强化学习求解TSP(八):Qlearning求解旅行商问题TSP(提供Python代码)
一、Qlearning简介
Q-learning是一种强化学习算法,用于解决基于奖励的决策问题。它是一种无模型的学习方法,通过与环境的交互来学习最优策略。Q-learning的核心思想是通过学习一个Q值函数来指导决策,该函数表示在给定状态下采取某个动作所获得的累积奖励。
Q-learning的训练过程如下:
1. 初始化Q值函数,将所有状态-动作对的Q值初始化为0。
2. 在每个时间步,根据当前状态选择一个动作。可以使用ε-greedy策略来平衡探索和利用。
3. 执行选择的动作,并观察环境返回的奖励和下一个状态。
4. 根据Q值函数的更新规则更新Q值。Q值的更新公式为:Q(s, a) = Q(s, a) + α * (r + γ * max(Q(s', a')) - Q(s, a)),其中α是学习率,γ是折扣因子,r是奖励,s是当八前状态,a是选择的动作,s'是下一个状态,a'是在下一个状态下选择的动作。
5. 重复步骤2-4,直到达到停止条件。
Q-learning的优点是可以在没有先验知识的情况下自动学习最优策略,并且可以处理连续状态和动作空间。它在许多领域中都有广泛的应用,如机器人控制、游戏策略和交通路线规划等。
二、TSP问题介绍
旅行商问题(Traveling salesman problem, TSP)是一个经典的组合优化问题,它可以描述为一个商品推销员去若干城市推销商品,要求遍历所有城市后回到出发地,目的是选择一个最短的路线。当城市数目较少时,可以使用穷举法求解。而随着城市数增多,求解空间比较复杂,无法使用穷举法求解,因此需要使用优化算法来解决TSP问题。TSP问题的应用非常广泛,不仅仅适用于旅行商问题本身,还可以用来解决其他许多的NP完全问题,如邮路问题、转配线上的螺母问题和产品的生产安排问题等等。因此,对TSP问题的有效求解具有重要意义。解决TSP问题的方法有很多,其中一种常用的方法是蚁群算法。除了蚁群算法,还有其他一些常用的解决TSP问题的方法,如遗传算法、动态规划和强化学习等。这些方法各有特点,适用于不同规模和特征的TSP问题。
三、Qlearning求解TSP问题
1、部分代码
可以自动生成地图也可导入自定义地图,只需要修改如下代码中chos的值即可。
import matplotlib.pyplot as plt
from Qlearning import Qlearning
#Chos: 1 随机初始化地图; 0 导入固定地图
chos=1
node_num=36 #当选择随机初始化地图时,自动随机生成node_num-1个城市
# 创建对象,初始化节点坐标,计算每两点距离
qlearn = Qlearning(alpha=0.5, gamma=0.01, epsilon=0.5, final_epsilon=0.05,chos=chos,node_num=node_num)
# 训练Q表、打印路线
iter_num=1000#训练次数
Curve,BestRoute,Qtable,Map=qlearn.Train_Qtable(iter_num=iter_num)
#Curve 训练曲线
#BestRoute 最优路径
#Qtable Qlearning求解得到的在最优路径下的Q表
#Map TSP的城市节点坐标
## 画图
plt.figure()
plt.ylabel("distance")
plt.xlabel("iter")
plt.plot(Curve, color='red')
plt.title("Q-Learning")
plt.savefig('curve.png')
plt.show()
2、部分结果
(1)以国际通用的TSP实例库TSPLIB中的测试集bayg29为例:
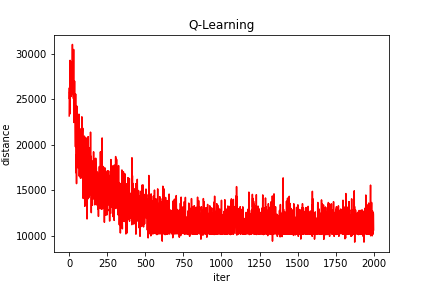
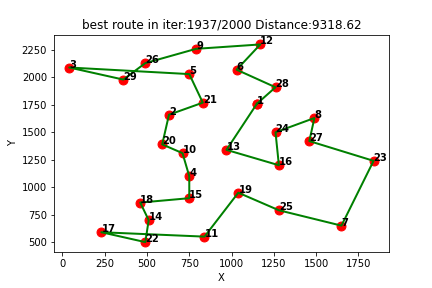
Q-learning得到的
最短路线: [1, 28, 6, 12, 9, 26, 29, 3, 5, 21, 2, 20, 10, 4, 15, 18, 14, 22, 17, 11, 19, 25, 7, 23, 27, 8, 24, 16, 13, 1]
(2)随机生成37个城市


Q-learning得到的最短路线: [1, 26, 33, 36, 5, 2, 22, 35, 3, 7, 12, 25, 34, 23, 11, 17, 9, 15, 27, 14, 28, 19, 37, 32, 18, 29, 16, 21, 13, 20, 8, 6, 10, 31, 4, 30, 24, 1]
(3)随机生成17个城市
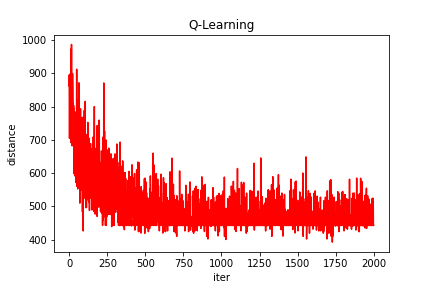
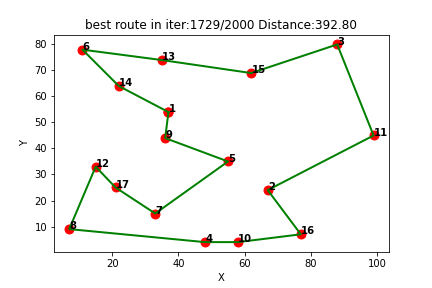
Q-learning得到的最短路线: [1, 9, 5, 7, 17, 12, 8, 4, 10, 16, 2, 11, 3, 15, 13, 6, 14, 1]
四、完整Python代码
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 使用 Burp Suite 分析攻击面
- Packet Tracer - Configuring Extended ACLs - Scenario 1
- 0基础学习VR全景平台篇第132篇:曝光三要素—快门速度
- 什么是向量数据库
- Jmeter 性能压测 —— 常见问题
- 111基于matlab的粒子滤波进行锂离子电池的循环寿命预测
- 【leetcode:1944. 队列中可以看到的人数】单调栈算法及其相关问题
- 移动端APP版本治理
- python爬取网页图片并下载之多线程
- InnoDB引擎-架构