20个网络层。
代码演示:
class ModuleList(nn.Module):
def __init__(self):
super(ModuleList, self).__init__()
# 使用列表生成式构建20个全连接层,每个全连接层10个神经元的网络
self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(20)])
def forward(self, x):
for i, linear in enumerate(self.linears):
x = linear(x)
return x
net = ModuleList()
2.3 nn.ModuleDict
nn.ModuleDict是 nn.module的容器,用于包装一组网络层,以索引方式调用网络层,可以用过参数的形式选取想要调用的网络层。
主要方法:
? clear():清空ModuleDict
? items():返回可迭代的键值对(key-value pairs)
? keys():返回字典的键(key)
? values():返回字典的值(value)
? pop():返回一对键值,并从字典中删除
代码展示,只选取conv和relu两个网络层:
class ModuleDict(nn.Module):
def __init__(self):
super(ModuleDict, self).__init__()
self.choices = nn.ModuleDict({
'conv': nn.Conv2d(10, 10, 3),
'pool': nn.MaxPool2d(3)
})
# 激活函数
self.activations = nn.ModuleDict({
'relu': nn.ReLU(),
'prelu': nn.PReLU()
})
def forward(self, x, choice, act): # 传入两个参数 用来选择网络层
x = self.choices[choice](x)
x = self.activations[act](x)
return x
net = ModuleDict()
fake_img = torch.randn((4, 10, 32, 32))
output = net(fake_img, 'conv', 'relu') #只选取conv和relu两个网络层。
print(output)
2.4 三种容器构建总结
? nn.Sequential:顺序性,各网络层之间严格按顺序执行,常用于block构建
? nn.ModuleList:迭代性,常用于大量重复网构建,通过for循环实现重复构建
? nn.ModuleDict:索引性,常用于可选择的网络层
三、AlexNet网络构建
AlexNet:2012年以高出第二名10多个百分点的准确率获得ImageNet分类任务冠军,开创了卷积神经网络的新时代
AlexNet特点如下:
- 采用ReLU:替换饱和激活函数,减轻梯度消失
- 采用LRN(Local Response Normalization):对数据归一化,减轻梯度消失
- Dropout:提高全连接层的鲁棒性,增加网络的泛化能力
- Data Augmentation:TenCrop,色彩修改
网络结构图如下:

构建代码:
import torch.nn as nn
import torch
from torchsummary import summary
# 定义一个名为AlexNet的神经网络模型,继承自nn.Module基类
class AlexNet(nn.Module):
# 构造函数,初始化网络的参数
def __init__(self, num_classes: int = 1000, dropout: float = 0.5) -> None:
# 调用父类的构造函数
super().__init__()
# 定义神经网络的特征提取部分,包含多个卷积层和池化层
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2), # 输入通道3,输出通道64,卷积核大小11x11,步长4,填充2
nn.ReLU(inplace=True), # 使用ReLU激活函数,inplace=True表示原地操作,节省内存
nn.MaxPool2d(kernel_size=3, stride=2), # 最大池化层,核大小3x3,步长2
nn.Conv2d(64, 192, kernel_size=5, padding=2), # 输入通道64,输出通道192,卷积核大小5x5,填充2
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
# 定义自适应平均池化层,将输入的任意大小的特征图池化为固定大小6x6
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
# 定义分类器部分,包含全连接层和Dropout层
self.classifier = nn.Sequential(
nn.Dropout(p=dropout), # 使用Dropout进行正则化,随机丢弃一部分神经元以防止过拟合
nn.Linear(256 * 6 * 6, 4096), # 输入大小为256*6*6,输出大小为4096
nn.ReLU(inplace=True),
nn.Dropout(p=dropout),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes), # 最后的全连接层输出类别数
)
# 前向传播函数,定义数据在网络中的传播过程
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x) # 特征提取
x = self.avgpool(x) # 平均池化
x = torch.flatten(x, 1) # 将特征图展平成一维向量
x = self.classifier(x) # 分类器
return x
if __name__ == '__main__':
net = AlexNet().cuda()
summary(net, (3, 256, 256))
打印出的网络结构图如下:

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Android studio第一次构建项目Gradle失败的解决方法
- 基于极限学习机的曲线分类,基于极限学习机的光谱分类,基于极限学习机的分类预测
- lodash源码分析每日一练 - 数组 - flatten / flattenDeep / flattenDepth
- 【影像组学入门百问】#25--#26
- 云计算:FusionCompute 通过 FreeNAS 添加SAN存储
- 洛谷P5732 【深基5.习7】杨辉三角(C语言)
- 实时仿真四路鱼眼实现2D环视效果
- SpringBoot-SpringBoot启动解析
- 微信小程序使用--如何生成二维码
- Linux:错误E45:“readonly” option is set(add ! to override)及Job for network.service failed because 解决方法