爬虫逆向开发教程1-介绍,入门案例
发布时间:2024年01月18日
爬虫前景
在互联网的世界里,数据就是新时代的“黄金”。而爬虫,就是帮助我们淘金的“工具”。随着互联网的不断发展,数据量呈现指数级的增长,在数据为王的时代,有效的挖掘数据和利用,你会得到更多东西。
学完爬虫你可以从事爬虫开发的工作,一个3-5年的爬虫工程师可以拿20k以上。相比Java,爬虫竞争少,好就业。
同时你也可以做爬虫兼职,每月能挣个大几千。
接下来我们正是学习爬虫。
什么是爬虫?
爬虫,顾名思义,就是像“爬行动物”一样在互联网上爬来爬去,收集信息的程序。它主要通过特定的算法,自动地从一个或多个网页开始,按照预设的规则下载并提取所需要的数据。简单来说,爬虫就是一个自动化的信息搜集工具。
从编程的角度说:用代码代替人去模拟浏览器或手机去执行执行某些操作。
例如:
-
自动登录钉钉,定时打卡
-
去91自动下载图片/视频
-
去京东抢茅台

分析&模拟
分析一个网址,用requests请求就可以实现。
分析:基于谷歌浏览器去分析。
模拟:基于requests模块发送请求。
pip3.11 install requests案例一
抓取数据的 username 和 标题

import requests
import json
res = requests.get(
url='https://api.huaban.com/search/file?text=%E5%86%99%E7%9C%9F&sort=all&limit=40&page=1&position=search_pin&fields=pins:PIN,total,facets,split_words,relations,recommend_topics'
)
#print(res.text)
data = json.loads(res.text)
pin_list = data['pins']
for item in pin_list:
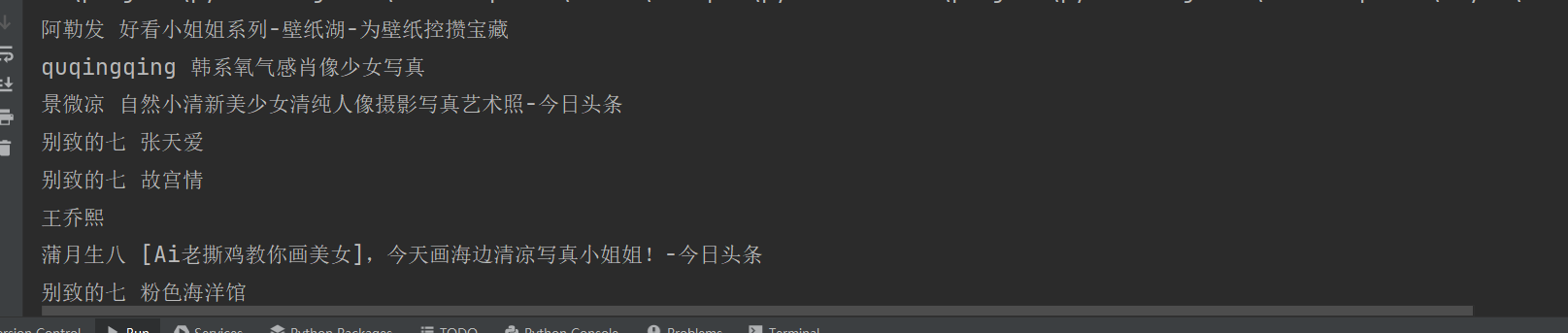
print(item['user']['username'], item['raw_text'])抓取结果:
文章来源:https://blog.csdn.net/lizhongjun1005/article/details/135657445
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 南大通用 GBase 8a MPP Cluster V95 数据库安装
- 宠物干货类软文怎么写?媒介盒子分享
- Java实现大病保险管理系统 JAVA+Vue+SpringBoot+MySQL
- gcc扩展选项__attribute__((interrupt))——指定中断处理函数属性
- 【ChatGPT-Share,国内可用】GPTS商店大更新:一探前沿科技的魅力!
- [Linux开发工具]——vim使用
- Linux运维手册:最常用的Linux命令行
- 金融业文件管理指南:如何保障文件安全与高效利用?
- Web组态可视化编辑器-by组态
- React16源码: React中的schedule调度整体流程