GBASE南大通用-GBase 8s分片表操作 提升大数据处理性能
目录
?一、GBase 8s分片表的优势
二、六种分片方法
轮转
??????? 1.轮转法
基于表达式分片
??????? 2.基本表达式
??????? 3.Mod运算表达式
??????? 4.Remainder关键字方式
??????? 5.List方式
??????? 6.interval 固定间隔
三、分片表的索引
? ? ? ? 1.创建索引的注意事项
??????? 2.detach索引替代delete功能展现
??????? 3.在现有分片表上增加一个新的分片
四、dbspace数据库空间
? ? ? ? 1.增加dbspaces空间
??????? 2.查看空间大小
??????? 3.查看空间剩余大小
GBase 8s 的分片是用来处理数据量非常大的表和索引的技术。分片可以用将大表拆分为小表的方式进行管理,提高了GBase 8s的大数据处理性能。同时对外提供的是同一个表的管理方式,这样对于使用数据库的访问者而言非常透明。
1、分片是指把一个表的数据分散到多个dbspace中存储。
2、在逻辑上对外提供一个表的访问接口。
3、在数据库内部,物理上把大表拆分为多个小表进行管理。
一、GBase 8s分片表的优势
概括一下,GBase 8s分片表的优势体现在以下三点:
(1)? 有效处理大数据表。
?有效利用并发运行,分片表可以启动PDQ,开启多线程并行处理,可以充分利用多 CPU、多磁盘的物理资源,大大提高大数据表的访问速度。利用分片忽略,可减少需要访问的表空间。利用分片表将大表拆分存放的特性,相当于以访问小表的效率进行访问,如某分片方式将每年存储在一个分片上,那么查询某一时间点的数据时,只需要扫描分片表的一个分片即可,可以有效地处理大数据量的表。实现仅仅对包含“目标数据”的数据分片进行扫描。从而大幅度地提高了整个系统效率。
(2)? 分片容易管理--表组合/表分离(attach/detach)。
?可以利用GBase 8s对分片表提供的attach和detach功能对分片表进行快速、高效的管理。例如detach可以对表的某一个分片进行快速分离,我们可以利用该功能对历史数据进行快速删除,可以替代delete方式。
(3)? 有效地提高可用性。
?当表的某个分片出现故障时,表的其他分片的数据仍然可用,同时只需要修复该分片即可。当我们需要对表进行重建时,我们可以对分片表利用attach/detach按分片一个个地完成重建,从而提高表的可用性,满足7x24运行模式的要求。
下面我们来看GBase分片的具体实现。
二、六种分片方法
GBase的六种分片方式可以大致划分为两类:一类是轮转法分片,第二类是基于表达式的方式。
轮转法:
1.轮转法
“轮转法分片”这个存放方法采用轮询调度,依次在dbspaces上存储数据库。特点为:
简单,不需要了解数据的分布 ;
把数据均匀地分配到所有分片中 ;
提高查询性能 ;
只能用于表,不能用于索引 ;
不能利用到忽略分片的特性,没有成功减少对磁盘的扫描;
可配合PDQ启用多线程并行扫描以提高查询性能。
?create table tab_round_robin
(
? id int,
? name varchar(40),
? nation varchar(40),?
? regtime datetime year to second default current year to second not null
) fragment by round robin
? in datadbs1,datadbs2,datadbs3,datadbs4;
显示的指定索引
create index ix_tab_round_robin_id on tab_round_robin(id) in datadbs1;
基于表达式分片:
“基于表达式分片”则根据表中的一个或多个字段对分片的规则进行定义,一般在预知查询条件时采用这种方式,从而避免查询中对某些分片的扫描。其特点为:
需要对数据分布有所了解 ;
为分片忽略和性能提升提供可能 ;
既可以用于表也可以用于索引 ;
可以基于一列或者多列构建表达式。
基于表达式包括多种具体的形式,下面将介绍5种形式:
2.基本表达式
#当不指定partition时,sql语句如下:
create table tab_expression_based
(
? id int,
? name varchar(40),
? nation varchar(40),?
? regtime datetime year to second default current year to second not null
) fragment by expression
id < 100 in datadbs1,
id < 200 in datadbs2,
id < 300 in datadbs3;
#加入指定partition,sql语句如下,这对于查询可以更好的提高效率。
#partition指定的情况下可以对于不同的p0、p1、p2都放在同一个datadbs1空间中
create table tab_expression_based
(
? id int,
? name varchar(40),
? nation varchar(40),?
? regtime datetime year to second default current year to second not null
) fragment by expression
PARTITION p0 id < 100 in datadbs1,
PARTITION p1 id < 200 in datadbs2,
PARTITION p2 id < 300 in datadbs3;
3.Mod运算表达式
加入取余运算的基本表达式。
create table employee
(
??? id int,
??? name char(50),
??? salary int
)fragment by expression
MOD(id,3) = 0 IN datadbs1,
MOD(id,3) = 1 IN datadbs2,
MOD(id,3) = 2 IN datadbs3;
create index idx_employee on employee(id);
4.Remainder关键字方式
利用remainder关键字将难以表达的范围数据指定到一个分片中。
create table table_test
(
??? col1 int,
??? col2 date
)fragment by expression
col1 >= 0 and col1 < 100 in datadbs1,
col1 >= 100 and col1 < 200 in datadbs2,
remainder in datadbs3;
create index idx_table_test on table_test(col1);
5.List方式
List方式本质上是对or和in运算的改进,使表达式计算更有灵活性,效率更高。
create table customer
(
??? id int,
??? name varchar(128),
??? street varchar(255),
??? state char(2),
??? zipcode char(5),
??? phone char(15)
)fragment by list(state)
PARTITION p0 values('RS','IL') in datadbs1,
PARTITION p1 values('CA','OR') in datadbs2,
PARTITION p2 values('NY','MN') in datadbs3,
PARTITION p3 values(NULL) in datadbs4;
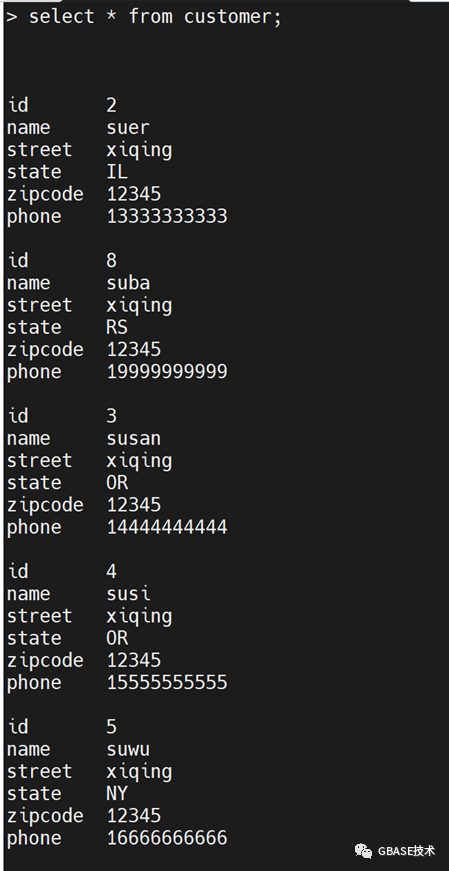
insert into customer values(1,'suyi','xiqing','RS','12345','12211231223');
insert into customer values(2,'suer','xiqing','IL','12345','13333333333');
insert into customer values(3,'susan','xiqing','OR','12345','14444444444');
insert into customer values(4,'susi','xiqing','CA','12345','15555555555');
insert into customer values(5,'suwu','xiqing','NY','12345','16666666666');
insert into customer values(6,'suliu','xiqing','MN','12345','17777777777');
insert into customer values(7,'suqi','xiqing','','12345','1888888888');
insert into customer values(8,'suba','xiqing','RS','12345','19999999999');
#查看分片的具体信息
select t.tabname,f.dbspace,f.partition,f.exprtext
from systables t,sysfragments f
where t.tabid = f.tabid and f.fragtype = 'T'
and t.tabname = 'customer';
#查询结果如下
tabname??? customer
dbspace
partition
exprtext
state
tabname??? customer
dbspace??? datadbs1
partition? p0
exprtext
VALUES ('RS' ,'IL' )
tabname??? customer
dbspace??? datadbs2
partition? p1
exprtext
VALUES ('CA' ,'OR' )
tabname??? customer
dbspace??? datadbs3
partition? p2
exprtext
VALUES ('NY' ,'MN' )
tabname??? customer
dbspace??? datadbs4
partition? p3
exprtext
VALUES (NULL)
5 row(s) retrieved.
通过update语句确认我们的分片表结构,成功按照list方式进行分片。
update customer set state = '' where id = 1;
执行上述update语句后,当前记录会从当前分片中删除并且在新的分片里面插入,通过逻辑日志展示,可以证明我们的想法。
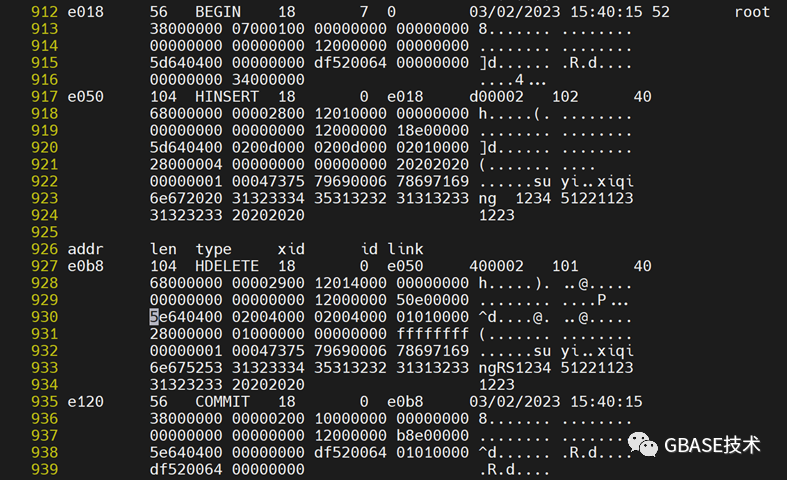
update customer set state = 'OR' where id = 4;
再来尝试上面这条update语句,我们知道当前记录对应的条件没有发生变化,仍在原来分区,只是state的值进行更新,所以猜想应该只是更新记录。通过查看逻辑日志,证明我们的猜想正确。
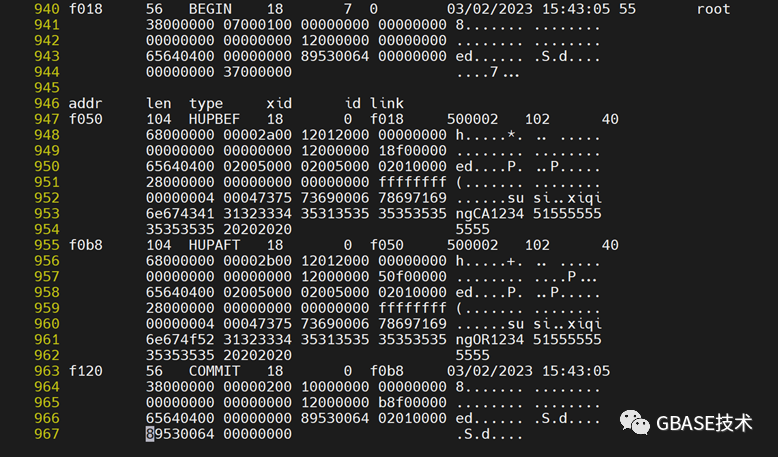
6.interval 固定间隔
最初的分片是基于一个range语句来定义的。
优点:GBase 8s提供的基于interval的分片策略,将根据Insert记录的情况自动扩展分片,可提供更为灵活的方式,减少人工维护。
create table sales
(
??? amount int,
??? id int,
??? data_time datetime year to second
)fragment by range(data_time)
interval (10 units day)
store in (datadbs1,datadbs2,datadbs3,datadbs4)
partition p_sales0 values < '2023-01-01 00:00:00' in dbspace;
create unique index idx_sales on sales(data_time,id);
三、分片表的索引
GBase 8s的索引分为attached和detached的两种索引。
两种索引的区别在于:attached索引指每个分片的数据都有相应的索引独立存在;detached索引指的是索引与分片数据存储在不同的dbspace上。
我们先简单的建立两种索引,了解一下。
create table frag_exp_tab
(
??? sale_time datetime year to second,
??? product_id int,
??? product_time datetime year to second,
??? price float,
??? sale_amount int,
??? primary key(sale_time,product_id)
)fragment by expression
sale_time < '2022-01-01 00:00:00' and sale_time >= '2021-01-01 00:00:00' in datadbs1,
sale_time < '2021-01-01 00:00:00' and sale_time >= '2020-01-01 00:00:00' in datadbs2,
sale_time < '2020-01-01 00:00:00' and sale_time >= '2019-01-01 00:00:00' in datadbs3;
create index idx_frad_exp_tab on frag_exp_tab(product_time,product_id);
#命令行中输入以下命令,可以查询当前表对应索引
oncheck -ci t:frag_exp_tab
#在GBase 8s中自动为主键、外键、唯一约束创建索引,默认情况下为detached索引。
#GBase 8s自动创建的索引名字为空格+tabid_+一个序号组成。
Validating indexes for t:root.frag_exp_tab...
????????????????Index ?101_1 ????#detached索引
??????????????????Index ?fragment partition rootdbs in DBspace rootdbs
????????????????Index idx_frad_exp_tab ??#attached索引
??????????????????Index ?fragment partition datadbs1 in DBspace datadbs1
??????????????????Index ?fragment partition datadbs2 in DBspace datadbs2
??????????????????Index ?fragment partition datadbs3 in DBspace datadbs3
1.创建索引的注意事项
注意:产生'-872'错误码的原因:
在分片表上,如果要创建一个unique的attached索引,需要在索引中包含分片的key字段,所以基于表达式的分片表上可以创建,不能在轮转法上创建。
2.detach索引替代delete功能展现
前文开始部分就提到,detached索引还可以起到将分片表中某一分片快速分离的作用,下面进行一个操作实践,直观感受一下detach起到的替代delete的功能。
①首先我们创建一个detached索引。
create index idx_frad_exp_tab2 on frag_exp_tab(product_time,sale_time) in datadbs4;
②其次向里面插入一部分数据,为了清晰的展示分片分离。
insert into frag_exp_tab values('2021-09-06 00:00:00',1,'2000-01-01 00:00:00',999.9,1);
insert into frag_exp_tab values('2020-09-06 00:00:00',2,'1999-01-01 00:00:00',666.6,2);
insert into frag_exp_tab values('2019-09-06 00:00:00',3,'1998-01-01 00:00:00',333.3,3);
insert into frag_exp_tab values('2020-05-01 00:00:00',4,'2000-01-01 00:00:00',111.1,1);
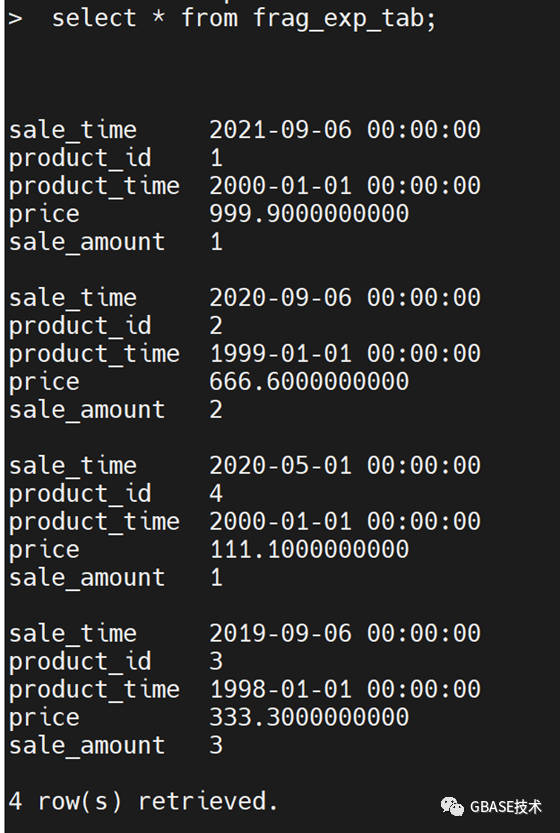
③执行detch子句,将范围区间分片datadbs2从表frag_exp_tab拆离并放置到新的未分片表segregation_tab1中。
alter fragment on table frag_exp_tab detach partition datadbs2 segregation_tab1;
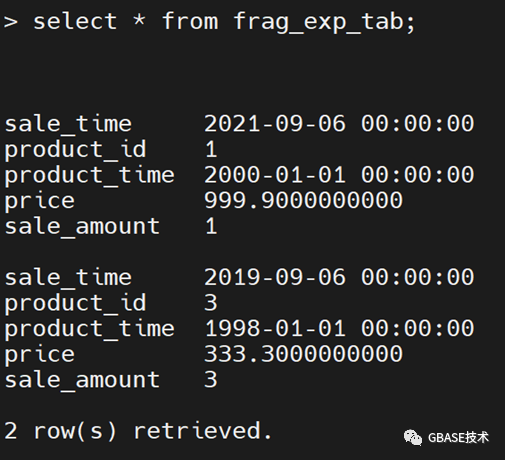
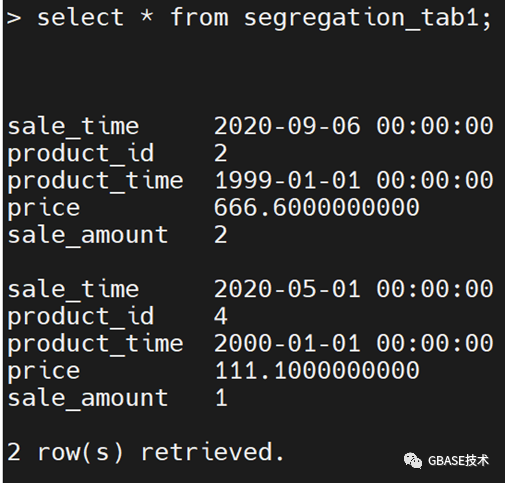
3.在现有分片表上增加一个新的分片
①首先在命令行下执行语句,查看我们当前表的结构状态。
dbschema -d t -t frag_exp_tab -ss
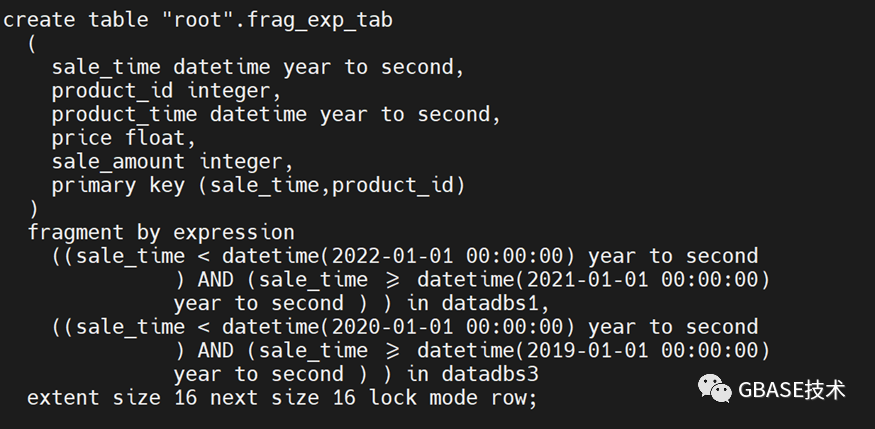
我们向里面加入一个新的分片。
alter fragment on table frag_exp_tab add
sale_time < '2021-01-01 00:00:00' and sale_time >= '2020-01-01 00:00:00' in datadbs2
before datadbs3;
③查看当前表结构,可以看到,已经增加了一个分片,操作成功。
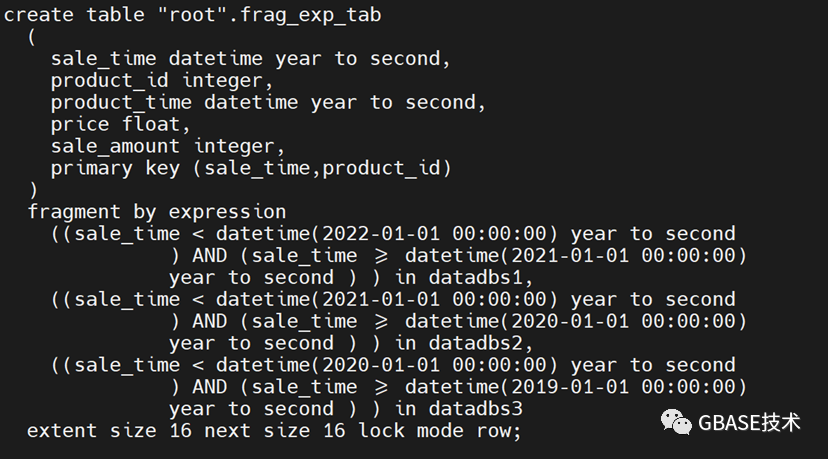
四、dbspace数据库空间
在实现GBase 8s分片技术时,基本都会使用到增加数据库空间的操作,下面对dbspace进行一下简单操作介绍。
1.增加dbspaces空间
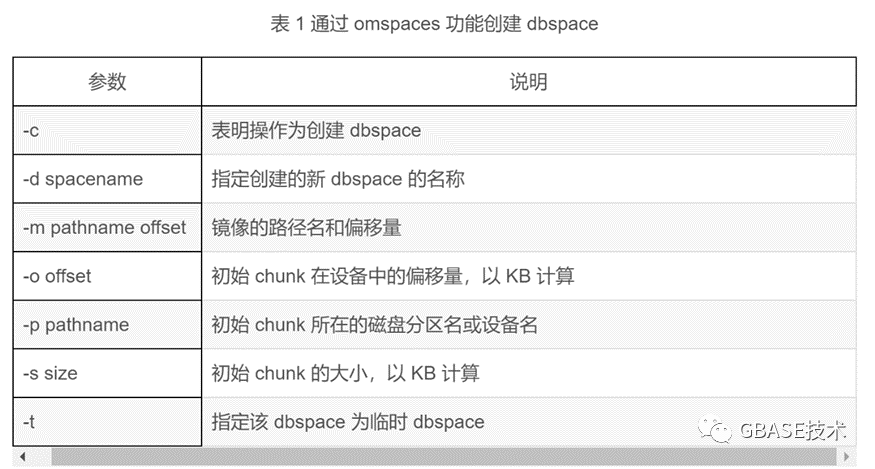
创建新数据库空间,使用onspaces命令。
onspaces -c -d-k-p-o-s
在linux环境中页大小默认2k,这里我们创建一个新的datadbs1,大小为1024000kb。
cd /home/su/gbase/storage
touch datadbs1
chmod 660 datadbs1
chown gbasedbt:gbasedbt datadbs1
onspaces -c -d datadbs1 -k 2 -p /home/su/gbase/storage/datadbs1 -o 0 -s 1024000
以下例子为创建一个临时 dbspace,名为 tempdbs1,大小为 500000,使用裸设备/dev/rdsk/device9,偏移量为 100000:
?onspaces -c -t -d tempdbs -p /dev/rdsk/device9 -o 100000 -s 500000?
2.查看空间大小
使用命令onstat -d 查看数据库空间信息。
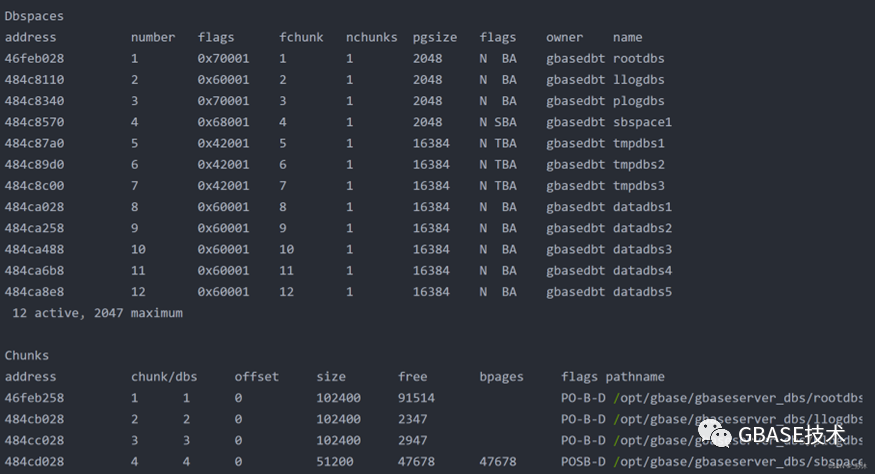
number 为表空间唯一标示号;
pagesize ?数据库空间的页大小;
flag ???????列信息:
Position 1:?? M?? 镜像
?????? N?? 未镜像
Position 2:?? X?? 新镜像
?????? D?? Down,不可用chunk
?????? P?? 物理恢复完成,等待逻辑恢复
?????? L?? 正在逻辑恢复
?????? R?? 正在恢复
???Position 3:?? B?? BLOB空间
?????? P?? 物理日志空间
?????? S?? 智能大对象空间
?????? T?? 临时空间
?????? U?? 临时智能大对象空间
?????? W?? SDS主节点的临时空间,只在SDS备节点显示
Position 4:?? B?? 空间可包含大于2G的chunk
Position 5:?? A?? 空间自动扩展
每个数据库空间有一个Chunk文件。Chunk输出信息中有size信息,这个信息是Chunk的页的数据,不是文件的字节大小。要得到Chunk的文件字节大小,需要用这个size乘以Chunk文件对应的数据库空间的pgsize。
3.查看空间剩余大小
剩余大小就是chunk输出信息中free数据乘以Chunk文件对应的数据库空间的pgsize。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【大数据进阶第三阶段之ClickHouse学习笔记】ClickHouse的简介和使用
- 【C#】当重复使用一段代码倒计时时,使用静态类和静态方法,实现简单的this扩展方法
- Phoncent博客发布小说《Q年文峰》GPT应用
- 业务逻辑漏洞—验证码绕过
- uniapp自定义封装只有时分秒的组件,时分秒范围选择
- 基于SpringBoot的人事管理系统(程序+数据库+文档)
- 解锁 ESLint 的秘密:代码质量的守护者(上)
- 22000mAh 电池,这款国产新机来了场「续航」震撼
- java中HashMap的七种遍历方式
- 【Mars3d】实现cesium叠加dwg或者其他矢量图的解决方案