alertmanager高可用集群的部署方案
目录
alertmanager集群模式如何形成?
GitHub - prometheus/alertmanager: Prometheus Alertmanager
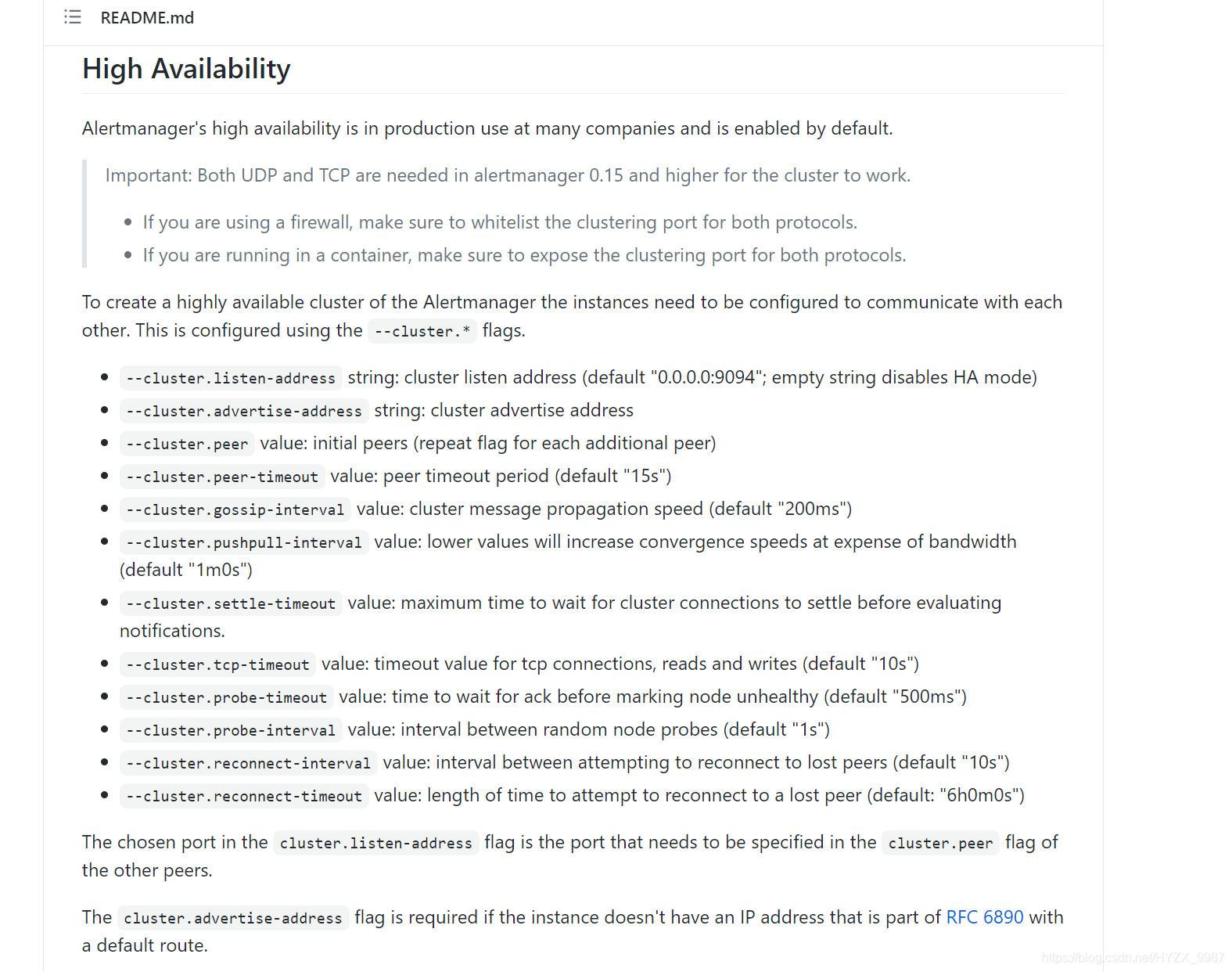
?基本上就是,通过cluster相关的参数进行组织。翻译原话过来就是:要创建 Alertmanager 的高可用性集群,需要将实例配置为相互通信。这是使用--cluster.*标志配置的?。
写的看起来很简单,但实际操作时,一次就完全成功可能远了点,下面直接来看成功案例,不费劲。
先看看prometheus这边怎么配
假设现在后面要做得alertmanager相关的都已经做好,这需要如何关联?
很简单(下图是以docker容器部署时的两个alert实例):
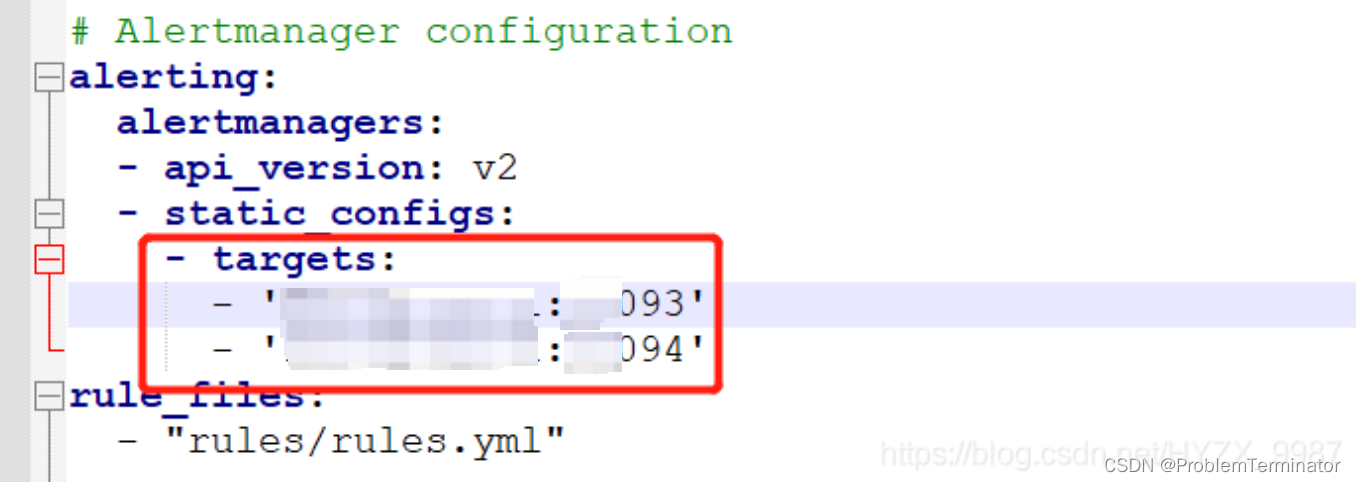
?注意端口别写错了,如果写错,那又是另一桩血案......
非容器部署
以两台机器为例
172.18.6.150上:
./alertmanager --web.listen-address=":9093" --cluster.listen-address="172.18.6.150:8101" --log.level=debug172.18.6.158上:
./alertmanager --web.listen-address=":9093" --cluster.listen-address="172.18.6.158:8101" --cluster.peer=172.18.6.150:8101 ?--log.level=debug这就相当于两个实例构成一个集群,两个之间通信通过各自开放的端口,前者开放8101,后者开放8101,同时后者通过cluster.peer来设置自己通过172.18.6.150:8101加入集群,看看日志:
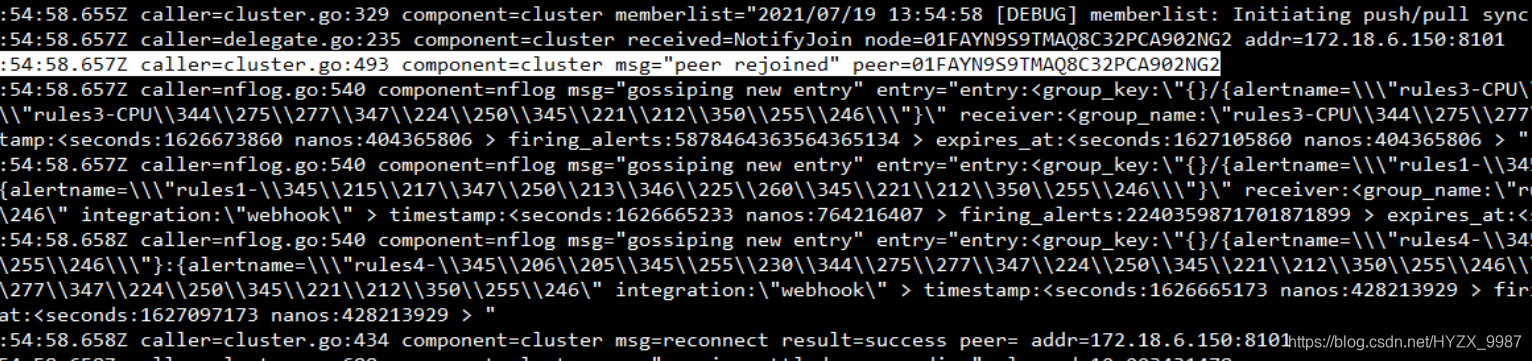
看看页面状态:
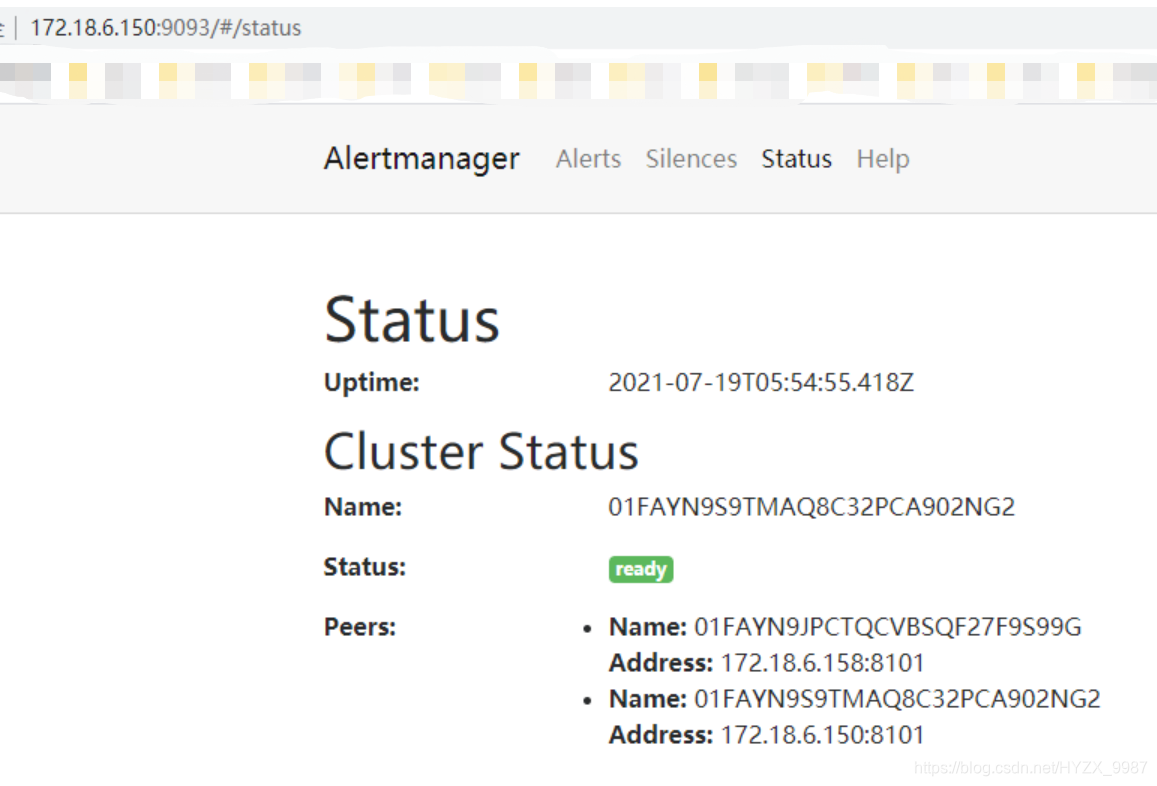
?(重要:如果你的不正常,那么看一下宿主机对对应端口的开放,是两种协议都要开放哦!)
这时候,prometheus的配置则是
- targets:
- '172.18.6.158:9093'
- '172.18.6.150:9093'如果你的prom也是集群模式,则告警这块都这么配就OK。?
没错,这就可以了。那么试想一下,这时候是两个实例,如果配置文件相同,告警发生后是发送一次还是两次?
HA模式下,alertmanager的配置文件配一样的就好,这样在发送告警时可自行判断和协调,最后决定以哪个实例来发送告警信息到用户,发出的告警也不会重复。这是怎样实现的?
-----可移步:GitHub - hashicorp/memberlist: Golang package for gossip based membership and failure detection
总结一下就是:
多个Alertmanager通过gossip协议可以组成一个集群。这时候每个alertmanager的规则可以完全一致,当触发告警时集群内各个节点通过gossip协议相互通信,即进行了发送前先对齐一下的过程,如果有重复的需要发送,则只发送一次。
n台机器组成集群都一样。
基于容器部署
下面你看到的直接是正确姿势,这是历经无数踩坑之后的...
启动第一个:
docker run -d -p 19093:9093 -p 19193:19193 -p 19193:19193/udp --name alert1 --restart always -v /opt/prom_mappings/alert1:/etc/alertmanager jialanli/alertmanager:0.22.2 --config.file=/etc/alertmanager/alertmanager.yml --cluster.listen-address=0.0.0.0:19193 --cluster.advertise-address=192.168.30.31:19193 --log.level=debug --cluster.peer-timeout=40s第二个:
docker run -d -p 19094:9093 -p 19194:19194 -p 19194:19194/udp --name alert2 --restart always -v /opt/prom_mappings/alert2:/etc/alertmanager jialanli/alertmanager:0.22.2 --config.file=/etc/alertmanager/alertmanager.yml --cluster.listen-address=0.0.0.0:19194 --cluster.advertise-address=192.168.30.31:19194 --cluster.peer=192.168.30.31:19193 --log.level=debug --cluster.peer-timeout=40s非常关键的、需要极其注意的地方是?-p x:y/udp?
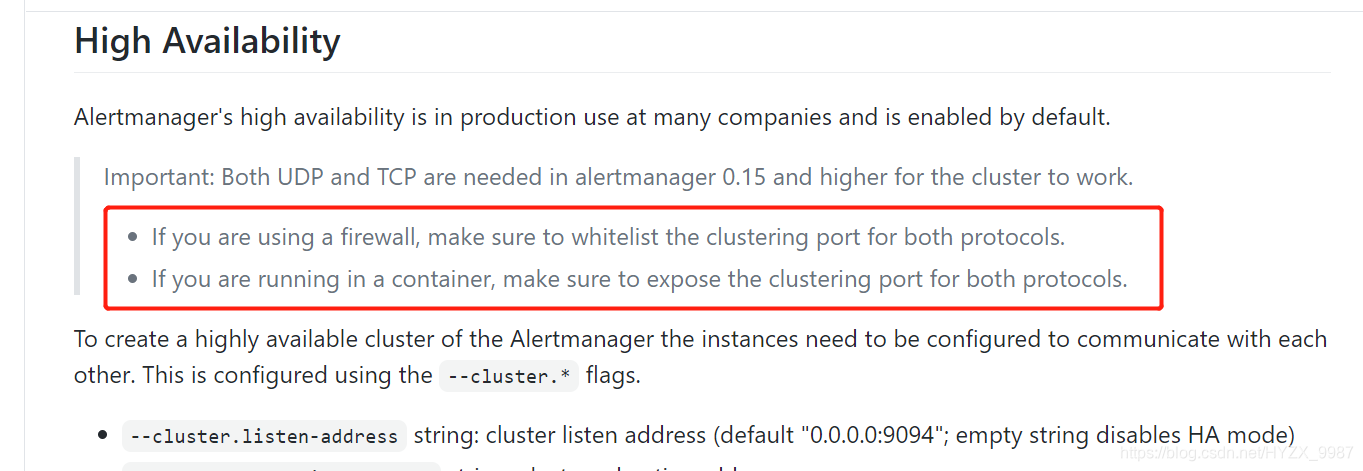
这时候,prom这么配(和非容器下一样):
- targets:
- '192.168.30.31:19093'
- '192.168.30.31:19094'?看看效果
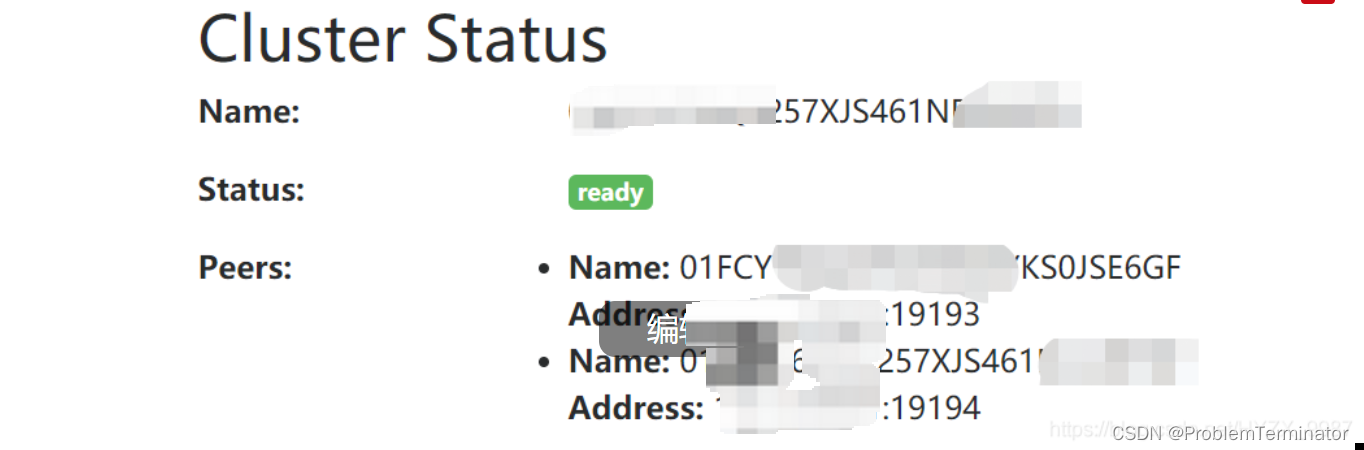
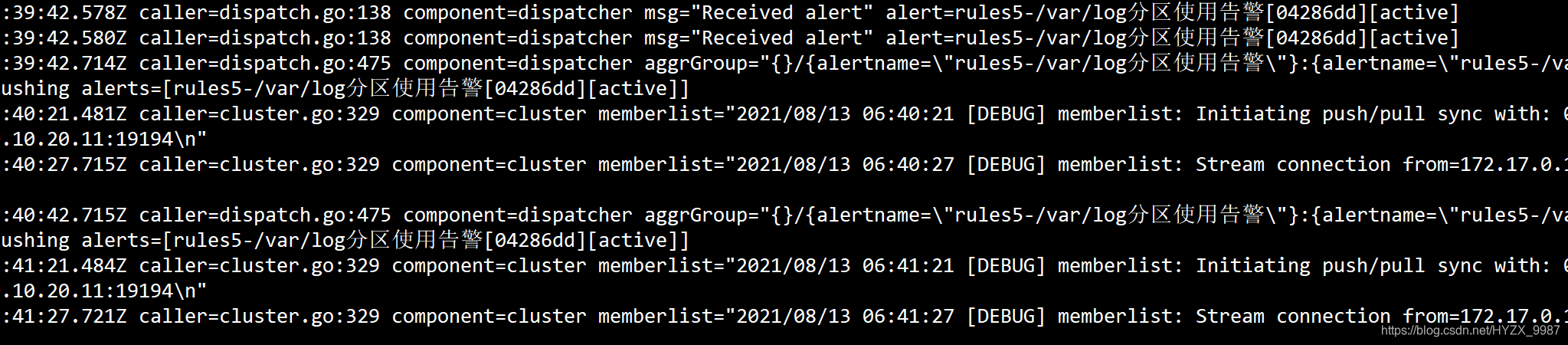
?告警触发且alertmanager收到prometheus发送的告警通知后,如果看到这种日志在交替打印,那么就是正常的:
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 大厂不断裁员,新手程序员要如何应对,才能更好的生存?
- P48类神经网络训练不起来怎么办- BatchNormalization
- nginx匹配规则
- Hibernate实战之操作MySQL数据库(2024-1-8)
- 【工具与中间件】通过飞书应用操作云文档
- SpringCloud 之HttpClient、HttpURLConnection、OkHttpClient切换源码
- hadoop自动获取时间
- 【精选】SpringMVC处理响应及注解开发
- 2022 年全国职业院校技能大赛高职组云计算赛项试卷部分解析
- 单片机11-13