工具系列:TensorFlow决策森林_(10)构建Uplifting Model
文章目录
欢迎来到TensorFlow决策森林(TF-DF)的 Uplifting Model教程。在本教程中,您将学习什么是令Uplifting Model,为什么它如此重要,以及如何在TF-DF中实现它。
在这本文中,您将:
- 了解什么是Uplifting Model。
- 在Hillstrom电子邮件营销数据集上训练一个令人振奋的随机森林模型。
- 评估该模型的质量。
安装 TensorFlow Decision Forests
通过运行以下单元格来安装 TF-DF。
在显示详细的训练日志(当在模型构造函数中使用 verbose=2 时),需要使用 Wurlitzer。
# 安装tensorflow_decision_forests和wurlitzer库
!pip install tensorflow_decision_forests wurlitzer
Collecting tensorflow_decision_forests
Obtaining dependency information for tensorflow_decision_forests from https://files.pythonhosted.org/packages/86/70/fa05c33db4bd9e7c4d4285a628f1127fd2d5a6aa5a3b324865f38f985bb1/tensorflow_decision_forests-1.6.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata
Using cached tensorflow_decision_forests-1.6.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.metadata (6.0 kB)
Collecting wurlitzer
Using cached wurlitzer-3.0.3-py3-none-any.whl (7.3 kB)
Requirement already satisfied: numpy in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow_decision_forests) (1.26.0)
Requirement already satisfied: pandas in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow_decision_forests) (2.1.1)
Requirement already satisfied: tensorflow~=2.14.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow_decision_forests) (2.14.0)
Requirement already satisfied: six in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow_decision_forests) (1.16.0)
Requirement already satisfied: absl-py in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow_decision_forests) (1.4.0)
Requirement already satisfied: wheel in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow_decision_forests) (0.41.2)
Requirement already satisfied: astunparse>=1.6.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.14.0->tensorflow_decision_forests) (1.6.3)
Requirement already satisfied: flatbuffers>=23.5.26 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.14.0->tensorflow_decision_forests) (23.5.26)
Requirement already satisfied: gast!=0.5.0,!=0.5.1,!=0.5.2,>=0.2.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.14.0->tensorflow_decision_forests) (0.5.4)
Requirement already satisfied: google-pasta>=0.1.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.14.0->tensorflow_decision_forests) (0.2.0)
Requirement already satisfied: h5py>=2.9.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.14.0->tensorflow_decision_forests) (3.9.0)
Requirement already satisfied: libclang>=13.0.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.14.0->tensorflow_decision_forests) (16.0.6)
Requirement already satisfied: ml-dtypes==0.2.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.14.0->tensorflow_decision_forests) (0.2.0)
Requirement already satisfied: opt-einsum>=2.3.2 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.14.0->tensorflow_decision_forests) (3.3.0)
Requirement already satisfied: packaging in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.14.0->tensorflow_decision_forests) (23.2)
Requirement already satisfied: protobuf!=4.21.0,!=4.21.1,!=4.21.2,!=4.21.3,!=4.21.4,!=4.21.5,<5.0.0dev,>=3.20.3 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.14.0->tensorflow_decision_forests) (3.20.3)
Requirement already satisfied: setuptools in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.14.0->tensorflow_decision_forests) (68.2.2)
Requirement already satisfied: termcolor>=1.1.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.14.0->tensorflow_decision_forests) (2.3.0)
Requirement already satisfied: typing-extensions>=3.6.6 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.14.0->tensorflow_decision_forests) (4.8.0)
Requirement already satisfied: wrapt<1.15,>=1.11.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.14.0->tensorflow_decision_forests) (1.14.1)
Requirement already satisfied: tensorflow-io-gcs-filesystem>=0.23.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.14.0->tensorflow_decision_forests) (0.34.0)
Requirement already satisfied: grpcio<2.0,>=1.24.3 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.14.0->tensorflow_decision_forests) (1.59.0)
Requirement already satisfied: tensorboard<2.15,>=2.14 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.14.0->tensorflow_decision_forests) (2.14.1)
Requirement already satisfied: tensorflow-estimator<2.15,>=2.14.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.14.0->tensorflow_decision_forests) (2.14.0)
Requirement already satisfied: keras<2.15,>=2.14.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorflow~=2.14.0->tensorflow_decision_forests) (2.14.0)
Requirement already satisfied: python-dateutil>=2.8.2 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from pandas->tensorflow_decision_forests) (2.8.2)
Requirement already satisfied: pytz>=2020.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from pandas->tensorflow_decision_forests) (2023.3.post1)
Requirement already satisfied: tzdata>=2022.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from pandas->tensorflow_decision_forests) (2023.3)
Requirement already satisfied: google-auth<3,>=1.6.3 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorboard<2.15,>=2.14->tensorflow~=2.14.0->tensorflow_decision_forests) (2.23.2)
Requirement already satisfied: google-auth-oauthlib<1.1,>=0.5 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorboard<2.15,>=2.14->tensorflow~=2.14.0->tensorflow_decision_forests) (1.0.0)
Requirement already satisfied: markdown>=2.6.8 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorboard<2.15,>=2.14->tensorflow~=2.14.0->tensorflow_decision_forests) (3.4.4)
Requirement already satisfied: requests<3,>=2.21.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorboard<2.15,>=2.14->tensorflow~=2.14.0->tensorflow_decision_forests) (2.31.0)
Requirement already satisfied: tensorboard-data-server<0.8.0,>=0.7.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorboard<2.15,>=2.14->tensorflow~=2.14.0->tensorflow_decision_forests) (0.7.1)
Requirement already satisfied: werkzeug>=1.0.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from tensorboard<2.15,>=2.14->tensorflow~=2.14.0->tensorflow_decision_forests) (3.0.0)
Requirement already satisfied: cachetools<6.0,>=2.0.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from google-auth<3,>=1.6.3->tensorboard<2.15,>=2.14->tensorflow~=2.14.0->tensorflow_decision_forests) (5.3.1)
Requirement already satisfied: pyasn1-modules>=0.2.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from google-auth<3,>=1.6.3->tensorboard<2.15,>=2.14->tensorflow~=2.14.0->tensorflow_decision_forests) (0.3.0)
Requirement already satisfied: rsa<5,>=3.1.4 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from google-auth<3,>=1.6.3->tensorboard<2.15,>=2.14->tensorflow~=2.14.0->tensorflow_decision_forests) (4.9)
Requirement already satisfied: requests-oauthlib>=0.7.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from google-auth-oauthlib<1.1,>=0.5->tensorboard<2.15,>=2.14->tensorflow~=2.14.0->tensorflow_decision_forests) (1.3.1)
Requirement already satisfied: importlib-metadata>=4.4 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from markdown>=2.6.8->tensorboard<2.15,>=2.14->tensorflow~=2.14.0->tensorflow_decision_forests) (6.8.0)
Requirement already satisfied: charset-normalizer<4,>=2 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from requests<3,>=2.21.0->tensorboard<2.15,>=2.14->tensorflow~=2.14.0->tensorflow_decision_forests) (3.3.0)
Requirement already satisfied: idna<4,>=2.5 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from requests<3,>=2.21.0->tensorboard<2.15,>=2.14->tensorflow~=2.14.0->tensorflow_decision_forests) (3.4)
Requirement already satisfied: urllib3<3,>=1.21.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from requests<3,>=2.21.0->tensorboard<2.15,>=2.14->tensorflow~=2.14.0->tensorflow_decision_forests) (2.0.6)
Requirement already satisfied: certifi>=2017.4.17 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from requests<3,>=2.21.0->tensorboard<2.15,>=2.14->tensorflow~=2.14.0->tensorflow_decision_forests) (2023.7.22)
Requirement already satisfied: MarkupSafe>=2.1.1 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from werkzeug>=1.0.1->tensorboard<2.15,>=2.14->tensorflow~=2.14.0->tensorflow_decision_forests) (2.1.3)
Requirement already satisfied: zipp>=0.5 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from importlib-metadata>=4.4->markdown>=2.6.8->tensorboard<2.15,>=2.14->tensorflow~=2.14.0->tensorflow_decision_forests) (3.17.0)
Requirement already satisfied: pyasn1<0.6.0,>=0.4.6 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from pyasn1-modules>=0.2.1->google-auth<3,>=1.6.3->tensorboard<2.15,>=2.14->tensorflow~=2.14.0->tensorflow_decision_forests) (0.5.0)
Requirement already satisfied: oauthlib>=3.0.0 in /tmpfs/src/tf_docs_env/lib/python3.9/site-packages (from requests-oauthlib>=0.7.0->google-auth-oauthlib<1.1,>=0.5->tensorboard<2.15,>=2.14->tensorflow~=2.14.0->tensorflow_decision_forests) (3.2.2)
Using cached tensorflow_decision_forests-1.6.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (16.8 MB)
Installing collected packages: wurlitzer, tensorflow_decision_forests
Successfully installed tensorflow_decision_forests-1.6.0 wurlitzer-3.0.3
导入库
# 导入tensorflow_decision_forests库
import tensorflow_decision_forests as tfdf
# 导入os库
import os
# 导入numpy库
import numpy as np
# 导入pandas库
import pandas as pd
# 导入tensorflow库
import tensorflow as tf
# 导入math库
import math
# 导入matplotlib.pyplot库
import matplotlib.pyplot as plt
2023-10-03 11:11:04.771348: E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:9342] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2023-10-03 11:11:04.771393: E tensorflow/compiler/xla/stream_executor/cuda/cuda_fft.cc:609] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2023-10-03 11:11:04.771442: E tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:1518] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
隐藏的代码单元格会限制Colab中的输出高度。
#@title
# 导入所需的模块
from IPython.core.magic import register_line_magic
from IPython.display import Javascript
from IPython.display import display as ipy_display
# 定义一个魔术命令,用于设置单元格的最大高度
@register_line_magic
def set_cell_height(size):
# 调用Javascript代码,设置单元格的最大高度
ipy_display(
Javascript("google.colab.output.setIframeHeight(0, true, {maxHeight: " +
str(size) + "})"))
# 检查 TensorFlow Decision Forests 的版本
print("Found TensorFlow Decision Forests v" + tfdf.__version__)
Found TensorFlow Decision Forests v1.6.0
什么是Uplift Modelling?
Uplift modeling是一种统计建模技术,用于预测对主体的行动的增量影响。该行动通常被称为可能或可能不会应用的处理。
Uplift modeling经常用于有针对性的营销活动中,以预测一个人在接收到营销宣传后进行购买(或任何其他期望的行动)的可能性增加。
例如,Uplift modeling可以预测电子邮件的效果。效果被定义为条件概率
\begin{align}
\text{effect}(\text{email}) = &\Pr(\text{outcome}=\text{purchase}\ \vert\ \text{treatment}=\text{with email})\ &- \Pr(\text{outcome}=\text{purchase} \ \vert\ \text{treatment}=\text{no email}),
\end{align}
其中
Pr
?
(
outcome
=
purchase?
∣
?
.
.
.
)
\Pr(\text{outcome}=\text{purchase}\ \vert\ ...)
Pr(outcome=purchase?∣?...)
是根据接收或不接收电子邮件而购买的概率。
将此与分类模型进行比较:使用分类模型,可以预测购买的概率。然而,具有高概率的客户可能会在商店里花钱,无论他们是否收到电子邮件。
类似地,可以使用数值提升来预测接收电子邮件时的数值花费增加。相比之下,回归模型只能增加预期花费,这在许多情况下是一个不太有用的指标。
在TF-DF中定义提升模型
TF-DF期望以“扁平”格式呈现提升数据集。
一个客户数据集可能如下所示
| 处理 | 结果 | 特征_1 | 特征_2 |
|---|---|---|---|
| 0 | 1 | 0.1 | 蓝色 |
| 0 | 0 | 0.2 | 蓝色 |
| 1 | 1 | 0.3 | 蓝色 |
| 1 | 1 | 0.4 | 蓝色 |
处理是一个二进制变量,指示示例是否接受了处理。在上面的示例中,处理指示客户是否收到了电子邮件。结果(标签)指示示例在接收处理(或未接收处理)后的状态。TF-DF支持分类提升的分类结果和数值提升的数值结果。
注意:提升在医学背景中也经常使用。这里的处理可以是医疗处理(例如接种疫苗),标签可以是生活质量的指标(例如患者是否生病)。这也解释了Uplift modeling的命名方式。
训练一个uplifting model
在这个例子中,我们将使用Hillstrom电子邮件营销数据集。
该数据集包含了64000名在过去十二个月内最后一次购买的顾客。这些顾客参与了一项电子邮件测试:
- 1/3的顾客被随机选择接收到一封以男士商品为特色的电子邮件广告。
- 1/3的顾客被随机选择接收到一封以女士商品为特色的电子邮件广告。
- 1/3的顾客被随机选择不接收任何电子邮件广告。
在电子邮件广告活动结束后的两周内,结果被跟踪记录。任务是判断男士或女士的电子邮件广告活动是否成功。
在数据集文档中了解更多关于数据集的信息。本教程使用由TensorFlow Datasets精选的数据集。
# 安装 TensorFlow Datasets 包
!pip install tensorflow-datasets -U --quiet
# 导入所需的库
import tensorflow_datasets as tfds
# 加载数据集
raw_train, raw_test = tfds.load('hillstrom', split=['train[:80%]', 'train[20%:]'])
# 显示测试集中的前10个样本
test_data = list(raw_test.batch(10).take(1)) # 获取测试集中的前10个样本
df = pd.DataFrame(test_data[0]) # 将样本转换为DataFrame格式
df
2023-10-03 11:11:10.733549: W tensorflow/core/common_runtime/gpu/gpu_device.cc:2211] Cannot dlopen some GPU libraries. Please make sure the missing libraries mentioned above are installed properly if you would like to use GPU. Follow the guide at https://www.tensorflow.org/install/gpu for how to download and setup the required libraries for your platform.
Skipping registering GPU devices...
2023-10-03 11:11:11.372447: W tensorflow/core/kernels/data/cache_dataset_ops.cc:854] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
| channel | conversion | history | history_segment | mens | newbie | recency | segment | spend | visit | womens | zip_code | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | b'Web' | 0 | 29.990000 | b'1) $0 - $100' | 1 | 0 | 6 | b'Womens E-Mail' | 0.0 | 0 | 0 | b'Surburban' |
| 1 | b'Web' | 0 | 150.380005 | b'2) $100 - $200' | 0 | 1 | 9 | b'Womens E-Mail' | 0.0 | 0 | 1 | b'Surburban' |
| 2 | b'Phone' | 0 | 602.960022 | b'5) $500 - $750' | 1 | 1 | 4 | b'Womens E-Mail' | 0.0 | 0 | 0 | b'Surburban' |
| 3 | b'Multichannel' | 0 | 341.010010 | b'3) $200 - $350' | 0 | 0 | 9 | b'Womens E-Mail' | 0.0 | 1 | 1 | b'Urban' |
| 4 | b'Phone' | 0 | 97.180000 | b'1) $0 - $100' | 0 | 1 | 3 | b'Womens E-Mail' | 0.0 | 1 | 1 | b'Surburban' |
| 5 | b'Web' | 0 | 83.269997 | b'1) $0 - $100' | 1 | 0 | 5 | b'Mens E-Mail' | 0.0 | 0 | 0 | b'Urban' |
| 6 | b'Web' | 0 | 331.170013 | b'3) $200 - $350' | 1 | 0 | 8 | b'Womens E-Mail' | 0.0 | 0 | 0 | b'Surburban' |
| 7 | b'Multichannel' | 0 | 628.400024 | b'5) $500 - $750' | 1 | 1 | 9 | b'No E-Mail' | 0.0 | 1 | 0 | b'Surburban' |
| 8 | b'Phone' | 0 | 134.610001 | b'2) $100 - $200' | 1 | 0 | 6 | b'No E-Mail' | 0.0 | 1 | 0 | b'Rural' |
| 9 | b'Web' | 0 | 141.210007 | b'2) $100 - $200' | 0 | 1 | 9 | b'Mens E-Mail' | 0.0 | 1 | 1 | b'Surburban' |
数据集预处理
由于TF-DF目前只支持二进制处理,将"Men’s Email"和"Women’s Email"活动合并。本教程使用二进制变量conversion作为结果。这意味着问题是一个分类提升问题。如果我们使用数值变量spend,问题将成为一个数值提升问题。
# 定义函数prepare_dataset,用于准备数据集
# 参数example为输入的样本数据
def prepare_dataset(example):
# 使用二进制的treatment类别
# 如果segment为'Mens E-Mail'或'Womens E-Mail',则treatment为1,否则为0
example['treatment'] = 1 if example['segment'] == b'Mens E-Mail' or example['segment'] == b'Womens E-Mail' else 0
# 将outcome赋值为example中的conversion值
outcome = example['conversion']
# 限制数据集的输入特征为'channel', 'history', 'mens', 'womens', 'newbie', 'recency', 'zip_code', 'treatment'
input_features = ['channel', 'history', 'mens', 'womens', 'newbie', 'recency', 'zip_code', 'treatment']
# 创建一个新的example字典,只包含input_features中的特征,并将对应的值从原始example中复制过来
example = {feature: example[feature] for feature in input_features}
# 返回处理后的example和outcome
return example, outcome
# 将raw_train数据集映射到prepare_dataset函数,并按照batch size为100进行分批处理
train_ds = raw_train.map(prepare_dataset).batch(100)
# 将raw_test数据集映射到prepare_dataset函数,并按照batch size为100进行分批处理
test_ds = raw_test.map(prepare_dataset).batch(100)
模型训练
最后,按照通常的方式训练和评估模型。请注意,TF-DF仅支持随机森林模型进行提升。
# 设置单元格高度为300
# 配置模型及其超参数。
model = tfdf.keras.RandomForestModel(
verbose=2, # 设置训练过程中的输出详细程度为2,即显示每个epoch的进度和性能指标。
task=tfdf.keras.Task.CATEGORICAL_UPLIFT, # 设置模型任务为分类的提升(uplift)任务。
uplift_treatment='treatment' # 设置提升任务的处理变量为'treatment'。
)
# 训练模型。
model.fit(train_ds) # 使用训练数据集进行模型训练。
<IPython.core.display.Javascript object>
Warning: The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
WARNING:absl:The `num_threads` constructor argument is not set and the number of CPU is os.cpu_count()=32 > 32. Setting num_threads to 32. Set num_threads manually to use more than 32 cpus.
Use /tmpfs/tmp/tmpkvr89ot3 as temporary training directory
Reading training dataset...
Training tensor examples:
Features: {'channel': <tf.Tensor 'data:0' shape=(None,) dtype=string>, 'history': <tf.Tensor 'data_1:0' shape=(None,) dtype=float32>, 'mens': <tf.Tensor 'data_2:0' shape=(None,) dtype=int64>, 'womens': <tf.Tensor 'data_3:0' shape=(None,) dtype=int64>, 'newbie': <tf.Tensor 'data_4:0' shape=(None,) dtype=int64>, 'recency': <tf.Tensor 'data_5:0' shape=(None,) dtype=int64>, 'zip_code': <tf.Tensor 'data_6:0' shape=(None,) dtype=string>, 'treatment': <tf.Tensor 'data_7:0' shape=(None,) dtype=int32>}
Label: Tensor("data_8:0", shape=(None,), dtype=int64)
Weights: None
Normalized tensor features:
{'channel': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data:0' shape=(None,) dtype=string>), 'history': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'data_1:0' shape=(None,) dtype=float32>), 'mens': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast:0' shape=(None,) dtype=float32>), 'womens': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_1:0' shape=(None,) dtype=float32>), 'newbie': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_2:0' shape=(None,) dtype=float32>), 'recency': SemanticTensor(semantic=<Semantic.NUMERICAL: 1>, tensor=<tf.Tensor 'Cast_3:0' shape=(None,) dtype=float32>), 'zip_code': SemanticTensor(semantic=<Semantic.CATEGORICAL: 2>, tensor=<tf.Tensor 'data_6:0' shape=(None,) dtype=string>)}
Training dataset read in 0:00:04.719923. Found 51200 examples.
Training model...
Standard output detected as not visible to the user e.g. running in a notebook. Creating a training log redirection. If training gets stuck, try calling tfdf.keras.set_training_logs_redirection(False).
[INFO 23-10-03 11:11:16.2703 UTC kernel.cc:773] Start Yggdrasil model training
[INFO 23-10-03 11:11:16.2703 UTC kernel.cc:774] Collect training examples
[INFO 23-10-03 11:11:16.2703 UTC kernel.cc:787] Dataspec guide:
column_guides {
column_name_pattern: "^__LABEL$"
type: CATEGORICAL
}
default_column_guide {
categorial {
max_vocab_count: 2000
}
discretized_numerical {
maximum_num_bins: 255
}
}
ignore_columns_without_guides: false
detect_numerical_as_discretized_numerical: false
[INFO 23-10-03 11:11:16.2707 UTC kernel.cc:393] Number of batches: 512
[INFO 23-10-03 11:11:16.2707 UTC kernel.cc:394] Number of examples: 51200
[INFO 23-10-03 11:11:16.2800 UTC kernel.cc:794] Training dataset:
Number of records: 51200
Number of columns: 9
Number of columns by type:
NUMERICAL: 5 (55.5556%)
CATEGORICAL: 4 (44.4444%)
Columns:
NUMERICAL: 5 (55.5556%)
2: "history" NUMERICAL mean:241.833 min:29.99 max:3345.93 sd:255.292
3: "mens" NUMERICAL mean:0.550391 min:0 max:1 sd:0.497454
4: "newbie" NUMERICAL mean:0.503086 min:0 max:1 sd:0.49999
5: "recency" NUMERICAL mean:5.75514 min:1 max:12 sd:3.50281
7: "womens" NUMERICAL mean:0.549687 min:0 max:1 sd:0.497525
CATEGORICAL: 4 (44.4444%)
0: "__LABEL" CATEGORICAL integerized vocab-size:3 no-ood-item
1: "channel" CATEGORICAL has-dict vocab-size:4 zero-ood-items most-frequent:"Web" 22576 (44.0938%)
6: "treatment" CATEGORICAL integerized vocab-size:3 no-ood-item
8: "zip_code" CATEGORICAL has-dict vocab-size:4 zero-ood-items most-frequent:"Surburban" 22966 (44.8555%)
Terminology:
nas: Number of non-available (i.e. missing) values.
ood: Out of dictionary.
manually-defined: Attribute which type is manually defined by the user i.e. the type was not automatically inferred.
tokenized: The attribute value is obtained through tokenization.
has-dict: The attribute is attached to a string dictionary e.g. a categorical attribute stored as a string.
vocab-size: Number of unique values.
[INFO 23-10-03 11:11:16.2800 UTC kernel.cc:810] Configure learner
[INFO 23-10-03 11:11:16.2802 UTC kernel.cc:824] Training config:
learner: "RANDOM_FOREST"
features: "^channel$"
features: "^history$"
features: "^mens$"
features: "^newbie$"
features: "^recency$"
features: "^womens$"
features: "^zip_code$"
label: "^__LABEL$"
task: CATEGORICAL_UPLIFT
random_seed: 123456
uplift_treatment: "treatment"
metadata {
framework: "TF Keras"
}
pure_serving_model: false
[yggdrasil_decision_forests.model.random_forest.proto.random_forest_config] {
num_trees: 300
decision_tree {
max_depth: 16
min_examples: 5
in_split_min_examples_check: true
keep_non_leaf_label_distribution: true
num_candidate_attributes: 0
missing_value_policy: GLOBAL_IMPUTATION
allow_na_conditions: false
categorical_set_greedy_forward {
sampling: 0.1
max_num_items: -1
min_item_frequency: 1
}
growing_strategy_local {
}
categorical {
cart {
}
}
axis_aligned_split {
}
internal {
sorting_strategy: PRESORTED
}
uplift {
min_examples_in_treatment: 5
split_score: KULLBACK_LEIBLER
}
}
winner_take_all_inference: true
compute_oob_performances: true
compute_oob_variable_importances: false
num_oob_variable_importances_permutations: 1
bootstrap_training_dataset: true
bootstrap_size_ratio: 1
adapt_bootstrap_size_ratio_for_maximum_training_duration: false
sampling_with_replacement: true
}
[INFO 23-10-03 11:11:16.2806 UTC kernel.cc:827] Deployment config:
cache_path: "/tmpfs/tmp/tmpkvr89ot3/working_cache"
num_threads: 32
try_resume_training: true
[INFO 23-10-03 11:11:16.2808 UTC kernel.cc:889] Train model
[INFO 23-10-03 11:11:16.2809 UTC random_forest.cc:416] Training random forest on 51200 example(s) and 7 feature(s).
[WARNING 23-10-03 11:11:16.4040 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:16.4058 UTC random_forest.cc:802] Training of tree 1/300 (tree index:28) done qini:0.000608425 auuc:0.00206948
[WARNING 23-10-03 11:11:16.4811 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:16.4858 UTC random_forest.cc:802] Training of tree 11/300 (tree index:1) done qini:7.44252e-05 auuc:0.00242451
[WARNING 23-10-03 11:11:16.5640 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:16.5666 UTC random_forest.cc:802] Training of tree 21/300 (tree index:22) done qini:4.22719e-05 auuc:0.00240438
[WARNING 23-10-03 11:11:16.6477 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:16.6521 UTC random_forest.cc:802] Training of tree 31/300 (tree index:13) done qini:8.03027e-05 auuc:0.00245679
[WARNING 23-10-03 11:11:16.7137 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:16.7161 UTC random_forest.cc:802] Training of tree 41/300 (tree index:38) done qini:8.50687e-05 auuc:0.00246156
[WARNING 23-10-03 11:11:16.7806 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:16.7833 UTC random_forest.cc:802] Training of tree 51/300 (tree index:49) done qini:-3.59235e-05 auuc:0.00234057
[WARNING 23-10-03 11:11:16.8648 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:16.8692 UTC random_forest.cc:802] Training of tree 61/300 (tree index:59) done qini:-0.000105298 auuc:0.00227119
[WARNING 23-10-03 11:11:16.9304 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:16.9329 UTC random_forest.cc:802] Training of tree 71/300 (tree index:68) done qini:-0.000137303 auuc:0.00223919
[WARNING 23-10-03 11:11:16.9970 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:16.9996 UTC random_forest.cc:802] Training of tree 81/300 (tree index:80) done qini:-8.23665e-05 auuc:0.00229412
[WARNING 23-10-03 11:11:17.0654 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:17.0682 UTC random_forest.cc:802] Training of tree 91/300 (tree index:91) done qini:-0.000220825 auuc:0.00215566
[WARNING 23-10-03 11:11:17.1524 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:17.1570 UTC random_forest.cc:802] Training of tree 101/300 (tree index:95) done qini:-0.000228188 auuc:0.0021483
[WARNING 23-10-03 11:11:17.2209 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:17.2235 UTC random_forest.cc:802] Training of tree 111/300 (tree index:108) done qini:-0.000288918 auuc:0.00208757
[WARNING 23-10-03 11:11:17.2774 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:17.2798 UTC random_forest.cc:802] Training of tree 121/300 (tree index:117) done qini:-0.000304144 auuc:0.00207234
[WARNING 23-10-03 11:11:17.3440 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:17.3463 UTC random_forest.cc:802] Training of tree 131/300 (tree index:129) done qini:-0.000216986 auuc:0.0021595
[WARNING 23-10-03 11:11:17.4250 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:17.4296 UTC random_forest.cc:802] Training of tree 141/300 (tree index:140) done qini:-0.000173193 auuc:0.0022033
[WARNING 23-10-03 11:11:17.4940 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:17.4966 UTC random_forest.cc:802] Training of tree 151/300 (tree index:151) done qini:-0.000152671 auuc:0.00222382
[WARNING 23-10-03 11:11:17.5521 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:17.5560 UTC random_forest.cc:802] Training of tree 161/300 (tree index:158) done qini:-0.000176023 auuc:0.00220047
[WARNING 23-10-03 11:11:17.6199 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:17.6225 UTC random_forest.cc:802] Training of tree 171/300 (tree index:171) done qini:-0.000151236 auuc:0.00222525
[WARNING 23-10-03 11:11:17.6565 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:17.6589 UTC random_forest.cc:802] Training of tree 196/300 (tree index:195) done qini:-0.000153745 auuc:0.00222274
[WARNING 23-10-03 11:11:17.8094 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:17.8143 UTC random_forest.cc:802] Training of tree 206/300 (tree index:205) done qini:-0.000105493 auuc:0.002271
[WARNING 23-10-03 11:11:17.8704 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:17.8730 UTC random_forest.cc:802] Training of tree 216/300 (tree index:208) done qini:-0.00012975 auuc:0.00224674
[WARNING 23-10-03 11:11:17.9298 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:17.9323 UTC random_forest.cc:802] Training of tree 226/300 (tree index:223) done qini:-0.000134271 auuc:0.00224222
[WARNING 23-10-03 11:11:18.0143 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:18.0189 UTC random_forest.cc:802] Training of tree 236/300 (tree index:233) done qini:-0.00011439 auuc:0.0022621
[WARNING 23-10-03 11:11:18.0843 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:18.0870 UTC random_forest.cc:802] Training of tree 246/300 (tree index:246) done qini:-0.000150459 auuc:0.00222603
[WARNING 23-10-03 11:11:18.1504 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:18.1529 UTC random_forest.cc:802] Training of tree 256/300 (tree index:248) done qini:-0.00013702 auuc:0.00223947
[WARNING 23-10-03 11:11:18.1913 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:18.1941 UTC random_forest.cc:802] Training of tree 280/300 (tree index:279) done qini:-0.000126474 auuc:0.00225001
[WARNING 23-10-03 11:11:18.3165 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:18.3189 UTC random_forest.cc:802] Training of tree 290/300 (tree index:287) done qini:-0.000183679 auuc:0.00219281
[WARNING 23-10-03 11:11:18.3762 UTC random_forest.cc:1105] Internal error: Non empty oob evaluation
[INFO 23-10-03 11:11:18.3785 UTC random_forest.cc:802] Training of tree 300/300 (tree index:295) done qini:-0.000173259 auuc:0.00220323
[INFO 23-10-03 11:11:18.3818 UTC random_forest.cc:882] Final OOB metrics: qini:-0.000173259 auuc:0.00220323
[INFO 23-10-03 11:11:18.3984 UTC kernel.cc:926] Export model in log directory: /tmpfs/tmp/tmpkvr89ot3 with prefix d0d80b64ba754300
[INFO 23-10-03 11:11:18.4402 UTC kernel.cc:944] Save model in resources
[INFO 23-10-03 11:11:18.4426 UTC abstract_model.cc:881] Model self evaluation:
Number of predictions (without weights): 51200
Number of predictions (with weights): 51200
Task: CATEGORICAL_UPLIFT
Label: __LABEL
Number of treatments: 2
AUUC: 0.00220323
Qini: -0.000173259
[INFO 23-10-03 11:11:18.4697 UTC kernel.cc:1233] Loading model from path /tmpfs/tmp/tmpkvr89ot3/model/ with prefix d0d80b64ba754300
[INFO 23-10-03 11:11:18.6711 UTC decision_forest.cc:660] Model loaded with 300 root(s), 60190 node(s), and 7 input feature(s).
[INFO 23-10-03 11:11:18.6711 UTC abstract_model.cc:1343] Engine "RandomForestGeneric" built
[INFO 23-10-03 11:11:18.6711 UTC kernel.cc:1061] Use fast generic engine
Model trained in 0:00:02.419511
Compiling model...
Model compiled.
<keras.src.callbacks.History at 0x7f48442b2a60>
评估Uplift models。
Uplift models的度量指标
评估Uplift models最重要的两个度量指标是AUUC(提升曲线下的面积)和Qini(Qini曲线下的面积)度量。这类似于用于分类问题的AUC和准确率的使用。对于这两个度量指标,它们越大越好。
AUUC和Qini都是非标准化的度量指标。这意味着度量指标的最佳可能值可以因数据集而异。这与例如AUC度量指标始终在0和1之间变化不同。
AUUC的正式定义如下。有关这些度量指标的更多信息,请参见Guelman和Betlei et al.。
模型自我评估
TF-DF随机森林模型对训练数据集的袋外样本进行自我评估。对于提升模型,它们公开了AUUC和Qini指标。您可以通过检查器直接在训练数据集上检索这两个指标。
稍后,我们将“手动”在测试数据集上重新计算AUUC指标。请注意,由于AUUC不是归一化指标,因此不应期望两个指标完全相等(训练集上的袋外与测试集)。
# 创建一个模型检查器对象insp,用于获取模型的自我评估信息
insp = model.make_inspector()
# 调用模型检查器的evaluation方法,获取模型的自我评估结果
insp.evaluation()
Evaluation(num_examples=51200, accuracy=None, loss=None, rmse=None, ndcg=None, aucs=None, auuc=0.0022032303161204467, qini=-0.00017325876815314604)
手动计算AUUC
在本节中,我们手动计算AUUC并绘制提升曲线。
接下来的几段解释AUUC指标的细节,可以跳过。
计算AUUC
假设您有一个带有 ∣ T ∣ |T| ∣T∣个带有处理的示例和 ∣ C ∣ |C| ∣C∣个没有处理的示例的标记数据集,称为控制示例。对于每个示例,提升模型 f f f生成一个条件概率,即处理示例将产生积极结果的概率。
假设决策者需要使用提升模型 f f f决定向哪些客户发送电子邮件。该模型生成电子邮件将导致转化的(条件)概率。因此,决策者可能只选择要发送的电子邮件数量 k k k,并将这些 k k k封电子邮件发送给具有最高概率的客户。
使用标记的测试数据集,可以研究 k k k对活动成功的影响。首先,我们对接收到电子邮件并转化的客户占所有接收电子邮件客户的比例 ∣ C ∩ T ∣ ∣ T ∣ \frac{|C \cap T|}{|T|} ∣T∣∣C∩T∣?感兴趣。这里 C C C是接收并转化电子邮件的客户集, T T T是接收电子邮件的客户总数。我们将这个比例绘制成 k k k的函数。
理想情况下,我们希望这条曲线急剧上升。这意味着模型优先发送电子邮件给那些在接收电子邮件时会产生转化的客户。
# 计算在测试数据集上的所有预测值
predictions = model.predict(test_ds).flatten()
# 提取结果和处理方法
outcomes = np.concatenate([outcome.numpy() for _, outcome in test_ds])
treatment = np.concatenate([example['treatment'].numpy() for example,_ in test_ds])
control = 1 - treatment
# 统计处理组的数量
num_treatments = np.sum(treatment)
# 没有处理的客户被称为'对照'组
num_control = np.sum(control)
num_examples = len(predictions)
# 根据预测值对标签和处理方法进行降序排序
prediction_order = predictions.argsort()[::-1]
outcomes_sorted = outcomes[prediction_order]
treatment_sorted = treatment[prediction_order]
control_sorted = control[prediction_order]
# 计算处理组的转化率
ratio_treatment = np.cumsum(np.multiply(outcomes_sorted, treatment_sorted), axis=0)/num_treatments
# 创建图表和坐标轴
fig, ax = plt.subplots()
ax.plot(ratio_treatment, label='处理组的转化率')
ax.set_xlabel('k')
ax.set_ylabel('转化率')
ax.legend()
1/512 [..............................] - ETA: 2:44
12/512 [..............................] - ETA: 2s
23/512 [>.............................] - ETA: 2s
34/512 [>.............................] - ETA: 2s
45/512 [=>............................] - ETA: 2s
55/512 [==>...........................] - ETA: 2s
66/512 [==>...........................] - ETA: 2s
77/512 [===>..........................] - ETA: 2s
88/512 [====>.........................] - ETA: 2s
98/512 [====>.........................] - ETA: 2s
109/512 [=====>........................] - ETA: 1s
120/512 [======>.......................] - ETA: 1s
131/512 [======>.......................] - ETA: 1s
142/512 [=======>......................] - ETA: 1s
153/512 [=======>......................] - ETA: 1s
164/512 [========>.....................] - ETA: 1s
175/512 [=========>....................] - ETA: 1s
186/512 [=========>....................] - ETA: 1s
197/512 [==========>...................] - ETA: 1s
208/512 [===========>..................] - ETA: 1s
219/512 [===========>..................] - ETA: 1s
230/512 [============>.................] - ETA: 1s
241/512 [=============>................] - ETA: 1s
252/512 [=============>................] - ETA: 1s
263/512 [==============>...............] - ETA: 1s
274/512 [===============>..............] - ETA: 1s
285/512 [===============>..............] - ETA: 1s
296/512 [================>.............] - ETA: 1s
307/512 [================>.............] - ETA: 0s
318/512 [=================>............] - ETA: 0s
328/512 [==================>...........] - ETA: 0s
339/512 [==================>...........] - ETA: 0s
350/512 [===================>..........] - ETA: 0s
361/512 [====================>.........] - ETA: 0s
372/512 [====================>.........] - ETA: 0s
383/512 [=====================>........] - ETA: 0s
394/512 [======================>.......] - ETA: 0s
405/512 [======================>.......] - ETA: 0s
416/512 [=======================>......] - ETA: 0s
427/512 [========================>.....] - ETA: 0s
438/512 [========================>.....] - ETA: 0s
449/512 [=========================>....] - ETA: 0s
460/512 [=========================>....] - ETA: 0s
471/512 [==========================>...] - ETA: 0s
482/512 [===========================>..] - ETA: 0s
493/512 [===========================>..] - ETA: 0s
504/512 [============================>.] - ETA: 0s
512/512 [==============================] - 3s 5ms/step
<matplotlib.legend.Legend at 0x7f482c2edd60>

同样地,我们也可以计算和绘制那些没有收到邮件的人群的转化率,称为对照组。理想情况下,这条曲线最初是平的:这意味着模型不会优先发送邮件给那些即使没有收到邮件也会产生转化的客户。
# 计算控制组的转化率
ratio_control = np.cumsum(np.multiply(outcomes_sorted, control_sorted), axis=0) / num_control
# 绘制控制组的转化率曲线
ax.plot(ratio_control, label='Conversion ratio of control')
# 添加图例
ax.legend()
# 显示图形
fig

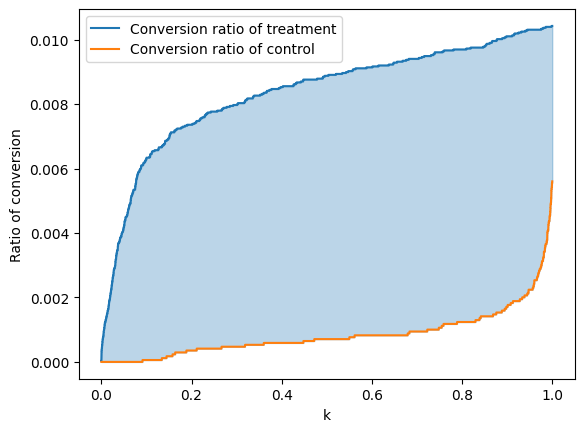
AUUC指标测量了这两条曲线之间的面积,并将y轴归一化到0和1之间。
# 创建一个等差数列,范围从0到1,共有num_examples个数据点
x = np.linspace(0, 1, num_examples)
# 绘制treatment组的转化率曲线
plt.plot(x, ratio_treatment, label='Treatment组的转化率')
# 绘制control组的转化率曲线
plt.plot(x, ratio_control, label='Control组的转化率')
# 使用蓝色填充treatment组转化率大于control组转化率的区域
plt.fill_between(x, ratio_treatment, ratio_control, where=(ratio_treatment > ratio_control), color='C0', alpha=0.3)
# 使用橙色填充treatment组转化率小于control组转化率的区域
plt.fill_between(x, ratio_treatment, ratio_control, where=(ratio_treatment < ratio_control), color='C1', alpha=0.3)
# 设置x轴标签为k
plt.xlabel('k')
# 设置y轴标签为转化率
plt.ylabel('转化率')
# 添加图例
plt.legend()
# 使用梯形法则计算两条曲线之间的面积,得到AUUC值
auuc = np.trapz(ratio_treatment - ratio_control, dx=1/num_examples)
# 打印AUUC值
print(f'测试数据集上的AUUC值为 {auuc}')
The AUUC on the test dataset is 0.007513928513572819
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2023.12.22力扣每日一题
- linux服务器ssh连接慢问题处理
- k8s 定义 gRPC 存活探针
- Cadence——布局部分相关教程
- 详解FreeRTOS:专栏总述
- ros2+rviz2示例代码--cmakelists.txt与package.xml备份
- 基于SpringBoot+Vue的农村电商对接平台(源码+文档+包运行)
- Python使用其它文件夹中的.py文件
- Python办公自动化 – 文件的比较合并和操作xml文件
- Python如何实现数据驱动的接口自动化测试