51-14 Retentive Network,RetNet 多尺度保留机制序列建模论文精读
咱们今天来看的论文叫RetNet,题目是Retentive Network:a successor to transformer for large language models。我们知道BLIP成了一个非常普适的一个工具,你可以拿这个模型去训练VLMo,训练CoCa,训练BEiT-3,去训练各种各样的多模态模型,因为它的目的就是生成更好的数据。 BEiT-3呢,他的核心思想是将图像建模为一种语言,这样我们就可以对图像、文本以及图像-文本对进行统一的mask?modeling。BEiT-3模型可以有效地完成不同的视觉和视觉语言任务,使其成为通用建模的一个有效选择。BLIP,BEiT-3这两个比较经典的模型都是基于Vision transformer,ViT而来,都是在利用transformer的encoder,decoder或者encoder-decoder各种组合完成建模任务,然而RetNet网络模型则是在魔改transformer架构。咱们来看看RetNet究竟是怎样做到的?
多尺度保留机制Retention与标准自注意力机制相比,有几大特点:
引入位置相关的指数衰减项取代 softmax,简化了计算,同时使前步的信息以衰减的形式保留下来。引入复数空间表达位置信息,取代绝对或相对位置编码,容易转换为循环的形式。另外,保持机制使用多尺度的衰减率,增加了模型的表达能力,并利用 GroupNorm 的缩放不变性来提高 Retention 层的精度。
Abstract
在这项工作中,我们提出了保留网络RetNet作为大型语言模型的基础架构,同时实现了并行训练、低成本推理和良好的性能。我们从理论上推导了循环和注意力之间的联系。然后,我们提出了序列建模的保留机制,该机制支持三种计算范式,即并行、循环和分块循环。具体地说,并行表示允许训练并行性。循环表示实现了低成本的O(1)推理,在不牺牲性能的情况下提高了解码吞吐量、延迟和GPU内存。逐块循环表示有助于以线性复杂性进行高效的长序列建模,其中每个块都是并行编码的,同时循环汇总块。语言建模实验结果表明,RetNet具有良好的可伸缩性、并行训练、低成本部署和高效推理等特点。有趣的特性使RetNet成为大型语言模型Transformer的有力继承者。代码在https://aka.ms/retnet.
Introduce
Transformer计算复杂,内存使用量高,推理效率低下。
Transformer已成为大型语言模型的实际架构,最初提出该架构是为了解决循环模型的序列训练问题。然而,由于每一步的O(N)计算复杂性和内存绑定的键值缓存,Transformers的训练并行性是以低效推理为代价的,这使得Transformers对部署不友好。不断增长的序列长度增加了GPU内存消耗以及延迟,并降低了推理速度。
在开发下一代架构方面,我们继续做出了大量努力,旨在保持训练并行性和transformer的竞争性能,同时具有高效的O(1)推理。同时实现上述目标是具有挑战性的,即所谓的“不可能的三角形”。

要解决该问题,当前主要研究有三个方面。
首先,线性化注意力,他用内核近似标准注意力分数,使得自回归推理可以以递归循环形式重写。然而,建模能力和性能比Transformers差,这阻碍了该方法的流行。第二,仍然用递归模型,实现高效推理,同时牺牲训练并行性。作为补救措施,使用逐元素运算符进行加速,但表示能力和性能会受到损害。第三,研究探索用其他机制取代注意力,之前的作品都无法突破不可能的三角,导致与transformer相比没有明确的赢家。
在这项工作中,我们提出了保留网络(RetNet),同时实现了低成本的推理、高效的长序列建模、Transformer的可比性能和并行模型训练,打破了不可能三角。
具体来说,我们引入了一种多尺度保留机制来代替多头注意力。
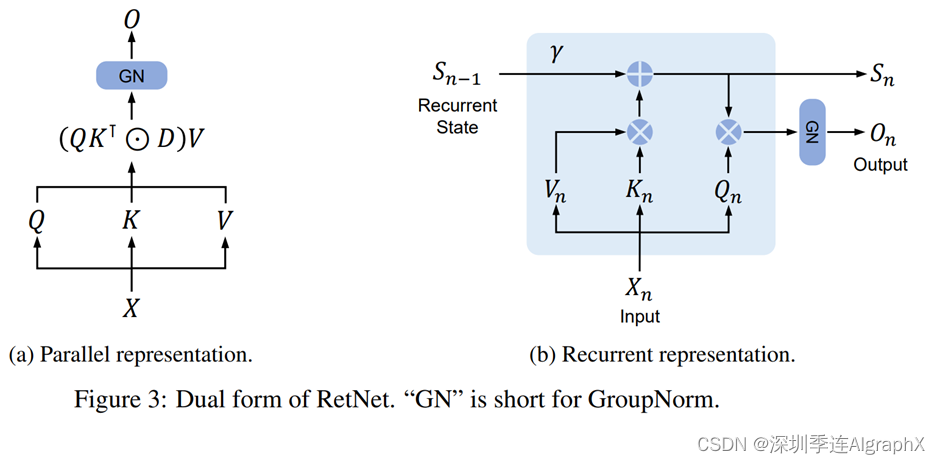
它有三种计算范式,即并行、循环和分块循环表示。首先,并行表示使训练能够并行利用GPU设备。其次,循环表示能够在记忆和计算方面实现有效的O(1)推理。可以显著降低部署成本和延迟。此外,在没有键值缓存技巧的情况下,实现大大简化。第三,分块循环表示可以进行有效的长序列建模。为了计算速度,我们对每个局部块进行并行编码,同时对全局块进行循环编码以节省GPU内存。
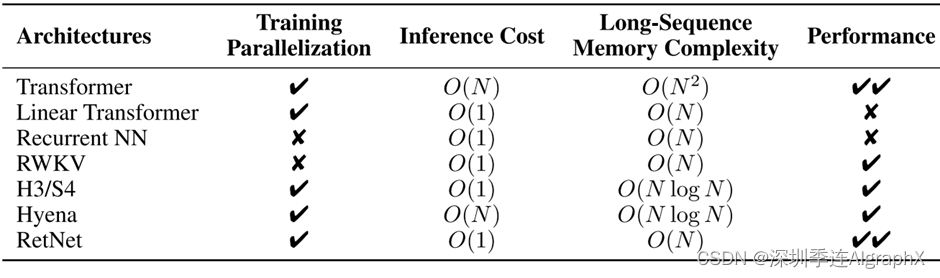
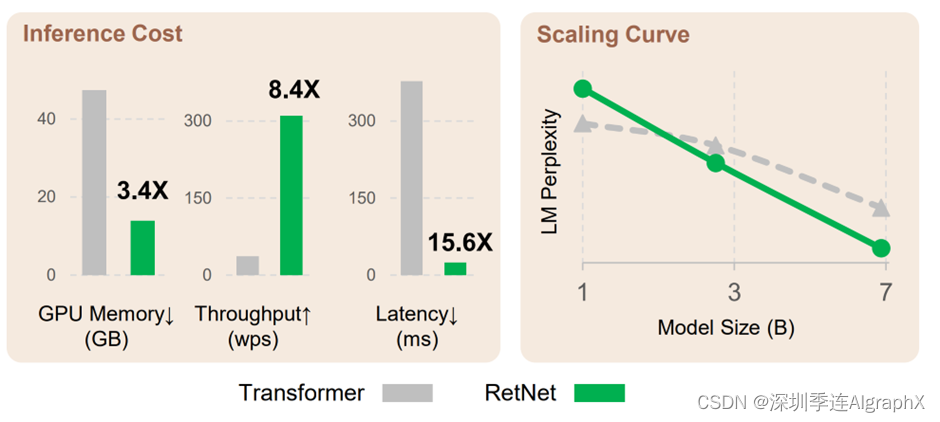
我们进行了广泛的实验,将RetNet与Transformer及其变体进行比较。语言建模的实验结果表明,retnet的推理成本与序列长度无关,以7B模型和8K序列长度为例,retnet的解码速度是带键值缓存的transformer的8.4倍,且内存节省达到70%。在训练过程中,retnet相较于标准transformer也能够节省25%~50%的内存,并实现了7倍的加速,在高度优化的Flashattention方面表现出优势。
Retentive Networks
多尺度保留机制RetNet 架构和 Transformer 类似,也是堆叠?L?层同样的模块,包括残差连接和pre-LayerNorm,每个模块包含两个子模块:一个 multi-scale retention(MSR),一个 feed-forward network (FFN)。该篇论文的主要目的是致力于更改transformer里面的self attention来达到节约资源,处理长序列这么一个目的。
网络结构如下:

(PS:我用Mathpix,MathType两工具,转到CSDN里面的LaTex格式,一直报错,只好贴图。特抱歉,有错的地方,请及时指出,谢谢!)
transformer是用来处理一个序列,这个序列表示成vector,每一个vector,我们叫它token。token的数量x表示每一个token的长度,它的尺寸也就是这个vector的长度,就是dmodel。对于每一个transformer encoder来说,它包含两个部分,一个是这个multi-head self-attention,另一个是这个feed forward network,FFN本质上是一个MLP。当然它的瓶颈就是在于attention。所以本文致力于用这个multi-scale retention,确切的说是gated multi-scale attention来替换原有的attention,来达到一个节约资源,处理长序列的目的。当然,Transformer原来是一层叠一层的,序列过了transformer之后,它的尺寸不变。现在retnet里面换了attention,网络的结构依然不变,那么现在是什么样的尺寸的序列进来,还是什么样的尺寸的序列出去。etention既然是为了替换attention,那它这里肯定也处理一个序列的这个token。
咱们来看RetNet怎么设计的?
X0字母的上标o是encoder的层数,字母的下标|x|,是这个token它的这个index,这里retention的目的和attention一样,都是想把一系列的这个token变换到另一个系列。在做attention的时候,所有的token都参与预算,随着序列的增长,运算量也不断的增加。然而在真正做模型语言生成任务时,其实是一个token一个token来生成,是一个autoregressive的方法(原文说RetNet encodes the sequence in an autoregressive way)。所以本论文的核心就是围绕着如何设计一种让它非常契合autoregressive方法。也就是说,当生成一个新的token的时候,不用把之前的所有的token再重新做一遍计算,这是本文的核心的思想。
Retention
下面将充分运用transformer模型种attention计算K,Q,V值的方法。关于K,Q,V工作原理,个人看了很多篇文档,感觉李沐老师讲得特别透彻,请参见文档。
咱们来看输入,输出。

这是一个很直接的设计,那么在这个设计的基础上,不断的迭代。这个就是作者一个最开始的思路,借鉴了这个recurrent neural network,当然按照self-attention的机制,这个q矩阵,k矩阵,它都是输入的这个token变换得来的。
那么怎么样在这个基础上把我们的运算进一步化简?
我们可以看到,因为我们的A矩阵是取了一个n-m次方,很自然的我们就想到这个特征值分解。
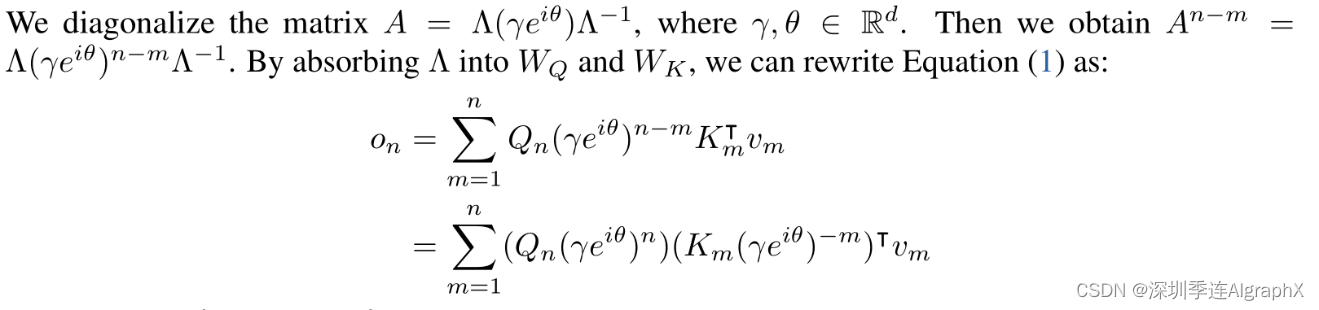
那么把A矩阵写成特征值这样的形式之后,An-m的值就是两两相乘,它的特征矩阵就约掉了。那么你最终形成的就是这个样子,头上有一个^,尾巴上有一个^,中间是它的特征值的矩阵的n-m次方。正好这里我们A这个矩阵,它的前后都有一个矩阵,我们会很自然的想,反正你前后两个矩阵都是学出来的,我就把这个特征值矩阵也都塞回到周围的前后的两个矩阵里面,这样子我的这个公式写出来就相对简单一点。接着将公式简化,将?γ 改为一个实数常量,经过这里矩阵的幂进一步拆分,这样一层操作之后,这个公式就写成了最后这个样子。
后面的运算,它的灵感来自于Xpos。
我们仔细来看上面的公式,其实一开始大家应该会有疑惑,为什么我们把特征值矩阵写成了γ这个样子。作者在这里,考虑在最一般的情况下,这个参数值,有可能是一个复数,为了优雅的表达这个复数,才写成了这个形式。这个i是那个复数单位,都把它理解成复平面上的一个极坐标,有极坐标的长度和朝向。因为有很多个特征值,这里的西塔和伽马都是向量vector,这个数其实就是表达了一个在复平面上任意数,填充在那个矩阵的对角线上的,对吧?对于每一个特征值来说,现在假设它的这个伽马都是同样的一个定值,那么在这个假设下,所有的特征值都会落到一个圆上,对吧?因为你想它们的长度都是固定的,唯一区别的就是一个角度,那么标量这个东西处理起来就很方便了。把它全部都拿出来,拿到最开始,那么然后我们来看这个角度,怎么样优雅的把这个负号拿出来,就是转置变成了共轭转制,因为共轭转制本质就是转置加共轭,那共轭的本质是什么?就是实部不变,虚部的这个符号给它取反,那么把这个定义掌握好,你这个表达式就会写得特别优雅。

Source: A Length-Extrapolatable Transformer: http://arxiv.org/abs/2212.10554
现在,我们说回到这个复数,我们引入了复数,难道这意味着我们需要在我们的矩阵中真的是维持一个复数的矩阵吗?当然并不是这样的,因为我们在日常生活中常常适用一个2*2的这样一个旋转矩阵来去表达这个复数。因为你对两个复数做各种操作,本质上跟对这种矩阵做各种操作是没有区别的,这是一个非常好的性质,这就让我们的实际的矩阵中全都是实数,同时它依然保留了这个复数的含义。
那么下面我们就来看具体的这个Xpos,你看这是我们想要表达的一个值,我现在把它写成了这样一个2*2的旋转矩阵的形式,那么对于一个在序列中位置为n的token,我们假设这是最简单的情况,我们假设它有两个channel,那么你的这个表达式写出来是什么样的?对,写出来最后是这个样子。注意,在这里,咱么把这个行矩阵写成了这个列的形式,这样子排版比较方便。当然在实际操作中,只有这样一个频率,这样一个角度是不行的,因为这样的网络就没有办法区分一个周期和两个周期这样的距离的区别。所以在实际使用中,往往都是我们通过增加这个channel的数量,前两个channel对应的是一个频率,后面这两个channel对应一个相对更高的频率,那再往后更高的频率。这样子通过一系列组合,很多个频率不同的cos,sin的组合,就把这个位置的编码真正的给它编出来了。
我们来看到这个xPos里面的这个算法,注意这个是直接从xPos里面的这个文章中截出来的,所以它的这个符号系统,跟我们的这个本文是不太一样的。首先要初始化这个角度,然后我们刚刚说了,我们希望有不同的频率吧来分层,注意这里i,它就不是复数单位,它是它是这个角速度的下标,你可以看到它实际的实现是这个样子。然后构建cos和sin这样的一个矩阵,你在第m个token,第n个这个角速度上,它的这个cos长这个样子,它的sin长这个样子,那注意这里为什么我说是n的角速度,而不是说n个channel的。因为角速度的数量是channel的一半,你在实际使用的时候,它的这个矩阵的排列是,比如说这个是θ,它是一个cosθ1,然后cosθ2这样的排列,你通过这样的一个复制的形式,把你的这个channel的数量从D/2变成了D。 那么怎么做这个矩阵的操作,这一行,我对这个 Q乘以这个Cos加上这个rotate,这个Q乘以这个Sin。rotate是什么样的函数?你可以看到它是这个样子的,它在channel这个层面上,把你的channel的顺序调换一下,那么为什么要做这样的调换,它实际表达的意义是什么?我们来看到这边,这个蓝色的框里面,开始跟cos做计算的时候,就是第一个对第一个,但是,你这里和sin做计算的时候,你考虑到这个矩阵的在这个channel上的这个变换,那么它实际写出来,是这个样子,我这里还是只写了一个频率,一个速度的情况下,那么你发现把这两个加起来啊,按照这样的方法加起来是不是就是它了?其实不是,为什么不是?因为这两个就是两个拆的顺序是交换掉的,你看你看在下面是这个channel靠前,这个channel靠后一点,但是这也不影响,对吧,它本质上都是一样的,这就是xPos最底层的实现。该步骤具体推算,涉及到复数、三角函数和欧拉公式,请参见xPos博文。
总之,我们从循环建模方法开始,然后推导出一个并行公式我们将从V(n)到O(n)的原始映射视为向量,并获得保留机制。保持网络ReNet由堆叠块组成,每个堆叠块包含多尺度保持MSR模块和前馈网络FFN模块组成。MSR模块以自回归的方式对输入序列进行编码,而保留机制以并行方式组合循环器,以并行方式训练模型通过以循环的方式制定从输入到输出的映射,然后导出其并行形式,保留机制实现了高效的序列建模。
The Parallel Representation of Retentio
我们将讨论表示retention的两种不同方式,即并行表示和循环表示。在并行表示中,我们使用三个元素q、k和v来定retention层。q是我们的输入X和权重矩阵Wq的乘积,全部元素乘以复数Θ。k是相似的,但它乘以数据的复共轭。V只是X和另一个权重矩阵Wv的乘积。

如果n大于或等于m,Dnm=γn-m,其中伽玛是常数。如果n小于m,则Dnm为零。D结合了因果掩码和沿相对距离的指数衰减。然后,通过将Q乘以K转置,乘以D,然后将结果乘以V,来计算X的tetention率。
这种并行表示允许我们使用GPU高效地训练模型。
现在我们就拿On来写真正的retention。左边第一方程式是针对特定的第n个token的情况下,现在把这个情况泛化到整个序列。假设有一个序列,那这token的序列,把输入X先做投影,得到Q、K、V,那么然后,要乘上这个刚刚才推导出的xPos。Q、K编码就是这个样子,我们定义这样的一个矩阵Q,那同样的这个K矩阵,这里注意乘的是共轭,也就是负西塔。按照每一个token位置,把Q、K的转置乘起来。剩下的V,直接一个投影,也把它变成矩阵的形式。那么最棘手的,就是这个γ ,在这个情况下,M是应该始终小于N的,所以它变成矩阵之后,它应该是一个三角阵。这个N和M是两个token的index,当N大于M的时候,它就是我们正常的这个值,当N小于M的时候,它取零,就不算这样的一项。
那么我们应该如何理解D呢?它就是你self-attention里面的那个causal mask,就是你当前的token,在计算的时候,它不需要考虑未来token是什么,但是它要考虑过去的token是什么。
γn-m ?表示exponential decay along relative distance。最后一个方程式就是本文最基本的retention的写法。类似attention,在训练的时候只是走一遍forward,就是把一串token投影到另一串token,然后做cross entropy这种loss。retention也是一样,把一串token变换到另一串token,注意记得这里变换完之后加一个group norm,所以这里叫做parallel representation。这个是只在训练中发生的,我们训练的时候跟attention就是一模一样。在此基础上,作者还对这里面的内容做了很多的normalization,比如说最经典的attention里面也有,这个D矩阵它也不是直接用的,也做了normalization,这个retention score,它也是做了一个normalization。
The Recurrent Representation of Retention
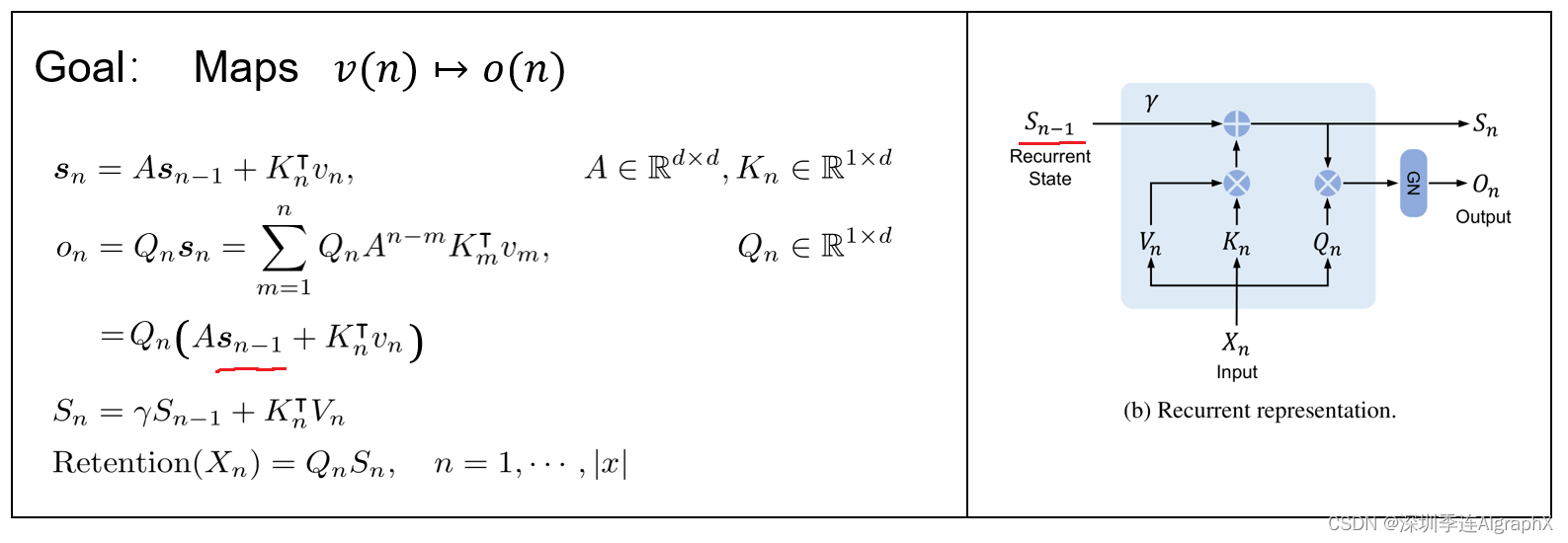
循环表示有点不同,Retention依赖前面一个token的state,它被写成一个循环神经网络RNN,这有利于推理。
针对inference的时候,本文的retention有一个非常好的构型Recurrent Representation。
先维护一个state,一个新的token进来,更新这个state。这个新生成的这个token是根据原来state更新而来。有这么一个好的性质,所以这也就意味着生成的过程其实只依赖于上一个这个recurrent state,相当于你把过去所有的这些token的精华都浓缩到Sn-1里面,然后每次进来一个新的token,更新一下这个state,然后再基于这个state去生成你的输出。那么这个就是最经典的recurrent new netwrork。当然记得这里输出的时候也要加上group normalization,这样操作的时候,influence的时候,也就是你autoregressive生成的时候,它的速度就是非常快。这种形式,作者叫他 Recurrent Representation of Retention。它既保留了像transform一样,一次这个前向传播,就能够把所有的头token都训练出来。训练一个sequence的时候,只需要做一次前向传播。同时,它也有recurrent这样的性质,就是在推理的过程中,只依赖于过去的一个状态,而不是把过去的所有的整个轨迹都找出来,这个是本文最核心的地方。以上并行和循环这两个结构,构建了retention的基本的构型。该结构引起咱们思考,RetNet是否可以胜任记忆的注意力分布在任务间共享,实现多任务协同?
The Chunkwise Recurrent Representation of Retention
我们实际在训练的时候,可能这个文本非常长,有可能出现内存容不下的情况,怎么办?作者说,我们为什么不把这个recurrent和这个parallel结合在一起?

使用并行和循环这两种表示的混合形式可以加快训练,特别是对于长序列。
这个就是chunkwise的recurrent,它意思就是说,把这个长序列分成一个一个的chunk,就相当于local attention的样子。原来的这些Q,K,V都给它结成一块一块。对于每一块的输出来说,有inner-chunk的这个retention作为打底,同时在这个基础上加上一个这个cross-chunk,也就是这个recurrent representation。只不过recurrent representation现在不是token的尺度,它是一个chunk的尺度。
Gated Multi-Scale Retention

这里把Gbated Multi-Scale Retention分成了两部分,一个是gate,一个是multi-scale。我们先看multi-scale,就像Multi-self attention一样,每个head处理不同的信息。同样,在这里同样也是把tensor分成各个head,每个头使用不同的参数矩阵Q,K,V∈Rd×d。此外,多尺度保留(MSR)为每个头分配不同的γ,不同的decay。这个作用是控制一个token到另一个token,随着它们距离的增加,它们相互的影响在衰减。在不同的head里面使用不同的γ ,就是希望不同的head能捕捉到不同的信息。最终,他的γ 的取值如上公式。这是一个跟head一样长的序列,做retention,每个head做自己的group normalization。
此外,我们添加了一个摆动门来增加保留层的非线性,咱们接下来看看gate部分。原始输入乘上矩阵Wg,通过Swish激活函数,调整retention的输出,最后再做一个投影Wo,那么这就是最终gated Multi-Scale Retention,是真正被用来替代self-attention的部分。
Experiments
为了与Transformer 及其他高效变体进行比较,论文中在多个语言任务上进行了大量实验和消融实验。Retnet 的主要优势在是推理,这使得 retnet 非常有可能成为下一代 Transformer 替代品。

消融实验

Conclusion
在这项工作中,我们提出了用于序列建模的保留网络RetNet,它实现了各种表示,即并行、循环和分块循环。RetNet的成绩显著提高推理效率(在内存、速度和延迟方面)、良好的训练并行性以及与Transformers相比具有竞争力的性能。上述优势使RetNet成为大型语言模型Transformers的理想继任者,特别是考虑到O(1)推理复杂性带来的部署优势。未来,我们希望在模型大小和训练步骤方面扩大RetNet。此外,保留网络可以有效地与通过压缩长期记忆的结构化提示。我们还将使用RetNet作为骨干架构来训练多模式大型语言模型。此外,我们有兴趣在各种边缘设备(如手机)上部署RetNet模型。
RetNet在CV任务中的应用前景:
从实验数据看,结合 Vision Transformer,后期RMT模型: Retentive Networks Meet Vision TransformersVision Retnet的出现,RetNet 在视觉领域的应用前景广阔:RetNet有更好的全局注意力建模、高效的计算效率、对遮挡的鲁棒性、支持基于注意力的图像生成、与置信度相关的门控机制和多任务学习等特点,对不同视觉任务可以共享历史注意力记忆,可以同时进行分类、分割、检测等任务。
Reference
https://arxiv.org/abs/2307.08621 RetNet 论文
RetNet: A Successor to Transformer for Large Language Models
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【数据结构】二叉树算法讲解(定义+算法原理+源码)
- Kaptcha 生成图形验证码
- 【Java、Python】获取电脑当前网络IP进行位置获取(附源码)
- java&springboot&Mysql “友书”综合书籍平台系统24489-计算机毕业设计项目选题推荐(附源码)
- 机器学习之协同过滤算法
- 【Python基础】一文搞懂:Python 中 csv 文件的写入与读取
- C#核心--实践小项目(贪吃蛇)
- ATA-3040B功率放大器在磁声声像中的应用研究
- Spring Boot整合Junit
- springboot整合shiro实现前后端分离,兼容最新的jakarta的依赖包(片尾推荐当前最好用的权限框架)