Multimodal Contrastive Training for Visual Representation Learning
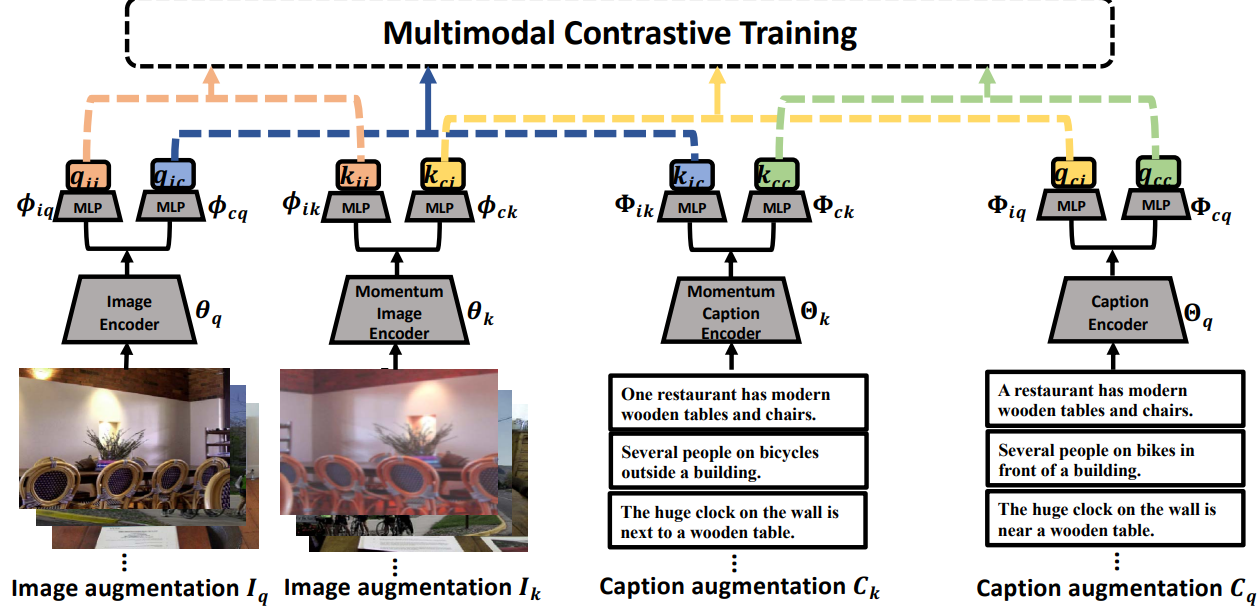
parameterize the image encoder as f
i
q
_{iq}
iq?
query feature q
i
i
_{ii}
ii?,key feature k
i
i
_{ii}
ii?
parameterize the textual encoder as
f
c
q
(
?
;
Θ
q
,
Φ
c
q
)
f_{cq}(·; Θ_q, Φ_{cq})
fcq?(?;Θq?,Φcq?),momentum textual encoder as
f
c
k
(
?
;
Θ
k
,
Φ
i
k
)
f_{ck}(·; Θ_k, Φ_{ik})
fck?(?;Θk?,Φik?).
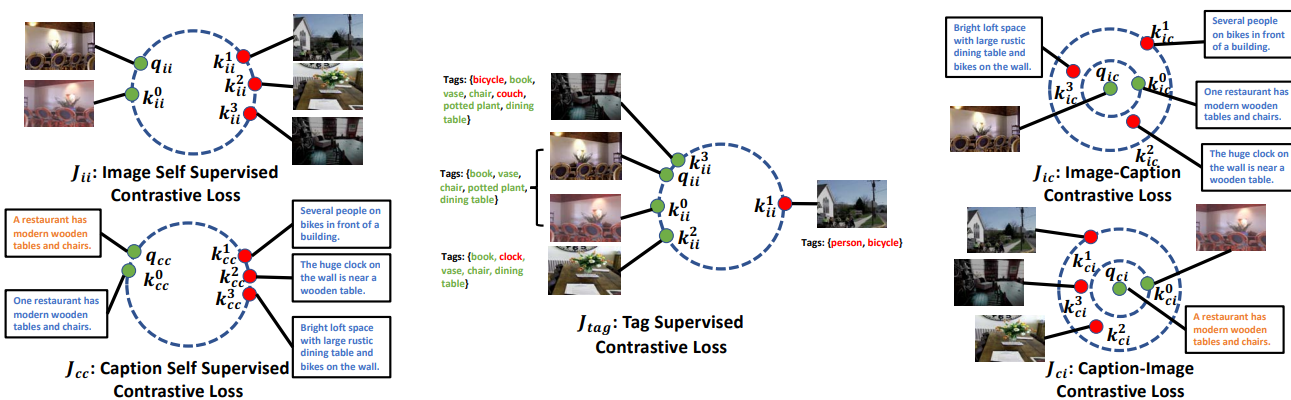
c
j
?
c^?_j
cj??和
c
j
?
c^\star_j
cj??是different augmented examples
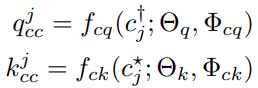
吐槽
第一张图字母下标被黑色背景盖住了,且作者不公布代码,不该是CVPR的“水平”
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2017年认证杯SPSSPRO杯数学建模B题(第一阶段)岁月的印记全过程文档及程序
- 用实例证明函数是go语言的一等公民
- vp与vs联合开发-Ini配置文件
- SQL注入
- 2024 年 20+ 个 Node.js 开发工具
- vcruntime140.dll怎么安装,详细解析vcruntime140.dll安装详情与解决方法
- 【Spring 篇】Spring事务控制:编织代码的魔法丝带
- 塑料检查井产品设计合理、座盖联合周密,为安装维护带来方便
- MySQL 从零开始:06 数据检索
- 第十篇【传奇开心果系列】Ant Design Mobile of React 开发移动应用:涉及到的相关基础知识介绍和示例