MongoDB5.x学习笔记
一、概述
官方文档:https://www.mongodb.com/docs/manual/
菜鸟教程:https://www.runoob.com/mongodb/mongodb-tutorial.html
1、MongoDB简介
1.1 简介
MongoDB是一个基于分布式文件存储的数据库(支持集群、分片处理)。由C++语言编写。旨在为WEB应用提供可扩展高性能的数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品(偏向于非关系型数据库NoSQL),是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似json的bson格式(对json进行扩展),因此可以存储比较复杂的数据类型。MongoDB最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
总结: mongoDB是一个非关系型文档数据库
1.2 发展历史
- 2009年2月,MongoDB数据库首次在数据库领域亮相,打破了关系型数据库一统天下的局面;
- 2010年8月, MongoDB 1.6发布。这个版本最大的一个功能就是Sharding—自动分片;
- 2014年12月, MongoDB 3.0发布。由于收购了WiredTiger 存储引擎,大幅提升了MongoDB的写入性能;
- 2015年12月,3.2版本发布,开始支持了关系型数据库的核心功能:关联。你可以一次同时查询多个MongoDB的集合。
- 2016年, MongoDB推出Atlas,在AWS、 Azure 和GCP上的MongoDB托管服务;
- 2017年10月,MongoDB成功在纳斯达克敲钟,成为26年来第一家以数据库产品为主要业务的上市公司。
- 2018年6月, MongoDB4.0 发布推出ACID事务支持,成为第一个支持强事务的NoSQL数据库;
- 2018年–至今,MongoDB已经从一个在数据库领域籍籍无名的“小透明”,变成了话题度和热度都很高的“流量”数据库。
1.3 特点
- 面向集合存储,易存储对象类型的数据
- 支持查询以及动态查询
- 支持RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言
- 文件存储格式为BSON(一种JSON的扩展)
- 支持复制和故障恢复和分片
- 支持事务支持(要求性不高,不能完全取代关系型数据库)
- 索引、聚合、关联
1.4 应用场景
- 游戏应用:使用云数据库MongoDB作为游戏服务器的数据库存储用户信息。用户的游戏装备、积分等直接以内嵌文档的形式存储,方便进行查询与更新
- 物流应用:使用云数据库MongoDB存储订单信息,订单状态在运送过程中会不断更新,以云数据库MongoDB内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来,方便快捷且一目了然
- 社交应用:使用云数据库MongoDB存储用户信息以及用户发表的朋友圈信息,通过地理位置索引实现附近的人、地点等功能。并且,云数据库MongoDB非常适合用来存储聊天记录,因为它提供了非常丰富的查询,并在写入和读取方面都相对较快
- 视频直播:使用云数据库MongoDB存储用户信息、礼物信息等。
- 大数据应用:使用云数据库MongoDB作为大数据的云存储系统,随时进行数据提取分析,掌握行业动态
2、MongoDB安装
2.1 原生安装
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-ubuntu2004-5.0.19.tgz
# 解压缩
tar -zxf mongodb-linux-x86_64-ubuntu2004-5.0.19.tgz
mv mongodb-linux-x86_64-ubuntu2004-5.0.19 mongodb
cd mongodb/bin
# bin目录用来存放启动mongoDB的服务以及客户端链接的脚本文件等
# 启动 MongoDB 服务
# --port 指定服务监听端口号 默认为 27017
# --dbpath 指定 mongodb 数据存放目录 启动要求目录必须存在
# --logpath 指定 mongodb 日志文件存放位置
./mongod --port=27017 --dbpath=../data --bind_ip=0.0.0.0 --logpath=../logs/mongo.log
# 5.x后需要确保cpu支持向量指令集,grep avx /proc/cpuinfo
# 客户端连接
./mongo --port=27017
下面是5.0.5版本和4.4.10版本配置文件启动,可以进行参考,机器环境为centos
# ======================5.05===========================
## 下载
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel80-5.0.5.tgz
## 解压
tar -zxvf mongodb-linux-x86_64-rhel80-5.0.5.tgz
## 重命名
mv mongodb-linux-x86_64-rhel80-5.0.5 mongodb5.0.5
## 进入mongodb
cd mongodb5.0.5
## 修改数据日志文件路径
mkdir -p /opt/home/mongodb5.0.5/data
mkdir -p /opt/home/mongodb5.0.5/log
touch /opt/home/mongodb5.0.5/log/mongod.log
## 设置权限
chmod -R 777 /opt/home/mongodb5.0.5/data
chmod -R 777 /opt/home/mongodb5.0.5/log
chmod -R 777 /opt/home/mongodb5.0.5/log/mongod.log
## 进入mongodb安装的bin目录下
cd /opt/home/mongodb5.0.5/bin
## 创建mongodb.conf文件
vim mongodb.conf
## 添加下面的文件
#数据文件存放目录
dbpath = /opt/home/mongodb5.0.5/data
#日志文件存放地址
logpath =/opt/home/mongodb5.0.5/log/mongod.log
#端口
port = 27017
#以守护程序的方式启用,即在后台运行
fork = true
#需要认证。如果放开注释,就必须创建MongoDB的账号,使用账号与密码才可>远程访问,第一次安装建议注释
#auth=true
#允许远程访问,或者直接注释,127.0.0.1是只允许本地访问
bind_ip=0.0.0.0
## 配置环境变量
vim /etc/profile
## mongodb
export PATH=/opt/home/mongodb5.0.5/bin:$PATH
## 使配置文件生效
source /etc/profile
## 启动
./mongod --config ./mongodb.conf
## 测试
./mongo
> 1+2
3
# ============================4.4.10版本=============================
## 下载
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel80-4.4.10.tgz
## 解压
tar -zxvf mongodb-linux-x86_64-rhel80-4.4.10.tgz
## 重命名
mv mongodb-linux-x86_64-rhel80-4.4.10 mongodb4.4.10
## 配置环境变量
vim /etc/profile
# mongodb
export PATH=/opt/home/mongodb4.4.10/bin:$PATH
## 使配置文件生效
source /etc/profile
## 修改数据日志文件路径
mkdir -p /opt/home/mongodb4.4.10/data
mkdir -p /opt/home/mongodb4.4.10/log
touch /opt/home/mongodb4.4.10/log/mongod.log
## 设置权限
chmod -R 777 /opt/home/mongodb4.4.10/data
chmod -R 777 /opt/home/mongodb4.4.10/log
chmod -R 777 /opt/home/mongodb4.4.10/log/mongod.log
## 进入mongodb安装的bin目录下
cd /opt/home/mongodb4.4.10/bin
## 创建mongodb.conf文件
vim mongodb.conf
#数据文件存放目录
dbpath = /opt/home/mongodb4.4.10/data
#日志文件存放地址
logpath =/opt/home/mongodb4.4.10/log/mongod.log
#端口
port = 27017
#以守护程序的方式启用,即在后台运行
fork = true
#需要认证。如果放开注释,就必须创建MongoDB的账号,使用账号与密码才可>远程访问,第一次安装建议注释
#auth=true
#允许远程访问,或者直接注释,127.0.0.1是只允许本地访问
bind_ip=0.0.0.0
## 启动
./mongod --config ./mongodb.conf
2.2 docker安装
docker pull mongo:5.0.18
# 运行 mongo 镜像
docker run -d --name mongo -p 27017:27017 mongo:5.0.18
docker exec -it mongo bash
# 连接
mongo --port=27017
2.3 快捷安装
# 安装 MongoDB
sudo apt-get install mongodb
# 查看版本号
mongod -version
# 启动和关闭 MongoDB 服务
service mongodb start
service mongodb stop
# 查看 MongoDB 服务是否启动成功
service mongodb status
pgrep mongo -l
# 卸载 MongoDB
sudo apt-get --purge remove mongodb mongodb-clients mongodb-server
二、核心概念
1、概述
库<DataBase>
mongodb中的库就类似于传统关系型数据库中库的概念,用来通过不同库隔离不同应用数据。 mongodb中可以建立多个数据库。每一个库都有自己的集合和权限,不同的数据库也放置在不同的文件中。默认的数据库为"test",数据库存储在启动指定的data目录中。
**集合<Collection>**集合就是 MongoDB 文档组,类似于 RDBMS (关系数据库管理系统:Relational Database Management System)中的表的概念。集合存在于数据库中,一个库中可以创建多个集合。每个集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性
文档<Document>
文档集合中一条条记录,是一组键值(key-value)对(即 BSON)。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。
| RDBMS | MongoDB |
|---|---|
| 数据库<database> | 数据库<database> |
| 表<table> | 集合<collection> |
| 行<row> | 文档<document> |
| 列<colume> | 字段<field> |
2、数据库常用操作
2.1 库和集合操作
# 首先进入客户端
# 查看所有库,默认时test
show databases; | show dbs;
# admin: 从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。
# local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合。
# config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
# 创建数据库
# 注意: use 代表创建并使用,当库中没有数据时默认不显示这个库
use 库名
# 删除数据库
# 默认删除当前选中的库
db.dropDatabase() #注意此处有括号
# 查看当前所在库
db
# ======================集合===============
# 查看库中所有集合
show collections; | show tables;
# 创建集合
db.createCollection('集合名称', [options])
# options可以是如下参数
# capped 布尔 (可选)如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。 当该值为 true 时,必须指定 size 参数
# size 数值 (可选)为固定集合指定一个最大值,即字节数。 如果 capped 为 true,也需要指定该字段
# max 数值 (可选)指定固定集合中包含文档的最大数量
# 注意:当集合不存在时,向集合中插入文档也会自动创建该集合
# 删除集合,如果成功删除选定集合,则 drop() 方法返回 true,否则返回 false
db.集合名称.drop();
2.2 文档操作
https://www.mongodb.com/docs/manual/reference/method/
# ========================插入文档==================
# 单条文档
db.集合名称.insert(document)
db.users.insert({"name":"shawn","age":23,"bir":"2012-12-12"});
db.users.insertOne({"name":"shawn","age":23,"bir":"2012-12-12"});
# 多条文档
db.collection.insertMany() # 向指定集合中插入多条文档数据【推荐使用】
db.集合名称.insertMany(
[ <document 1> , <document 2>, ... ],
{
writeConcern: 1,//写入策略,默认为1,即要求确认写操作,0是不要求。
ordered: true //指定是否按顺序写入,默认true,按顺序写入。
}
)
db.users.insert([
{"name":"shawn","age":23,"bir":"2012-12-12"},
{"name":"小黑","age":25,"bir":"2012-12-12"}
]);
# 脚本方式
for(let i=0;i<100;i++){
db.users.insert({"_id":i,"name":"编程不良人_"+i,"age":23});
}
# 注意:在mongodb中每个文档都会有一个_id作为唯一标识,_id默认会自动生成,如果手动指定将使用手动指定的值作为_id 的值
# ========================查询====================
# 查询所有
db.集合名称.find();
# =====================删除文档===================
db.集合名称.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
db.集合名称.deleteMany({query}) #不指定条件时删除集合下全部文档
# query :可选删除的文档的条件
# justOne : 可选如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值 false,则删除所有匹配条件的文档。
# writeConcern :可选抛出异常的级别。默认为writeConcern.NONE
db.users.deleteMany({});
db.users.deleteMany({age:23});
# 文档内容全部删除后,文档仍存在,即删除内容,不删除结构。
# =======================更新文档=======================
db.集合名称.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
);
# 参数说明:
# query : update的查询条件,类似sql update查询内where后面的。
# update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
# upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
# multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
# writeConcern :可选,抛出异常的级别。
# WriteConcern.NONE:没有异常抛出
# WriteConcern.NORMAL:仅抛出网络错误异常,没有服务器错误异常
# WriteConcern.SAFE:抛出网络错误异常、服务器错误异常;并等待服务器完成写操作。
# WriteConcern.MAJORITY: 抛出网络错误异常、服务器错误异常;并等待一个主服务器完成写操作。
# WriteConcern.FSYNC_SAFE: 抛出网络错误异常、服务器错误异常;写操作等待服务器将数据刷新到磁盘。
# WriteConcern.JOURNAL_SAFE:抛出网络错误异常、服务器错误异常;写操作等待服务器提交到磁盘的日志文件。
# WriteConcern.REPLICAS_SAFE:抛出网络错误异常、服务器错误异常;等待至少2台服务器完成写操作。
# 这个更新是将符合条件的全部更新成后面的文档,相当于先删除在更新
db.集合名称.update({"name":"zhangsan"},{name:"11",bir:new date()})
# 保留原来数据更新,但是只更新符合条件的第一条数据
db.集合名称.update({"name":"xiaohei"},{$set:{name:"mingming"}})
# 保留原来数据更新,更新符合条件的所有数据
db.集合名称.update({name:”小黑”},{$set:{name:”小明”}},{multi:true})
# 保留原来数据更新,更新符合条件的所有数据,没有条件符合时插入数据
db.集合名称.update({name:”小黑”},{$set:{name:”小明”}},{multi:true,upsert:true})
2.3 文档查询
# MongoDB 查询文档使用 find() 方法。find() 方法以非结构化的方式来显示所有文档。
db.集合名称.find(query, projection)
# query :可选,使用查询操作符指定查询条件
# projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。
# 如果你需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下
db.集合名称.find().pretty()
# 条件运算符
db.集合名.find({age:30}); # 查找 age=30 的数据
db.集合名.find({age:{$lt:30}}); # 查找 age<30 的数据
db.集合名.find({age:{$lte:30}}); # 查找 age<=30 的数据
db.集合名.find({age:{$gt:30}}); # 查找 age>30 的数据
db.集合名.find({age:{$gte:30}}); # 查找 age>=30 的数据
db.集合名.find({age:{$ne:30}}); # 查找 age!=30 的数据
# AND
db.集合名称.find({key1:value1, key2:value2,...}).pretty()
# 类似于 WHERE 语句:WHERE key1=value1 AND key2=value2
db.users.find({"age":27,"name":"欧力给",_id:8});
db.users.find({"age":3,"age":27}); # 同一字段多次出现查询条件时,只有最后的查询条件才生效,即后面会覆盖前面的查询条件
# OR
# MongoDB OR 条件语句使用了关键字 $or,语法格式如下:
db.集合名称.find({$or: [{key1: value1}, {key2:value2}]}).pretty()
db.users.find({$or:[{_id:3},{age:15}]});
# AND 和 OR 联合
db.users.find({age:{$gt:15},$or:[{_id:3},{age:15}]});
# 数组中查询
db.集合名称.insert({ "_id" : 11, "age" : 29, "likes" : [ "看电视", "读书xx", "美女" ], "name" : "shawn_xx_11" })
# 执行数组查询
db.users.find({likes:"看电视"})
# $size 按照数组长度查询
db.users.find({likes:{$size:3}});
# 模糊查询
# 注意:在 mongoDB 中使用正则表达式可以是实现近似模糊查询功能
db.users.find({likes:/shawn/});
# 排序,1 升序 -1 降序
db.集合名称.find().sort({name:1,age:1})
# 分页
db.集合名称.find().sort({条件}).skip(start).limit(rows);
# 总条数
db.集合名称.count()
db.集合名称.find({"name":"shawn"}).count();
# 去重
db.集合名称.distinct('字段')
db.users.distinct("age");
# 指定返回字段
# 参数2: 1 返回 0 不返回
db.集合名称.find({条件},{name:1,age:1})
# db.users.find({},{"name":1});查询所有,返回指定字段
# db.users.find({age:{$lt:17}},{name:1});按照指定条件查询,返回指定字段
# db.users.find({age:{$lt:17}},{_id:0,name:1});按照指定条件查询,返回指定字段,不返回id,注意id是唯一索引
2.4 $type
$type操作符是基于BSON类型来检索集合中匹配的数据类型,并返回结果
# 如果想获取 "col" 集合中 title 为 String 的数据,你可以使用以下命令
db.col.find({"title" : {$type : 2}}).pretty();
db.col.find({"title" : {$type : 'string'}}).pretty();
# 如果想获取 "col" 集合中 tags 为 Array 的数据,你可以使用以下命令:
db.col.find({"tags":{$type : 4}}).pretty();
db.col.find({"tags" : {$type : 'array'}}).pretty();
3、索引<index>
3.1 原理
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。 默认_id已经创建了索引
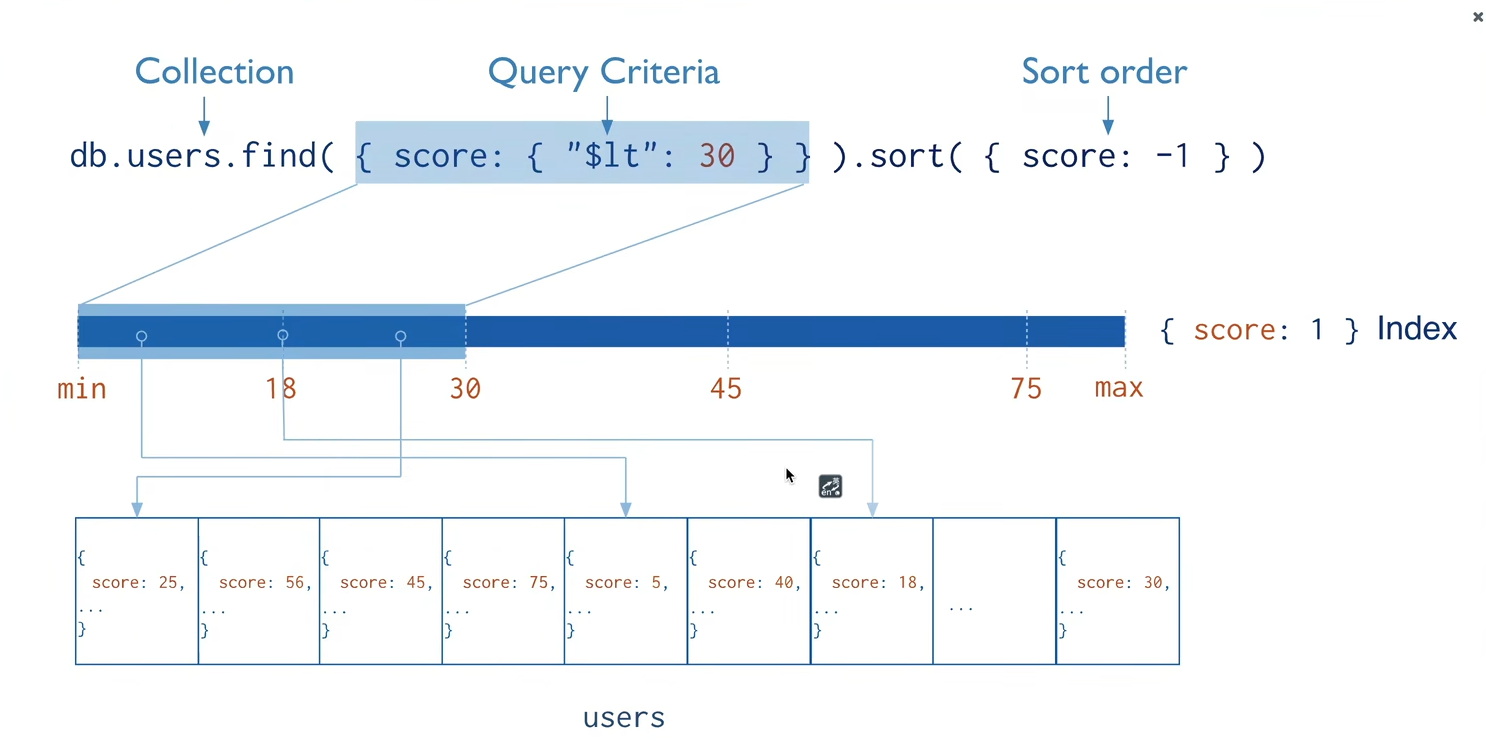
3.2 索引操作
# 索引创建
# 说明: 语法中 Key 值为你要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可
db.集合名称.createIndex(keys, options)
db.集合名称.createIndex({"title":1,"description":-1})
# 查看集合索引
db.集合名称.getIndexes()
# 普通索引,key 为要创建索引的字段,1 为指定升序创建索引,降序可以指定为 -1
db.集合名.ensureIndex({key:1});
# 唯一索引
db.集合名.ensureIndex({key:1},{unique:true});
# 查看集合索引大小
db.集合名称.totalIndexSize()
# 删除集合所有索引(不包含_id索引)
db.集合名称.dropIndexes()
# 删除集合指定索引
db.集合名称.dropIndex("索引名称")
# 查看 explain 执行计划---查看函数执行信息
db.集合名.find({age:6}).explain();
createIndex() 接收可选参数,可选参数列表如下:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 “background” 可选参数。 “background” 默认值为false |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
3.3 复合索引
一个索引的值是由多个 key 进行维护的索引的称之为复合索引
db.集合名称.createIndex({"title":1,"description":-1})
# 注意: mongoDB 中复合索引和传统关系型数据库一致都是左前缀匹配原则
4、聚合<aggregate>
MongoDB 中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似 SQL 语句中的 count(*)
# 测试用例
db.test.insertMany([
{
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by_user: 'runoob.com',
url: 'http://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
title: 'NoSQL Overview',
description: 'No sql database is very fast',
by_user: 'runoob.com',
url: 'http://www.runoob.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 10
},
{
title: 'Neo4j Overview',
description: 'Neo4j is no sql database',
by_user: 'Neo4j',
url: 'http://www.neo4j.com',
tags: ['neo4j', 'database', 'NoSQL'],
likes: 750
}
]);
# 现在我们通过以上集合计算每个作者所写的文章数,使用aggregate()计算结果如下
# 注意:此处的_id是分组表示,不是文档的 _id
db.test.aggregate([{$group : {
_id : "$by_user",
num_tutorial : {$sum : 1}
}}])
常见聚合表达式
# $sum,计算总和
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}])
# $avg,计算平均值
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}])
# $min,获取集合中所有文档对应值得最小值
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}])
# $max,获取集合中所有文档对应值得最大值
db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}])
# $push,将值加入一个数组中,不会判断是否有重复的值
db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}])
# $addToSet,将值加入一个数组中,会判断是否有重复的值,若相同的值在数组中已经存在了,则不加入
db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}])
# $first,根据资源文档的排序获取第一个文档数据
db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}])
# $last,根据资源文档的排序获取最后一个文档数据
db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}])
三、应用整合
1、SpringBoot整合
1.1 环境配置
创建springboot工程羡慕,引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
编写配置
# mongodb 没有开启任何安全协议
# mongodb(协议)://121.5.167.13(主机):27017(端口)/baizhi(库名)
spring.data.mongodb.uri=mongodb://192.168.31.167:27017/baizhi
?
# mongodb 存在密码
#spring.data.mongodb.host=shawn
#spring.data.mongodb.port=27017
#spring.data.mongodb.database=baizhi
#spring.data.mongodb.username=root
#spring.data.mongodb.password=root
1.2 集合操作
// 创建集合
@Test
public void testCreateCollection(){
mongoTemplate.createCollection("users");//参数: 创建集合名称
}
// 注意: 创建的集合已经存在时,再次创建会报错,因此创建前需要判断集合时候已经存在
@Test
public void testCreateCollection(){
// 判断集合是否存在
boolean isExist = mongoTemplate.collectionExists("products");
// 不存在时创建集合
if (!isExist) {
mongoTemplate.createCollection("products");
}
}
// 删除集合
@Test
public void testDropCollection(){
mongoTemplate.dropCollection("products");
}
1.3 相关注解
Java–>对象–>JSON–>MongoDB
@Document 对应 类
- 修饰范围: 用在类上
- 作用: 用来映射这个类的一个对象为 mongo 中一条文档数据
- 属性:(value 、collection )用来指定操作的集合名称
@Id 对应 要指定为_id的变量名
- 修饰范围: 用在成员变量、方法上,只能出现一次
- 作用: 用来将成员变量的值映射为文档的_id 的值
@Field 对应 剩余变量名(变量名都按照类中属性名定义时,可以不指定,即同名时可不指定)
- 修饰范围: 用在成员变量、方法上
- 作用: 用来将成员变量以及值映射为文档中一个key、value对
- 属性: ( name,value)用来指定在文档中 key 的名称,默认为成员变量名
@Transient 不参与文档转换
- 修饰范围: 用在成员变量、方法上
- 作用 : 用来指定改成员变量,不参与文档的序列化
mongoTemplate.insert(new User(4, "小wangb", 22, new Date()), "db1");
mongoTemplate.save(new User(1,"小米",22,new Date()));
mongoTemplate.insert(Arrays.asList(new User(2, "小号", 11, new Date()),new User(3, "chiwan", 99, new Date())), User.class);
// insert 可以批量插入数据,重复id会报错
// save不可以批量插入数据,重复id不会报错
1.4 文档查询

//根据id查询
mongoTemplate.findById(1, User.class);
//查询所有
mongoTemplate.findAll(User.class);
//等值查询
mongoTemplate.find(Query.query(Criteria.where("name").is("小红")), User.class);
//<,>,>=,<=
mongoTemplate.find(Query.query(Criteria.where("age").lt(33)), User.class);
//and查询
mongoTemplate.find(Query.query(Criteria.where("name").is("小号").and("age").is(11)), User.class);
//or查询
Criteria criteria = new Criteria();
criteria.orOperator(Criteria.where("name").is("小号"), Criteria.where("name").is("小红"));
mongoTemplate.find(Query.query(criteria), User.class);
//and or 查询
mongoTemplate.find(Query.query(Criteria.where("age").is(22).orOperator(Criteria.where("name").is("小红"), criteria.where("name").is("小wangb"))), User.class);
//排序
mongoTemplate.find(new Query().with(Sort.by(Sort.Order.desc("age"))), User.class);
//分页
mongoTemplate.find(new Query().with(Sort.by(Sort.Order.desc("age"))).skip(3).limit(2), User.class);
//总条数
mongoTemplate.count(new Query(), User.class);
//去重
mongoTemplate.findDistinct(new Query(), "age", User.class, int.class);
//传统采用Json格式查询
mongoTemplate.find(new BasicQuery("{$or:[{age:22},{age:99}]}", "{name:0}"), User.class);
1.5 文档更新&删除
// ====== 更新 ====
//更新第一条
Query query = new Query(Criteria.where("age").is(44));
mongoTemplate.updateFirst(query, new Update().set("age", 33).set("name", "小王八"), User.class);
//更新批量
mongoTemplate.updateMulti(query, new Update().set("age", 11), User.class);
//更新插入
UpdateResult age = mongoTemplate.upsert(query, new Update().set("age", 44), User.class);
System.out.println(age.getModifiedCount());//修改条数
System.out.println(age.getMatchedCount());//匹配条数
System.out.println(age.getUpsertedId());//插入id
// ====== 删除 ====
//条件删除
mongoTemplate.remove(new Query(Criteria.where("age").is(44)), User.class);
//删除所有
mongoTemplate.remove(new Query(), User.class);
四、权限配置与可视化
1、概述
刚安装完毕的mongodb默认不使用权限认证方式启动,与MySQL不同,mongodb在安装的时候并没有设置权限,然而公网运行系统需要设置权限以保证数据安全。MongoDB是没有默认管理员账号,所以要先添加管理员账号,并且mongodb服务器需要在运行的时候开启验证模式
- 用户只能在用户所在数据库登录(创建用户的数据库),包括管理员账号。
- 管理员可以管理所有数据库,但是不能直接管理其他数据库,要先认证后才可以。
2、权限管理
2.1 创建账户
# 进入mongodb的shell
mongo
# 使用admin数据库(超级管理员账号必须创建在该数据库上)
use admin
# 创建一个不受访问限制的超级用户
db.createUser({"user":"user","pwd":"password","roles":["root"]})
# 创建admin超级管理员用户
# 指定用户的角色和数据库:(注意此时添加的用户都只用于admin数据库,而非你存储业务数据的数据库)
# (在cmd中敲多行代码时,直接敲回车换行,最后以分号首尾)
db.createUser(
{ user: "admin",
customData:{description:"superuser"},
pwd: "admin",
roles: [ { role: "userAdminAnyDatabase", db: "admin" } ]
}
)
# user字段,为新用户的名字;
# pwd字段,用户的密码;
# cusomData字段,为任意内容,例如可以为用户全名介绍;
# roles字段,指定用户的角色,可以用一个空数组给新用户设定空角色。在roles字段,可以指定内置角色和用户定义的角色。
# 超级用户的role有两种,userAdmin或者userAdminAnyDatabase(比前一种多加了对所有数据库的访问,仅仅是访问而已)。
# db是指定数据库的名字,admin是管理数据库。
# 不能用admin数据库中的用户登录其他数据库。注:只能查看当前数据库中的用户,哪怕当前数据库admin数据库,也只能查看admin数据库中创建的用户。
# ===================下面创建普通账户=========================
# 创建一个业务数据库管理员用户,只负责某一个或几个数据库的増查改删
db.createUser({
user:"user001",
pwd:"123456",
customData:{
name:'shawn',
email:'shawn@qq.com',
age:18,
},
roles:[
{role:"readWrite",db:"db001"},
{role:"readWrite",db:"db002"},
'read'// 对其他数据库有只读权限,对db001、db002是读写权限
]
})
# ==================相关介绍=========================
# Built-In Roles(内置角色):
# 1. 数据库用户角色:read、readWrite;
# 2. 数据库管理角色:dbAdmin、dbOwner、userAdmin;
# 3. 集群管理角色:clusterAdmin、clusterManager、clusterMonitor、hostManager;
# 4. 备份恢复角色:backup、restore;
# 5. 所有数据库角色:readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase
# 6. 超级用户角色:root,这里还有几个角色间接或直接提供了系统超级用户的访问(dbOwner 、userAdmin、userAdminAnyDatabase)
# 7. 内部角色:__system
# 具体角色的功能:
# 1. Read:允许用户读取指定数据库
# 2. readWrite:允许用户读写指定数据库
# 3. dbAdmin:允许用户在指定数据库中执行管理函数,如索引创建、删除,查看统计或访问system.profile
# 4. userAdmin:允许用户向system.users集合写入,可以找指定数据库里创建、删除和管理用户
# 5. clusterAdmin:只在admin数据库中可用,赋予用户所有分片和复制集相关函数的管理权限。
# 6. readAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的读权限
# 7. readWriteAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的读写权限
# 8. userAdminAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的userAdmin权限
# 9. dbAdminAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的dbAdmin权限。
# 10. root:只在admin数据库中可用。超级账号,超级权限
2.2 账户常用操作
# 查看创建的用户
show users
db.system.users.find()
db.runCommand({usersInfo:"userName"})
# 修改密码
use admin
db.changeUserPassword("username", "xxx")
# 修改密码和用户信息
db.runCommand(
{
updateUser:"username",
pwd:"xxx",
customData:{title:"xxx"}
}
)
# 删除数据库用户
use admin
db.dropUser('user001')
db.dropAllUser()
# 创建其他数据管理员
# 登录管理员用户
use admin
db.auth('admin','admin')
# 切换至db001数据库
use db001
# 増查改删该数据库专有用户
2.3 权限启动认证
# 启用权限验证
mongo --auth
# 或者修改mongo.conf,最后一行添加
auth=true
# 重新启动mongodb
3、Docker启动认证
3.1 创建管理员
# 创建一个文件夹用于存放数据,具体路径根据你自己想法来。这里这是举例。
mkdir /mongo/data/
# 创建无校验的容器
docker run --name linux-mongo -p 27017:27017 -v /mongo/data:/data/db -d mongo
# 进入容器
docker exec -it linux-mongo mongo admin
# 创建管理员
db.createUser({ user:'rootuser',pwd:'rootpassword', roles: [ { role: "userAdminAnyDatabase", db: "admin" } ] });
# 退出
exit
# 停止 linux-mongo 容器
docker stop linux-mongo
# 删除。其实不删除也可以,没有其他影响,不删除记得下面步骤的命名不要重复。这里我建议你删除,因为容易混乱,如果需要重新配置再按上面步骤操作就可以。
docker rm linux-mongo
# 至此创建管理员任务完成
3.2 创建 MongoDB 镜像 - 带验证
# 创建容器 - 有校验
docker run --name linux-mongo -p 27017:27017 -v /mongo/data:/data/db -d mongo --auth
# 启动容器之后,使用admin进入
docker exec -it linux-mongo mongo admin
# 权限认证
db.auth("rootuser","rootpassword"); # 返回 1 证明成功, 返回 0 证明失败
# 创建可用用户。或者直接使用 rootuser ( 权限要要 root 才能在外部操作)
db.createUser({ user: 'testadmin', pwd: 'testadmin123', roles: [ { role: "root", db: "admin" } ] });
# 校验
db.auth("testadmin","testadmin123"); # 返回 1 证明成功, 返回 0 证明失败
# 权限说明
# 1.数据库用户角色:read、readWrite;
# 2.数据库管理角色:dbAdmin、dbOwner、userAdmin;
# 3.集群管理角色:clusterAdmin、clusterManager、clusterMonitor、hostManager;
# 4.备份恢复角色:backup、restore
# 5.所有数据库角色:readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase
# 6.超级用户角色:root
# 退出
exit
# MongoDB 数据库操作
show dbs; # 查看现有数据库
show users; # 查看用户
db.dropUser("testadmin") # 删除用户,外部想连接 testadmin 的话,此处不要删除
# 至此,有一个用户可以直接使用。
4、MongoDB可视化
docker run -d \
--name mongo \
-v /home/docker/mongo/db:/data/db \
-p 27017:27017 \
-e MONGO_INITDB_ROOT_USERNAME=admin \
-e MONGO_INITDB_ROOT_PASSWORD=123456 \
--restart=always \
mongo:5.0
# 下面是 mongo-express 可视化
docker run -d \
--name mongo-express \
-p 8081:8081 \
--link mongo \
-e ME_CONFIG_MONGODB_SERVER='172.21.9.203' \
-e ME_CONFIG_MONGODB_ADMINUSERNAME='admin' \
-e ME_CONFIG_MONGODB_ADMINPASSWORD='123456' \
-e ME_CONFIG_BASICAUTH_USERNAME='admin' \
-e ME_CONFIG_BASICAUTH_PASSWORD='admin123' \
--restart=always \
mongo-express:0.54
五、副本与集群
1、副本集
1.1 概述
MongoDB 副本集(Replica Set)是有自动故障恢复功能的主从集群,有一个Primary节点和一个或多个Secondary节点组成。副本集没有固定的主节点,当主节点发生故障时整个集群会选举一个主节点为系统提供服务以保证系统的高可用。注意:这种方式并不能解决主节点的单点访问压力问题。
**注意:**当MongoDB副本集架构只剩一个节点时,整个节点是不可用的。单主不可写

1.2 自动故障转移
当主节点未与集合的其他成员通信超过配置的选举超时时间(默认为 10 秒)时,合格的辅助节点将调用选举以将自己提名为新的主节点。集群尝试完成新主节点的选举并恢复正常操作。

1.3 副本集搭建
# 这里我是用了一台机器,可以分作不同机器,注意ip即可
# 创建数据目录
mkdir -p rep1/data1
mkdir -p rep1/data2
mkdir -p rep1/data3
# 搭建副本集
./mongod --port 27017 --dbpath ../rep1/data1 --bind_ip 0.0.0.0 --replSet myreplace/[1.14.17.152:27018,1.14.17.152:27019]
./mongod --port 27018 --dbpath ../rep1/data2 --bind_ip 0.0.0.0 --replSet myreplace/[1.14.17.152:27017,1.14.17.152:27019]
./mongod --port 27019 --dbpath ../rep1/data3 --bind_ip 0.0.0.0 --replSet myreplace/[1.14.17.152:27018,1.14.17.152:27017]
# ./ mongo --port 27018
# 配置副本集,连接任意节点
use admin
# 初始化副本集
var config = {
_id:"myreplace",
members:[
{_id:0,host:"121.5.167.13:27017"},
{_id:1,host:"121.5.167.13:27018"},
{_id:2,host:"121.5.167.13:27019"}]
}
rs.initiate(config);//初始化配置
# 进入从节点,让其可以读,每个从节点都要设置
# 设置客户端临时可以访问,然后navicat就可以集群连接了
rs.slaveOk(); //旧的
rs.secondaryOk(); //新的
# springboot :spring.data.mongodb.uri=mongodb://1.14.17.152:27017,1.14.17.152:27018,1.14.17.152:27019/chihiro
还有一种方式是配置文件
## 检查端口运行情况 如果正在运行 关闭服务
netstat -lnp | grep 27017
## 切换到 /opt/home目录下
cd /opt/home/
## 将mongodb5.0.5复制三份
cp -r mongodb5.0.5/ mongodb1
cp -r mongodb5.0.5/ mongodb2
cp -r mongodb5.0.5/ mongodb3
## 创建数据目录
mkdir -p /data/mongodb/data1
mkdir -p /data/mongodb/data2
mkdir -p /data/mongodb/data3
## 进入mongodb1的bin目录
cd mongodb1/bin/
## 修改mongodb.conf配置文件
vim mongodb.conf
## 修改内容如下 修改datapath、logpath目录和port端口号
#数据文件存放目录
dbpath = /data/mongodb/data1
#日志文件存放地址
logpath =/data/mongodb/log1.log
#端口
port = 27018
#以守护程序的方式启用,即在后台运行
fork = true
#需要认证。如果放开注释,就必须创建MongoDB的账号,使用账号与密码才可>远程访问,第一次安装建议注释
#auth=true
#允许远程访问,或者直接注释,127.0.0.1是只允许本地访问
bind_ip=0.0.0.0
replSet=myreplace/[192.168.200.128:27019,192.168.200.128:27020]
## 其余两个同上 端口分别为 27018 27019 27020
# 分别连接三台MongoDB
./mongo --port 27018
./mongo --port 27019
./mongo --port 27020
# 配置副本集,连接任意节点
var config = {
_id:"myreplace",
members:[
{_id:0,host:"192.168.200.128:27018"},
{_id:1,host:"192.168.200.128:27019"},
{_id:2,host:"192.168.200.128:27020"}]
}
## 初始化配置
rs.initiate(config);
## 在主节点添加一条数据
use test;
db.test.insert({_id:1, name:'java'});
db.test.find();
## 设置客户端临时可以访问 分别在从节点执行查询命令db.test.find();
# 方式一
rs.slaveOk();
# 方式二
rs.secondaryOk();
# 查询
db.test.find();
## 手动摸拟异常 关闭主节点 查看从节点是否从新选举
# 结果 从节点会从新选举主节点 主节点再次启动后会自动变更为从节点
2、分片集群(sharing cluster)
2.1 概述
分片(sharding)是指将数据拆分,将其分散存在不同机器的过程,有时也用分区(partitioning)来表示这个概念,将数据分散在不同的机器上,不需要功能强大的大型计算机就能存储更多的数据,处理更大的负载。
分片目的是通过分片能够增加更多机器来应对不断的增加负载和数据,还不影响应用运行。MongoDB支持自动分片,可以摆脱手动分片的管理困扰,集群自动切分数据做负载均衡。
MongoDB分片的基本思想就是将集合拆分成多个块,这些快分散在若干个片里,每个片只负责总数据的一部分,应用程序不必知道哪些片对应哪些数据,甚至不需要知道数据拆分了,所以在分片之前会运行一个路由进程,mongos进程,这个路由器知道所有的数据存放位置,应用只需要直接与mongos交互即可。mongos自动将请求转到相应的片上获取数据,从应用角度看分不分片没有什么区别。
2.2 架构

- Shard: 用于存储实际的数据块,实际生产环境中一个shard server角色可由几台机器组个一个replica set承担,防止主机单点故障
- Config Server:mongod实例,存储了整个 ClusterMetadata
- Query Routers: 前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用
- Shard Key: 片键,设置分片时需要在集合中选一个键,用该键的值作为拆分数据的依据,这个片键称之为(shard key),片键的选取很重要,片键的选取决定了数据散列是否均匀
2.3 分片集群搭建
下面是原生安装集群,docker安装可以参考:Docker部署MongoDB分片+副本集集群(实战)
# 1.集群规划
- Shard Server 1:27017
- Shard Repl 1:27018
- Shard Server 2:27019
- Shard Repl 2:27020
- Shard Server 3:27021
- Shard Repl 3:27022
- Config Server :27023
- Config Server :27024
- Config Server :27025
- Route Process :27026
#2.进入安装的bin目录创建数据目录
## s0
mkdir -p /data/mongodb/shard/s0
mkdir -p /data/mongodb/shard/s0-repl
## s1
mkdir -p /data/mongodb/shard/s1
mkdir -p /data/mongodb/shard/s1-repl
## s2
mkdir -p /data/mongodb/shard/s2
mkdir -p /data/mongodb/shard/s2-repl
## config
mkdir -p /data/mongodb/shard/config1
mkdir -p /data/mongodb/shard/config2
mkdir -p /data/mongodb/shard/config3
mkdir -p /data/mongodb/shard/config
启动6个 shard服务
## 启动 s0、r0
./mongod --port 27017 --dbpath /data/mongodb/shard/s0 --bind_ip 0.0.0.0 --shardsvr --replSet r0/123.57.80.91:27018 --fork --logpath /data/mongodb/shard/s0/s0.log
./mongod --port 27018 --dbpath /data/mongodb/shard/s0-repl --bind_ip 0.0.0.0 --shardsvr --replSet r0/123.57.80.91:27017 --fork --logpath /data/mongodb/shard/s0-repl/s0-repl.log
# 登录任意节点
./mongo --port 27017
# 选择admin库
use admin
# 在admin中执行
config = {
_id:"r0", members:[
{_id:0,host:"123.57.80.91:27017"},
{_id:1,host:"123.57.80.91:27018"}
]
}
# 初始化
rs.initiate(config);
## 启动 s1、r1
./mongod --port 27019 --dbpath /data/mongodb/shard/s1 --bind_ip 0.0.0.0 --shardsvr --replSet r1/123.57.80.91:27020 --fork --logpath /data/mongodb/shard/s1/s1.log
./mongod --port 27020 --dbpath /data/mongodb/shard/s1-repl --bind_ip 0.0.0.0 --shardsvr --replSet r1/123.57.80.91:27019 --fork --logpath /data/mongodb/shard/s1-repl/s1-repl.log
# 登录任意节点
./mongo --port 27019
# 在admin中执行
use admin
# 执行
config = {
_id:"r1", members:[
{_id:0,host:"123.57.80.91:27019"},
{_id:1,host:"123.57.80.91:27020"}
]
}
# 初始化
rs.initiate(config);
## 启动 s2、r2
./mongod --port 27021 --dbpath /data/mongodb/shard/s2 --bind_ip 0.0.0.0 --shardsvr --replSet r2/123.57.80.91:27022 --fork --logpath /data/mongodb/shard/s2/s2.log
./mongod --port 27022 --dbpath /data/mongodb/shard/s2-repl --bind_ip 0.0.0.0 --shardsvr --replSet r2/123.57.80.91:27021 --fork --logpath /data/mongodb/shard/s2-repl/s2-repl.log
# 登录任意节点
./mongo --port 27017
# 选择admin库
use admin
# 在admin中执行
config = {
_id:"r2", members:[
{_id:0,host:"123.57.80.91:27021"},
{_id:1,host:"123.57.80.91:27022"}
]
}
# 初始化
rs.initiate(config);
启动3个config服务
./mongod --port 27023 --dbpath /data/mongodb/shard/config1 --bind_ip 0.0.0.0 --replSet config/[123.57.80.91:27024,123.57.80.91:27025] --configsvr --fork --logpath /data/mongodb/shard/config1/config.log
./mongod --port 27024 --dbpath /data/mongodb/shard/config2 --bind_ip 0.0.0.0 --replSet config/[123.57.80.91:27023,123.57.80.91:27025] --configsvr --fork --logpath /data/mongodb/shard/config2/config.log
./mongod --port 27025 --dbpath /data/mongodb/shard/config3 --bind_ip 0.0.0.0 --replSet config/[123.57.80.91:27023,123.57.80.91:27024] --configsvr --fork --logpath /data/mongodb/shard/config3/config.log
初始化 config server 副本集
# 登录任意节点 congfig server
./mongo --port 27023
# 选择数据库
use admin
# 在admin中执行
config = {
_id:"config",
configsvr: true,
members:[
{_id:0,host:"123.57.80.91:27023"},
{_id:1,host:"123.57.80.91:27024"},
{_id:2,host:"123.57.80.91:27025"}
]
}
# 初始化副本集配置
rs.initiate(config);
启动 mongos 路由服务
./mongos --port 27026 --configdb config/123.57.80.91:27023,123.57.80.91:27024,123.57.80.91:27025 --bind_ip 0.0.0.0 --fork --logpath /data/mongodb/shard/config/config.log
登录 mongos 服务
# 1.登录
./mongo --port 27026
# 2.选择数据库
use admin
# 3.添加分片信息
db.runCommand({ addshard:"r0/123.57.80.91:27017,123.57.80.91:27018","allowLocal":true });
db.runCommand({ addshard:"r1/123.57.80.91:27019,123.57.80.91:27020","allowLocal":true });
db.runCommand({ addshard:"r2/123.57.80.91:27021,123.57.80.91:27022","allowLocal":true });
# 4.指定分片的数据库
db.runCommand({ enablesharding:"users" });
# 5.设置库的片键信息
db.runCommand({ shardcollection: "users.user", key: { _id:1}});
db.runCommand({ shardcollection: "users.emp", key: { _id: "hashed"}})
测试
# 1.登陆27026节点
./mongo --port 27026
# 2.选择数据库
use users;
# 3.插入数据
for(let i=0;i<1000;i++){
db.user.insert({_id:i, name:"java_"+i, age: i});
}
# 4.验证27017
./mongo --port 27017
use users;
db.user.count();
# 5.验证27019
./mongo --port 27019
use users;
db.user.count();
# 6.验证27021
./mongo --port 27021
use users;
db.user.count();
六、数据备份与恢复
1、常规数据备份与恢复
1.1 备份 MongoDB 数据库(包括身份验证)
假设我们要备份一个名为 mydatabase 的 MongoDB 数据库,并将备份文件保存在 /backup 目录下。数据库的用户名是 myuser,密码是 mypassword,身份验证数据库是 admin
mongodump --host localhost --port 27017 --db mydatabase --username myuser --password mypassword --authenticationDatabase admin --out /backup
# 写法
mongodump --host <hostname> --port <port> --db <database_name> --username <username> --password <password> --authenticationDatabase <auth_db> --out /backup
<hostname>: MongoDB 主机名或 IP 地址<port>: MongoDB 端口,默认为 27017<database_name>: 要备份的数据库名称<username>: 用户名<password>: 用户密码<auth_db>: 用户的身份验证数据库/backup: 备份文件输出目录
1.2 恢复 MongoDB 数据库(包括身份验证)
假设我们要从之前的备份文件恢复 mydatabase 数据库
mongorestore --host localhost --port 27017 --db mydatabase --username myuser --password mypassword --authenticationDatabase admin /backup/mydatabase
# 写法
mongorestore --host <hostname> --port <port> --db <database_name> --username <username> --password <password> --authenticationDatabase <auth_db> /backup/<database_name>
<hostname>: MongoDB 主机名或 IP 地址<port>: MongoDB 端口,默认为 27017<database_name>: 要恢复的数据库名称<username>: 用户名<password>: 用户密码<auth_db>: 用户的身份验证数据库/backup/<database_name>: 备份文件所在的目录
最后,基于docker的可以参考:基于docker的mongodump / mongorestore 备份恢复
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【占用网络】FlashOcc:快速、易部署的占用预测模型
- chapter9-让你的系统全天候为你服务
- thinkphp5实战之phpstudy v8环境搭建,解决Not Found找不到路径问题
- 会员互动服务平台,商协会会员管理解决方案
- Shell三剑客:正则表达式(元字符)——示例
- Web实战丨基于Django与HTML的新闻发布系统
- AcWing 1229.日期问题(枚举题,细节多)
- 【vue2】状态管理之 Vuex
- Vue面试题
- 编程笔记 html5&css&js 037 CSS选择器