大模型基础2
发布时间:2024年01月18日
大模型基础2
第二章:大模型的能力
语言模型的适应性:从语言模型到任务模型的转化
- 语言模型转化为任务模型的过程称为"适应":
- 任务的自然语言描述
- 一组训练实例(输入-输出对)
- 进行适应的两个种方法:
- 训练(标准的有监督学习)
- 提示(上下文)学习
- 零样本学习(Zero-shot):提示/上下文信息的数量为0,模型直接基于对任务的理解输出结果。
- 单样本学习(One-shot):提示/上下文信息的数量为1,一般来说模型基于1个例子可以更好的理解任务从而较好的生成结果。
- 少样本学习(Few-shot):提示/上下文信息的数量大于1,大模型可以看到更丰富的例子,一般来说获得比单样本学习更好的效果。
Language Modeling
-
困惑度,自然语言处理和语言模型中的一个重要概念,用于衡量语言模型的性能(如果一个模型的困惑度较低,那么它在预测下一个词的时候就会更加准确。)
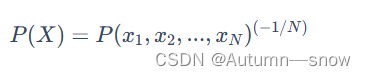
-
语言模型可能会犯两种类型的错误,而困惑度对这两种错误的处理方式并不对称:
-
召回错误
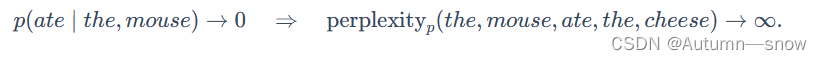
-
精确度错误

-
-
Penn Tree Bank:是自然语言处理中的一个经典数据集,最初是为了进行句法解析而标注的。
- 适应性测试
- 评估其困惑度
-
LAMBADA
- 预测句子的最后一个词:解决这个任务需要对较长的内容进行建模,并对较长的内容具有一定的依赖。
-
HellaSwag:
- 动机:评估模型进行常识推理的能力
- 任务:从一系列选择中选出最适合完成句子的选项
Question answering
- TriviaQA
- 任务:给定一问题后生成答案 原始数据集是由业余爱好者收集的,并被用作开放式阅读理解的挑战,但我们用它来进行(闭卷)问题回答。
- WebQuestions
- 任务:和TriviaQA类似是问答任务 数据集从Google搜索查询中收集,最初用于对知识库的问题回答。
- NaturalQuestions
- 任务:回答问题 从Google搜索查询中收集的数据集(区别在于答案的长度较长)
Translation
- 翻译任务是将源语言(例如,德语)中的句子翻译成目标语言(例如,英语)中的句子。
Arithmetic
- GPT-3是一个语言模型(主要是英语),但我们可以在一系列更“抽象推理”的任务上评估它,以评估GPT-3作为更通用模型的性能。
News article generation
- 任务:给定标题和副标题,生成新闻文章。
Novel tasks
- 使用新词
- 纠正英语语法
Other tasks
- SWORDS:词汇替换,目标是在句子的上下文中预测同义词。
- Massive Multitask Language Understanding:包括数学,美国历史,计算机科学,法律等57个多选问题。
- TruthfulQA:人类由于误解而错误回答的问答数据集。
文章来源:https://blog.csdn.net/Autumn_snow/article/details/135662288
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- [NOIP2008 普及组] 传球游戏
- 小型肉制品厂废水处理设备加工厂家
- 哨兵1号回波数据(L0级)FDBAQ压缩算法详解
- 利用 LangChain 和 Neo4j 向量索引,构建一个RAG应用程序
- Java学习,一文掌握Java之SpringBoot框架学习文集(6)
- 阻塞队列实现
- 数学模型与数学建模(急救版80+)常考知识点(三)
- 西北工业大学计算机组成原理实验报告——verilog前两次
- 【算法】动态中位数(对顶堆)
- 网站监测工具的极与极,Site24x7 与百川云