【Java 集合】ArrayBlockingQueue
ArrayBlockingQueue, 顾名思义: 基于数组的阻塞队列, 位于 JUC (java.util.concurrent) 下, 是一个线程安全的集合, 其本身具备了
- 不支持 null 元素: 存入 null 元素会抛出异常
- 固定容量: 在初始化时需要指定一个固定的容量大小。这意味着一旦队列达到最大容量,将不再接受新的元素,直到有消费者取出元素为止
- 有序性: 内部采用数组作为底层数据结构,保持了元素的有序性。这意味着当你向队列中添加元素时,它们将按照添加的顺序排列,而消费者线程将按照相同的顺序取出这些元素
- 阻塞特性:ArrayBlockingQueue 会在队列满时, 阻塞添加数据的线程直至队列非满状态, 同样, 在队列空时, 阻塞获取数据的线程直至队列重新非空
- 支持锁公平性配置: 在初始化时可以指定是否使用公平锁, 默认为非公平锁。公平锁通常会降低吞吐量, 但是减少了可变性和避免了线程饥饿问题
1 实现的数据结构
通常, 队列的实现方式有数组和链表两种方式。
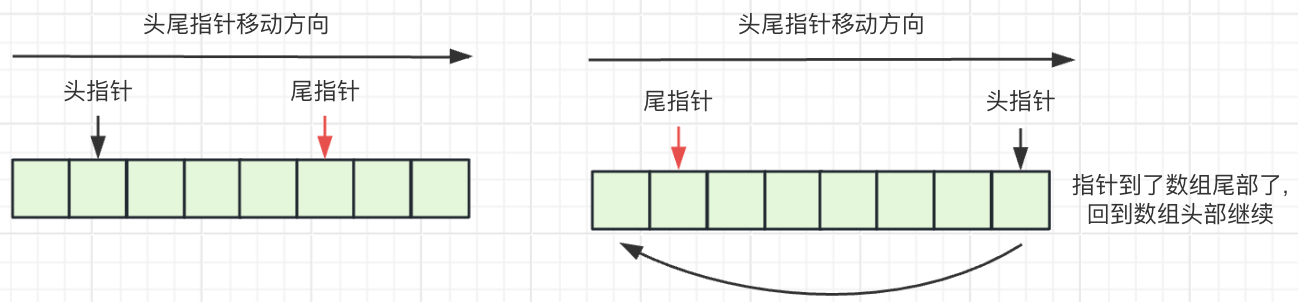
ArrayBlockingQueue 的选择数组作为自己底层的数据结构, 同时通过维护 1 个队头指针 + 1 个队尾指针指针, 达到数据的入队和出队操作。
同时他内部对数组的使用做了一些小心思, 使得入队和出队操作都可以在 O(1) 的时间内完成。
入队涉及到的是数组的添加数据, 同理, 出队涉及到的是数组的删除数据。
而数组的删除操作, 通常的步骤是
- 删除数组中的某个元素
- 将数组中删除元素后的所有元素往前移动一个位置
而 ArrayBlockingQueue 的是队列, 出队固定的第一个节点, 也就是数组的第一个, 所以内部通过维护的 2 个指针, 简化了数组删除的操作
- 删除数组中的某个元素
- 将头指针指向下一个元素, 如果头指针指向了数组的最后一个元素, 那么将头指针重新指向数组的第一个元素,
- 数组的添加也是到了数组的最后一个元素, 重新回到数组的头部, 通过这种方式避免了删除时, 对数组元素的移动
2 源码分析
分析完了 ArrayBlockingQueue 的逻辑实现方式, 下面我们通过源码的形式, 更进一步的了解 ArrayBlockingQueue 的实现。
2.1 ArrayBlockingQueue 持有的属性
public class ArrayBlockingQueue<E> {
// 队列的底层实现结构, 数组
final Object[] items;
// 当前队列的队头指针
int takeIndex;
// 当前队列的队尾指针
int putIndex;
// 队列中的元素个数
int count;
// 用于并发控制的可重入锁
final ReentrantLock lock;
// 并发时的两种状态
// 非空等待条件 (内部实际就是一个队列, 所以可以理解为一个等待队列), 也就是数组中重新有数据了, 可以继续取数据了
// 当某个线程尝试从当前的队列中获取元素时, 如果数组中没有数据, 会把这个线程放到这个等待条件中
// 在另外一个线程中添加元素到数组中,数组变为非空状态, 会唤醒等待在这个等待条件中的线程
private final Condition notEmpty;
// 非满等待条件 (内部实际就是一个队列, 所以可以理解为一个等待队列), 也就是数组中的数据没有达到上限, 可以继续添加数据
// 当某个线程尝试向当前的队列添加元素, 但是当前数组已经满了, 会把这个线程放到这个等待条件中
// 在另一个线程中从当前队列中获取一个元素时, 数组变为非满状态, 会唤醒等待在这个等待条件中的线程
private final Condition notFull;
}
items 是一个数组, 用来存放入队的数据, count 表示队列中元素的个数。takeIndex 和 putIndex 分别代表队头和队尾指针。
2.2 ArrayBlockingQueue 构造函数
public class ArrayBlockingQueue<E> {
// 指定容量构造函数
public ArrayBlockingQueue(int capacity) {
// 调用自带的指定容量和锁公平性配置的构造函数, 默认为非公平的
this(capacity, false);
}
// 指定容量和锁公平性配置的构造函数
public ArrayBlockingQueue(int capacity, boolean fair) {
// 容量小于等于 0, 直接抛异常
if (capacity <= 0)
throw new IllegalArgumentException();
// 声明数组
this.items = new Object[capacity];
// 创建可重入锁, 锁公平性由参数配置
lock = new ReentrantLock(fair);
// 获取非空等待条件
notEmpty = lock.newCondition();
// 获取非满等待条件
notFull = lock.newCondition();
}
// 指定容量, 公平性和初始元素的构造函数
public ArrayBlockingQueue(int capacity, boolean fair, Collection<? extends E> c) {
// // 指定容量和锁公平性配置的构造函数
this(capacity, fair);
// 上锁
lock.lock();
try {
int i = 0;
try {
// 依次遍历入参的集合, 添加到当前的队列中
for (E e : c) {
// 队列中的数据不能为空
checkNotNull(e);
items[i++] = e;
}
} catch (ArrayIndexOutOfBoundsException ex) {
throw new IllegalArgumentException();
}
// 算出队列中的元素个数
count = i;
// 下次添加元素的位置 = 当前队列中的元素个数等于容量上限了 ? 0 (重新回到队头) : 元素的个数 (当前队列的队尾)
putIndex = (i == capacity) ? 0 : i;
} finally {
// 释放锁
lock.unlock();
}
}
}
三个构造函数
指定队列大小的非公平锁构造函数
指定队列大小和锁公平性的构造函数
指定队列大小, 锁公平性和初始元素的构造函数
在第三个函数中, 将入参的集合元素依次添加到当前的队列的过程前, 先使用了 ReentrantLock 来加锁, 再把传入的集合元素按顺序一个个放入 items 中, 这个加锁的操作有必要吗?
一个实例的构造函数不可能存在并发调用的, 那么这个锁的作用是什么呢?
在 Happens-Before 规则中, 有一条监视器锁规则 (Monitor Lock Rule), 简单理解就是线程 A 加锁, 做了数据变更, 线程 A 解锁, 线程 B 加上同一个锁, 这时线程 A 做的变更对线程 B 都是可见的。
创建 ArrayBlockingQueue 的线程是加锁初始 ArrayBlockingQueue 的属性, 后面线程调用 ArrayBlockingQueue 的其他方法时, 都会遇到这个锁, 就会获取到最新的数据。
既然为了可见性, 为什么不使用 volatile 修饰 items 数组呢?
这就涉及到 volatile 的特性了, volatile 修饰的变量, 只能保证可见性, 而这里的 items 数组是一个引用类型, 如果对 items 的引用做了修改 (比如重新赋值, 置为空),
那么其他的线程可以感知到, 但是修改数组里面的数据, volatile 不会保证他们的可见性。
2.3 ArrayBlockingQueue 支持的方法
2.3.1 数据入队方法
ArrayBlockingQueue 提供了多种入队操作的实现来满足不同情况下的需求, 入队操作有如下几种:
- boolean add(E e)
- void put(E e)
- boolean offer(E e)
- boolean offer(E e, long timeout, TimeUnit unit)
add(E e)
public class ArrayBlockingQueue<E> extends AbstractQueue<E> {
public boolean add(E e) {
return super.add(e);
}
// super.add(E e), 父级的 add 方法, 也就是 AbstractQueue 方法
public boolean add(E e) {
// 调用自身的 offer
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
}
}
可以看到 add 方法调用的是父类, 也就是 AbstractQueue 的 add 方法, 而 AbstractQueue 的 add 方法又重新调用会子类的 offer 方法。
offer(E e)
顺着 add 方法, 看一下 offer 方法:
public class ArrayBlockingQueue<E> {
public boolean offer(E e) {
// 非空校验, 为空会抛出一个异常
checkNotNull(e);
final ReentrantLock lock = this.lock;
// 加锁
lock.lock();
try {
// 当前存储数据的数组的长度 == 存储的数组元素个数的, 达到上限了
// 直接返回 false
if (count == items.length)
return false;
else {
// 调用自身的 enqueue 方法将元素添加到队列中
enqueue(e);
return true;
}
} finally {
lock.unlock();
}
}
private void enqueue(E x) {
final Object[] items = this.items;
// 将当前的元素添加到数组的 putIndex 位置
items[putIndex] = x;
// putIndex + 1 后如果已经等于当前数组的长度了, 也就是达到了数组的尾部最后一个了, 直接将 putIndex 设置为 0
// 下次添加元素的位置从 0 开始
if (++putIndex == items.length)
putIndex = 0;
// 元素个数 + 1
count++;
// 队列里面又有数据了, 非空了, 唤醒在 notEmpty 里面等待的线程
notEmpty.signal();
}
}
offer 方法的逻辑很简单
入参非空校验
加锁
队列中的元素达到上限, 直接返回 false, 并释放锁
队列中的元素达未到上限, 将元素添加到队列中, 唤醒在非空等待条件中等待的线程, 返回 ture, 并释放锁
在 enqueue 方法中, 将元素放到队列后, 会计算下次元素存放的位置, 这个计算过程实际就是一个取模操作, 当下一个元素存放的位置超过了队列的长度, 那么将元素重新存放到队列的头部, 也就是我们上面说的指针回到数组头部。
offer(E e, long timeout, TimeUnit unit)
offer(E e, long timeout, TimeUnit unit) 方法只是在 offer(E e) 的基础上增加了超时时间的概念。在队列上阻塞了多少时间后, 队列还是满的, 就返回。
public class ArrayBlockingQueue<E> {
public boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException {
// 先进行非空校验
checkNotNull(e);
// 把超时时间转换成纳秒
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
// 获取一个可中断的互斥锁
lock.lockInterruptibly();
try {
// while 循环的目的是防止在中断后没有到达传入的 timeout 时间, 可以继续重试
// 当数组的元素个数等于数组的长度了, 达到上限了, 先进入阻塞
while (count == items.length) {
// 已经达到超时时间了, 直接返回 false, 结束
if (nanos <= 0)
return false;
// 将当前线程阻塞在 非满 等待条件上 nanos 纳秒
// 唤醒后, 返回剩余的等待时间 (可被中断)
nanos = notFull.awaitNanos(nanos);
}
// 入队操作
enqueue(e);
return true;
} finally {
lock.unlock();
}
}
}
该方法利用了 Condition 的 awaitNanos 方法, 等待指定时间, 因为该方法可中断, 所以这里利用 while 循环来处理中断后还有剩余时间的问题, 等待时间到了以后数组非满时, 可以调用 enqueue 方法放入队列。
put(E e)
public class ArrayBlockingQueue<E> {
public void put(E e) throws InterruptedException {
// 非空校验
checkNotNull(e);
final ReentrantLock lock = this.lock;
// 可中断锁获取
lock.lockInterruptibly();
try {
// 当数组的元素个数 等于数组的长度了, 达到上限了, 进入阻塞等待唤醒
while (count == items.length)
notFull.await();
// 入队操作
enqueue(e);
} finally {
lock.unlock();
}
}
}
put() 方法在 count 等于 items 长度时, 即队列已经满时, 进入阻塞, 然后一直等待, 直到被其他线程唤醒。唤醒后调用 enqueue 方法放入队列。
2.3.2 数据出队方法
同入队的方法一样, 出队也有多种实现, ArrayBlockingQueue 提供了好几种出队的方法, 大体如下:
- E poll()
- E poll(long timeout, TimeUnit unit)
- E take()
poll()
public class ArrayBlockingQueue<E> {
public E poll() {
final ReentrantLock lock = this.lock;
// 加锁
lock.lock();
try {
// 如果当前数组的元素个数为 0, 直接返回 null,
// 否则调用 dequeue 方法获取一个元素返回
return (count == 0) ? null : dequeue();
} finally {
lock.unlock();
}
}
private E dequeue() {
final Object[] items = this.items;
// 获取 taskIndex 位置的元素, 同时将 taskIndex 位置置为 null
@SuppressWarnings("unchecked")
E x = (E) items[takeIndex];
items[takeIndex] = null;
// taskIndex + 1 后, 如果等于数组的长度, 达到了数组的长度, 将 taskIndex 置为 0, 从头开始
if (++takeIndex == items.length)
takeIndex = 0;
// 元素个数 - 1
count--;
// 迭代器不为空, 也要进行元素的弹出 (这里可以先暂时不处理)
if (itrs != null)
itrs.elementDequeued();
// 唤醒在 notFull 等待条件上的线程
notFull.signal();
return x;
}
}
poll() 如果队列没有元素返回 null, 否则调用 dequeue() 方法把队头的元素出队列。
dequeue 会根据 takeIndex 获取到该位置的元素, 并把该位置置为 null, 然后将队头的指针指向下一个元素, 当当前指针已经在数组的最后一个元素, 则重新回到数组的头部, 最后唤醒 notFull 等待条件中的线程。
poll(long timeout, TimeUnit unit)
该方法是 poll() 的可配置超时等待方法。
和入队方法 offer() 方法一样, 使用 while 循环 + Condition 的 awaitNanos 来进行等待, 等待时间到后, 队列有数据, 就执行 dequeue 获取元素。
public class ArrayBlockingQueue<E> {
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
// 转换为纳秒
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
// 获取可中断的锁
lock.lockInterruptibly();
try {
// 数组的元素个数为 0
while (count == 0) {
// 超过了等待时间了, 返回 null
if (nanos <= 0)
return null;
// 带超时的的等待
nanos = notEmpty.awaitNanos(nanos);
}
return dequeue();
} finally {
lock.unlock();
}
}
}
take()
public class ArrayBlockingQueue<E> {
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
// 当前数组的容量为 0, 将当前线程阻塞在 notEmpty 的等待条件中, 等待唤醒
while (count == 0)
notEmpty.await();
// 线程唤醒了, 调用 dequeue 获取数据
return dequeue();
} finally {
lock.unlock();
}
}
}
take() 方法和 put() 方法类似, 当队列为空时, 进入阻塞, 一直等待, 直到被唤醒, 唤醒后调用 dequeue() 方法获取队列中的元素。
2.3.3 获取元素方法
获取数据的方法就一个。
peek()
public class ArrayBlockingQueue<E> {
public E peek() {
final ReentrantLock lock = this.lock;
// 尝试获取锁
lock.lock();
try {
// 直接返回当前数组的 takeIndex 位置的元素, 也就是队头, 可能为空
return itemAt(takeIndex);
} finally {
lock.unlock();
}
}
final E itemAt(int i) {
return (E) items[i];
}
}
这里获取元素时上锁是为了避免脏数据的产生。
2.3.4 删除元素方法
因为删除元素是指定元素删除,删除的位置不确定,所以只能像普通的数组删除一样, 对应位置的元素删除后, 后面的元素向前移动一个位置。
remove(Object o)
public class ArrayBlockingQueue<E> {
public boolean remove(Object o) {
// 需要删除的元素为空, 直接返回 false
if (o == null)
return false;
final Object[] items = this.items;
final ReentrantLock lock = this.lock;
lock.lock();
try {
// 数组里面没有数据, 可以直接不处理
if (count > 0) {
final int putIndex = this.putIndex;
int i = takeIndex;
// 从 takeIndex 一直遍历到 putIndex, (遍历途中, 如果到了数组的尾部, 就从 0 继续开始)
// 直到找到和元素 o 相同的元素, 调用 removeAt 进行删除
do {
if (o.equals(items[i])) {
removeAt(i);
return true;
}
if (++i == items.length)
i = 0;
} while (i != putIndex);
}
} finally {
lock.unlock();
}
}
void removeAt(final int removeIndex) {
final Object[] items = this.items;
// 移除的位置刚好是 taskIndex, 也就是数组的头部
if (removeIndex == takeIndex) {
// 直接将 taskIndex 置为 null
items[takeIndex] = null;
// taskIndex + 1 后等于数组的长度, 达到了尾部了, 回到头部
if (++takeIndex == items.length)
takeIndex = 0;
// 元素个数 - 1
count--;
// 迭代器不为空, 进行迭代器的元素删除
if (itrs != null)
itrs.elementDequeued();
} else {
final int putIndex = this.putIndex;
// 将 removeIndex 到 putIndex 间所有的元素都向前移动一位, 移动到尾部了, 就从 0 继续开始
for (int i = removeIndex;;) {
// 从下一个位置开始
int next = i + 1;
// 下一个位置为数组的尾部了, 从 0 继续开始
if (next == items.length)
next = 0;
// 当前要处理的位置 i 的下一个位置不等于 putIndex
if (next != putIndex) {
// 将当前的位置 i 的值修改为下一个位置的值
items[i] = items[next];
// 更新需要处理的位置为下一个位置
i = next;
} else {
// 当前要处理的位置 i 的下一个位置为 putIndex
// 将当前位置置为 null
items[i] = null;
// 当前的 putIndex = 当前的位置
this.putIndex = i;
// 跳出循环
break;
}
}
// 元素个数减 1
count--;
// 迭代器不为空, 进行迭代器的元素删除
if (itrs != null)
itrs.removedAt(removeIndex);
}
// 唤醒等待在 notFull 上的线程
notFull.signal();
}
}
remove 整体的逻辑比较简单, 从 takeIndex 开始一直遍历到 putIndex, 直到找到和元素 o 相同的元素, 调用 removeAt 方法进行删除。
而 removeAt 方法的处理方式分为两种情况来考虑
- removeIndex == takeIndex, 这时后面的元素不需要往前移, 而只需要把 takeIndex 的指向下一个元素即可
- removeIndex != takeIndex, 这时通过 putIndex 将 removeIndex 后的元素往前移一位
3 总结
它是 BlockingQueue 接口的一种实现,通过固定大小的数组来存储元素,
同时借助 ReentrantLock 和 ReentrantLock 的 Condition 提供了阻塞操作,使得在队列已满或为空时,线程能够安全地等待。
内部借助头尾 2 个指针的移动达到一种循环数组的效果, 避免了整个元素删除时, 数组需要将后面的元素迁移的操作。
4 参考
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- antd的动态表单配置默认拥有一个或几个,第一个是否可以删除
- Unity之铰链关节和弹簧组件
- 【原创】docker +宝塔+安装zabbix
- Autosar DEM模块
- 【操作系统】第二章 进程的描述与控制
- RocketMQ 顺序消息收发实践
- Unity 踩坑记录 项目启动时获取目标子UI的位置相同
- linux服务器备份禅道数据
- C++复合数据类型:结构体|枚举
- 【华为OD机试】工号不够用了怎么办【2023 B卷|100分】