数据操作——有类型转换操作
有类型转换操作
以下算子有@Test的前置条件
-
以下算子有@Test的前置条件
// 1. 创建SparkSession val spark = SparkSession.builder() .appName("trans_test") .master("local[6]") .getOrCreate() // 导入隐式转换 import spark.implicits._ // case样例类 case class Person(name: String, age: Int)
转换
- 转换
-
flatMap
通过 flatMap 可以将一条数据转为一个数组, 后再展开这个数组放入 Dataset
@Test def trans():Unit={ // flatmap val ds = Seq("hello spark", "hello hadoop").toDS() ds.flatMap(item => item.split(" ")).show() }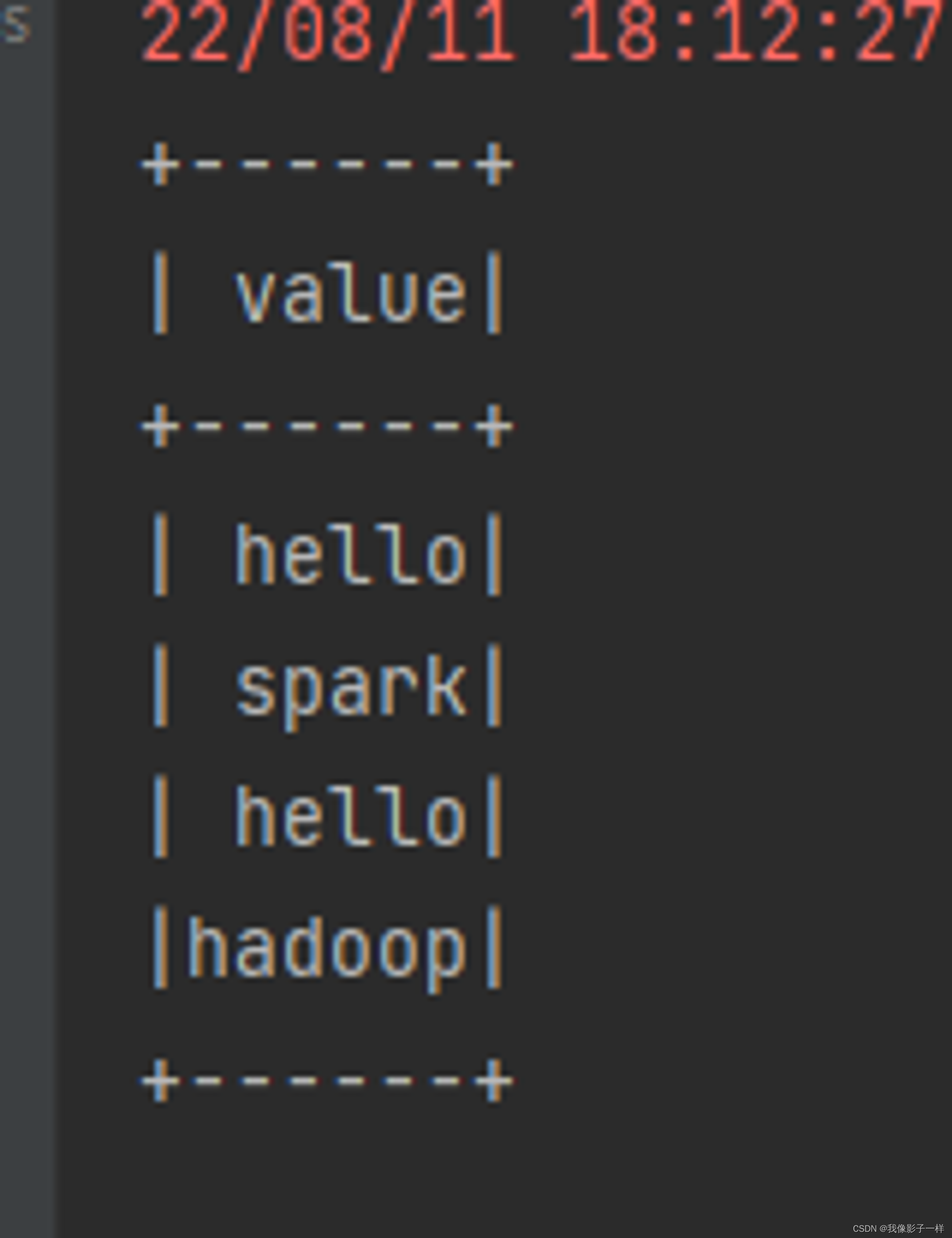
-
map
map 可以将数据集中每条数据转为另一种形式
@Test def trans(): Unit = { // map val ds2 = Seq(Person("zhangsan", 15), Person("lisi", 20)).toDS() ds2.map(person => Person(person.name, person.age * 2)).show() }
-
mapPartitions
mapPartitions 和 map 一样, 但是 map 的处理单位是每条数据, mapPartitions 的处理单位是每个分区
@Test def trans(): Unit = { // mapPartitions val ds3 = Seq(Person("zhangsan", 15), Person("lisi", 20)).toDS() ds3.mapPartitions( // iter 不能大到每个 Executor 的内存放不下, 不然就会OOM(内存不够使) // 对每个元素进行转换,后生成一个新的集合 iter => { val result = iter.map(person => Person(person.name, person.age * 2)) result } ).show() } -
transform
map 和 mapPartitions 以及 transform 都是转换, map 和 mapPartitions 是针对数据, 而 transform 是针对整个数据集, 这种方式最大的区别就是 transform 可以直接拿到 Dataset 进行操作
**// transform @Test def trans1(): Unit = { val ds = spark.range(10) ds.transform(dataset => dataset.withColumn("doubled", 'id * 2)) // withColumn 新增列 ds.show() }**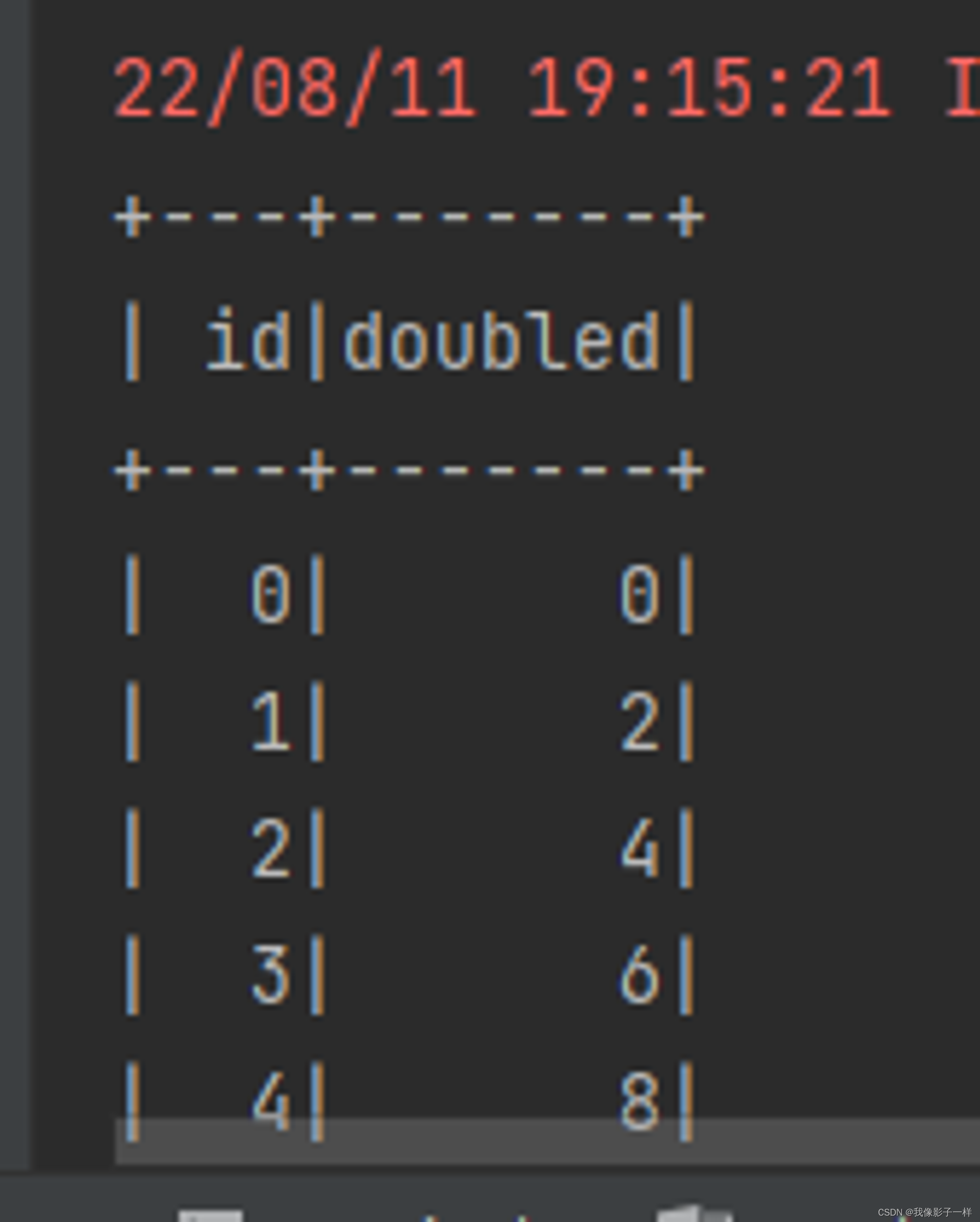
-
as
as[Type] 算子的主要作用是将弱类型的 Dataset 转为强类型的 Dataset, 它有很多适用场景, 但是最常见的还是在读取数据的时候, 因为 DataFrameReader 体系大部分情况下是将读出来的数据转换为 DataFrame 的形式, 如果后续需要使用 Dataset 的强类型 API, 则需要将 DataFrame 转为 Dataset. 可以使用 as[Type] 算子完成这种操作
// as @Test def as(): Unit = { // 1. 读取 // 创建Schema结构信息 val schema = StructType( List( StructField("name", StringType), StructField("age", IntegerType), StructField("gpa", FloatType) ) ) // 读取文件 val df: Dataset[Row] = spark.read // DataFrame = Dataset[Row] .schema(schema) .option("delimiter", "\t") // 指定制表符 .csv("./dataset/studenttab10k") // 2. 转换 // 本质上: Dataset[Row].as[Student] => Dataset[Student] // Dataset[(String, int, float)].as[Student] => Dataset[Student] val ds: Dataset[Student] = df.as[Student] // 3. 输出 ds.show() } case class Student(name: String, age: Int, gpa: Float)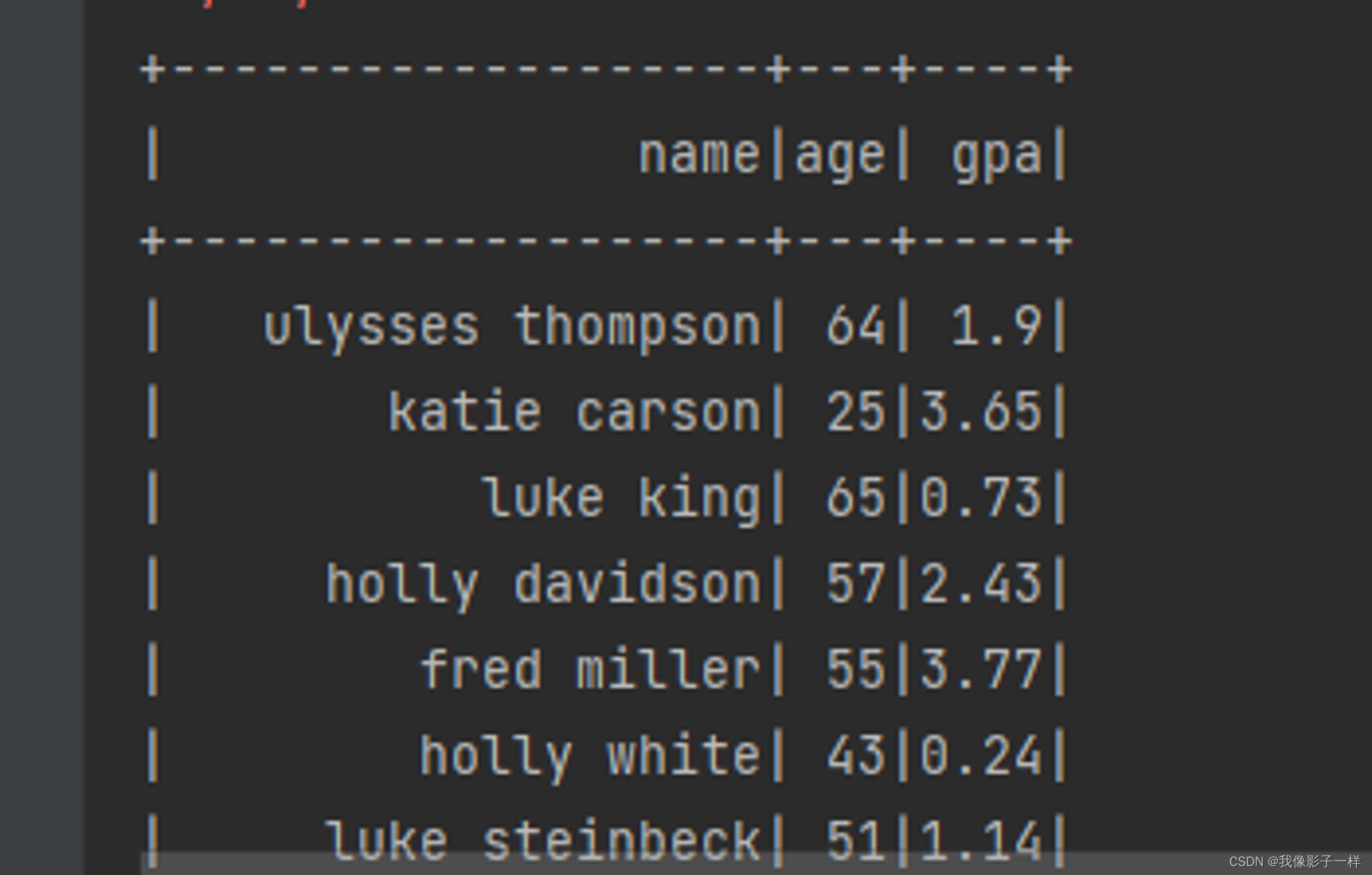
-
filter (过滤)
-
filter (过滤)
filter 用来按照条件过滤数据集
// filter @Test def filter(): Unit = { val ds = Seq(Person("zhangsan", 15), Person("lisi", 20)).toDS() ds.filter(person => person.age > 15).show() }
groupByKey(聚合)
-
groupByKey(聚合)
grouByKey 算子的返回结果是 KeyValueGroupedDataset, 而不是一个 Dataset, 所以必须要先经过 KeyValueGroupedDataset 中的方法进行聚合, 再转回 Dataset, 才能使用 Action 得出结果
其实这也印证了分组后必须聚合的道理
// groupByKey @Test def groupByKey():Unit = { val ds = Seq(Person("zhangsan", 15), Person("zhangsan", 16), Person("lisi", 20)).toDS() // SQL: select count(*) from person group by name val grouped: KeyValueGroupedDataset[String, Person] = ds.groupByKey(person => person.name) // 返回key,自己通过函数给他 val result: Dataset[(String, Long)] = grouped.count() // 分组后必须先聚合,再show result.show() }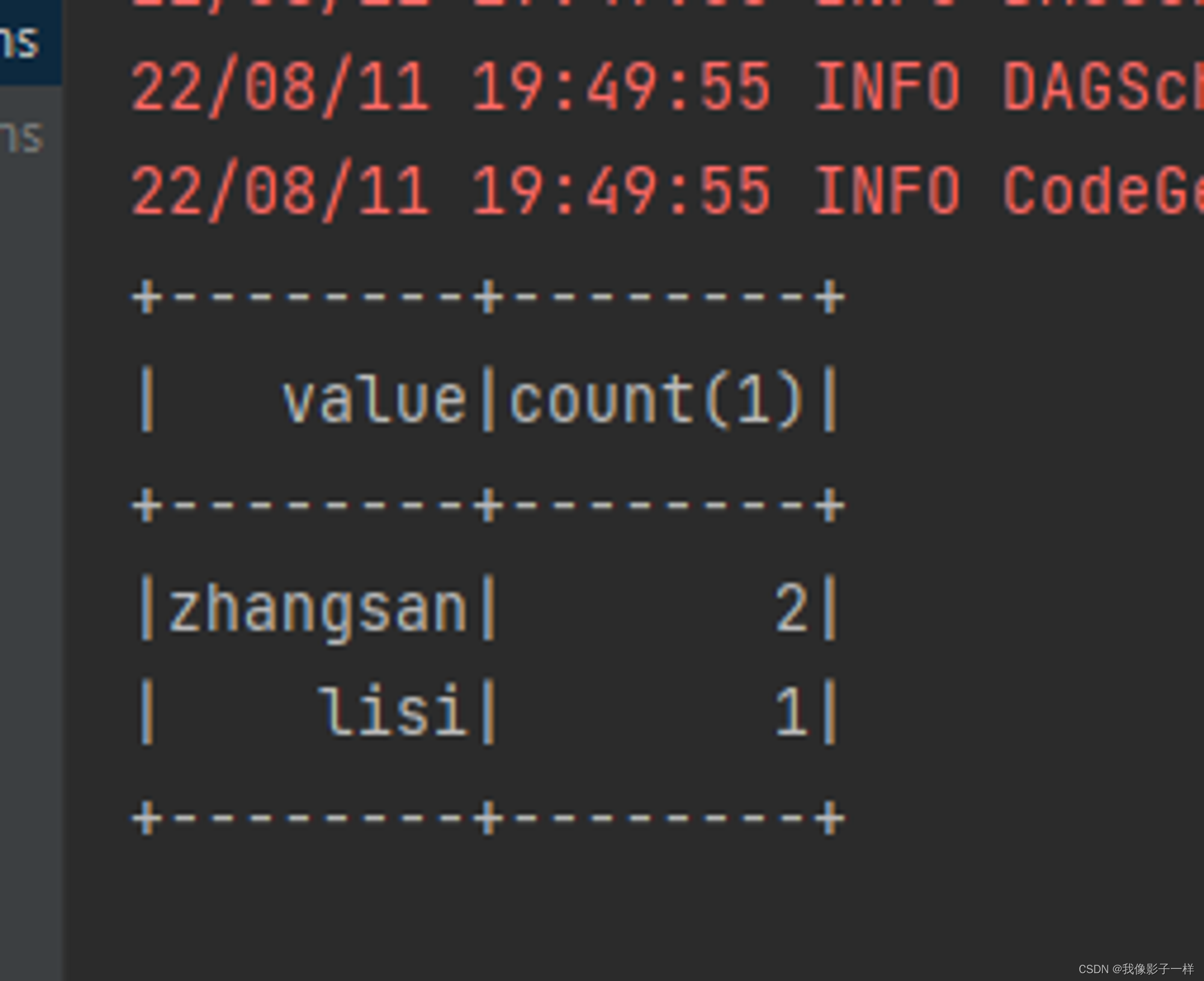
切分
- 切分
-
randomSplit
randomSplit 会按照传入的权重随机将一个 Dataset 分为多个 Dataset, 传入 randomSplit 的数组有多少个权重, 最终就会生成多少个 Dataset, 这些权重的加倍和应该为 1, 否则将被标准化
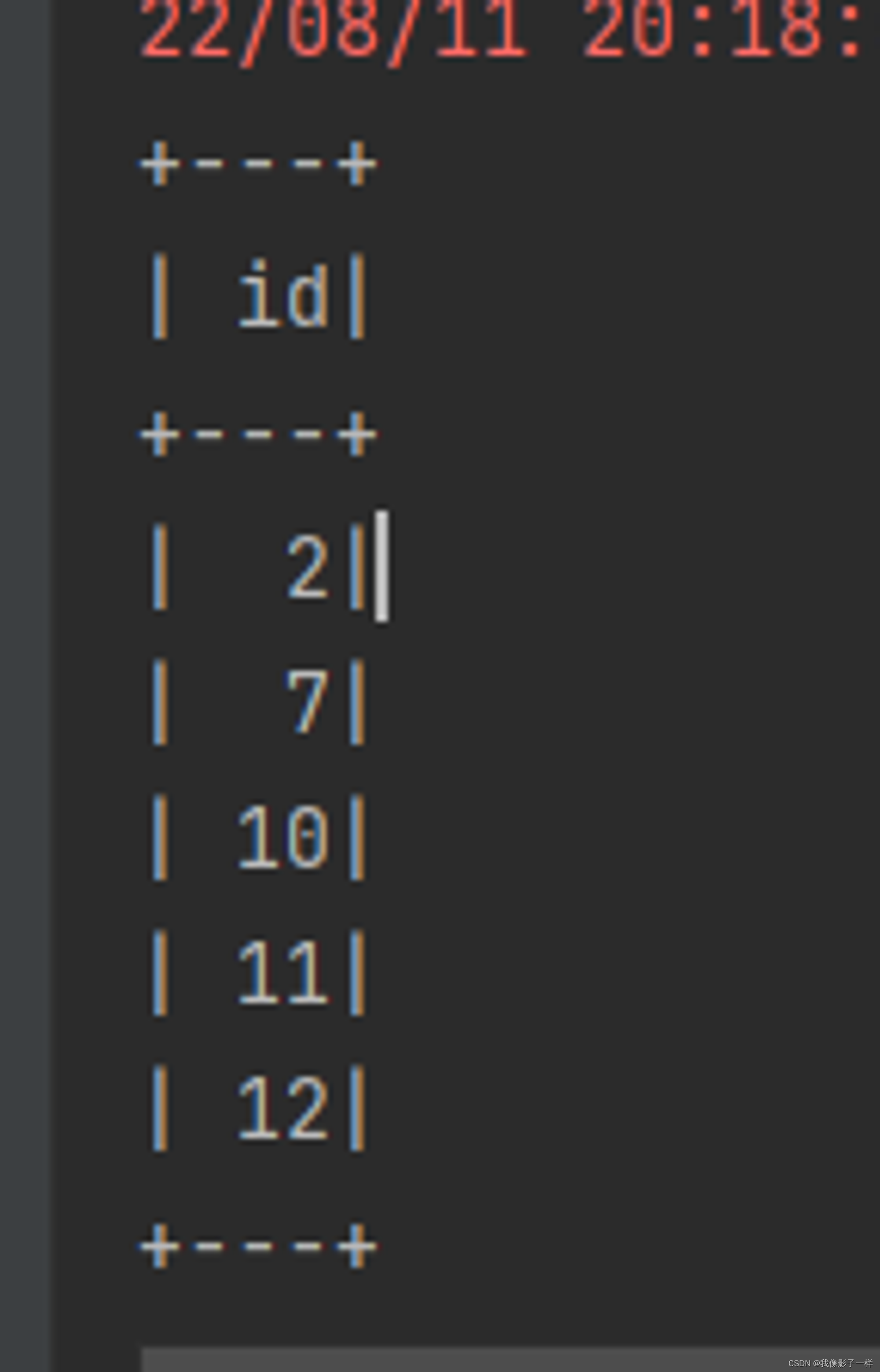
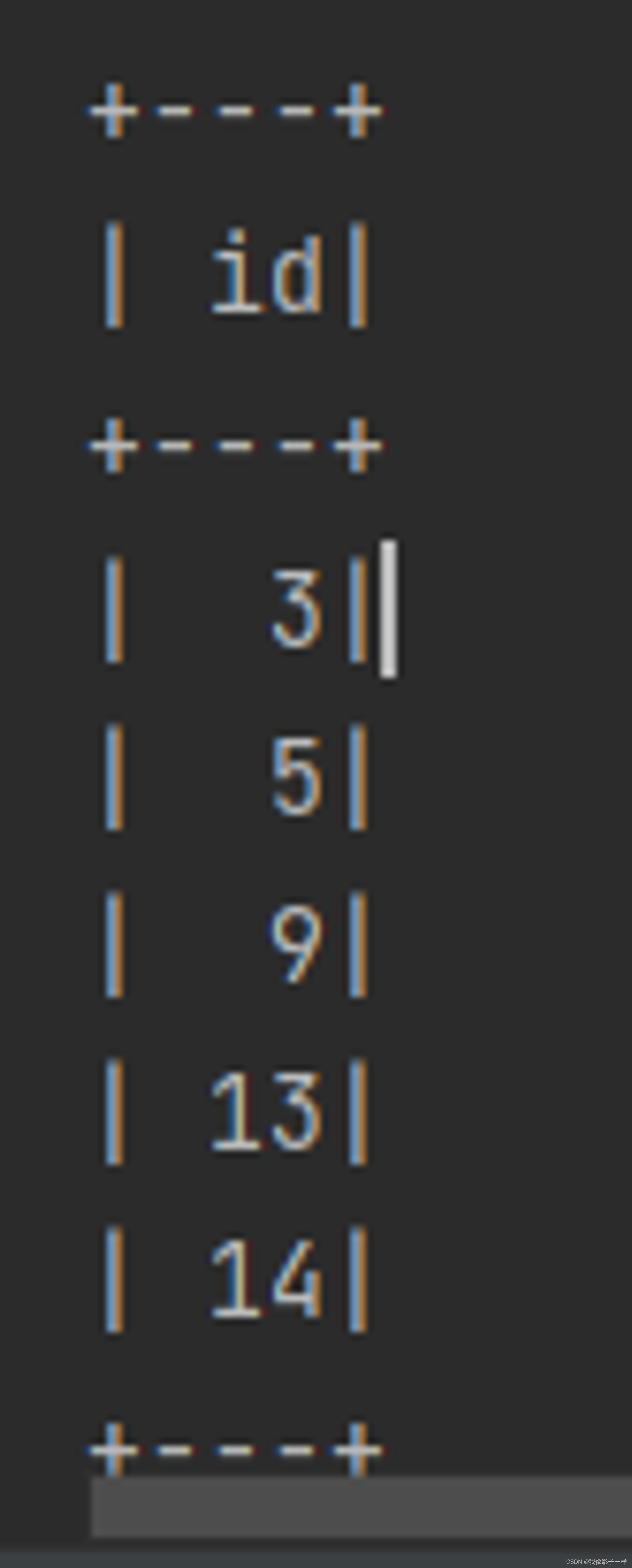
@Test def split():Unit = { val ds = spark.range(15) // randomSplit, 切多少份, 权重多少 val datasets = ds.randomSplit(Array(5, 2, 3)) // 只能整10, //给你五个你两个给你三个 datasets.foreach(_.show()) }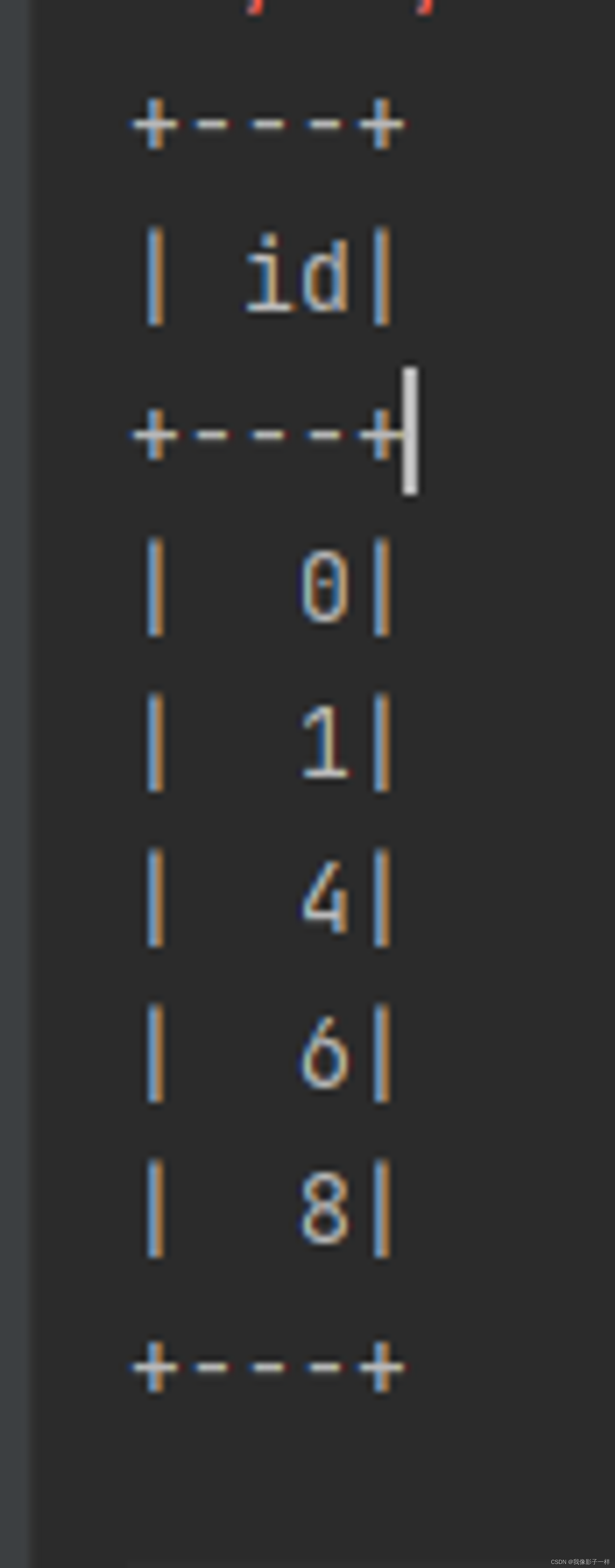
-
sample
sample 会随机在 Dataset 中抽样
@Test def split():Unit = { val ds = spark.range(15) // sample ds.sample(withReplacement = false, fraction = 0.4).show() // 不放回,采样百分比0.4 }
-
排序
- 排序
-
orderBy
orderBy 配合 Column 的 API, 可以实现正反序排列
@Test def sort():Unit = { val ds = Seq(Person("zhangsan", 20),Person("zhangsan", 8), Person("lisi", 15)).toDS // orderBy // 还有单引号选择列名时,要导入隐式转换 ds.orderBy('age.desc).show() // select * from ... order by ..desc desc 降序, asc升序 }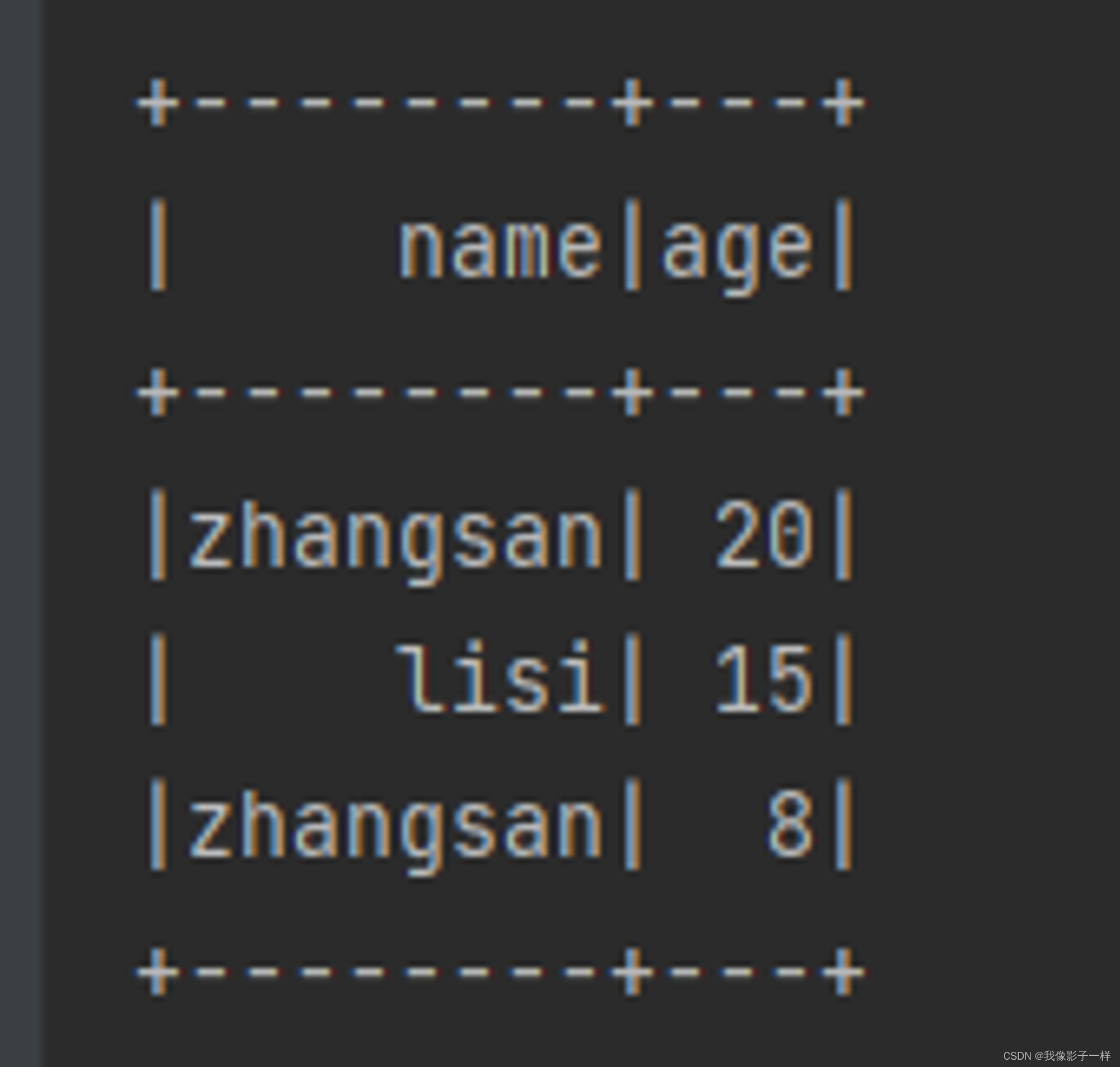
-
sort
其实 orderBy 是 sort 的别名, 所以它们所实现的功能是一样的
@Test def sort():Unit = { val ds = Seq(Person("zhangsan", 20),Person("zhangsan", 8), Person("lisi", 15)).toDS // 还有单引号选择列名时,要导入隐式转换 // select * from ... order by ..desc desc 降序, asc升序 // sort ds.sort('age.asc).show() }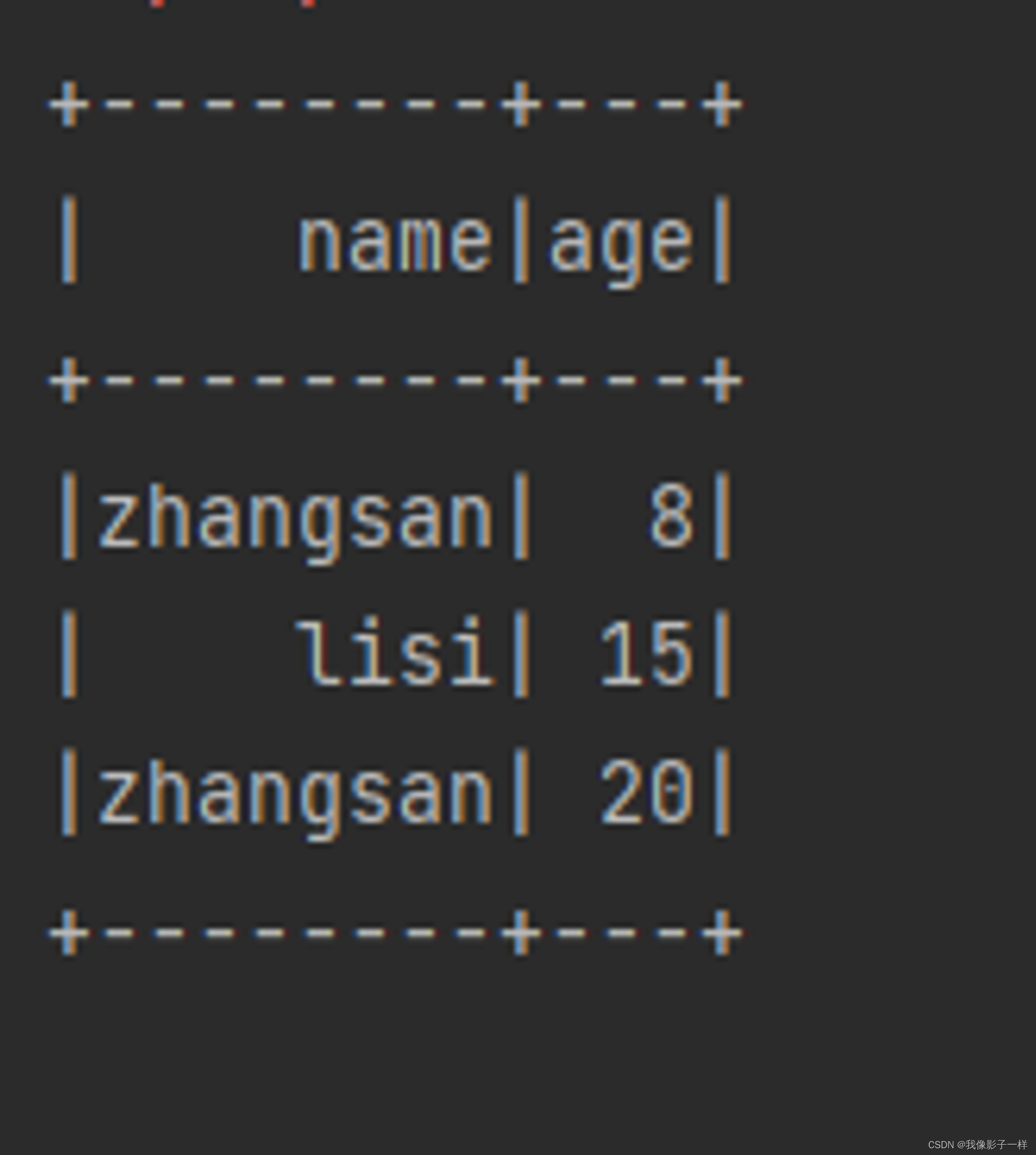
-
分区
- 分区
-
coalesce
减少分区, 此算子和 RDD 中的 coalesce 不同, Dataset 中的 coalesce 只能减少分区数, coalesce 会直接创建一个逻辑操作, 并且设置 Shuffle 为 false
@Test def partitions(): Unit = { val ds = spark.range(15) // coalesce ds.coalesce(1).explain(true) }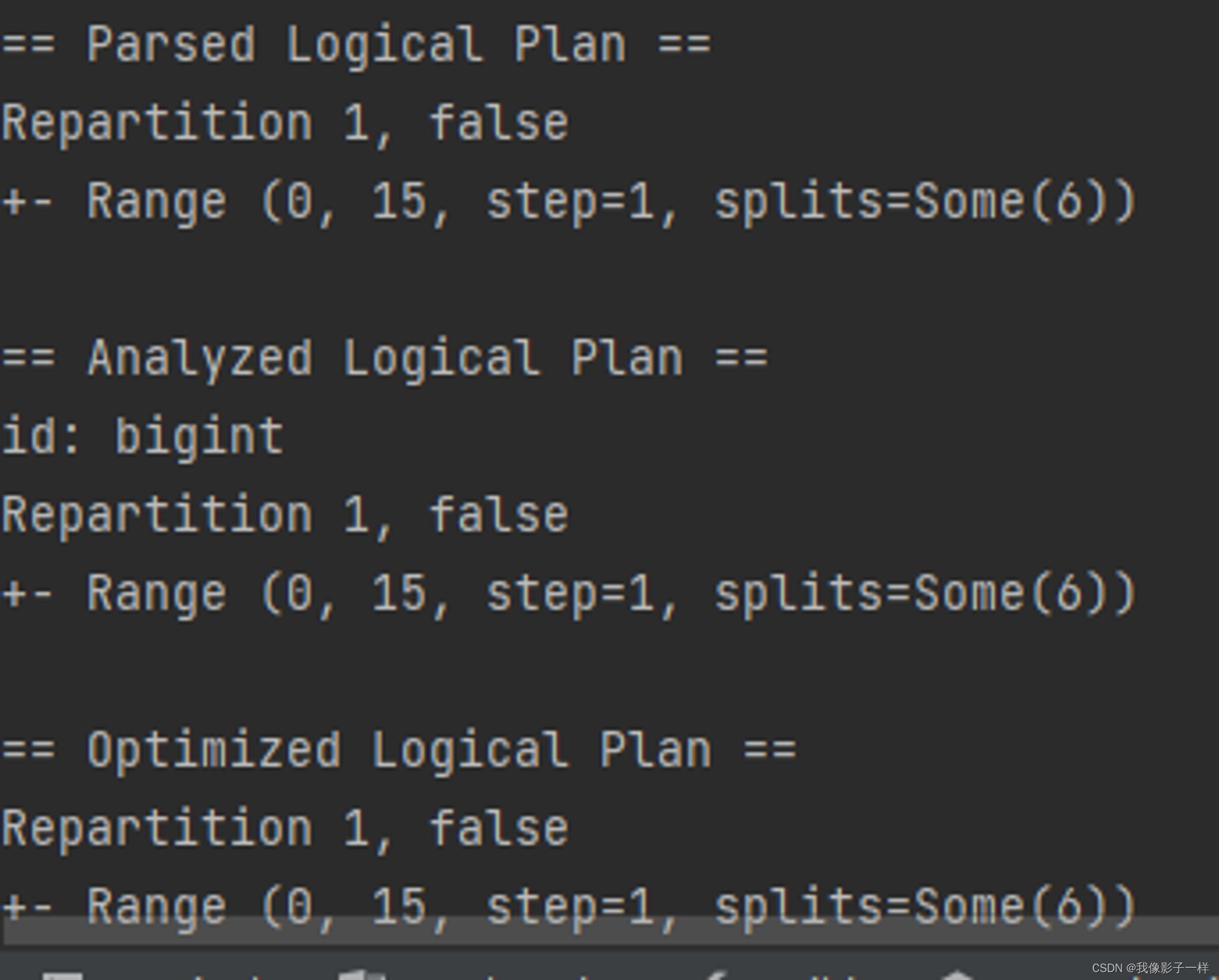
-
repartition
repartition 有两个作用, 一个是重分区到特定的分区数, 另一个是按照某一列来分区, 类似于 SQL 中的 DISTRIBUTE BY
@Test def partitions(): Unit = { val ds = Seq(Person("zhangsan", 12), Person("zhangsan", 8), Person("lisi", 15)).toDS() ds.repartition(4) ds.repartition('name) .explain(true) }
-
去重
- 去重
-
dropDuplicates
使用 dropDuplicates 可以去掉某一些列中重复的行
@Test def dropDuplication(): Unit = { val ds = spark.createDataset(Seq(Person("zhangsan", 15), Person("zhangsan", 15), Person("lisi", 15))) // dropDuplicates ds.dropDuplicates("age").show() }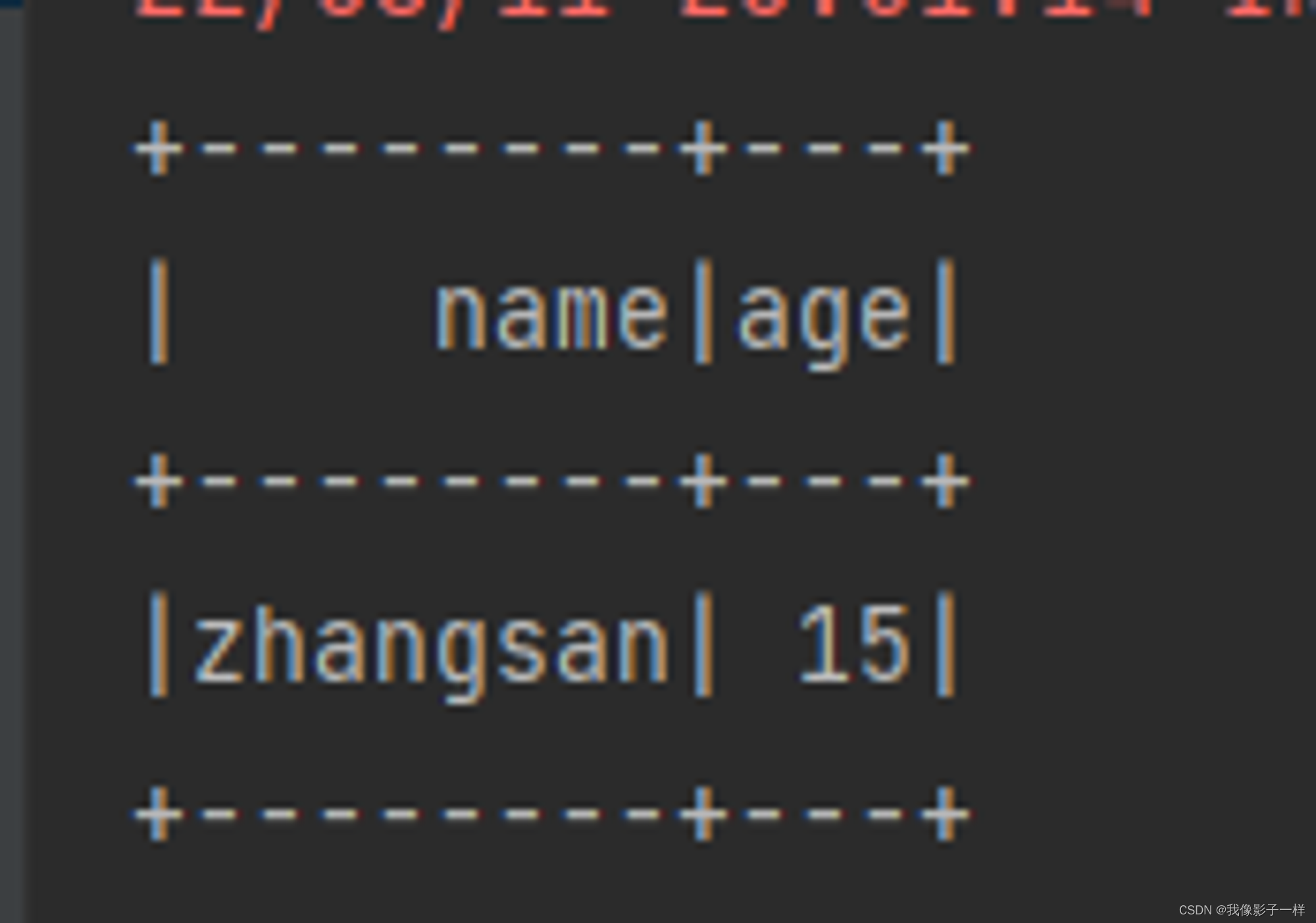
-
distinct
当 dropDuplicates 中没有传入列名的时候, 其含义是根据所有列去重, dropDuplicates() 方法还有一个别名, 叫做 distinct
所以, 使用 distinct 也可以去重, 并且只能根据所有的列来去重
@Test def dropDuplication(): Unit = { val ds = spark.createDataset(Seq(Person("zhangsan", 15), Person("zhangsan", 15), Person("lisi", 15))) // distinct ds.distinct().show() }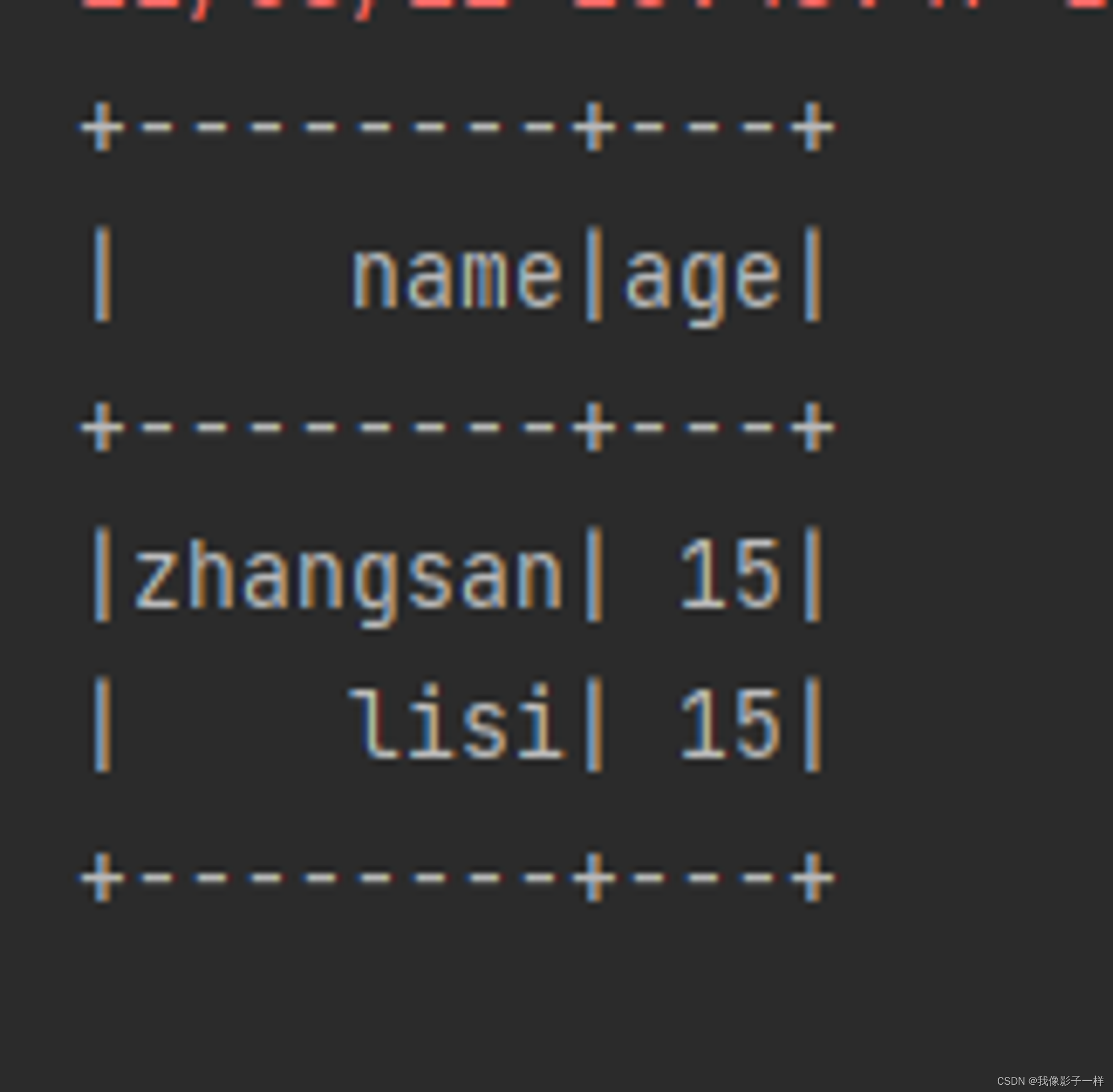
-
集合操作
-
集合操作
-
except
except 和 SQL 语句中的 except 一个意思, 是求得 ds1 中不存在于 ds2 中的数据, 其实就是差集
@Test def collection(): Unit = { val ds1 = spark.range(1, 10) val ds2 = spark.range(5, 15) // 差集 ds1.except(ds2).show() }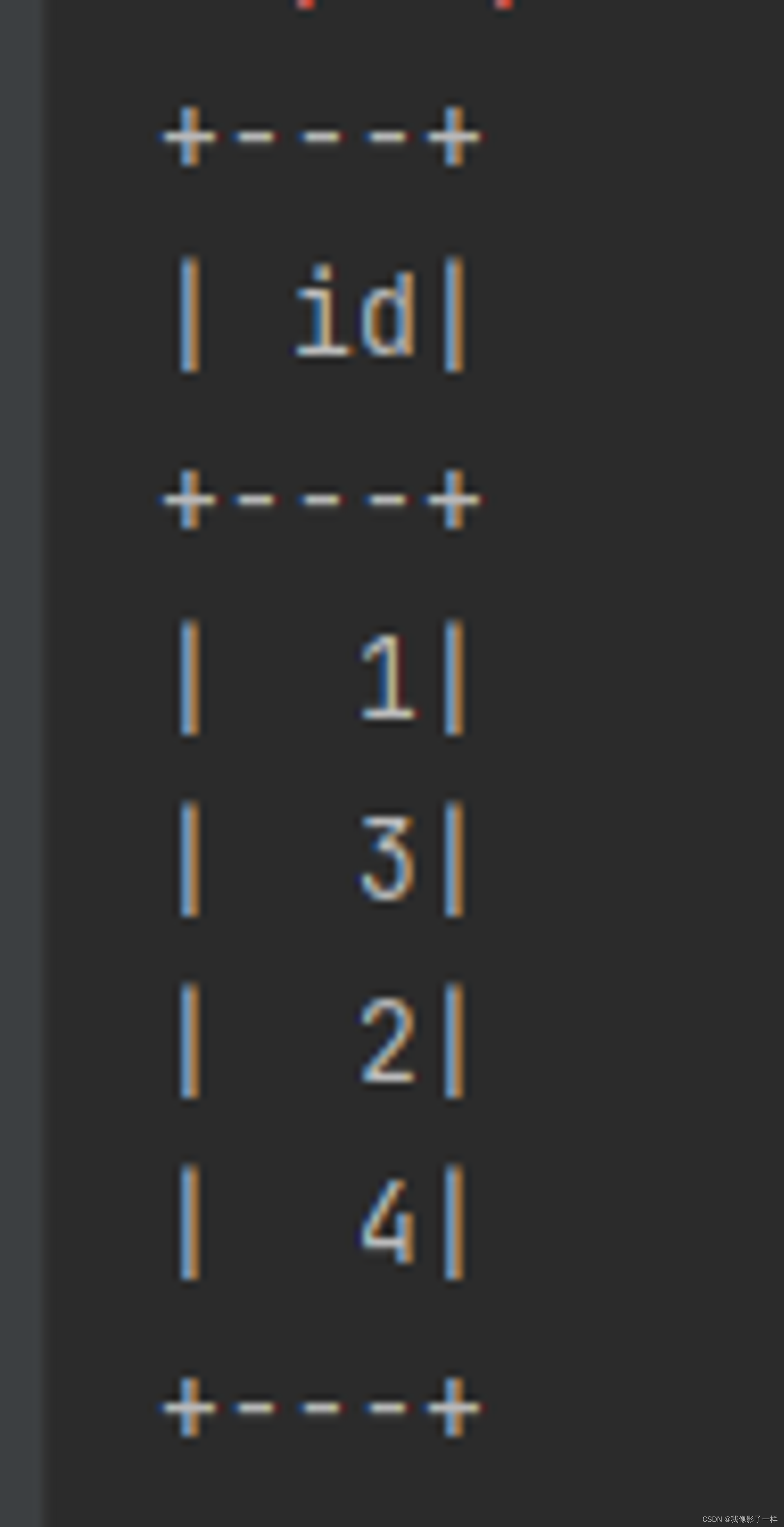
-
intersect
求得两个集合的交集
@Test def collection(): Unit = { val ds1 = spark.range(1, 10) val ds2 = spark.range(5, 15) // 交集 ds1.intersect(ds2).show() }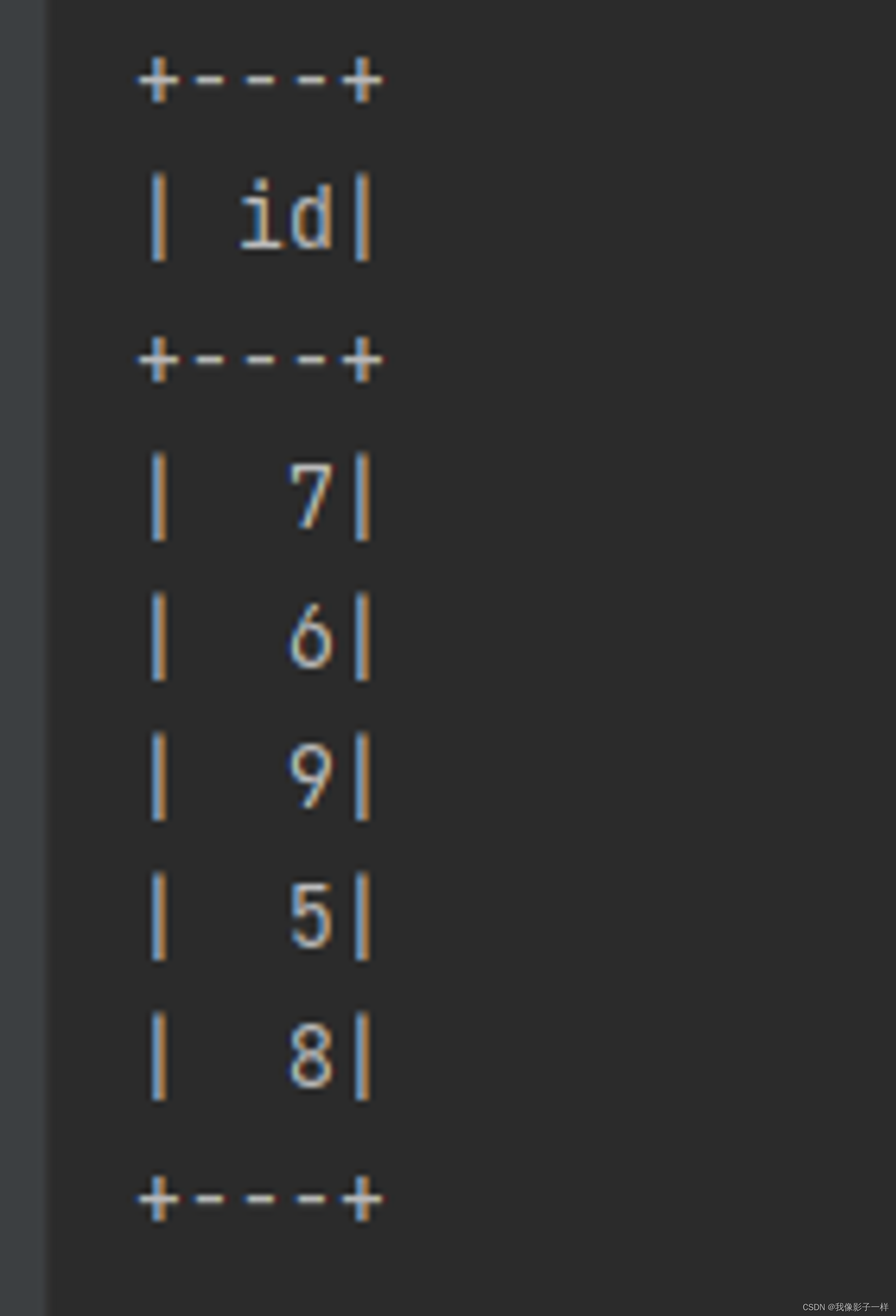
-
union
求得两个集合的并集
@Test def collection(): Unit = { val ds1 = spark.range(1, 10) val ds2 = spark.range(5, 15) // 并集 ds1.union(ds2).show() }
-
limit
限制结果集数量
@Test def collection(): Unit = { val ds1 = spark.range(1, 10) val ds2 = spark.range(5, 15) // limit ds1.limit(3).show() }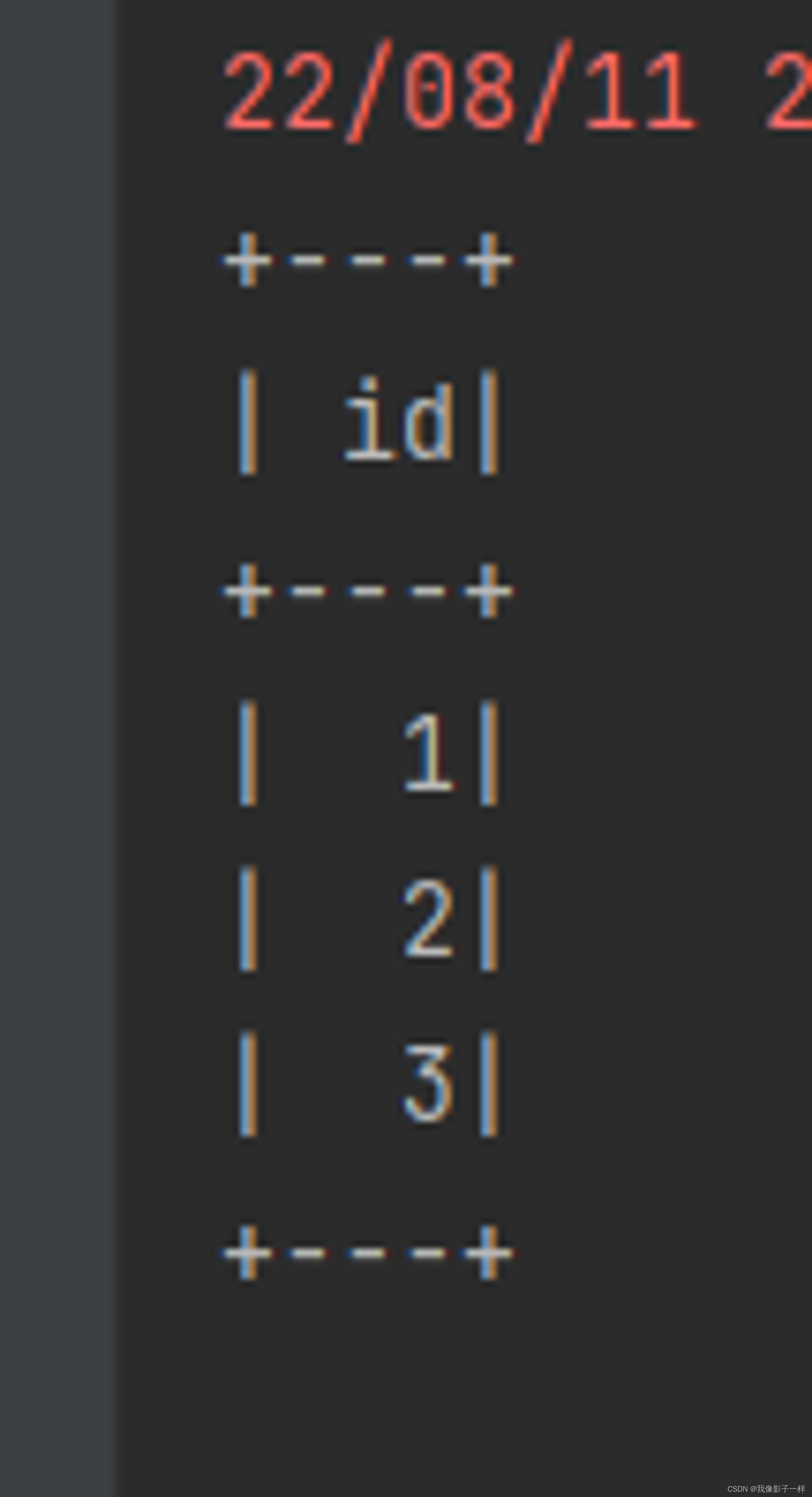
-
-
所用文件
[studenttab10k.zip]
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【分享&备忘录】Postgresql/pgsql 根据规则,批量联级删除多张表
- 生成式AI,发展可持续吗?
- 12.31信号位宽转换(整数,非整数),时钟分频(奇数,偶数,任意小数,占空比),自动售货机(1,2),游戏机
- Istio-gateway
- 【?什么是分布式系统的一致性 ?】
- AD采集卡设计方案:630-基于PCIe的高速模拟AD采集卡
- windows中修改my.ini出现MySQL服务正在启动或停止中或服务无法启动
- 大一C语言作业 12.8
- 抠图软件哪个好用?这4款轻松一键抠图!
- 【html】输入框里按了一下回车,页面就刷新了,怎么解决?