人工智能任务2-读懂Transformer模型的十个灵魂拷问问题,深度理解Transformer模型架构
大家好,我是微学AI,今天给大家介绍一下人工智能任务2-读懂Transformer模型的十个灵魂拷问问题,深度理解Transformer模型架构。Transformer模型是一种基于自注意力机制的神经网络架构,被广泛用于自然语言处理任务中,如机器翻译、文本分类、情感分析等。下面的文章我将介绍十个关于Transformer模型的灵魂拷问问题。
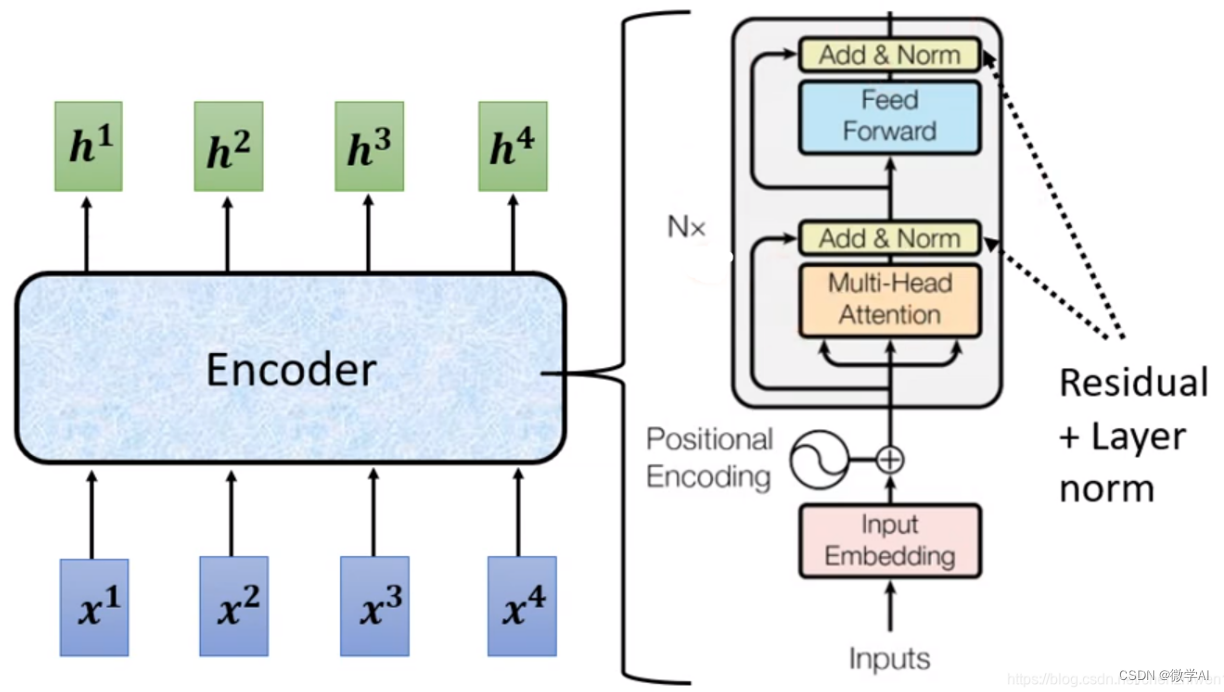
一、 Transformer的自注意力层中发生了什么?
Transformer的自注意力层是该架构的核心机制之一。在这一层中,输入序列的每个成员都会与其他成员进行比较,并根据它们之间的相似性对输出序列的相应位置进行修改。自注意力层通过可微分的键-值搜索来处理输入序列,然后将结果添加到输出序列中。输出和输入具有相同的序列长度和维度。对每个序列位置的输出,通过加权值对应的查询和键的相似性来进行加权求和。这一过程是通过将查询、键和值投影到相同形状的三个矩阵中来完成的。然后,对查询和键进行“软序列最近邻搜索”,并根据点积的softmax对值进行加权,并对加权值进行求和。最后,将结果添加到残差连接中并进行归一化。这一过程可以用以公式表示:Y = softmax(QK^T)V。
此外,结果还会添加到残差连接中并进行归一化。这一过程还包括一些细节,例如点积的“缩放”、残差连接和层归一化。自注意力层的计算复杂度是与序列长度的平方成正比,因为需要计算L×L的注意力矩阵。然而,对于某些任务,如字符级模型,上下文大小至关重要。此外,Transformer通常通过自监督任务进行预训练,如掩码语言建模或下一个标记预测。预训练模型通常非常通用,并且通常在多个GPU上进行预训练。Transformer模型通常需要在Kubernetes集群中进行部署,以便在生产环境中使用。
二、自注意力层的键-值搜索是如何处理输入序列的?
自注意力层的键-值搜索是通过将输入序列的每个成员与其他成员进行比较,并根据它们之间的相似性对输出序列的相应位置进行修改来处理输入序列的。这一过程是通过将查询、键和值投影到相同形状的三个矩阵中来完成的。然后,对查询和键进行“软序列最近邻搜索”,并根据点积的softmax对值进行加权,并对加权值进行求和。最后,将结果添加到残差连接中并进行归一化。整个过程可以用以下伪代码表示:Y = softmax(QK^T)V。这一过程还包括一些细节,例如点积的“缩放”、残差连接和层归一化。自注意力层的计算复杂度是与序列长度的平方成正比,因为需要计算L×L的注意力矩阵。
三、为什么在自注意力层中需要对点积结果进行缩放处理?
在自注意力层中需要对点积结果进行缩放处理是为了控制点积的值域,以确保点积的结果不会因为向量维度的增加而变得过大。这样做有助于更稳定地进行softmax计算,从而提高模型的训练效果。通过缩放处理,可以使点积的结果在一个合理的范围内,避免因为数值过大而导致梯度消失或梯度爆炸的问题,从而提高模型的训练稳定性。
四、在自注意力层中,除了缩放处理外,还有哪些方法可以避免梯度消失或梯度爆炸的问题?
除了缩放处理外,还有一些其他方法可以避免梯度消失或梯度爆炸的问题。其中包括使用残差连接(residual connections)、层归一化(layer normalization)和使用适应性优化器(如Adam)等。残差连接可以使网络更容易优化,允许更深的网络进行训练。层归一化有助于稳定训练过程,减少梯度消失或梯度爆炸的风险。适应性优化器可以根据每个参数在每个时间步的动量和学习率进行递归估计,有助于更稳定地训练模型。这些方法的综合应用可以帮助避免梯度消失或梯度爆炸的问题,提高模型的训练稳定性。
五、层归一化是如何稳定训练过程,减少梯度消失或梯度爆炸的风险的?
层归一化通过对每个样本的特征进行归一化处理,有助于稳定训练过程,减少梯度消失或梯度爆炸的风险。它的作用在于使得每一层的输入保持在一个相对稳定的范围内,避免了输入数值的剧烈变化。这有助于减少梯度消失或梯度爆炸的风险,因为输入的稳定性可以使得梯度的传播更加平稳和可控。通过层归一化,模型在训练过程中更容易收敛,减少了训练过程中出现梯度消失或梯度爆炸的可能性,提高了模型的训练稳定性。
六、Transformer模型中的损失函数是怎么计算的?
在Transformer模型中,通常使用交叉熵损失函数来计算损失。该损失函数通过比较模型生成的逻辑(logits)与实际目标的标记之间的差异来衡量模型的性能。交叉熵损失函数的计算公式如下:
交叉熵损失 = ? ∑ i = 1 N ( y i log ? ( p i ) ) \text{交叉熵损失} = -\sum_{i=1}^{N} \left( y_i \log(p_i) \right) 交叉熵损失=?i=1∑N?(yi?log(pi?))
其中, N N N 是类别的数量, y i y_i yi? 是实际标记的第 i i i 个元素, p i p_i pi? 是预测概率的第 i i i 个元素。使用该公式可以度量实际标记和预测概率之间的差异,进而评估模型的性能。
在训练阶段,模型通过最小化损失函数来调整参数,使得模型的预测结果尽可能接近实际目标。这样可以提高模型在生成输出序列时的准确性和泛化能力。
七、Transformer的编码器与解码器是如何对接的
Transformer模型的编码器和解码器是通过输入嵌入和位置编码进行对接的。编码器负责从输入句子中提取特征,而解码器则利用这些特征生成输出句子(翻译)。现在我来逐步解释一下这个过程。
1.输入嵌入和位置编码:
首先,我们将输入句子进行分词,得到一个由单词组成的序列。每个单词会被转换成一个嵌入向量,这个向量表示了单词的语义信息。同时,为了让模型知道单词的位置,我们还会对每个嵌入向量进行位置编码。
2.编码器处理输入特征:
输入的嵌入向量和位置编码经过编码器的多个编码器块,编码器块会对这些向量进行线性代数运算,从整个句子中提取上下文信息,并丰富嵌入向量的内容。
3.解码器生成输出概率:
解码器使用来自编码器的输入特征来生成输出句子。解码器会逐个生成输出单词,每个输出单词都会成为下一个输入单词的一部分。这种处理方式被称为“自回归”,它允许模型生成与输入长度不同的输出句子。
八、在Transformer模型中,如何通过自回归生成来适应不同长度的输出序列?
在Transformer模型中,通过自回归生成来适应不同长度的输出序列是通过解码器的自注意力机制和位置编码来实现的。
1.解码器的自注意力机制:
在解码器中,每个生成的单词都会利用自注意力机制来关注输入序列的不同部分,以及之前生成的单词。这样可以确保每个生成的单词都能够充分利用输入序列的信息,从而适应不同长度的输入。
2.位置编码:
解码器中的位置编码会为每个生成的单词提供位置信息,使得模型知道每个单词在句子中的位置。这样可以确保模型在生成不同长度的输出序列时能够正确地安排单词的顺序。
通过解码器的自注意力机制和位置编码,Transformer模型可以在生成输出序列时适应不同长度的输入序列。这使得Transformer模型在处理翻译、摘要等任务时能够灵活地生成不同长度的输出序列,从而提高了其在自然语言处理任务中的适用性。
九、在Transformer模型中,为什么需要使用自回归的方式生成输出句子?
在Transformer模型中,需要使用自回归的方式生成输出句子是因为这种方式能够更好地处理变长序列的生成任务,如翻译、摘要等。自回归生成保证了生成的每个单词都可以利用之前生成的单词作为上下文,从而更好地捕捉句子的语法和语义信息。
自回归生成确保了模型在生成每个单词时都可以考虑到之前生成的单词,这样可以更好地保持句子的连贯性和逻辑性。在翻译任务中,这种方式可以更好地处理源语言和目标语言之间的语序差异,确保翻译结果符合目标语言的语法规则。
另外,自回归生成还可以适应不同长度的输出序列,因为每个单词的生成都是基于之前生成的单词,而不是固定长度的上下文。这使得Transformer模型可以处理各种长度的输入和输出序列,使其在自然语言处理任务中表现出色。
十、Transformer为什么要用多头自注意力机制,多头有什么含义?
Transformer模型使用多头自注意力机制是为了增强模型对不同位置和语义之间关系的建模能力。多头自注意力机制允许模型同时关注输入序列中的不同部分,并学习它们之间的复杂关系,从而提高模型的表征能力和泛化能力。
多头自注意力机制的含义在于,它允许模型并行地学习多组不同的注意力权重,每组权重都可以关注输入序列中的不同部分。这些不同的注意力权重可以捕捉到输入序列中不同位置和语义之间的关联,从而使模型能够更好地理解和处理输入序列的信息。
多头自注意力机制通过将输入进行线性变换,然后分成多个头(通常是8个头),每个头学习不同的注意力权重。最后,这些多头的注意力权重被合并在一起,以获得更丰富和全面的表示。这样做的好处是,模型可以同时关注输入序列中的不同部分,并学习它们之间的复杂关系,从而提高模型的性能和泛化能力。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- GPT/GPT4科研应用与AI绘图技术及论文高效写作(建议收藏)
- jquery获取name包含mc的元素数量 $(“input[name *= ‘mc‘]“) 是什么意思 jQuery 获取 name包含mc和add的元素
- Qt3D 输入类处理鼠标键盘动作
- CNAS中兴新支点——性能测试的流程分享
- 初中数学:几何题的相关解题原则总结
- 【SpringBoot】-Spring MVC详解
- 倾斜摄影三维模型地方坐标系几何坐标转换方法分析
- 基于OpenCV的图像平移
- NumPy 高级教程——性能优化
- Matplotlib_布局格式定方圆