【InternLM 大模型实战】第六课
OpenCompass 大模型评测
关于评测的三个问题
1、为什么需要评测
-
模型选型
大预言模型应用场景多,建立统一的评测标准才能更好的帮助我们去选择对模型进行选型 -
模型能力提升
对于开发者,评测的效果能让他们了解到模型的边界在哪 -
真实应用场景效果评测
2、我们需要测什么
知识、推理、语言
长文本、智能体、多轮对话
情感、认知、价值观
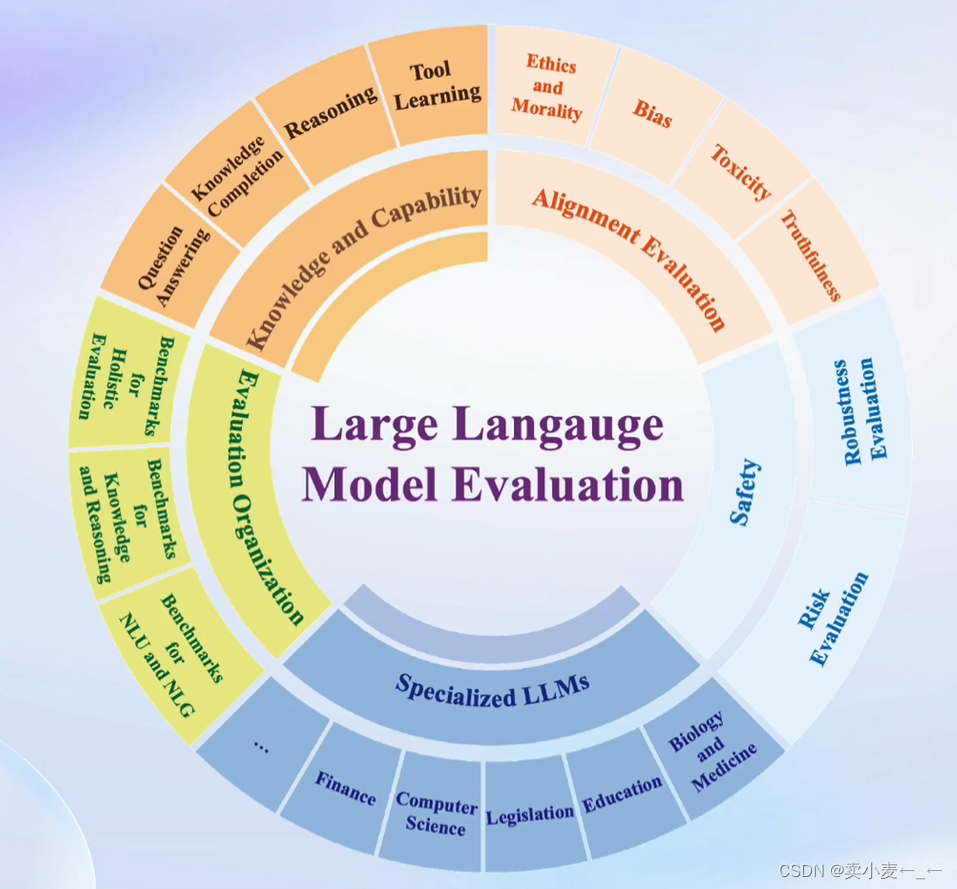
3、怎么测试大预言模型?
自动化客观评测
人机交互评测
基于大模型的大模型评测
例如基座模型评测的时候需要给一个instruct(即给个格式,让大语言模型按照格式回答),对话模型则直接像人一样提问和回答就好了
客观评测:无论模型怎么回答,只要能从回答中提取到我们想要的关键词,那就是正确的
主观评测:对一些主管的问题,如诗歌的谁写的更优,这种评测要做自动化的则需要用模型(如chatgpt)去评测模型
主流大模型评测框架

openCompass 能力框架

有meta官方推荐,唯一由国内开发的大模型评测体系
openCompass 开源评测平台架构
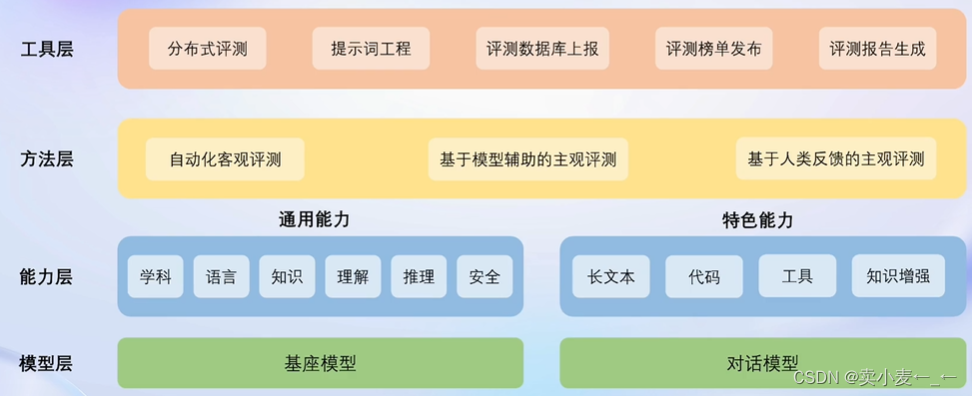
openCompass 评测流水线设计
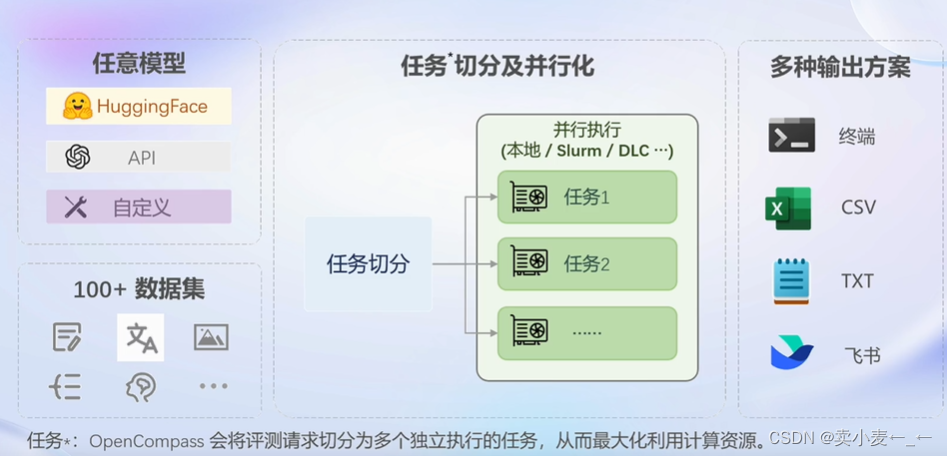
无论是huggingface的开源模型还是chatgpt这种api模型都可以评测
openCompass 前沿探索
多模态-MMBench

垂直领域-法律 LawBench

垂直领域-医疗 MedBench
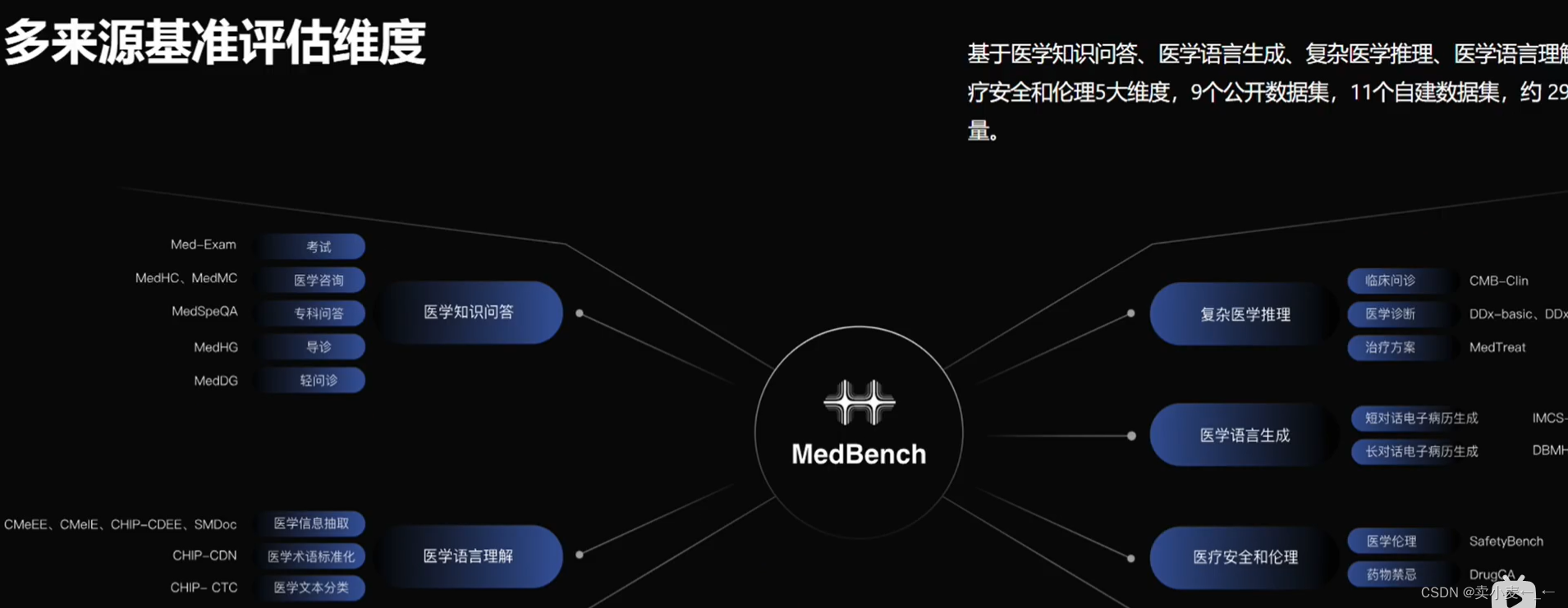
大模型评测里领域的挑战
- 缺少高质量中文评测集
- 难以准确提取答案
- 能力维度不足
- 测试集混入训练集(数据污染,会造成准确率虚高)
- 测试标砖各异
- 人工测试成本高昂
动手实战环节
环境准备
安装并激活conda环境
conda create --name opencompass --clone=/root/share/conda_envs/internlm-base
source activate opencompass
下载openCompass并安装
git clone https://github.com/open-compass/opencompass
cd opencompass
pip install -e .
有部分第三方功能,如代码能力基准测试 Humaneval 以及 Llama格式的模型评测,可能需要额外步骤才能正常运行,如需评测,详细步骤请参考安装指南。
数据准备
# 解压评测数据集到 data/ 处
cp /share/temp/datasets/OpenCompassData-core-20231110.zip /root/opencompass/
unzip OpenCompassData-core-20231110.zip
# 将会在opencompass下看到data文件夹
查看支持的数据集和模型
# 列出所有跟 internlm 及 ceval 相关的配置
python tools/list_configs.py internlm ceval
启动评测
为了方便可以把命令放到一个bash文件里跑
python run.py --datasets ceval_gen --hf-path /share/temp/model_repos/internlm-chat-7b/ --tokenizer-path /share/temp/model_repos/internlm-chat-7b/ --tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True --model-kwargs trust_remote_code=True device_map='auto' --max-seq-len 2048 --max-out-len 16 --batch-size 4 --num-gpus 1 --debug
命令解析
--datasets ceval_gen \
--hf-path /share/temp/model_repos/internlm-chat-7b/ \ # HuggingFace 模型路径
--tokenizer-path /share/temp/model_repos/internlm-chat-7b/ \ # HuggingFace tokenizer 路径(如果与模型路径相同,可以省略)
--tokenizer-kwargs padding_side='left' truncation='left' trust_remote_code=True \ # 构建 tokenizer 的参数
--model-kwargs device_map='auto' trust_remote_code=True \ # 构建模型的参数
--max-seq-len 2048 \ # 模型可以接受的最大序列长度
--max-out-len 16 \ # 生成的最大 token 数(做客观评测的时候都会开得比较少,这样不会堵住,更好的做指令跟随,做主观评测可以设为100)
--batch-size 4 \ # 批量大小
--num-gpus 1 # 运行模型所需的 GPU 数量
--debug
--reuse # 如果有这个参数,则会在评测中断时保留进度,下一次评测再继续装个进度
如果一切正常,您应该看到屏幕上显示 “Starting inference process”:
[2024-01-12 18:23:55,076] [opencompass.openicl.icl_inferencer.icl_gen_inferencer] [INFO] Starting inference process...
主管评测还要多做一步,参考config里面eval_subjective_alignbench.py 设置
除了通过命令行配置实验外,OpenCompass 还允许用户在配置文件中编写实验的完整配置,并通过 run.py 直接运行它。配置文件是以 Python 格式组织的,并且必须包括 datasets 和 models 字段。
示例测试配置在 configs/eval_demo.py 中。此配置通过 继承机制 引入所需的数据集和模型配置,并以所需格式组合 datasets 和 models 字段。
from mmengine.config import read_base
with read_base():
from .datasets.siqa.siqa_gen import siqa_datasets
from .datasets.winograd.winograd_ppl import winograd_datasets
from .models.opt.hf_opt_125m import opt125m
from .models.opt.hf_opt_350m import opt350m
datasets = [*siqa_datasets, *winograd_datasets]
models = [opt125m, opt350m]
运行任务时,我们只需将配置文件的路径传递给 run.py:
python run.py configs/eval_demo.py
OpenCompass 提供了一系列预定义的模型配置,位于 configs/models 下。以下是与 opt-350m(configs/models/opt/hf_opt_350m.py)相关的配置片段:
# 使用 `HuggingFaceCausalLM` 评估由 HuggingFace 的 `AutoModelForCausalLM` 支持的模型
from opencompass.models import HuggingFaceCausalLM
# OPT-350M
opt350m = dict(
type=HuggingFaceCausalLM,
# `HuggingFaceCausalLM` 的初始化参数
path='facebook/opt-350m',
tokenizer_path='facebook/opt-350m',
tokenizer_kwargs=dict(
padding_side='left',
truncation_side='left',
proxies=None,
trust_remote_code=True),
model_kwargs=dict(device_map='auto'),
# 下面是所有模型的共同参数,不特定于 HuggingFaceCausalLM
abbr='opt350m', # 结果显示的模型缩写
max_seq_len=2048, # 整个序列的最大长度
max_out_len=100, # 生成的最大 token 数
batch_size=64, # 批量大小
run_cfg=dict(num_gpus=1), # 该模型所需的 GPU 数量
)
使用配置时,我们可以通过命令行参数 --models 指定相关文件,或使用继承机制将模型配置导入到配置文件中的 models 列表中。
与模型类似,数据集的配置文件也提供在 configs/datasets 下。用户可以在命令行中使用 --datasets,或通过继承在配置文件中导入相关配置
每个数据集都有infer_config和eval_config,eval_config里面要指定evaluator
本次评测是在开发机上,所以runner用localrunner
下面是来自 configs/eval_demo.py 的与数据集相关的配置片段:
from mmengine.config import read_base # 使用 mmengine.read_base() 读取基本配置
with read_base():
# 直接从预设的数据集配置中读取所需的数据集配置
from .datasets.winograd.winograd_ppl import winograd_datasets # 读取 Winograd 配置,基于 PPL(困惑度)进行评估
from .datasets.siqa.siqa_gen import siqa_datasets # 读取 SIQA 配置,基于生成进行评估
datasets = [*siqa_datasets, *winograd_datasets] # 最终的配置需要包含所需的评估数据集列表 'datasets'
数据集配置通常有两种类型:‘ppl’ 和 ‘gen’,分别指示使用的评估方法。其中 ppl 表示辨别性评估,gen 表示生成性评估。
此外,configs/datasets/collections 收录了各种数据集集合,方便进行综合评估。OpenCompass 通常使用 base_medium.py 进行全面的模型测试。要复制结果,只需导入该文件,例如:
python run.py --models hf_llama_7b --datasets base_medium
可视化评估结果
评估完成后,评估结果表格将打印如下:
dataset version metric mode opt350m opt125m
--------- --------- -------- ------ --------- ---------
siqa e78df3 accuracy gen 21.55 12.44
winograd b6c7ed accuracy ppl 51.23 49.82
所有运行输出将定向到 outputs/demo/ 目录,结构如下:
outputs/default/
├── 20200220_120000
├── 20230220_183030 # 每个实验一个文件夹
│ ├── configs # 用于记录的已转储的配置文件。如果在同一个实验文件夹中重新运行了不同的实验,可能会保留多个配置
│ ├── logs # 推理和评估阶段的日志文件
│ │ ├── eval
│ │ └── infer
│ ├── predictions # 每个任务的推理结果
│ ├── results # 每个任务的评估结果
│ └── summary # 单个实验的汇总评估结果
├── ...
打印评测结果的过程可被进一步定制化,用于输出一些数据集的平均分 (例如 MMLU, C-Eval 等)。
更多教程
想要更多了解 OpenCompass, 可以点击下列链接学习。
- https://opencompass.readthedocs.io/zh-cn/latest/
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!