【C++】unordered_map,unordered_set模拟实现
unordered_map,unordered_set模拟实现

喜欢的点赞,收藏,关注一下把!
上一篇文章我们把unordered_map和unordered_set底层哈希桶的知识也都说清楚了,今天就根据哈希桶模拟实现出unordered_map和unordered_set。
这里如果看过以前文章【C++】map和set的模拟实现,应该会觉得简单。
因为unordered_map和unordered_set底层都是哈希桶,因此我们只需要一个哈希桶就好了。所以哈希桶的代码我们做一下修改,让它能够同时满足unordered_map和unordered_set的需求。
unordered_map是KV模型,unordered_set是K模型,因此先把链表节点改一下,传个T,这个T既可以是KV,也可以是K。
template<class T>
struct HashNode
{
T _data;
HashNode<T>* _next;
HashNode(const T& data)
:_data(data)
,_next(nullptr)
{}
};
插入这里也要改一下,因为find我们只要key,但是unordered_map是pair,我们要把key取出来,因此HashTable需要增加一个模板参数,这个模板参数分别由unordered_set、unordered_map传过来一个仿函数。作用是把key取出来
bool Insert(const T& data)
{
KeyOfT kot;//不知道T是key还是pair
if (Find(kot(data))//仿函数把key取出来
return false;
//负载因子控制在1,超过就扩容
if (_n == _tables.size())
{
vector<Node*> newtable;
//newtable.resize(_tables.size() * 2);
newtable.resize(__stl_next_prime(_tables.size()));
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
//头插到新表
while (cur)
{
Node* next = cur->_next;
size_t hashi = Hash()(kot(data)) % newtable.size();
cur->_next = newtable[hashi];
newtable[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newtable);//旧表和新表交换一下
}
//匿名对象去调用仿函数,算在第几个桶里面
int hashi = Hash()(kot(data)) % _tables.size();
//头插
Node* newnode = new Node(data);//调用Node的构造,因此Node写个构造
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
return true;
}
然后再说这个模板参数Hash的问题

可以看见keyOfT写在Hash后面,Hash报错了,因为它有缺省值keyOfT没有。当然你也可以把Hash放在keyOfT后面,但是这里的问题不是这个。因为Hash在HashTable不应该有缺省值,应该是由它的上层unordered_map和unordered_set传过去。为什么?
因为不见得你以后写一个vector< string >这样类似的自定义类型底层可以把它转成整数,还是要由调用的unordered_map和unordered_set人传一个能把这样类型转成整数的仿函数。所以把Hash的缺省值放在unordered_map和unordered_set的模板参数中。
下面我们把unordered_map和unordered_set模拟实现大框架搭建出来
//UnorderedMap.h
namespace wdl
{
template<class K,class V,class Hash=HashFunc<K>>
class unordered_map
{
struct MapKeyOfT
{
const K& operator()(const pair<const K, V>& kv)
{
return kv.first;
}
};
public:
private:
//第二个参数决定是KV模型
HashTable<K, pair<const K, V>, Hash, MapKeyOfT> _ht;
};
}
//UnorderedSet.h
namespace wdl
{
template<class K,class Hash = HashFunc<K>>
class unordered_set
{
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
public:
private:
//第二个参数决定是K模型
HashTable<K, K, Hash, SetKeyOfT> _ht;
};
}
插入
复用哈希桶的插入
//UnorderedMap.h
bool insert(const pair<K, V>& kv)
{
return _ht.Insert(kv);
}
//UnorderedSet.h
bool insert(const K& key)
{
return _ht.Insert(key);
}
插入很简单,但注意到库里的插入返回的是pair,插入成功是返回指向这个节点的指针和true,插入失败也就是插入的是相同的值返回指向这个相同节点的指针和false

所以下面我们先实现迭代器在把插入完善
普通迭代器
思考这样一个问题,++怎么走,如何做到把一个桶走完了找到下一个桶?

可不可以把这些桶都链接起来?
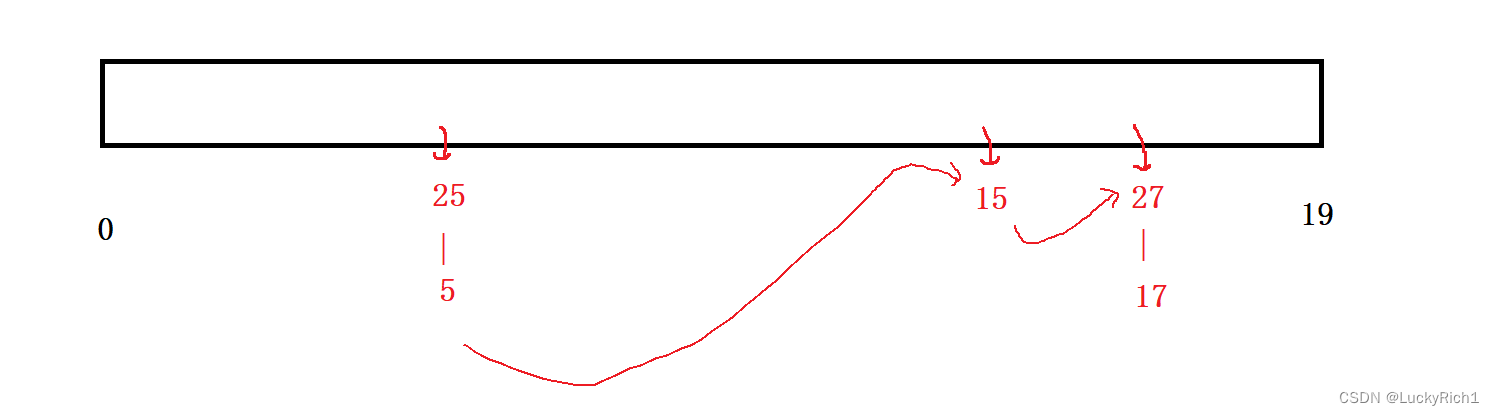
这样遍历起来就方便了,找到第一个桶的第一个位置然后next往下走就像单链表一样遍历就走完了。如果查找的话给每个桶最后一个节点标记位这样也可以解决找别的桶去了的问题。
但是真正麻烦的是插入怎么办?
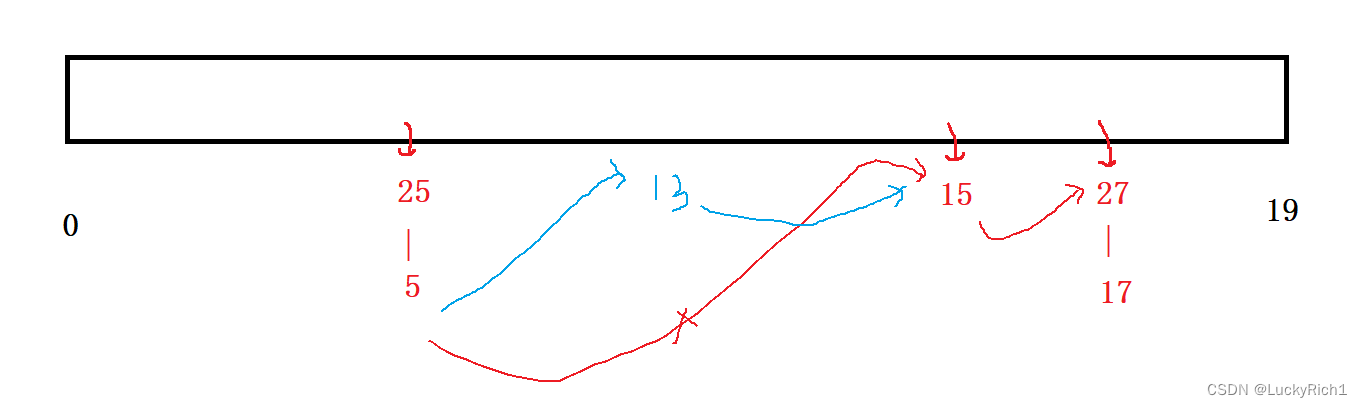
插入13,要找到上一个桶的最后一个节点连接起来,再找到下一个桶的第一个节点连接起来。
删除怎么办?
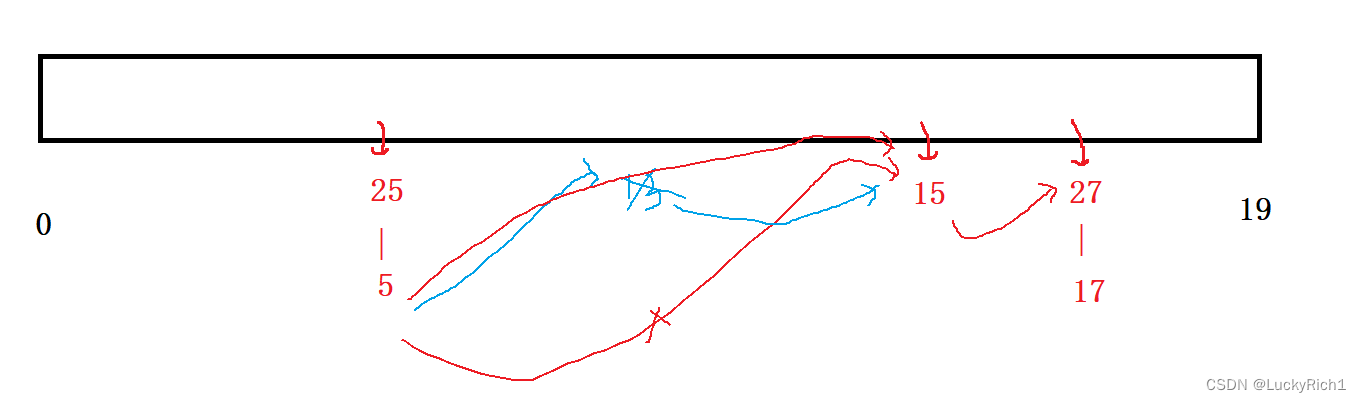
删除13,不还是要找到上一个桶最后一个节点和下一个桶第一个节点然后连接起来吗。
其实哈希桶的遍历也很简单,无非就是当前桶走完了找下一个桶,如果我们有这个表的话,当前桶走完遍历一下找到下一个桶不就好了吗。因此我们不仅要有这个节点的指针,还要有这个表。库里就是这样的实现方式。
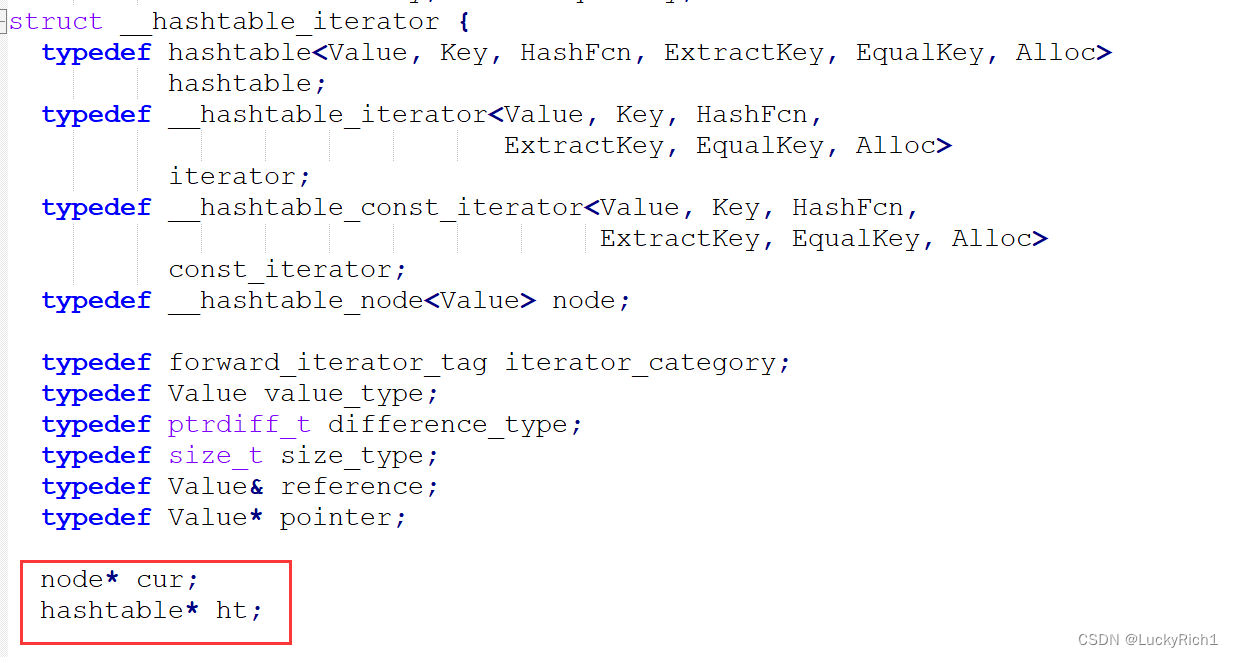
通过哈希表的指针找到这张表。
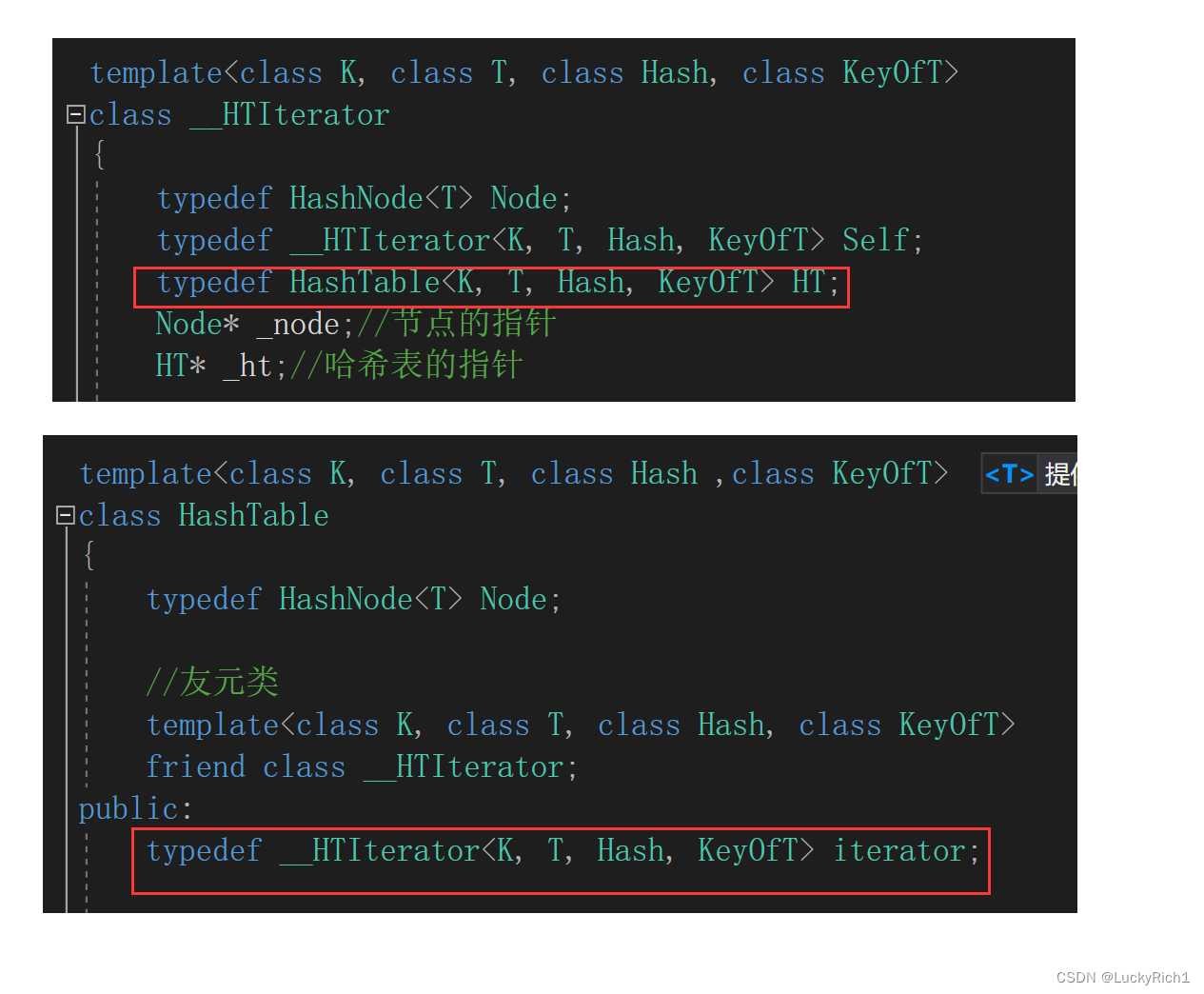
template<class K, class T, class Hash, class KeyOfT>
class __HTIterator
{
typedef HashNode<T> Node;
typedef __HTIterator<K, T, Hash, KeyOfT> Self;
Node* _node;//节点的指针
Self& operator++()
{
if (_node->_next)
{
_node = _node->_next;//遍历当前桶的所有节点
}
else
{
//当前桶走完,要找下一个桶的第一个节点
Hash hf;
KeyOfT kot;
size_t hashi = hf(kot(_node->_data)) % ;//计算当前在那个桶
}
}
};
要模表长,因此把表的指针传过去,当然也可以只把vector传过去。
template<class K, class T, class Hash, class KeyOfT>
class __HTIterator
{
typedef HashNode<T> Node;
typedef __HTIterator<K, T, Hash, KeyOfT> Self;
typedef HashTable<K, T, Hash, KeyOfT> HT;
Node* _node;//节点的指针
HT* _ht;//哈希表的指针
Self& operator++()
{
if (_node->_next)
{
_node = _node->_next;//遍历当前桶的所有节点
}
else
{
//当前桶走完,要找下一个桶的第一个节点
Hash hf;
KeyOfT kot;
size_t hashi = hf(kot(_node->_data)) % _ht->_tables.size();//计算当前在那个桶
}
}
};
但是vector在HashTable可是私有成员。这里不能直接用。

因此在HashTable声明一下__HTIterator是HashTable的友元类就可以用HashTable私有成员

Self& operator++()
{
//_node最开始指向第一个存数据桶的第一个节点
if (_node->_next)
{
_node = _node->_next;//遍历当前桶的所有节点
}
else
{
//当前桶走完,要找下一个存数据桶的第一个节点
Hash hf;
KeyOfT kot;
size_t hashi = hf(kot(_node->_data)) % _ht->_tables.size();//计算当前在那个桶
++hashi;//从下一个桶开始找
while (hashi < _ht->_tables.size())
{
if (_ht->_tables[hashi])
{
_node = _ht->_tables[hashi];//找到下一个存数据桶的第一个节点
break;
}
else
{
++hashi;
}
}
//走到表的结束,没找到下一个桶
if (hashi == _ht->_tables.size())
{
_node == nullptr;
}
}
return *this;
}
接下来我们把剩下的都补充一下,
template<class K, class T, class Hash, class KeyOfT>
class __HTIterator
{
typedef HashNode<T> Node;
typedef __HTIterator<K, T, Hash, KeyOfT> Self;
typedef HashTable<K, T, Hash, KeyOfT> HT;
Node* _node;//节点的指针
HT* _ht;//哈希表的指针
public:
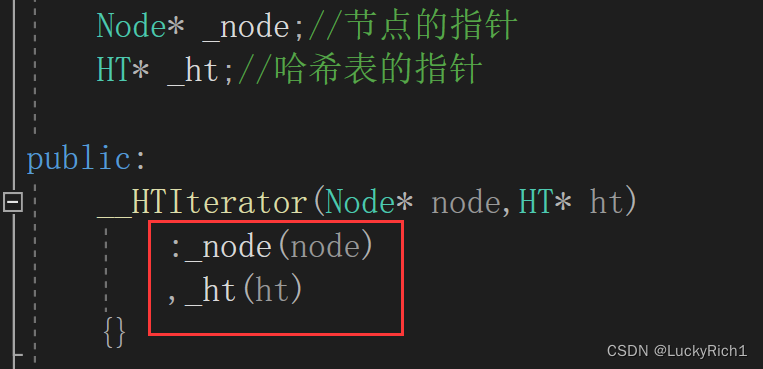
__HTIterator(Node* node,HT* ht)
:_node(node)
,_ht(ht)
{}
T& operator*()
{
return _node->_data;
}
T* operator->()
{
return &_node->_data;
}
bool operator!=(const Self& s)
{
return _node != s._node;
}
Self& operator++()
{
//_node最开始指向第一个存数据桶的第一个节点
if (_node->_next)
{
_node = _node->_next;//遍历当前桶的所有节点
}
else
{
//当前桶走完,要找下一个存数据桶的第一个节点
Hash hf;
KeyOfT kot;
size_t hashi = hf(kot(_node->_data)) % _ht->_tables.size();//计算当前在那个桶
++hashi;//从下一个桶开始找
while (hashi < _ht->_tables.size())
{
if (_ht->_tables[hashi])
{
_node = _ht->_tables[hashi];//找到下一个存数据桶的第一个节点
break;
}
else
{
++hashi;
}
}
//走到表的结束,没找到下一个桶
if (hashi == _ht->_tables.size())
{
_node == nullptr;
}
}
return *this;
}
};
在把哈希桶的begin和end写一下。
template<class K, class T, class Hash ,class KeyOfT>
class HashTable
{
typedef HashNode<T> Node;
//友元类
template<class K, class T, class Hash, class KeyOfT>
friend class __HTIterator;
public:
typedef __HTIterator<K, T, Hash, KeyOfT> iterator;
public:
iterator begin()
{
//找第一个桶
for (size_t i = 0; i < _tables.size(); ++i)
{
if (_tables[i])
return iterator(_tables[i], this);//哈希表对象的指针通过this得到
}
return iterator(nullptr, this);
}
iterator end()
{
//走到最后一个桶的最后一个节点在++就是nullptr
return iterator(nullptr, this);
}
//。。。
}
但是这里还有问题,会编译报错。

因为这里存在相互引用的问题,
迭代器要哈希表,哈希表要迭代器。
以前是容器要迭代器,迭代器在前面,容器就可以直接用迭代器了。但是现在存在相互引用的问题。
解决方法:把哈希表放在前面前置声明一下

这样就没问题了。
把unordered_map和unordered_set加上迭代器
//UnorderedMap.h
namespace wdl
{
template<class K,class V,class Hash=HashFunc<K>>
class unordered_map
{
struct MapKeyOfT
{
const K& operator()(const pair<const K, V>& kv)
{
return kv.first;
}
};
public:
typedef typename HashTable<K, pair<const K, V>, Hash, MapKeyOfT>::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
bool insert(const pair<K, V>& kv)
{
return _ht.Insert(kv);
}
private:
//第二个参数决定是KV模型
HashTable<K, pair<const K, V>, Hash, MapKeyOfT> _ht;
};
}
//UnorderedSet.h
namespace wdl
{
template<class K,class Hash = HashFunc<K>>
class unordered_set
{
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
public:
typedef typename HashTable<K, K, Hash, SetKeyOfT>::iterator iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
bool insert(const K& key)
{
return _ht.Insert(key);
}
private:
//第二个参数决定是K模型
HashTable<K, K, Hash, SetKeyOfT> _ht;
};
}
HashTable没有实例化不能区分iterator是一个静态变量还是内置类型,因为静态变量也可以这样用,因此加个typename告诉编译器这是一个类型,先不要报错等实例化之后在去取。
跑一下unordered_set的迭代器看一眼效果
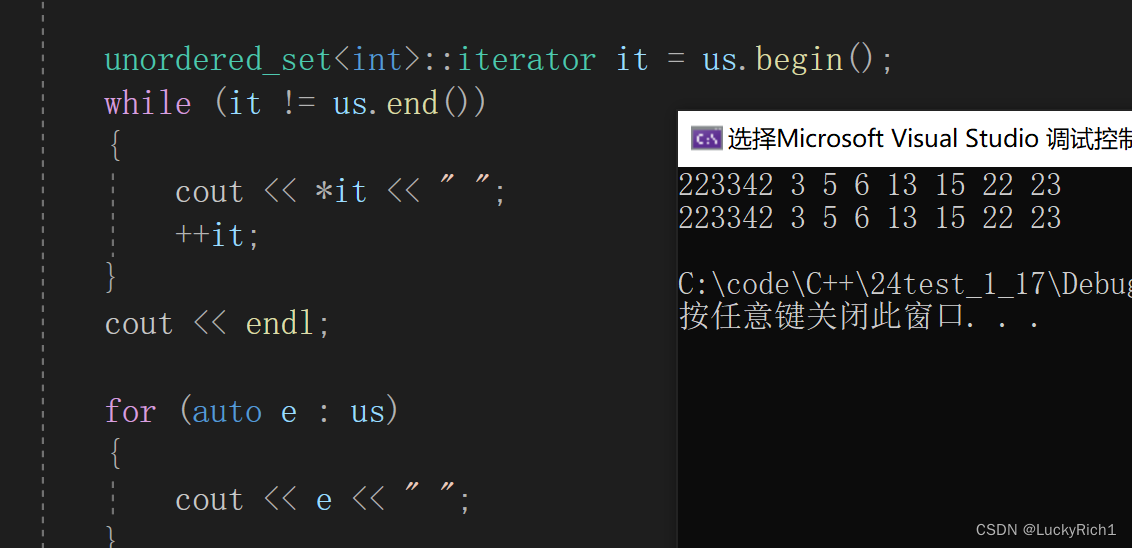
能正常跑是没错。
但真的没问题吗?
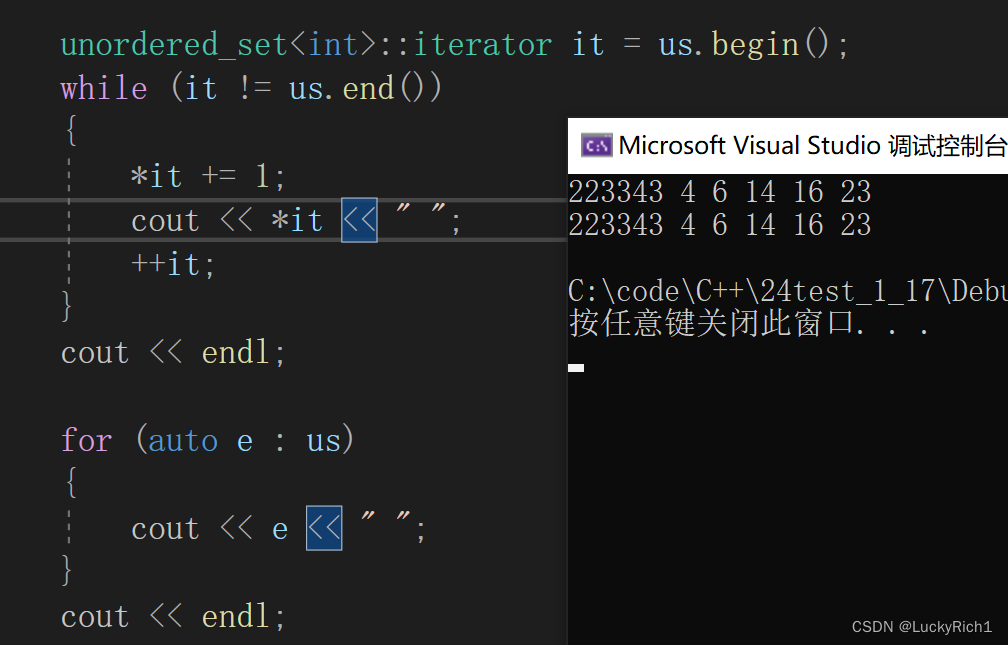
K模型竟然可以改变key值。
这里就如同模拟实现set一样的问题。所以unordered_set迭代器都改成const迭代器。

const迭代器
这里先和以前一样的实现。const迭代器和普通迭代器共用一个模板,因为参数传的不同,所以同一份模板可以实例化出不同对象
//前置声明
template<class K, class T, class Hash, class KeyOfT>
class HashTable;
template<class K, class T,class Ref,class Ptr, class Hash, class KeyOfT>
class __HTIterator
{
typedef HashNode<T> Node;
typedef __HTIterator<K, T, Ref, Ptr, Hash, KeyOfT> Self;
typedef HashTable<K, T, Hash, KeyOfT> HT;
Node* _node;//节点的指针
HT* _ht;//哈希表的指针
public:
__HTIterator(Node* node,HT* ht)
:_node(node)
,_ht(ht)
{}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
Self& operator++()
{
//_node最开始指向第一个存数据桶的第一个节点
if (_node->_next)
{
_node = _node->_next;//遍历当前桶的所有节点
}
else
{
//当前桶走完,要找下一个存数据桶的第一个节点
Hash hf;
KeyOfT kot;
size_t hashi = hf(kot(_node->_data)) % _ht->_tables.size();//计算当前在那个桶
++hashi;//从下一个桶开始找
while (hashi < _ht->_tables.size())
{
if (_ht->_tables[hashi])
{
_node = _ht->_tables[hashi];//找到下一个存数据桶的第一个节点
break;
}
else
{
++hashi;
}
}
//走到表的结束,没找到下一个桶
if (hashi == _ht->_tables.size())
{
_node = nullptr;
}
}
return *this;
}
bool operator!=(const Self& s)
{
return _node != s._node;
}
};
template<class K, class T, class Hash ,class KeyOfT>
class HashTable
{
typedef HashNode<T> Node;
//友元类
template<class K, class T,class Ref,class Ptr, class Hash, class KeyOfT>
friend class __HTIterator;
public:
typedef __HTIterator<K, T,T&,T*, Hash, KeyOfT> iterator;
typedef __HTIterator<K, T, const T&, const T*, Hash, KeyOfT> const_iterator;
public:
iterator begin()
{
//找第一个桶
for (size_t i = 0; i < _tables.size(); ++i)
{
if (_tables[i])
return iterator(_tables[i], this);
}
return iterator(nullptr, this);
}
iterator end()
{
return iterator(nullptr, this);
}
const_iterator begin() const
{
//找第一个桶
for (size_t i = 0; i < _tables.size(); ++i)
{
if (_tables[i])
return const_iterator(_tables[i], this);
}
return const_iterator(nullptr, this);
}
const_iterator end() const
{
return const_iterator(nullptr, this);
}
再把unordered_set的迭代器修改一下
namespace wdl
{
template<class K,class Hash = HashFunc<K>>
class unordered_set
{
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
public:
typedef typename HashTable<K, K, Hash, SetKeyOfT>::const_iterator iterator;
typedef typename HashTable<K, K, Hash, SetKeyOfT>::const_iterator const_iterator;
//加上const普通对象和const对象都能调用begin
//但是因此对象不同所以调用哈希表的begin也是不同的
//普通对象走普通的begin,const对象走const的begin
iterator begin() const
{
return _ht.begin();
}
iterator end() const
{
return _ht.end();
}
bool insert(const K& key)
{
return _ht.Insert(key);
}
private:
//第二个参数决定是K模型
HashTable<K, K, Hash, SetKeyOfT> _ht;
};
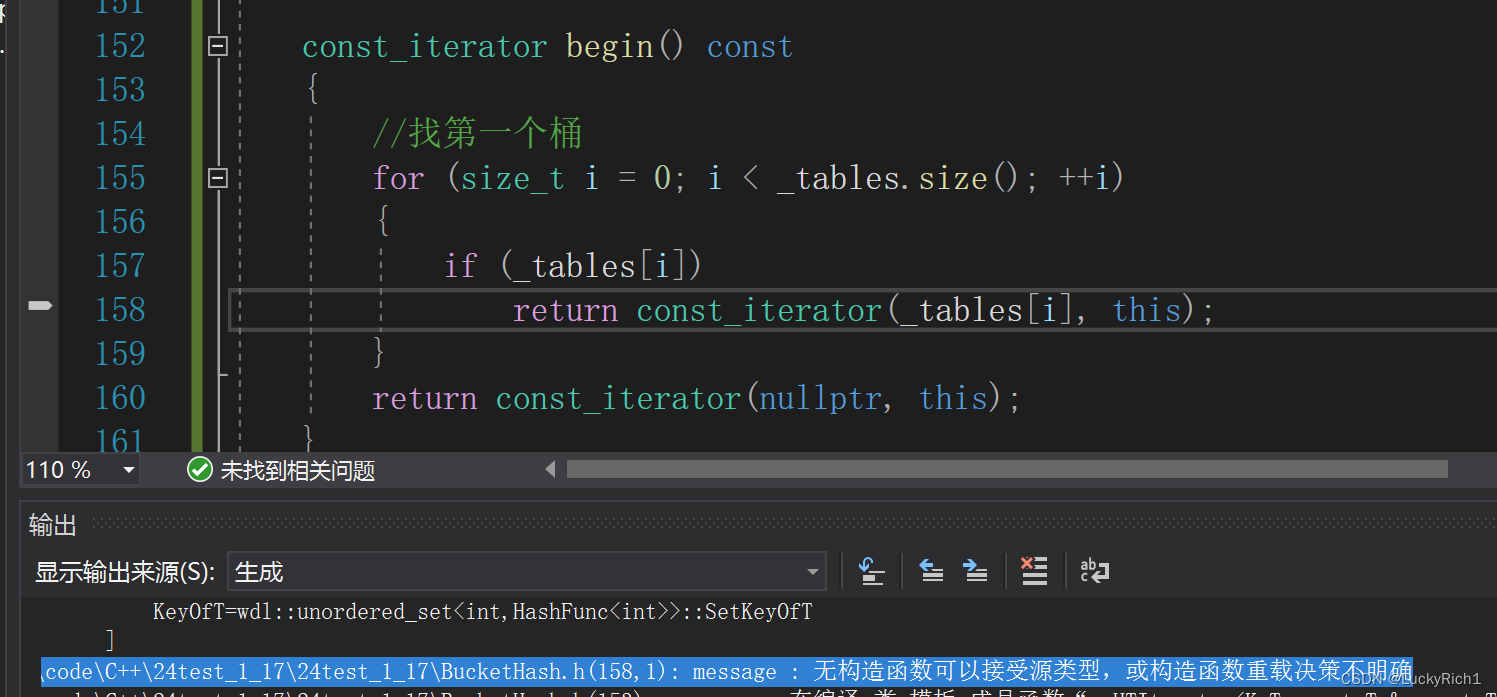
但是走const迭代器报了上面的错误。
无构造函数可以接受原类型,或者构造函数重载不明确。这是为什么?
难道哈希表的const迭代器写错了?我们看看库怎么写的。
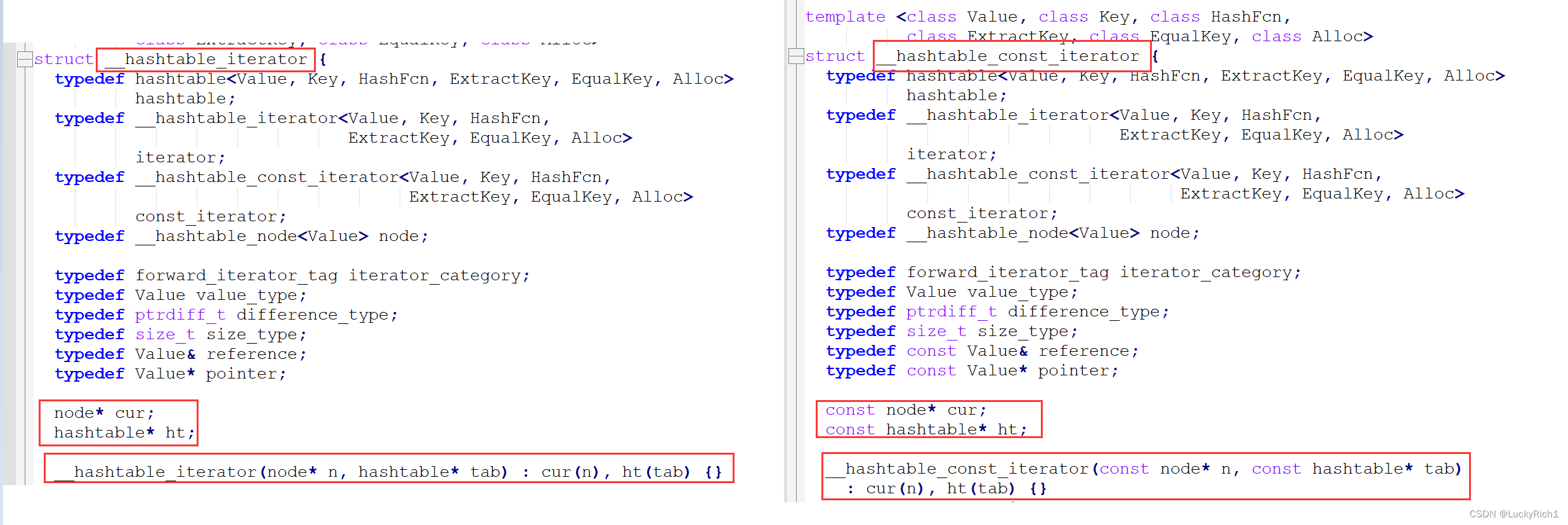
注意到库里是把普通迭代器和const迭代器分开写的。并且const迭代器的成员变量都加了const修饰。而且构造的的参数都加上const了。
而我们const迭代器和普通迭代器用的是同一个模板,但是这个模板在调用的是const迭代器构造的时候却没有const修饰参数。

问题的原因在于:
当const对象调用begin的时候走的是下面的begin。而我们在这个begin加了const修饰。这里面隐藏的this指针就变成了 ----> const HashTable* const this。const修饰*this不就是修饰对象本身吗,也就是说对象从一个普通对象变成了const对象。
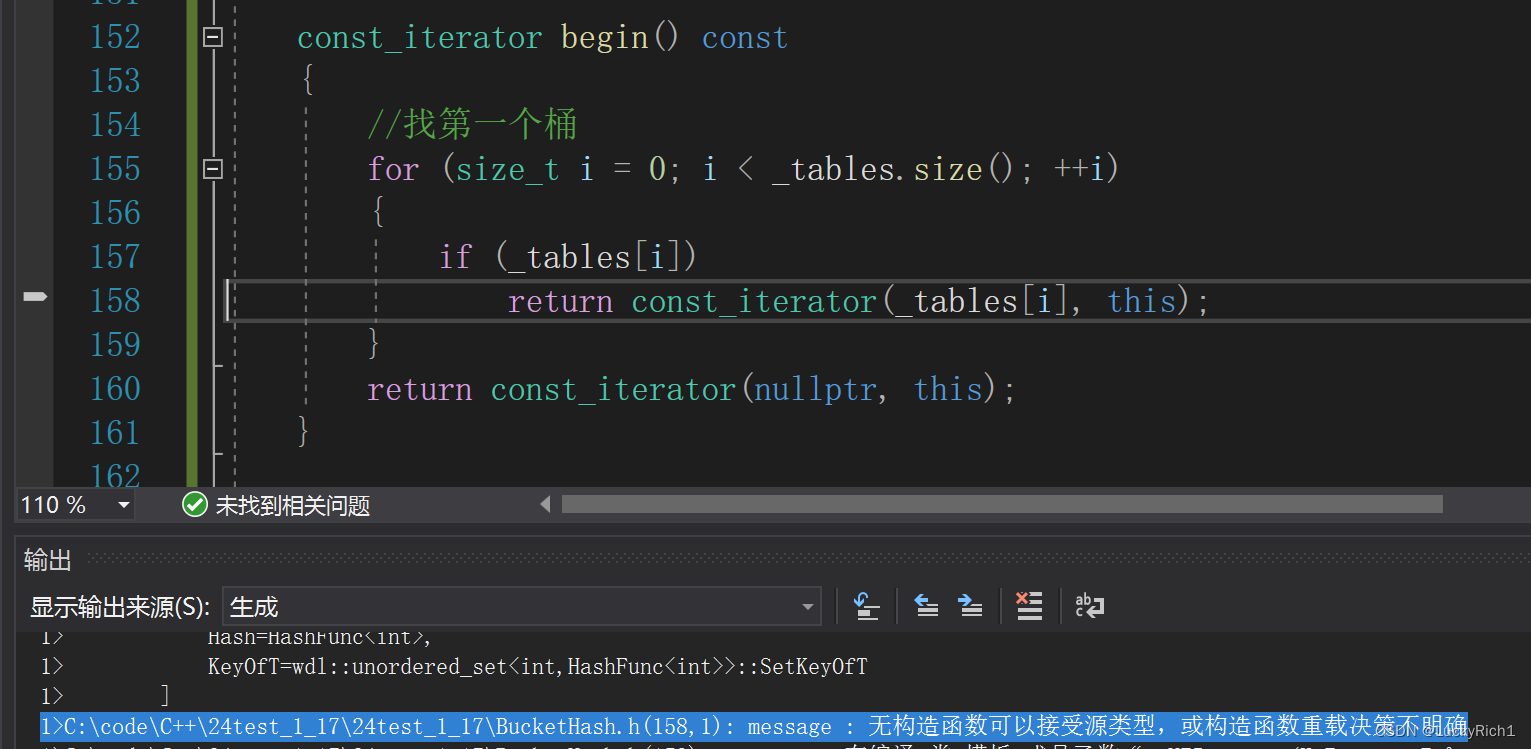
再看这个,调用的是vector的[ ]

你是const对象,那你调用vector的[ ]返回的就是const,所以说vector里面的也是const

然后调用const_iterator的构造,但是它和普通迭代器用的是同一个构造

以前说过,指针和引用赋值的权限只能平移或者缩小。但是现在你传过去权限相当于放大了。所以造成了错误!所以const迭代器的构造第一个参数要有const修饰,这样在传过去就是权限平移。不会有问题。并且表的指针也要加上const。
因为this也是const。
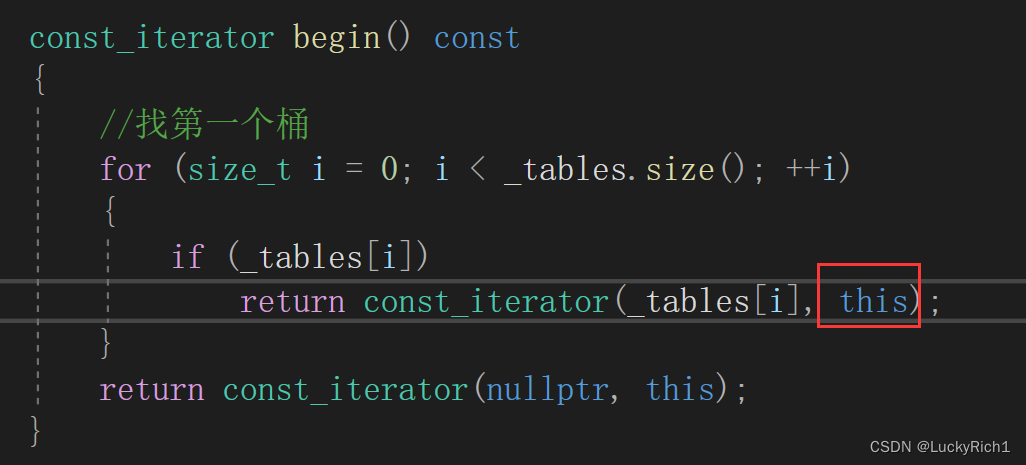
const迭代器成员变量也是const的原因是因为,这里构造的时候也涉及了权限的平移。
不过这里const迭代器还差一点点东西,我们现在回头把插入写完再说。
template<class K, class T, class Hash, class KeyOfT>
class __HTConstIterator
{
typedef HashNode<T> Node;
typedef __HTConstIterator<K, T, Hash, KeyOfT> Self;
typedef HashTable<K, T, Hash, KeyOfT> HT;
const Node* _node;//节点的指针
const HT* _ht;//哈希表的指针
public:
__HTConstIterator(const Node* node, const HT* ht)
:_node(node)
, _ht(ht)
{}
const T& operator*()
{
return _node->_data;
}
const T* operator->()
{
return &_node->_data;
}
Self& operator++()
{
//_node最开始指向第一个存数据桶的第一个节点
if (_node->_next)
{
_node = _node->_next;//遍历当前桶的所有节点
}
else
{
//当前桶走完,要找下一个存数据桶的第一个节点
Hash hf;
KeyOfT kot;
size_t hashi = hf(kot(_node->_data)) % _ht->_tables.size();//计算当前在那个桶
++hashi;//从下一个桶开始找
while (hashi < _ht->_tables.size())
{
if (_ht->_tables[hashi])
{
_node = _ht->_tables[hashi];//找到下一个存数据桶的第一个节点
break;
}
else
{
++hashi;
}
}
//走到表的结束,没找到下一个桶
if (hashi == _ht->_tables.size())
{
_node = nullptr;
}
}
return *this;
}
bool operator!=(const Self& s)
{
return _node != s._node;
}
};
现在有了迭代器,我们先把哈希表要用的到迭代器的插入和查找改一下
pair<iterator,bool> Insert(const T& data)
{
KeyOfT kot;
iterator it = Find(kot(data));
if (it != end())
return make_pair(it, false);//插入失败返回指向这个节点的指针和false
//负载因子控制在1,超过就扩容
if (_n == _tables.size())
{
vector<Node*> newtable;
//newtable.resize(_tables.size() * 2);
newtable.resize(__stl_next_prime(_tables.size()));
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
//头插到新表
while (cur)
{
Node* next = cur->_next;
size_t hashi = Hash()(kot(data)) % newtable.size();
cur->_next = newtable[hashi];
newtable[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newtable);//旧表和新表交换一下
}
//匿名对象去调用仿函数,算在第几个桶里面
int hashi = Hash()(kot(data)) % _tables.size();
//头插
Node* newnode = new Node(data);//调用Node的构造,因此Node写个构造
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
return make_pair(iterator(newnode,this),true);//插入返回新节点的指针和true
}
iterator Find(const K& key)
{
size_t hashi = Hash()(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (KeyOfT()(cur->_data) == key)
return iterator(cur,this);//找到返回指向这个节点的指针
else
cur = cur->_next;
}
return end();//没找到返回nullptr
}
再把unordered_set和unordered_map的插入修改一下
namespace wdl
{
template<class K,class V,class Hash=HashFunc<K>>
class unordered_map
{
struct MapKeyOfT
{
const K& operator()(const pair<const K, V>& kv)
{
return kv.first;
}
};
public:
typedef typename HashTable<K, pair<const K, V>, Hash, MapKeyOfT>::iterator iterator;
typedef typename HashTable<K, pair<const K, V>, Hash, MapKeyOfT>::const_iterator const_iterator;
pair<iterator, bool> insert(const pair<K, V>& kv)
{
return _ht.Insert(kv);
}
//。。。
private:
//第二个参数决定是KV模型
HashTable<K, pair<const K, V>, Hash, MapKeyOfT> _ht;
};
}
//UnorderedSet.h
namespace wdl
{
template<class K,class Hash = HashFunc<K>>
class unordered_set
{
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
public:
typedef typename HashTable<K, K, Hash, SetKeyOfT>::const_iterator iterator;
typedef typename HashTable<K, K, Hash, SetKeyOfT>::const_iterator const_iterator;
pair<iterator, bool> insert(const K& key)
{
return _ht.Insert(key);
}
//。。。
private:
//第二个参数决定是K模型
HashTable<K, K, Hash, SetKeyOfT> _ht;
};
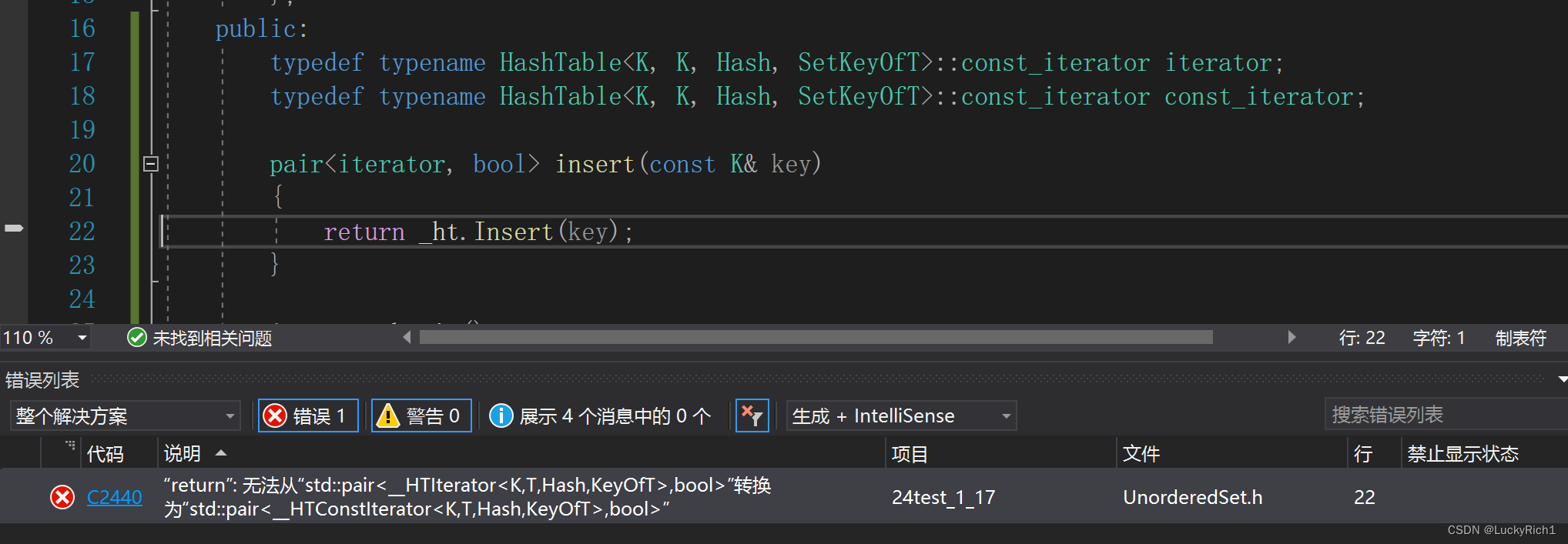
unordered_set的插入又报了老错误,返回类型不匹配的问题,因为unordered_set的迭代器都是const迭代器,而哈希表插入返回的普通迭代器。这里和库的解决方法一样。在const迭代器写一个拷贝构造函数,把iterator构造成const_iterator。
template<class K, class T, class Hash, class KeyOfT>
class __HTConstIterator
{
typedef HashNode<T> Node;
typedef __HTConstIterator<K, T, Hash, KeyOfT> Self;
typedef HashTable<K, T, Hash, KeyOfT> HT;
typedef __HTIterator< K, T, Hash, KeyOfT > iterator;
const Node* _node;//节点的指针
const HT* _ht;//哈希表的指针
public:
__HTConstIterator(const Node* node, const HT* ht)
:_node(node)
, _ht(ht)
{}
//拷贝构造,把iterator构造成const_iterator
__HTConstIterator(const iterator& it)
:_node(it._node)
,_ht(it._ht)
{}
//。。。
};
自此我们的const彻底写完了。
现在unordered_set的插入就没问题了,顺便也把unordered_map的插入补上
//UnorderedSet.h
namespace wdl
{
template<class K,class Hash = HashFunc<K>>
class unordered_set
{
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
public:
typedef typename HashTable<K, K, Hash, SetKeyOfT>::const_iterator iterator;
typedef typename HashTable<K, K, Hash, SetKeyOfT>::const_iterator const_iterator;
pair<iterator, bool> insert(const K& key)
{
//先用同一类型接收
pair<typename HashTable<K, K, Hash, SetKeyOfT>::iterator, bool> ret = _ht.Insert(key);
//在把iterator构造成const_iterator
return pair<iterator, bool>(ret.first, ret.second);
}
//。。。
private:
//第二个参数决定是K模型
HashTable<K, K, Hash, SetKeyOfT> _ht;
};
//UnorderedMap.h
namespace wdl
{
template<class K,class V,class Hash=HashFunc<K>>
class unordered_map
{
struct MapKeyOfT
{
const K& operator()(const pair<const K, V>& kv)
{
return kv.first;
}
};
public:
typedef typename HashTable<K, pair<const K, V>, Hash, MapKeyOfT>::iterator iterator;
typedef typename HashTable<K, pair<const K, V>, Hash, MapKeyOfT>::const_iterator const_iterator;
pair<iterator, bool> insert(const pair<K, V>& kv)
{
return _ht.Insert(kv);
}
//。。。
private:
//第二个参数决定是KV模型
HashTable<K, pair<const K, V>, Hash, MapKeyOfT> _ht;
};
}
unordered_map的插入直接返回就可以,因为用的是iterator,并且pair里面的K由const修饰,使用普通迭代器不能改变K。
unordered_map的[ ]接口实现
这个在【C++】map和set的使用及注意事项中map有详细介绍,这里不再叙述
V& operator[](const K& key)
{
pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));
return ret.first->second;
}
查找+修改
//UnorderedMap.h
iterator find(const K& key)
{
return _ht.Find(key);//这里直接返回
}
bool erase(const K& key)
{
return _ht.Erase(key);
}
//UnorderedSet.h
iterator find(const K& key)
{
return _ht.Find(key);//这里在返回的时候调用一下const_iterator的拷贝构造
}
bool erase(const K& key)
{
return _ht.Erase(key);
}
哈希桶完整代码
template<class T>
struct HashNode
{
T _data;
HashNode<T>* _next;
HashNode(const T& data)
:_data(data)
,_next(nullptr)
{}
};
//前置声明
template<class K, class T, class Hash, class KeyOfT>
class HashTable;
template<class K, class T,class Hash, class KeyOfT>
class __HTIterator
{
typedef HashNode<T> Node;
typedef __HTIterator<K, T,Hash, KeyOfT> Self;
typedef HashTable<K, T, Hash, KeyOfT> HT;
public:
Node* _node;//节点的指针
HT* _ht;//哈希表的指针
public:
__HTIterator(Node* node,HT* ht)
:_node(node)
,_ht(ht)
{}
T& operator*()
{
return _node->_data;
}
T* operator->()
{
return &_node->_data;
}
Self& operator++()
{
//_node最开始指向第一个存数据桶的第一个节点
if (_node->_next)
{
_node = _node->_next;//遍历当前桶的所有节点
}
else
{
//当前桶走完,要找下一个存数据桶的第一个节点
Hash hf;
KeyOfT kot;
size_t hashi = hf(kot(_node->_data)) % _ht->_tables.size();//计算当前在那个桶
++hashi;//从下一个桶开始找
while (hashi < _ht->_tables.size())
{
if (_ht->_tables[hashi])
{
_node = _ht->_tables[hashi];//找到下一个存数据桶的第一个节点
break;
}
else
{
++hashi;
}
}
//走到表的结束,没找到下一个桶
if (hashi == _ht->_tables.size())
{
_node = nullptr;
}
}
return *this;
}
bool operator!=(const Self& s)
{
return _node != s._node;
}
};
template<class K, class T, class Hash, class KeyOfT>
class __HTConstIterator
{
typedef HashNode<T> Node;
typedef __HTConstIterator<K, T, Hash, KeyOfT> Self;
typedef HashTable<K, T, Hash, KeyOfT> HT;
typedef __HTIterator< K, T, Hash, KeyOfT > iterator;
const Node* _node;//节点的指针
const HT* _ht;//哈希表的指针
public:
__HTConstIterator(const Node* node, const HT* ht)
:_node(node)
, _ht(ht)
{}
__HTConstIterator(const iterator& it)
:_node(it._node)
,_ht(it._ht)
{}
const T& operator*()
{
return _node->_data;
}
const T* operator->()
{
return &_node->_data;
}
Self& operator++()
{
//_node最开始指向第一个存数据桶的第一个节点
if (_node->_next)
{
_node = _node->_next;//遍历当前桶的所有节点
}
else
{
//当前桶走完,要找下一个存数据桶的第一个节点
Hash hf;
KeyOfT kot;
size_t hashi = hf(kot(_node->_data)) % _ht->_tables.size();//计算当前在那个桶
++hashi;//从下一个桶开始找
while (hashi < _ht->_tables.size())
{
if (_ht->_tables[hashi])
{
_node = _ht->_tables[hashi];//找到下一个存数据桶的第一个节点
break;
}
else
{
++hashi;
}
}
//走到表的结束,没找到下一个桶
if (hashi == _ht->_tables.size())
{
_node = nullptr;
}
}
return *this;
}
bool operator!=(const Self& s)
{
return _node != s._node;
}
};
template<class K, class T, class Hash ,class KeyOfT>
class HashTable
{
typedef HashNode<T> Node;
//友元类
template<class K, class T, class Hash, class KeyOfT>
friend class __HTIterator;
template<class K, class T, class Hash, class KeyOfT>
friend class __HTConstIterator;
public:
typedef __HTIterator<K, T,Hash, KeyOfT> iterator;
typedef __HTConstIterator<K, T, Hash, KeyOfT> const_iterator;
public:
iterator begin()
{
//找第一个桶
for (size_t i = 0; i < _tables.size(); ++i)
{
if (_tables[i])
return iterator(_tables[i], this);
}
return iterator(nullptr, this);
}
iterator end()
{
return iterator(nullptr, this);
}
const_iterator begin() const
{
//找第一个桶
for (size_t i = 0; i < _tables.size(); ++i)
{
if (_tables[i])
return const_iterator(_tables[i], this);
}
return const_iterator(nullptr, this);
}
const_iterator end() const
{
return const_iterator(nullptr, this);
}
HashTable()
:_n(0)//这里虽然没有明确写调用vector构造,但是编译器会按照声明顺序去调用的,所以会自动调用vecto的构造
{
//_tables.resize(10);//调用HashNode的构造
_tables.resize(__stl_next_prime(0));
}
~HashTable()
{
for (size_t i=0;i<_tables.size();++i)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_tables[i] = nullptr;
}
}//走到这里会自动调用vector的析构
HashTable(const HashTable<K,T,Hash,KeyOfT>& ht)
:_n(ht._n)
{
_tables.resize(ht._tables.size());
for (size_t i = 0; i < ht._tables.size(); ++i)
{
Node* cur = ht._tables[i];
if (cur)
{
Node* copy = new Node(cur->_kv);
_tables[i] = copy;
while (cur->_next)
{
cur = cur->_next;
//尾插
copy->_next = new Node(cur->_kv);
copy = copy->_next;
}
}
}
}
//赋值重载现代写法 复用拷贝构造
HashTable<K, T, Hash, KeyOfT>& operator=(HashTable<K, T, Hash, KeyOfT> ht)
{
_n = ht._n;
_tables.swap(ht._tables);
return *this;
}
pair<iterator,bool> Insert(const T& data)
{
KeyOfT kot;
iterator it = Find(kot(data));
if (it != end())
return make_pair(it, false);
//负载因子控制在1,超过就扩容
if (_n == _tables.size())
{
vector<Node*> newtable;
//newtable.resize(_tables.size() * 2);
newtable.resize(__stl_next_prime(_tables.size()));
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
//头插到新表
while (cur)
{
Node* next = cur->_next;
size_t hashi = Hash()(kot(data)) % newtable.size();
cur->_next = newtable[hashi];
newtable[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;
}
_tables.swap(newtable);//旧表和新表交换一下
}
//匿名对象去调用仿函数,算在第几个桶里面
int hashi = Hash()(kot(data)) % _tables.size();
//头插
Node* newnode = new Node(data);//调用Node的构造,因此Node写个构造
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_n;
return make_pair(iterator(newnode,this),true);
}
iterator Find(const K& key)
{
size_t hashi = Hash()(key) % _tables.size();
Node* cur = _tables[hashi];
while (cur)
{
if (KeyOfT()(cur->_data) == key)
return iterator(cur,this);
else
cur = cur->_next;
}
return end();
}
bool Erase(const K& key)
{
size_t hashi = Hash()(key) % _tables.size();
Node* cur = _tables[hashi];
Node* prev = nullptr;//记录被删节点前一个位置
while (cur)
{
if (cur->_kv.first == key)
{
if (cur == _tables[hashi])//被删节点是头一个节点
{
_tables[hashi] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
return true;
}
else
{
prev = cur;
cur = cur->_next;
}
}
return false;
}
inline unsigned long __stl_next_prime(unsigned long n)
{
static const int __stl_num_primes = 28;
static const unsigned long __stl_prime_list[__stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};//最大质数取得是靠近整型最大数得质数
for (size_t i = 0; i < __stl_num_primes; ++i)
{
if (__stl_prime_list[i] > n)
return __stl_prime_list[i];
}
//不用担心会哈希表会扩到最大质数,因为这时对于整型来说都已经差不多48G了
return __stl_prime_list[__stl_num_primes - 1];
}
private:
vector<Node*> _tables;
size_t _n;
};
unordered_map完整代码
template<class K>
struct HashFunc
{
//凡是能转成整型的就转成整型 如负数,如指针,如浮点数
//string不能转
size_t operator()(const K& key)
{
return (size_t)key;
}
};
//模板特化
template<>
struct HashFunc<string>
{
//BKDR
size_t operator()(const string& key)
{
size_t num = 0;
for (auto& ch : key)
{
num *= 131;
num += ch;
}
return num;
}
};
namespace wdl
{
template<class K,class V,class Hash=HashFunc<K>>
class unordered_map
{
struct MapKeyOfT
{
const K& operator()(const pair<const K, V>& kv)
{
return kv.first;
}
};
public:
typedef typename HashTable<K, pair<const K, V>, Hash, MapKeyOfT>::iterator iterator;
typedef typename HashTable<K, pair<const K, V>, Hash, MapKeyOfT>::const_iterator const_iterator;
pair<iterator, bool> insert(const pair<K, V>& kv)
{
return _ht.Insert(kv);
}
V& operator[](const K& key)
{
pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));
return ret.first->second;
}
iterator find(const K& key)
{
return _ht.Find(key);
}
bool erase(const K& key)
{
return _ht.Erase(key);
}
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
const_iterator begin() const
{
return _ht.begin();
}
const_iterator end() const
{
return _ht.end();
}
private:
//第二个参数决定是KV模型
HashTable<K, pair<const K, V>, Hash, MapKeyOfT> _ht;
};
}
unordered_set完整代码
template<class K>
struct HashFunc
{
//凡是能转成整型的就转成整型 如负数,如指针,如浮点数
//string不能转
size_t operator()(const K& key)
{
return (size_t)key;
}
};
//模板特化
template<>
struct HashFunc<string>
{
//BKDR
size_t operator()(const string& key)
{
size_t num = 0;
for (auto& ch : key)
{
num *= 131;
num += ch;
}
return num;
}
};
namespace wdl
{
template<class K,class Hash = HashFunc<K>>
class unordered_set
{
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
public:
typedef typename HashTable<K, K, Hash, SetKeyOfT>::const_iterator iterator;
typedef typename HashTable<K, K, Hash, SetKeyOfT>::const_iterator const_iterator;
pair<iterator, bool> insert(const K& key)
{
pair<typename HashTable<K, K, Hash, SetKeyOfT>::iterator, bool> ret = _ht.Insert(key);
return pair<iterator, bool>(ret.first, ret.second);
}
iterator find(const K& key)
{
return _ht.Find(key);
}
bool erase(const K& key)
{
return _ht.Erase(key);
}
iterator begin() const
{
return _ht.begin();
}
iterator end() const
{
return _ht.end();
}
private:
//第二个参数决定是K模型
HashTable<K, K, Hash, SetKeyOfT> _ht;
};
}
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- AAAI2024 | 论文接受列表,含全部论文下载(持续更新......)
- 强化学习(二)多臂老虎机 “Multi-armed Bandits”——2
- ARO Robot Dynamics
- 讯飞星火认知大模型智能语音交互调用
- 2022年全国职业院校技能大赛网络安全竞赛试题1-10-B模块总结
- 面试算法112:最长递增路径
- GC6153国产芯片——低噪声、低振动,应用于摄像机,机器人等产品上
- Chromadb词向量数据库总结
- C语言作业练习:求“水仙花数”
- Nature Methods - method to watch 用于基因组学的大模型