SparkSQL——(扩展) Cataylst
(扩展) Cataylst 优化器
-
RDD 和 SparkSQL 运行时的区别
RDD 的运行流程
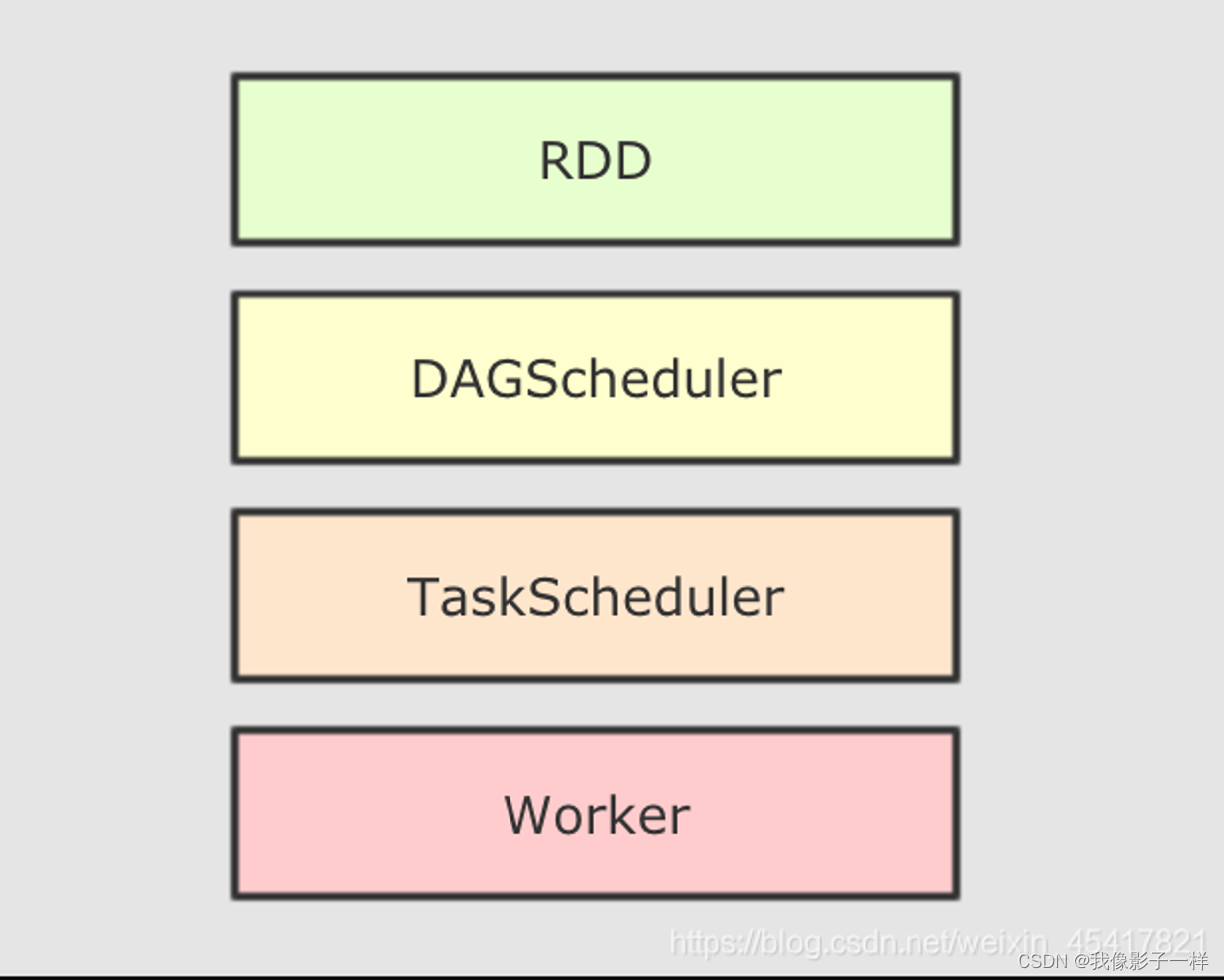
大致运行步骤:
- 先将 RDD 解析为由 Stage 组成的 DAG, 后将 Stage 转为 Task 直接运行
问题:
- 任务会按照代码所示运行, 依赖开发者的优化, 开发者的会在很大程度上影响运行效率
解决办法:
- 创建一个组件, 帮助开发者修改和优化代码, 但是这在 RDD 上是无法实现的
为什么 RDD 无法自我优化?
- RDD 没有 Schema 信息
- RDD 可以同时处理结构化和非结构化的数据
SparkSQL 提供了什么?
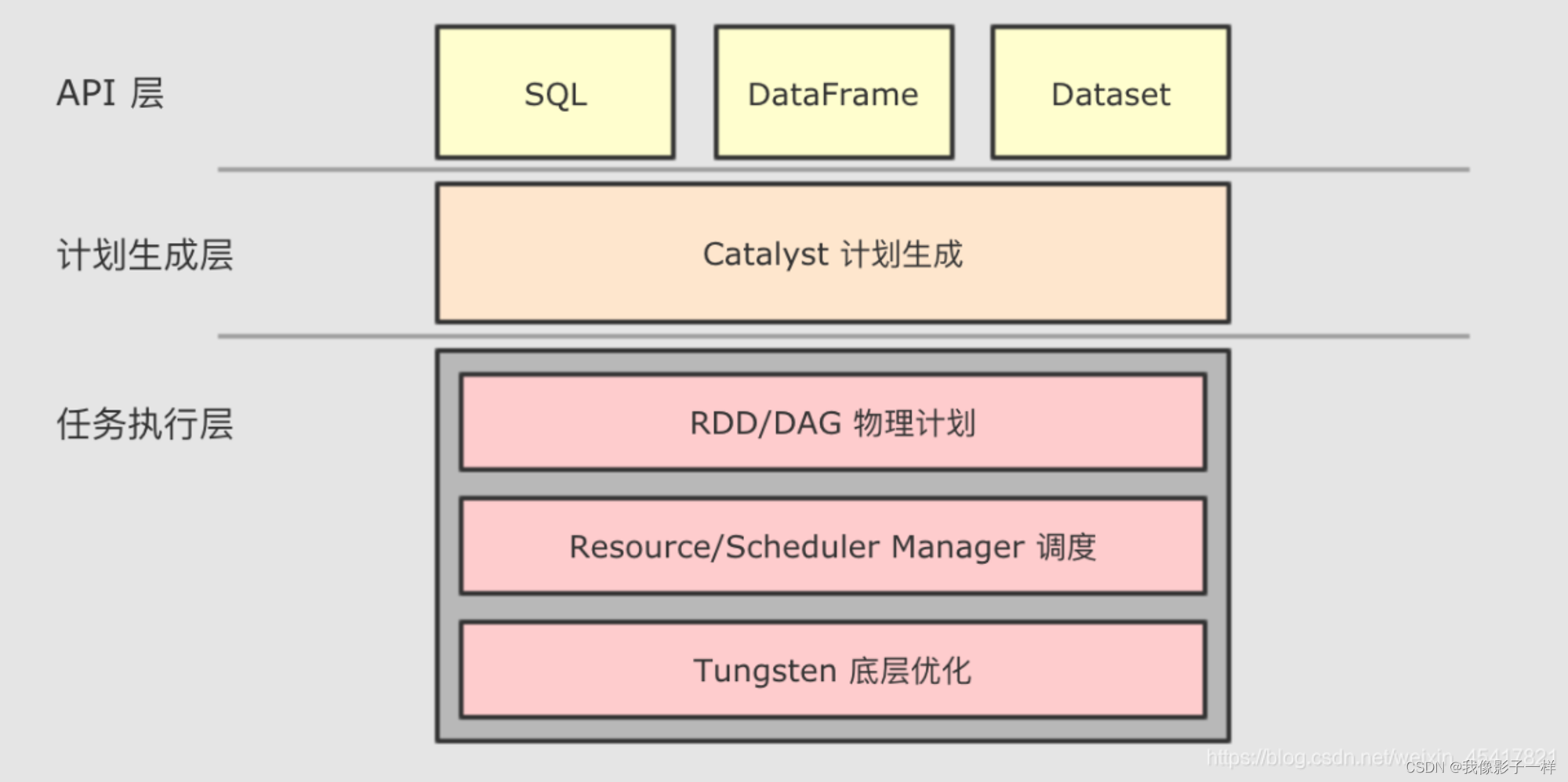
和 RDD 不同, SparkSQL 的 Dataset 和 SQL 并不是直接生成计划交给集群执行, 而是经过了一个叫做 Catalyst 的优化器, 这个优化器能够自动帮助开发者优化代码
也就是说, 在 SparkSQL 中, 开发者的代码即使不够优化, 也会被优化为相对较好的形式去执行
为什么 SparkSQL 提供了这种能力?
首先, SparkSQL 大部分情况用于处理结构化数据和半结构化数据, 所以 SparkSQL 可以获知数据的 Schema, 从而根据其 Schema 来进行优化
-
Catalyst
为了解决过多依赖 Hive 的问题, SparkSQL 使用了一个新的 SQL 优化器替代 Hive 中的优化器, 这个优化器就是 Catalyst, 整个 SparkSQL 的架构大致如下

- API 层简单的说就是 Spark 会通过一些 API 接受 SQL 语句
- 收到 SQL 语句以后, 将其交给 Catalyst, Catalyst 负责解析 SQL, 生成执行计划等
- Catalyst 的输出应该是 RDD 的执行计划
- 最终交由集群运行

Step 1 : 解析 SQL, 并且生成 AST (抽象语法树)
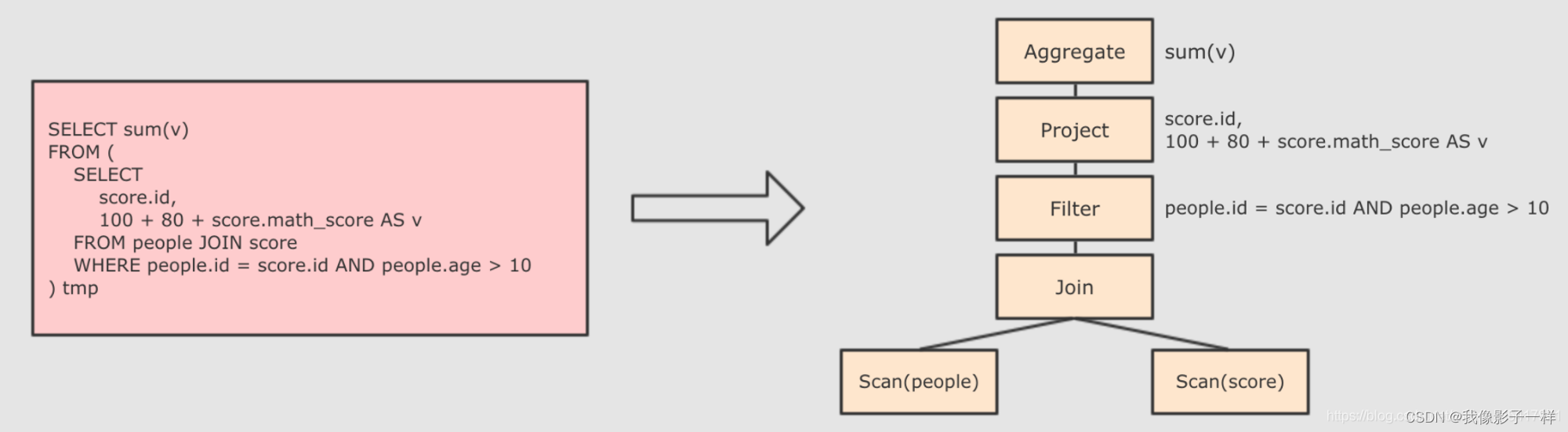
Step 2 : 在 AST 中加入元数据信息, 做这一步主要是为了一些优化, 例如 col = col 这样的条件, 下图是一个简略图, 便于理解
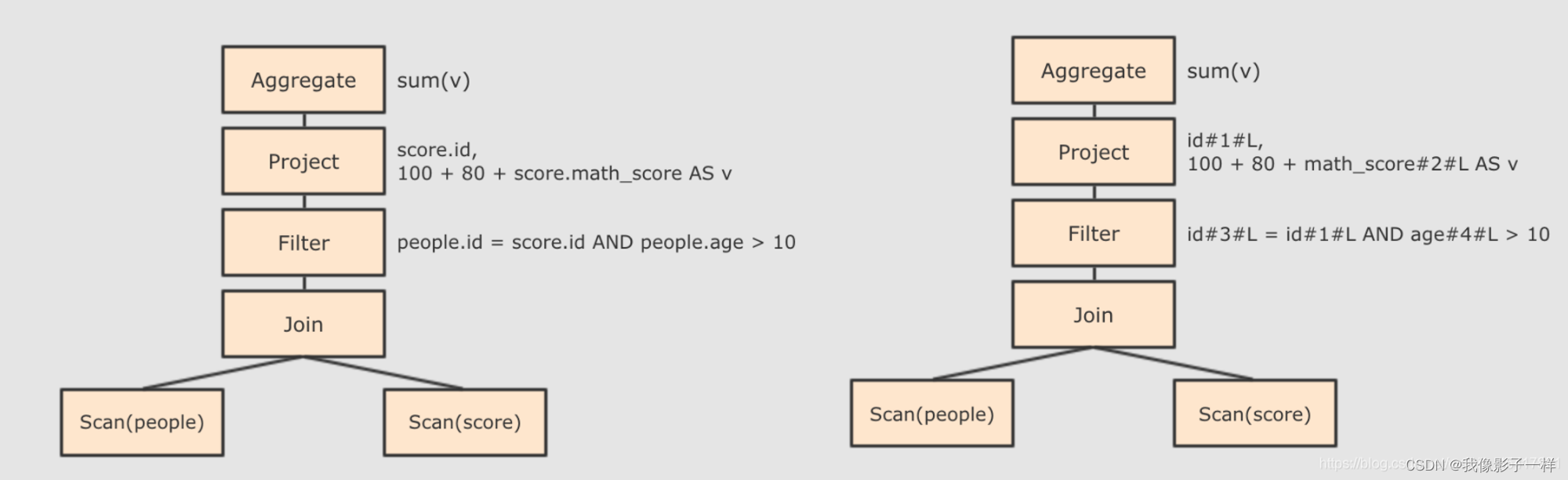
- score.id → id#1#L 为 score.id 生成 id 为 1, 类型是 Long
- score.math_score → math_score#2#L 为 score.math_score 生成 id 为 2, 类型为 Long
- people.id → id#3#L 为 people.id 生成 id 为 3, 类型为 Long
- people.age → age#4#L 为 people.age 生成 id 为 4, 类型为 Long
Step 3 : 对已经加入元数据的 AST, 输入优化器, 进行优化, 从两种常见的优化开始, 简单介绍
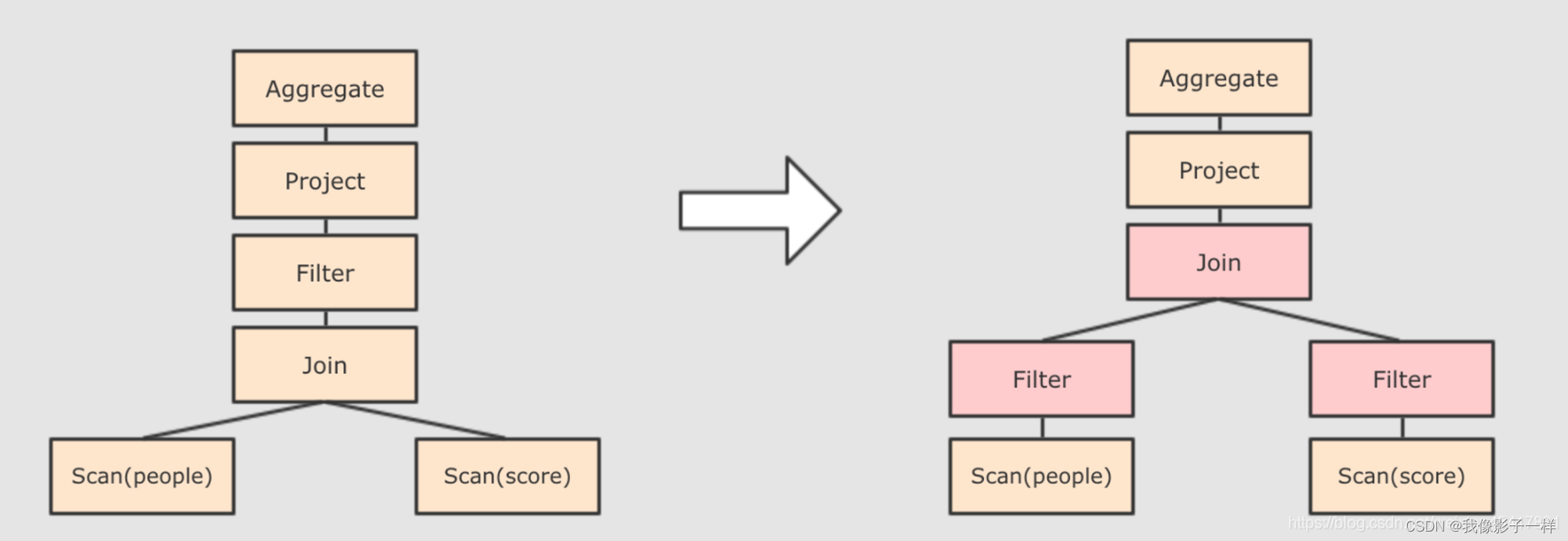
谓词下推 Predicate Pushdown, 将 Filter 这种可以减小数据集的操作下推, 放在 Scan 的位置, 这样可以减少操作时候的数据量
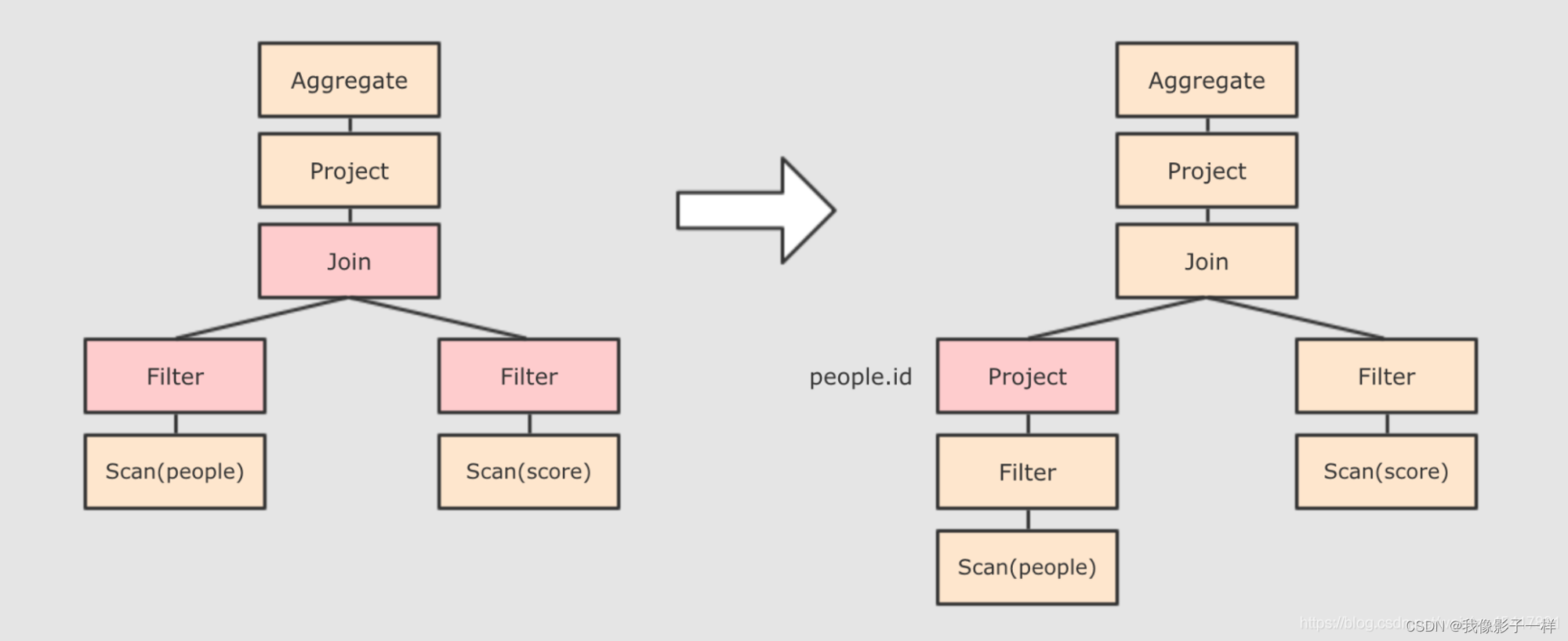
- 列值裁剪 Column Pruning, 在谓词下推后, people 表之上的操作只用到了 id 列, 所以可以把其它列裁剪掉, 这样可以减少处理的数据量, 从而优化处理速度
- 还有其余很多优化点, 大概一共有一二百种, 随着 SparkSQL 的发展, 还会越来越多, 感兴趣的同学可以继续通过源码了解, 源码在 org.apache.spark.sql.catalyst.optimizer.Optimizer
Step 4 : 上面的过程生成的 AST 其实最终还没办法直接运行, 这个 AST 叫做 逻辑计划, 结束后, 需要生成 物理计划, 从而生成 RDD 来运行
- 在生成
物理计划的时候, 会经过成本模型对整棵树再次执行优化, 选择一个更好的计划 - 在生成
物理计划以后, 因为考虑到性能, 所以会使用代码生成, 在机器中运行
可以使用 queryExecution 方法查看逻辑执行计划, 使用 explain 方法查看物理执行计划
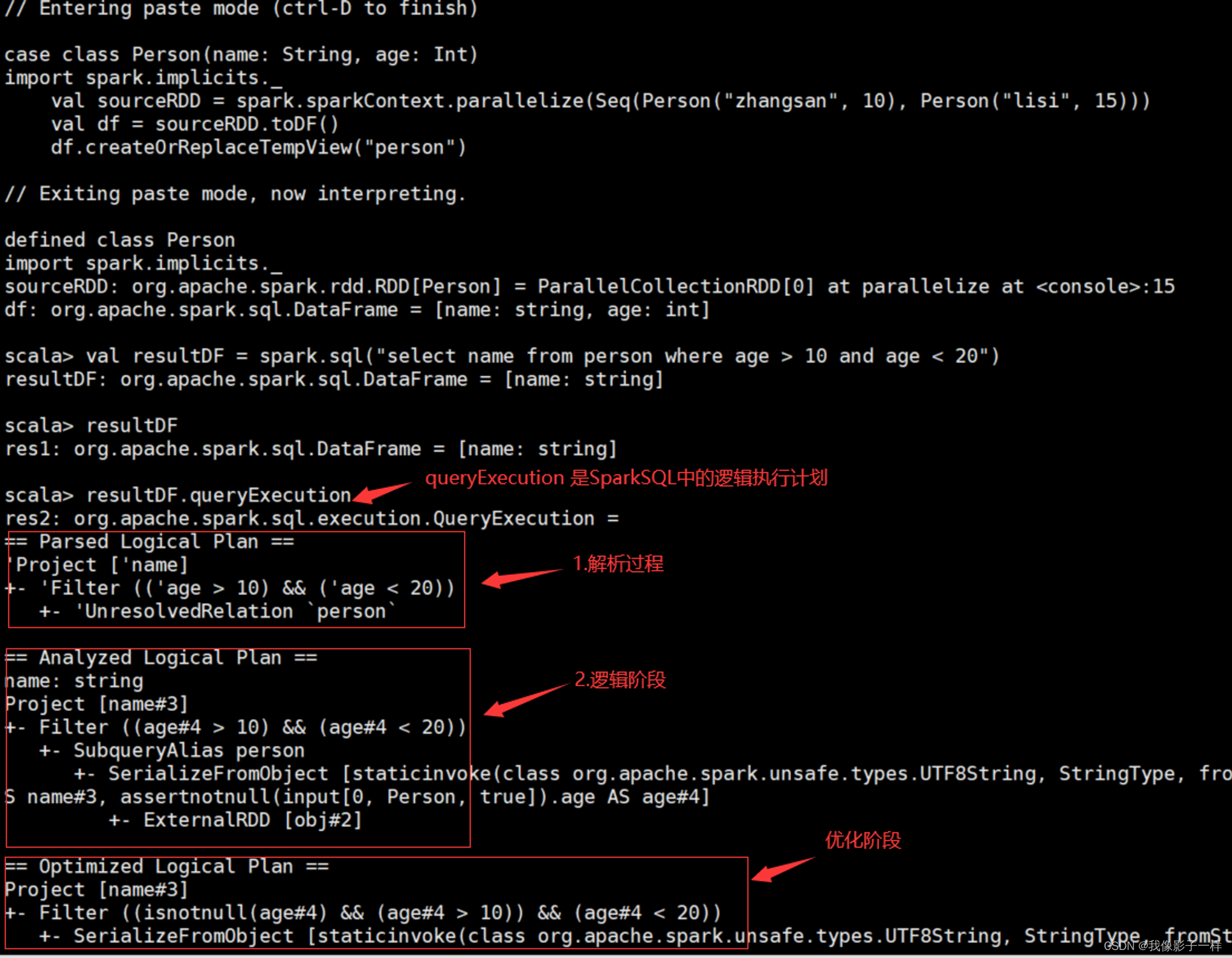
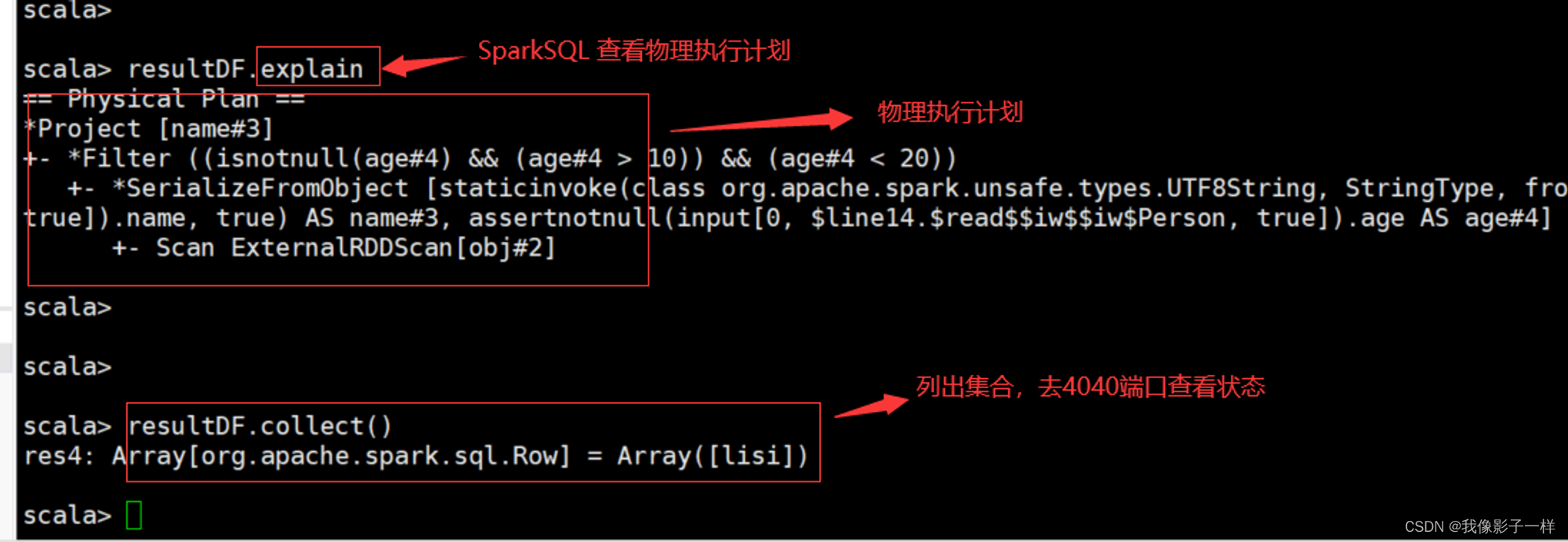
使用 Spark WebUI 进行查看
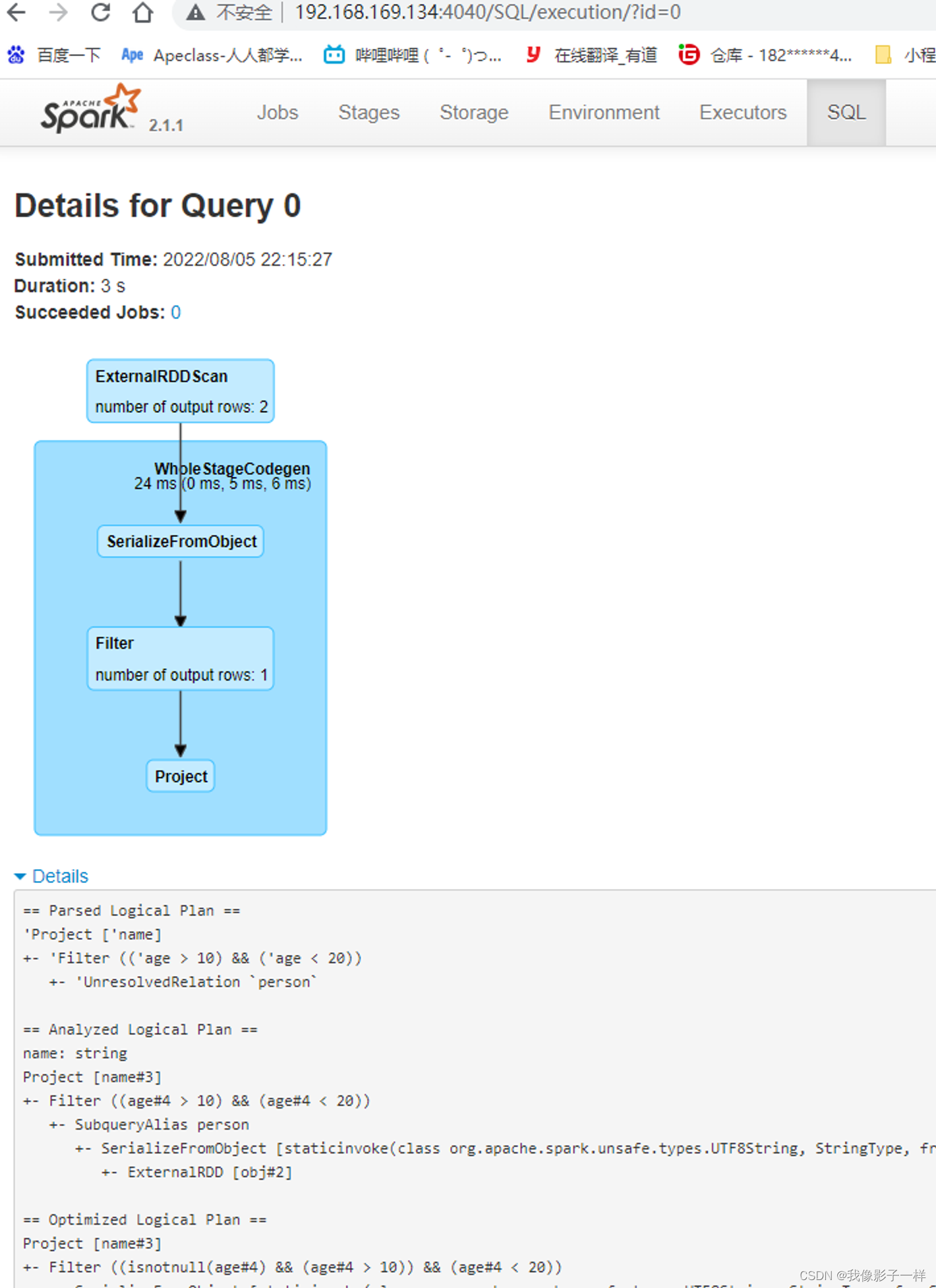
总结
- SparkSQL 和 RDD 不同的主要点是在于其所操作的数据是结构化的, 提供了对数据更强的感知和分析能力, 能够对代码进行更深层的优化, 而这种能力是由一个叫做 Catalyst 的优化器所提供的
- Catalyst 的主要运作原理是分为三步, 先对 SQL 或者 Dataset 的代码解析, 生成逻辑计划, 后对逻辑计划进行优化, 再生成物理计划, 最后生成代码到集群中以 RDD 的形式运行
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- DockerFile常用保留字指令及知识点合集
- FPGA高端项目:UltraScale GTH + SDI 视频编解码,SDI无缓存回环输出,提供2套工程源码和技术支持
- Day25 235二叉搜索树的公共祖先 701二叉搜索树插入 450二叉搜索树删除
- 前端密钥怎么存储,以及临时存储一些数据,如何存储才最安全?
- 【js】js数组对象去重:
- 阿里云Centos6/7/8 转换为Red Hat Enterprise Linux(RHEL)6/7/8
- 树莓派摄像头使用python获取摄像头内容将图片上传到百度云识别文字并将识别结果返回
- 爬虫-10-selenium自动化(2)
- thinkphp5自定义命令行要进入到网站的目录下运行php think test
- DRL入门