【Redis刨析】知识图谱的构建与实现
前言


ChatGPT体验地址

引用
对于编程的学习,过了初级阶段,我认为应该减少对视频的依赖,学习编程,遇到错误,检查搜索错误,然后验证方案,最后解决错误,将每一个错误,每一个丢失在脑袋中的知识点,去形成一个属于自己的知识结构。
对于知识图谱的构建,我相信大家都能够第一时间想到思维导图吧,在这里推荐一个免费的在线工具库:tool 。解决了实操场地,那我们一起来聊聊对于构建过程你是否有体系的方法

构建过程
我认为在整个从接触到精通过程中,我往往把构建过程分为四步
第一步,构图。也就是说我们拿到一个知识点,我们学了一遍之后呢,我们这一个知识点包括了123条内容,就比我刚学java,需要知道java的定义,Java的关键字,符号,语法,面向对象等等,而面向对象里面又有好多内容,比如说特性就有封装,继承,多态,当我们逐渐积累,成长,我们会对一个或一块内容,进行查漏补缺,我把它称为第二步,补图。第三步我把它称为拆图,逐渐灵活掌握,我们不会把知识的运用局限于某一块内容,通常会形成一个思维定势,我把这个思维定势称为自我高度片面化总结,其实从这里开始,你会发现书本上的知识进入大脑中,都是干货。但是往往发现,你会有总结不完的内容。最后一步,我把它称为挖图,你自己高度片面化总结的知识,进行底层逻辑的深挖,也就是从广度到深度的过程。
相信有很多正在学习的在校生,或者准备面试的应届生,亦或是刚刚步入职场的伙伴。我们这些都在成长路上有共同目标的人,我觉得我们都可以在以上的第三步,互相分享共同进步。
创建了一个分享平台:聚友堂
在这里你可以找到共同进步的伙伴,进行聊天,创建房间,发布帖子,一起来分享吧
Redis的知识图谱构建过程
Redis介绍
我们首先肯定要了解redis的内容是什么
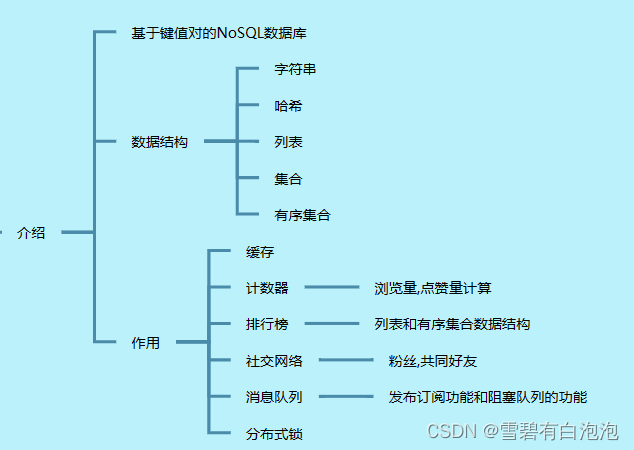
redis是一个基于键值对的NoSQL数据库,你知道NoSQL是什么吗?非关系型数据库说的通俗一点:不是表结构的,而是用数据模型.那这个数据模型支持哪些数据结构呢?字符串,哈希,列表,集合,有序集合(比集合多一个权重). 那既然有这么多种数据结构,具体的作用有:首先是常用的缓存功能,还有计数器,点赞浏览量什么的.还有排行榜,消息队列,分布式等等.
快的原因
我们经常使用redis做缓存是因为它快,那么快的原因是什么呢?
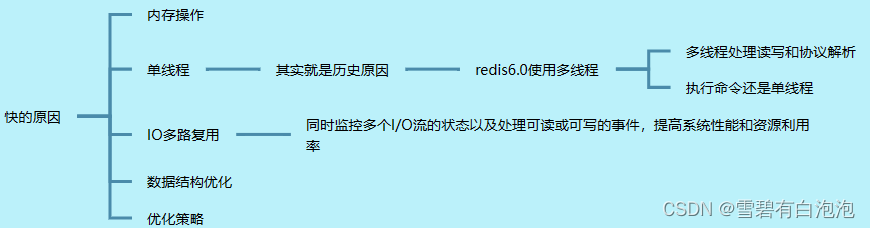
redis的速度十分之快,是mysql的几十倍,首先因为他的对库操作都是完全基于内存操作,其次的话redis在底层使用的数据结构都是优化过的数据结构,可以达到很高的性能,而且使用单线程处理客户端请求,避免了多线程的开销.使用的是IO多路复用.同时监控多个IO流的状态以及处理可读或可写的事件.其实在这个单线程来说,redis的6.0版本处理读写和协议解析使用了多线程,之前的单线程似乎是历史问题,但是执行命令还是单线程.这样的目的肯定是为了进一步提高性能,redis的性能瓶颈在于网络IO,并非CPU,所以使用多线程能提升IO读写的效率.
持久化
我们对于redis已经有了基础的了解,我们来详细了解一下持久化的内容

首先是redis持久化的方法,主要有两种,RDB和AOF.首先RDB就是关系型数据库的存储方法,就是表结构.而AOF是一种以写入命令日志的方式记录数据库的持久化方法,并且提供了可读性和数据恢复.具体的流程为:将所有写入命令追加到缓冲区,缓冲区根据策略同步到硬盘。AOF文件会随着操作越来越大,需要进行重写和压缩。当重新启动Redis时,可以加载AOF文件来恢复数据.至于两个的选择和优缺点来说,RDB适用于资源有限、性能要求高、可接受一定数据丢失的环境,而AOF适用于对数据安全性和完整性要求较高的环境。为了达到MySQL相同安全性可以两者结合使用.前者说到使用AOF进行数据恢复.我们知道redis的启动过程是先加载AOF如何再加载RDB,然后成功启动,那么恢复的过程只需要RDB或者AOF拷贝到数据目录即可恢复,如果是AOF恢复,需要开启AOF然后启动即可.最后,在持久化的选择我们说过可以同时使用,在redis4.0中,结合了两者优点提出了混合持久化机制,总结就是加载RDB内容并重放增量AOF日志
还有很多内容可以私信获取,比如说redis高可用,缓存设计,无底洞问题,运维还有场景问题,在redis知识图谱的过程中,我们从大范围高度片面化总结为一句话或者一段话内容,为我们后续的深挖过程奠定了踏实的基础,
具体的内容可以看下面这本热销书籍
购买链接为:地址
- 🎁本次送书1~3本【取决于阅读量,阅读量越多,送的越多】👈
- ??活动时间:截止到2023-12月31号
- ??参与方式:关注博主+三连(点赞、收藏、评论)

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!