Spark三:Spark SQL
Spark SQL
数据的分析方式、数据分类和SparkSQL适用场景、数据抽象(DataFrame, DataSet, RDD),SparkSQL读取数据和处理数据的两种风格:SQL风格和DSL风格
学习链接 https://mp.weixin.qq.com/s/caCk3mM5iXy0FaXCLkDwYQ
一、数据分析方式
1.1 命令式
通过一个算子,得到一个结果,通过结果在进行后续计算
sc.textFile("...")
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.collect()
优缺点
优点:
- 操作粒度细,能控制数据的每一个处理环节
- 操作明确,步骤清晰,容易维护
- 支持半/非结构化数据操作
缺点:
- 需要代码能力、写起来麻烦
1.2 SQL
SQL on Hadoop
select name, id, class
from students
where age > 10
优缺点
优点:
- 表达清晰
缺点
- 使用机器学习算法麻烦
二、SparkSQL
2.1 发展历史
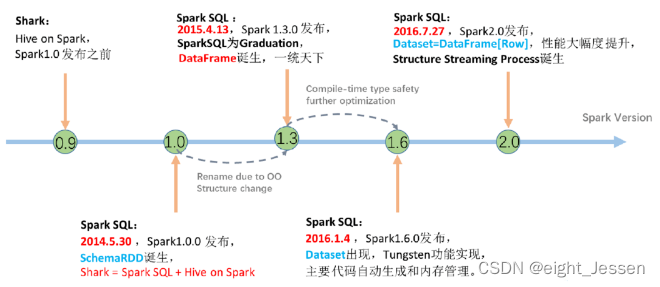
2.2 Hive和SparkSQL
Hive是将SQL转为MapReduce
SparkSQL是将SQL解析为:“RDD+优化”再执行
三、数据分类和SparkSQL适用场景
3.1 结构化数据
指数据由固定的Schema(约束),例如在用户表中,name字段为String,name每一条数据的name字段值都可以当做String来使用。
3.2 半结构化数据
指数据没哟?的Schema,但是数据本身是有结构的
3.2.1 没有固定的Schema
指的是半结构化数据是没有固定的 Schema 的,可以理解为没有显式指定 Schema。
比如说一个用户信息的 JSON 文件,
第 1 条数据的 phone_num 有可能是数字,
第 2 条数据的 phone_num 虽说应该也是数字,但是如果指定为 String,也是可以的,
因为没有指定 Schema,没有显式的强制的约束。
3.2.2 有结构
虽说半结构化数据是没有显式指定 Schema 的,也没有约束,但是半结构化数据本身是有有隐式的结构的,也就是数据自身可以描述自身。
例如 JSON 文件,其中的某一条数据是有字段这个概念的,每个字段也有类型的概念,所以说 JSON 是可以描述自身的,也就是数据本身携带有元信息。
| 数据类型 | 定义 | 特点 | 举例 |
|---|---|---|---|
| 结构化数据 | 有固定的 Schema | 有预定义的 Schema | 关系型数据库的表 |
| 半结构化数据 | 没有固定的 Schema,但是有结构 | 没有固定的 Schema,有结构信息,数据一般是自描述的 | 指一些有结构的文件格式,例如 JSON |
| 非结构化数据 | 没有固定 Schema,也没有结构 | 没有固定 Schema,也没有结构 | 指图片/音频之类的格式 |
3.3 Spark处理数据类型
RDD主要用于处理非结构化数据、半结构化数据、结构化
SparkSQL主要处理结构化数据(较为规范的半结构化数据也可以处理)
四、SparkSQL数据抽象
4.1 DataFrame/Dataset
4.1.1 DataFrame
DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库的二维表格,带有 Schema 元信息(可以理解为数据库的列名和类型)。
4.1.2 Dataset
与RDD相比,Dataset保存了更多描述信息,概念上等同于关系型数据库中的二维表。
与DataFrame相比,保存了类型信息,是强类型的,提供了编译时类型检查。
调用 Dataset 的方法先会生成逻辑计划,然后被 spark 的优化器进行优化,最终生成物理计划,然后提交到集群中运行!
DataSet包含了DataFrame的功能。
在Spark2.0中,DataFrame表示为DataSet[ROW],即DataSet的子集。
4.1.3 RDD、DataFrame、DataSet的区别
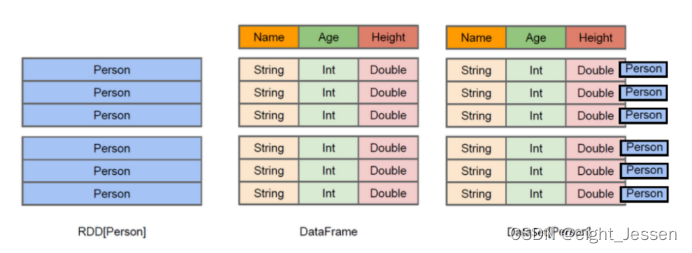
- RDD[Person]:以Person为类型参数,但不了解其内部结构
- DataFrame:提供了详细的结构信息 schema 列的名称和类型。这样看起来就像一张表了。
- DataSet[Person]:不光有 schema 信息,还有类型信息。
4.1.4 以图解为例
- RDD[Person]

- DataFrame
DataFrame = RDD[Person] - 泛型 + Schema + SQL操作 + 优化

- Dataset
Dataset[Person] = DataFrame + 泛型

五、Spark SQL应用
Spark2.0 SparkSession 封装了 SqlContext 及 HiveContext;
实现了 SQLContext 及 HiveContext 所有功能;
通过 SparkSession 还可以获取到 SparkConetxt。
5.1 创建DataFrame/Dataset
5.1.1 读取文本文件:
-
- 本地有数据文件
-
- 创建SparkSession
-
- 定义case class(相当于表的schema)
-
- 将RDD和case class关联
-
- 将RDD转换成DataFrame
-
- 查看数据和schema
-
- 注册表
-
- 执行QL
5.1.2 读取json文件:
读取之后可以使用DataFrame的函数操作
val jsonDF= spark.read.json("file:///resources/people.json")
jsonDF.show
注意:直接读取 json 文件有 schema 信息,因为 json 文件本身含有 Schema 信息,SparkSQL 可以自动解析。
5.1.3 读取parquet文件
val parquetDF=spark.read.parquet("file:///resources/users.parquet")
parquetDF.show
注意:直接读取 parquet 文件有 schema 信息,因为 parquet 文件中保存了列的信息。
5.2 两种查询风格:DSL和SQL
假设有一份数据
val lineRDD= sc.textFile("hdfs://node1:8020/person.txt").map(_.split(" "))
case class Person(id:Int, name:String, age:Int)
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))
val personDF = personRDD.toDF
personDF.show
5.2.1 DSL风格
- 查看name字段数据
personDF.select("name").show - 查看name和age字段
personDF.select("name", "age").show - 查看name和age字段,并将age+1
personDF.select(col("name"), col("age") + 1).show
personDF.select($"name",$"age",$"age"+1).show - 过滤age大于等于25的数据
personDF.filter($"age" >25).show - 按年龄进行分组并统计相同年龄的人数
personDF.groupBy("age").count().show
5.2.2 SQL风格:
可以通过在程序中使用 spark.sql() 来执行 SQL 查询,结果将作为一个 DataFrame 返回。
如果想使用 SQL 风格的语法,需要将 DataFrame 注册成表,采用如下的方式:
personDF.createOrReplaceTempView("t_person")
spark.sql("select * from t_person").show
- 显示表的描述信息
spark.sql("desc t_person").show - 查询年龄最大的前两名
spark.sql("select * from t_person order by age desc limit 2").show - 查询年龄大于30的人的信息
spark.sql("select * from t_person where age>30").show
5.2.3 总结:
- DataFrame和DataSet都可以通过RDD来创建
- 也可以通过读取普通文本创建——需要通过RDD+Schema约束
- 通过json/parquet会有完整的约束
- 不管是DataFrame还是DataSet都可以注册成标,之后可以使用SQL和DSL。
5.3 Spark SQL WordCount举例
package com.example
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
object WordCount {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc = spark.sparkContext
sc.setLogLevel("WARN")
import spark.implicits._
val filePath = "D:\\workshop\\code\\my-test-maven\\src\\main\\scala\\com\\example\\test.txt"
val fileDF: DataFrame = spark.read.text(filePath)
val fileDS: Dataset[String] = spark.read.textFile(filePath)
// 都能打印出来
fileDF.show()
fileDS.show()
// val words = fileDF.flatMap(_.split(" ")) //注意:报错,因为DF没有泛型,不知道_是String
val wordDS = fileDS.flatMap(_.split(" ")) //注意:正确,因为DS有泛型,知道_是String
wordDS.groupBy("value").count().orderBy($"count".desc).show()
sc.stop()
spark.stop()
}
}
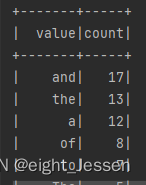
5.4 Spark SQL多数据源交互
5.4.1 读取数据:
- 读取json文件
spark.read.json("D:\\data\\output\\json").show() - 读取csv文件
spark.read.csv("D:\\data\\output\\csv").toDF("id","name","age").show() - 读取parquet文件
spark.read.parquet("D:\\data\\output\\parquet").show() - 读取mysql表:
val prop = new Properties()
prop.setProperty("user","root")
prop.setProperty("password","root")
spark.read.jdbc(
"jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8","person",prop).show()
5.4.2 写数据
- 写入json文件
personDF.write.json("D:\\data\\output\\json") - 写入csv文件
personDF.write.csv("D:\\data\\output\\csv") - 写入parquet文件
personDF.write.parquet("D:\\data\\output\\parquet") - 写入mysql表
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 基于多反应堆的高并发服务器【C/C++/Reactor】(中)子线程 WorkerThread的实现
- GEE时序——利用sentinel-2(哨兵-2)数据进行地表物候学分析(时间序列平滑法估算和非平滑算法代码)
- <虚幻引擎UE>挑战——教你快速捏出自己的专属虚拟人Metahuman Creator
- Web 安全之文件下载漏洞详解
- 发酵食品全解析:定义、种类与科学证实的健康优势
- 智能充电桩电动工具 wifi蓝牙 解决方案
- PDFMiner,一个神奇的 Python 库!
- 网络第6天
- 【FPGA】分享一些FPGA入门学习的书籍
- 翻译: LLM构建 GitHub 提交记录的聊天机器人二 使用 Timescale Vector、pgvector 和 LlamaIndex