数据采集与预处理01: 项目1 数据采集与预处理准备
数据采集与预处理01: 项目1 数据采集与预处理准备

任务1 认识数据采集技术,熟悉数据采集平台
数据采集:足够的数据量是企业大数据战略建设的基础,因此数据采集成为大数据分析的前站。数据采集是大数据价值挖掘中重要的一环,其后的分析挖掘都建立在数据采集的基础上。大数据技术的意义确实不在于掌握规模庞大的数据信息,而在于对这些数据进行智能处理,从而分析和挖掘出有价值的信息,但前提是拥有大量的数据。
数据采集过程中涉及3个过程:数据的抽取Extract,数据的清洗转换Transform和数据的加载Load。英文缩写为ETL。
数据采集的来源:管理信息系统、Web信息系统、物理信息系统、科学实验系统。
数据采集的方法:
? 数据采集的新方法有系统日志采集方法、网络数据采集方法等
? 另外有网页数据采集的方法。
数据采集的过程基本步骤如下:
- 将需要抓取的数据网站的URL信息写入URL队列。
- 爬虫从URL队列中获取需要抓取数据网站的URL信息。
- 获取某个具体网站的网页内容。
- 从网页内容中抽取出该该网站正文页内容的链接地址。
- 从数据库中读取已经抓取国内容的网页地址。
- 过滤URL。对当前的URL和已经抓去过的URL进行比较。
- 如果该网页地址没被抓去过,则将该地址写入数据库。如果该地址已经被抓取过,则放弃对这个地址的抓取操作。
- 获取该地址的网页内容,并抽取出所需属性的内容值。
- 将抽取的网页内容写入数据库。
任务实施
- Scrapy系统环境搭建
Scrapy是Python开发的一个快速、高层次的屏幕抓取和Web抓取框架。支持多种类型的爬虫基类。
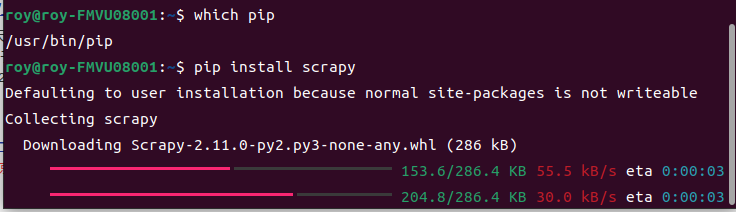
sudo apt-get install python-pip
pip install --upgrade pip
pip install scrapy

日志系统环境的搭建
- 安装Flume
Flume是Cloudera提供的一个高可用的、高可靠的、分布式的海量日志采集、聚合和传输系统,支持在日志系统中定制各种数据发送方,用于收集数据。同时,Flume具有对数据进行简单处理,并写到各种数据接收方的能力。
Flume需要JDK环境,使用 java -version 命令查看系统是否配置了JDK环境

没有的话则需要下载安装。
接着下载flume。
https://flume.apache.org/
在官网下载。
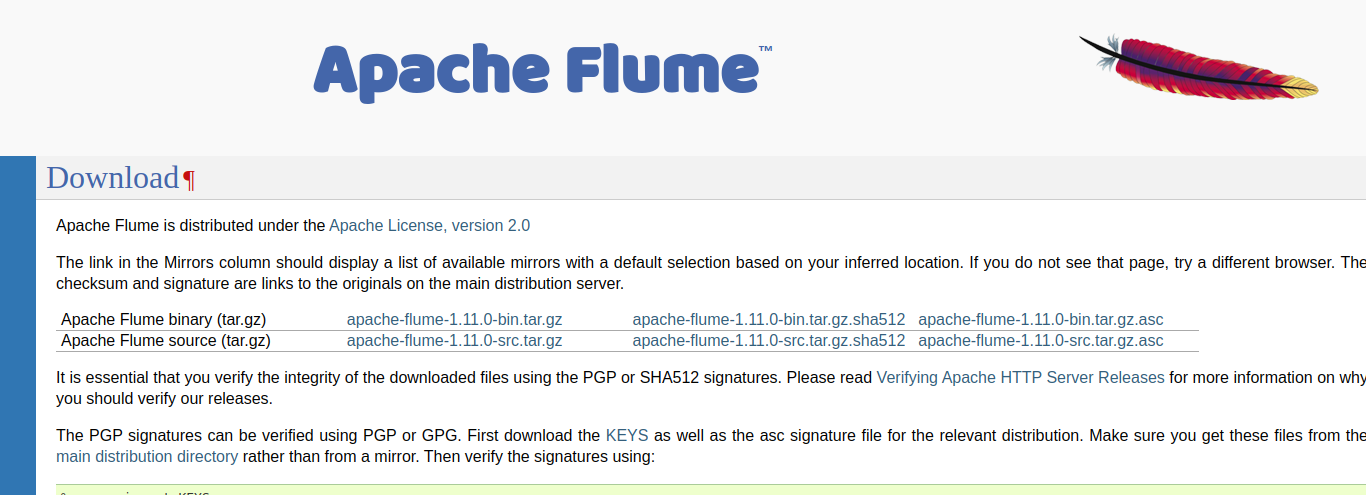
然后执行解压与安装
cd 下载
sudo tar -zxvf apache-flume-1.11.0-bin.tar.gz -C /usr/local
cd usr/local
sudo chown 777 apache-flume-1.11.0-bin
sudo mv apache-flume-1.11.0-bin flume
- 配置环境变量
执行sudo gedit /etc/profile 命令
export FLUME_HOME=/usr/local/flume
export FLUME_CONF_DIR=$FLUME_HOME/conf
export PATH=$java_home/bin:$PATH:$FLUME_HOME/bin
使用source /etc/profile使其生效。
另外还要修改配置文件什么的,非常繁琐。
https://blog.csdn.net/qq_43452181/article/details/109187373
给个参考。
检测成果。
cd /usr/local/flume
./bin/flume-ng version
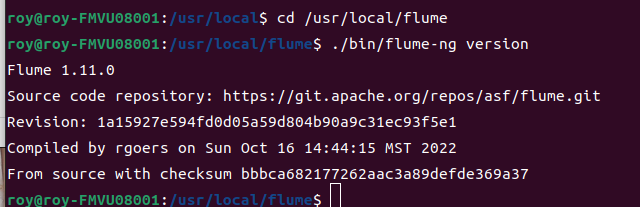
这样就行。
任务2 认识数据预处理技术
数据预处理是指在对数据进行数据挖掘的主要处理以前,先对原始数据进行必要的清理、集成、转换、离散、归约、特征选择和提取等一系列处理工作,达到挖掘算法进行知识获取、研究所要求的最低规范和标准。
数据预处理的常见问题:
- 数据采样 分为加权采样、随机采样和分层采样3类,其目的是从数据集中采集部分样本进行处理。
- 数据清理 ,清理技术通常包括填补遗漏的数据值、平滑有噪声数据、识别或者除去异常值。
? 2.1 数据填充:包括人工填写、特殊值填充、平均值填充、热卡填充(就近填充)、k近邻填充。
? 2.2 平滑噪声;分箱、回归、聚类
? 2.3 数据集成: 实体识别、冗余和相关分析、元组重复、数据值冲突的检测与处理、数据转换、数据归约、特征选择和特征提取。
任务实施
搭建pig系统。
https://blog.csdn.net/m0_52595361/article/details/127930651
搭建kettle系统。
https://blog.csdn.net/lcy1619260/article/details/132540385
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C语言思维导图
- Fastbee物联网项目新手快速入门
- Double 4 VR智能互动系统模拟陪同口译实训教学场景
- 基于Java版本与鸿鹄企业电子招投标系统的二次开发实践-鸿鹄企业电子招投标系统源代码+支持二开+鸿鹄电子招投标系统
- 石油化工行业常用PFA镊子本底低无溶出析出防污染样品
- vue2和vue3生命四种周期函数的比较(详细讲解)
- JavaScript的Map、Set、WeakMap 、WeakSet
- 金融信贷场景的风险“要素”与主要“风险点”
- python 二分查找算法实现对递增序列进行数据定位
- C语言 二叉树详解(自我理解版)!!!二叉树的实现