【教学类-35-19】20240117 中4班描字帖(学号+姓名 A4竖版2份 横面)
发布时间:2024年01月17日
作品展示:
背景需求:
2024年1月16日中4班的C老师光荣退休了,2024年1月17日我正式成为中4班的班主任,为了认识新班级的孩子们,我做了一套“中4班的学号名字描字帖”,幼儿描写后拍照,便于我记忆幼儿的基本信息(人脸、学号、姓名)
中4班信息分析:
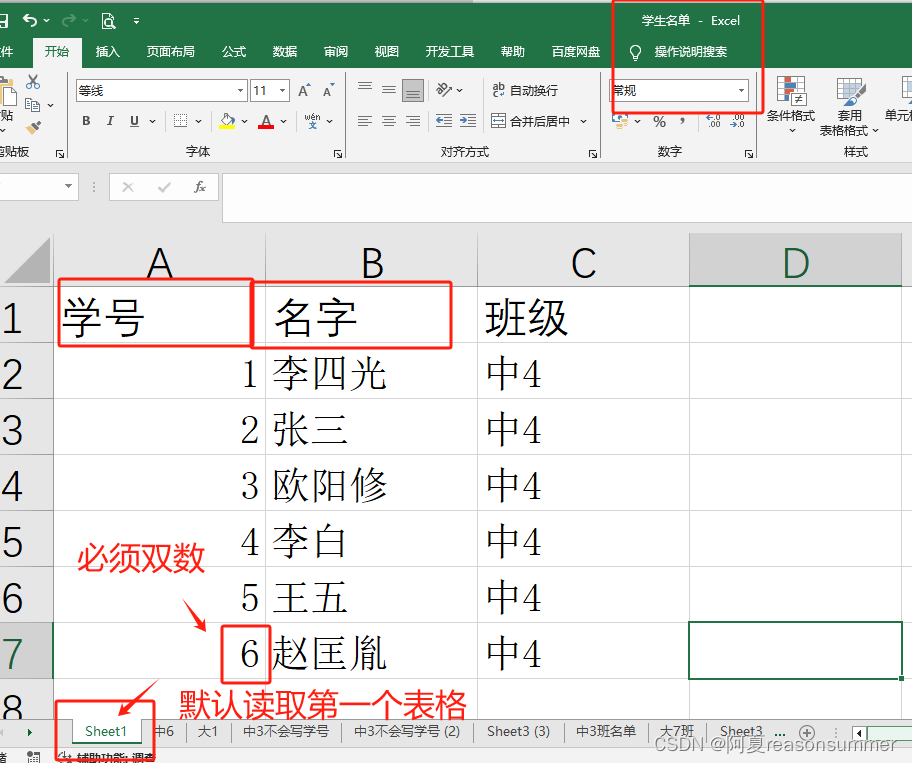
1、总数31人(单数):由于模板是一页两份(双数),所以把31号复制一份放在32号的位置上(31号有两份)
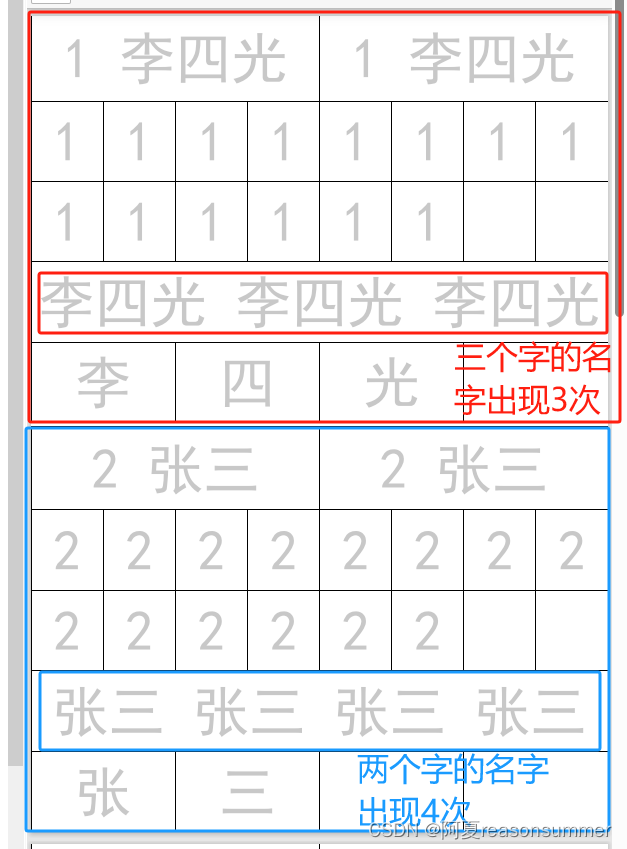
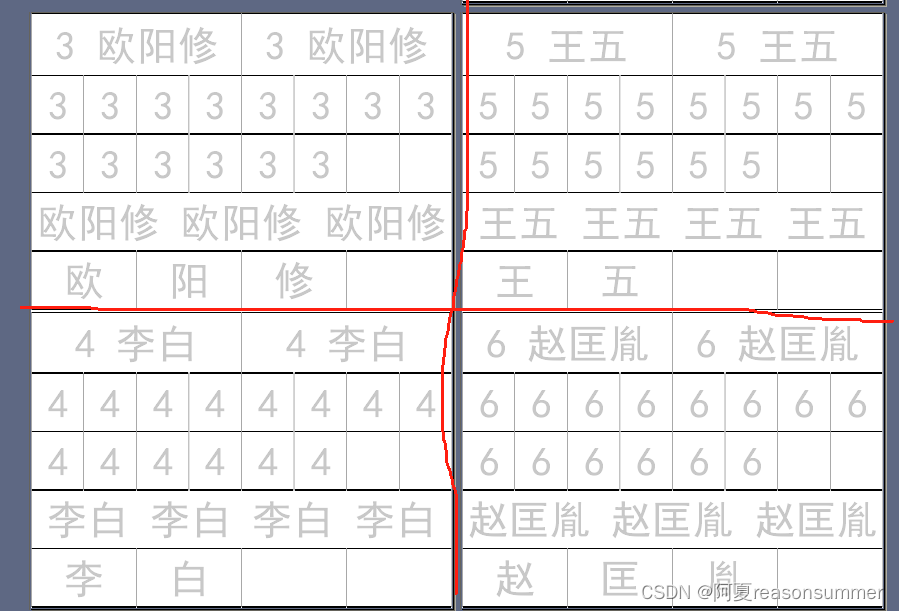
2、近几年来带的班级里几乎只有1-2位孩子是两个字名字。但是中四班有5位孩子是2个名字,数量不少!
3、本次班级里没有4个名字的孩子。
因此我想根据名字是2个字、3个字的差异,制作不同数量的名字模板。
第3行:如果是名字是3个字,姓名字帖部分就出现3次名字,如果名字是2个字,为了填满空格,就让名字字帖部分出现4次2个名字

第4行,如果名字是3个字,写入3个格子,空1个格子,如果名字是2个字,写入2个格子,空2个格子

素材准备:

代码演示
'''
20240116中4班描字帖
作者:阿夏
时间:2024年1月16日
学号和姓名分开
'''
import xlwt
import xlrd
import os
import random
from win32com.client import constants,gencache
from win32com.client.gencache import EnsureDispatch
from win32com.client import constants # 导入枚举常数模块
import os,time
import docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
# hs=int(input('一行2个,需要几行(1行,还有6行是表格)\n'))
print('----------第1步:新建一个临时文件夹------------')
# 新建一个”装N份word和PDF“的临时文件夹
imagePath1=r'C:\Users\jg2yXRZ\OneDrive\桌面\描字帖\零时Word'
if not os.path.exists(imagePath1): # 判断存放图片的文件夹是否存在
os.makedirs(imagePath1) # 若图片文件夹不存在就创建
gz=23
wb= xlrd.open_workbook(r"C:\Users\jg2yXRZ\OneDrive\桌面\描字帖\20240117中4班学号描字帖\学生名单.xlsx") #打开文件并返回一个工作蒲对象。open_workbook可以点进去看看函数里面的参数的含义之类的,很详细,英语不好的可以百度翻译,翻译出来的结果差不多。
sheet=wb.sheet_by_index(0) #通过索引的方式获取到某一个sheet,现在是获取的第一个sheet页,也可以通过sheet的名称进行获取,sheet_by_name('sheet名称')
col1=sheet.col_values(0)# 学号
col2=sheet.col_values(1)# 名字
# col3=sheet.col_values(2)# 班级
num=len(col1)-1 # 第一列去掉第一行
numberall=[]
# 生成 基本组:“学号+名字“
for num in range(1,len(col1)):
for x0 in range(2):
name00=str(int(col1[num])) +' '+str(col2[num]) #学号和名字拼在一起, 1 张三
numberall.append(name00)
for x1 in range(14):
number1=int(col1[num])
numberall.append(number1) # 只要学号
for x2 in range(2):
b=' '
numberall.append(b) # 学号留两个空
# 如果是三个名字,就连着三个名字,如果是2个名字,就连着4个名字
if len(col2[num])==3:
number2=col2[num]+' '+col2[num]+' '+col2[num] #只要名字, 李四光 李四光 李四光
numberall.append(number2)
if len(col2[num])==2:
number2=col2[num]+' '+col2[num]+' '+col2[num] +' '+col2[num] #只要名字, 张三 张三 张三 张三
numberall.append(number2)
# 如果是三个字的名字,写三到空格里,空格1个,
if len(col2[num])==3:
for w1 in range(len(col2[num])):
numberall.append(col2[num][w1]) # 名字留两个空
for x3 in range(1):
b=' '
numberall.append(b) # 名字留两个空
# 如果是2个字的名字,写两个空格,空格2个
if len(col2[num])==2:
for w1 in range(len(col2[num])):
numberall.append(col2[num][w1]) # 名字留两个空
for x3 in range(2):
b=''
numberall.append(b) # 名字留两个空
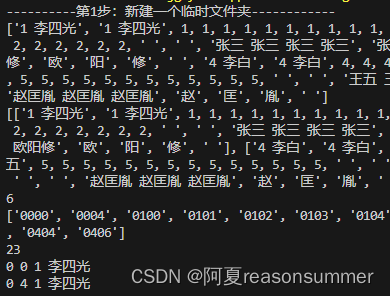
print(numberall)
# 一个数组【】
# 切开25人 一人16个数字
list1=[]
for fk in range(int(len(numberall)/gz)): # 一共26格子
list1.append(numberall[fk*gz:fk*gz+gz])
print(list1)
print(len(list1))
list=[]
for r in range(int(len(list1)/2)):
list.append(list1[r*2:r*2+2])
# print(list)
# print(len(list))
# 25个数组【】
bg=[]
# 第一行的格子
a=['0000','0004']
for z1 in a:
bg.append(z1)
# 第2-3行学号的格子16格子
for x in range(1,3):
for y in range(0,8):
z2='{}{}'.format('%02d'%x,'%02d'%y)
bg.append(z2)
# 第4行学号的格子
a='0300'
bg.append(a)
for x2 in range(4,5):
for y2 in range(0,8,2):
z2='{}{}'.format('%02d'%x2,'%02d'%y2)
bg.append(z2)
print(bg)
print(len(bg))
# ['0000', '0004', '0100', '0101', '0102', '0103', '0104', '0105', '0106', '0107', '0200', '0201', '0202', '0203', '0204', '0205', '0206', '0207', '0300', '0302', '0304', '0306', '0400', '0402', '0404', '0406']
for n in range(int(num/2)):
doc = docx.Document(r"C:\Users\jg2yXRZ\OneDrive\桌面\描字帖\20240117中4班学号描字帖\中4班描字帖.docx")
for b in range(2):
table = doc.tables[b]
# print(p)
for t in range(len(bg)): # 0-gz
# print(list[t])
pp=int(bg[t][0:2]) # 提取表格bg里面每个元素的第0个数字==单元格X坐标 t=索引数字
qq=int(bg[t][2:4])
k=list[n][b][t]
# f=font[t]
print(pp,qq,k)
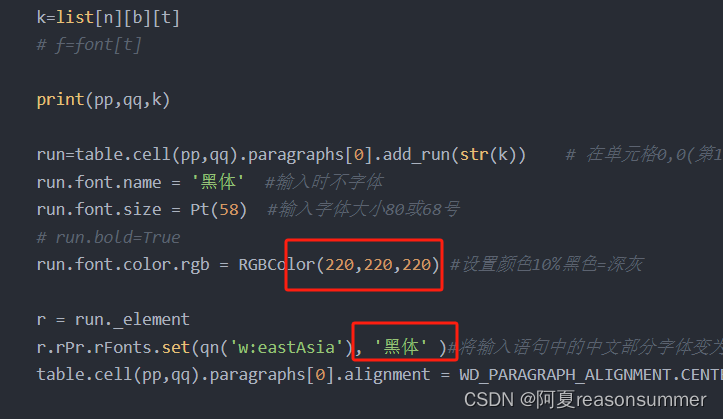
run=table.cell(pp,qq).paragraphs[0].add_run(str(k)) # 在单元格0,0(第1行第1列)输入第0个名字
run.font.name = '黑体' #输入时不字体
run.font.size = Pt(58) #输入字体大小80或68号
# run.bold=True
run.font.color.rgb = RGBColor(220,220,220) #设置颜色10%黑色=深灰
r = run._element
r.rPr.rFonts.set(qn('w:eastAsia'), '黑体' )#将输入语句中的中文部分字体变为华文行楷
table.cell(pp,qq).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中
doc.save(r'C:\Users\jg2yXRZ\OneDrive\桌面\描字帖\零时Word\{}.docx'.format('%02d'%n))#保存为XX学号的零时word
time.sleep(1)
from docx2pdf import convert
# docx 文件另存为PDF文件
inputFile = r"C:\Users\jg2yXRZ\OneDrive\桌面\描字帖\零时Word\{}.docx".format('%02d'%n)# 要转换的文件:已存在
outputFile = r"C:\Users\jg2yXRZ\OneDrive\桌面\描字帖\零时Word\{}.pdf".format('%02d'%n) # 要生成的文件:不存在
# 先创建 不存在的 文件
f1 = open(outputFile,'w')
f1.close()
# 再转换往PDF中写入内容
convert(inputFile, outputFile)
time.sleep(1)
from docx2pdf import convert
print('----------第4步:把都有PDF合并为一个打印用PDF------------')
import os
from PyPDF2 import PdfMerger
target_path = 'C:/Users/jg2yXRZ/OneDrive/桌面/描字帖/零时Word'
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfMerger()
for pdf in pdf_lst:
print(pdf)
file_merger.append(pdf)
# file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/描字帖/(打印合集)大班A整页描字帖2乘5加表格-4名字-({}人).pdf".format(num))
file_merger.write("C:/Users/jg2yXRZ/OneDrive/桌面/描字帖/(打印合集)中4班描字帖练习册({}份).pdf".format(num))
file_merger.close()
# doc.Close()
# # print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree('C:/Users/jg2yXRZ/OneDrive/桌面/描字帖/零时Word') #递归删除文件夹,即:删除非空文件夹`
终端运行:
直接运行,不用输入参数
结果展示
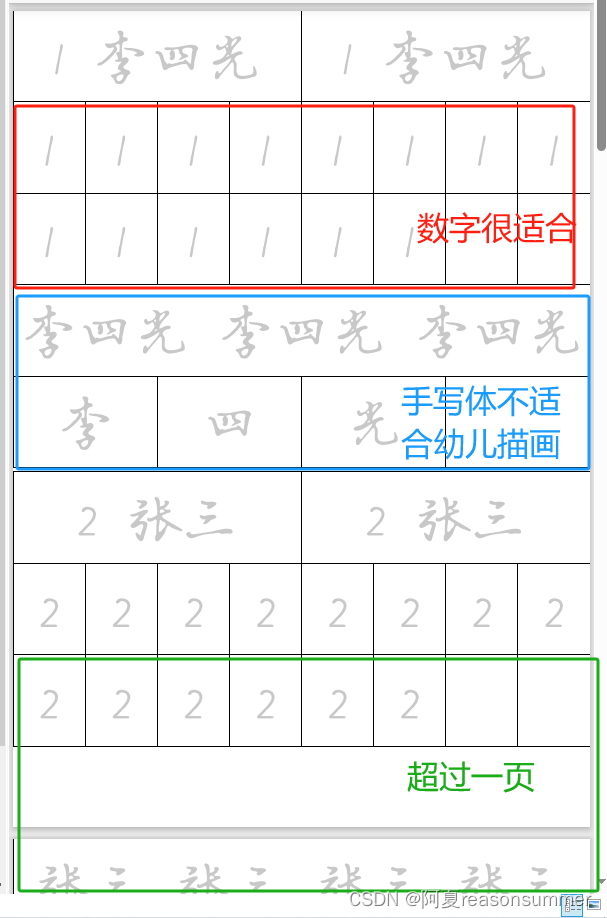
黑体 58号
换字体:德彪钢笔行书字库? 58号字体
换字体 Print Dashed 58号字帖
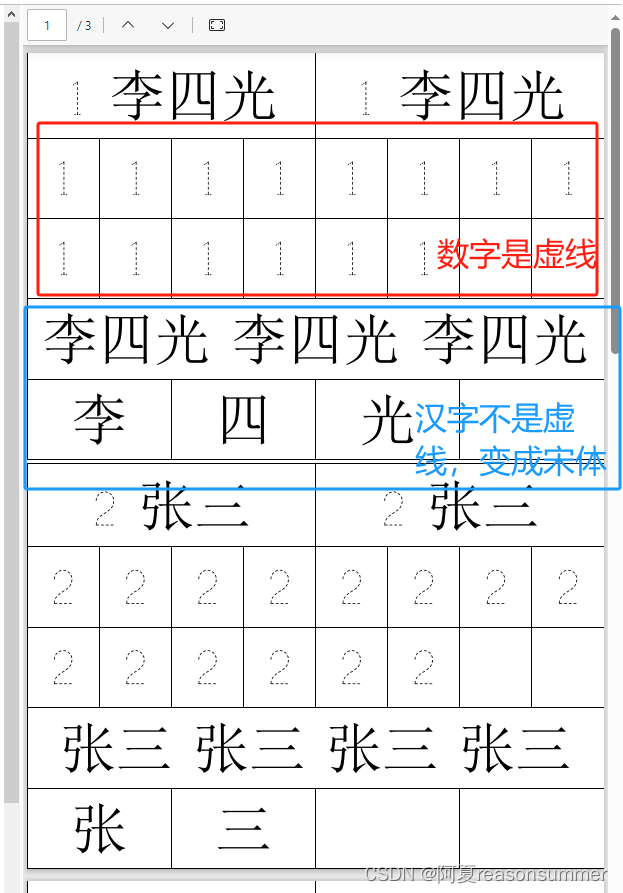
适合的阿拉伯数字字体(德彪字体、print字体)并不兼容汉字字体
感悟:
随着学生数锐减,教师大幅缩编。不再招聘新教师且大幅度并班,在编老师的岗位也有一种岌岌可危的感觉。如今我终于有固定班级了,深感幸运!
与中班孩子们相亲相爱,斗智斗勇的日子又开始了!
材料打印:
打了一张发现200 200 200的灰度还是偏黑色的,所以再次测试了220的灰度,感觉比较适合
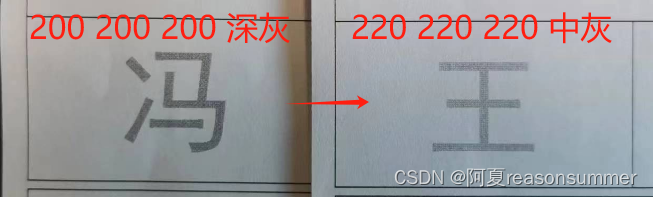
A4整张(一页两份)

切割后,A4半张
 教学实践:
教学实践:
文章来源:https://blog.csdn.net/reasonsummer/article/details/135634647
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 编译android的C版本Lua库
- 2021腾讯、华为前端面试题集(基础篇)
- vue编辑页面提示 this file does not belong to the project
- 【Linux】进程等待
- 无需编程,简单易上手的家具小程序搭建方法分享
- 虚拟机(克隆)导入/导出镜像(VOA&VOF)
- 【Elasticsearch】索引恢复(recovery)流程梳理之副本分片数据恢复
- 算法训练营第四十九天|121. 买卖股票的最佳时机 122.买卖股票的最佳时机II
- 贵金属入门知识有哪些?
- Oracle VirtualBox中Linux系统基本使用方法——备赛笔记——2024全国职业院校技能大赛“大数据应用开发”赛项——任务2:离线数据处理