大模型 RLHF 实战!【OpenAI独家绝技RLHF!RLHF的替代算法DPO!Claude 暗黑科技 RAIHF!】
?
大模型 RLHF 实战
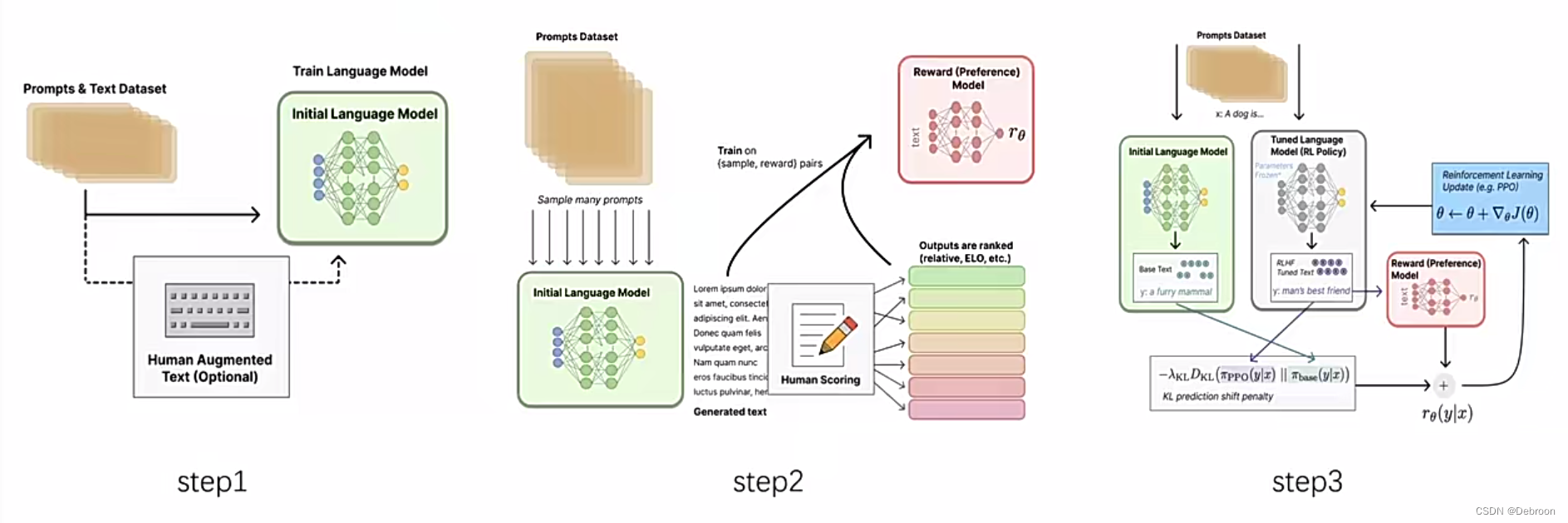
RLHF(基于人类反馈的强化学习)分为 3 个阶段:
- 预训练:为了生成内容,需要一个生成式的预训练语言模型(如GPT);还会引入微调,帮助模型更好理解提示(Prompts)
- 训练奖励函数:通过对模型生成的结果,人工标注反馈,构造训练集,用于训练奖励函数,模拟人的奖励偏好
- 强化学习:定义策略(第一阶段语言模型输入输出)、动作空间(词表token的排列组合)、奖励函数(第二阶段训练的);对于同一个问题,会同时送入原始模型、训练模型,用奖励函数对俩者评分,分数差值用于训练策略函数。
安利下面的工具,支持主流模型(ChatGLM系列、Baichuan系列、LLaMA系列、Qwen系列、Bloom):
同时支持训练方法,包括预训练(pre-training), 有监督微调(sft)和 RLHF,微调方式均为 LoRA 或者 QLoRA、全参数。
按照ta的教程一步步操作即可。
RLHF:OpenAI独家绝技
正在更新…
RLHF 的问题
RLHF 的替代有 2 种:DPO、RAIHF。
-
RLHF:从人类反馈中学习的强化学习
-
DPO:直接偏好优化算法,专门替代传统的基于奖励的 RL 方法。
RLHF 问题:策略和价值函数迭代步骤相当复杂,经验数据采集计算成本高。
改进:DPO 是简化了 RLHF 步骤(不需要对奖励函数进行复杂的工程设计),但同时效果不比 RLHF 差。
-
RAIHF:RLHF不再需要人类,AI 实现标注自循环,AI标注效果一样好。
RLHF 问题:
- 成本高昂(收集高质量人工,反馈需要大量的时间和金钱资源),RLHF通常使用数以万计的人类偏好标签
- 样本效率低(模型需要大量的人类反馈来学习和改进其行为)
- 人类偏见(模型可能会学习并放大人类评估者的偏见)
- 一致性问题(不同人评估给出不一致的反馈,导致模型训练中的不确定性)
- 可扩展性问题(对于非常复杂的任务或环境,难以获得足够的人类反馈来训练模型)
?
改进:RAIHF 是通过 AI 排序,而非人工排序数据集,训练出来的偏好模型PM的指引下迭代模型策略。
DPO 直接偏好优化算法:RLHF的替代算法
作者在训练 DPO 模型时省略了奖励模型训练的步骤,而是通过设计一种包含正负样本对比的损失函数,在训练过程中得到一个满足人类偏好的模型。
- 你的语言模型其实是一个奖励模型
- 不训练奖励模型,语言模型直接做偏好优化
- 学习你的偏好,满足你的偏好
这种方法在文本总结和单轮对话任务上提高了生成结果的质量。
正样本和负样本的对比,使得模型能够更好地学习到人类偏好的特征,从而提升了生成的质量。
RLHF、DPO 差异:
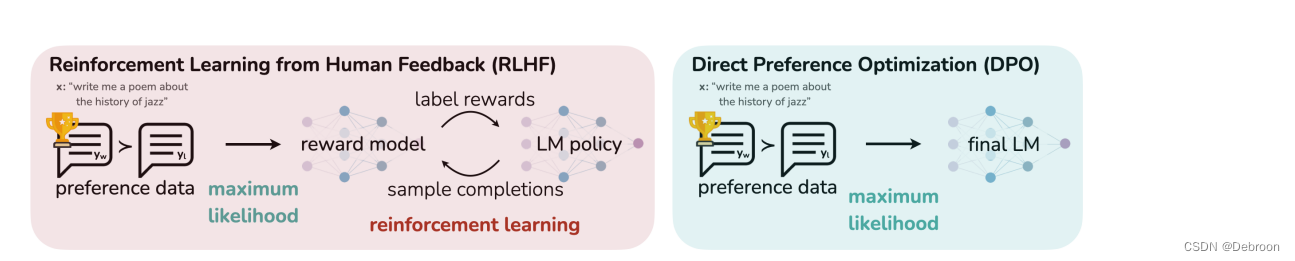
左右两边最大的区别就是,有没有reward model (RM)。
DPO 是将配给 RW 的训练融合在 final LM 里面,LLM本身即是RM。
公式 1 - 4:KL散度下奖励的最大化目标
p ? ( y 1 ? y 2 ∣ x ) = exp ? ( r ? ( x , y 1 ) ) exp ? ( r ? ( x , y 1 ) ) + exp ? ( r ? ( x , y 2 ) ) p^*(y_1\succ y_2\mid x)=\frac{\exp\left(r^*(x,y_1)\right)}{\exp\left(r^*(x,y_1)\right)+\exp\left(r^*(x,y_2)\right)} p?(y1??y2?∣x)=exp(r?(x,y1?))+exp(r?(x,y2?))exp(r?(x,y1?))?
- 人类偏好分布 p ? p* p?
- 模型会生成问答对,会呈现给人类标注者,并让他们给出一个答案偏好 y 1 > y 2 ∣ x y_{1}>y_{2} | x y1?>y2?∣x
- y 1 > y 2 y_{1}>y_{2} y1?>y2?:更好的答案
- 假设这些偏好是由某个潜在的奖励模型 r ? ( x , y 1 ) r^*(x,y_1) r?(x,y1?) 生成
建立奖励模型,对其参数做最大似然估计,从而将问题转换为二分类问题,同时使用负对数做似然损失:
- L R ( r ? , D ) = ? E ( x , y w , y l ) ~ D [ log ? σ ( r ? ( x , y w ) ? r ? ( x , y l ) ) ] \mathcal{L}_{R}(r_{\phi},\mathcal{D})=-\mathbb{E}_{(x,y_{w},y_{l})\sim\mathcal{D}}\big[\log\sigma(r_{\phi}(x,y_{w})-r_{\phi}(x,y_{l}))\big] LR?(r??,D)=?E(x,yw?,yl?)~D?[logσ(r??(x,yw?)?r??(x,yl?))]
目标函数(使用学到的奖励函数来为语言模型提供反馈):
- max ? π θ E x ~ D , y ~ π θ ( y ∣ x ) [ r ? ( x , y ) ] ? β D K L [ π θ ( y ∣ x ) ∣ ∣ π r e f ( y ∣ x ) ] \max_{\pi_\theta}\mathbb{E}_{x\sim\mathcal{D},y\sim\pi_\theta(y|x)}\big[r_\phi(x,y)\big]-\beta\mathbb{D}_{\mathbf{KL}}\big[\pi_\theta(y\mid x)||\pi_{\mathbf{ref}}(y\mid x)\big] maxπθ??Ex~D,y~πθ?(y∣x)?[r??(x,y)]?βDKL?[πθ?(y∣x)∣∣πref?(y∣x)]
推导上式,得到:
-
π
r
(
y
∣
x
)
=
1
Z
(
x
)
π
r
e
f
(
y
∣
x
)
exp
?
(
1
β
r
(
x
,
y
)
)
\pi_r(y\mid x)=\frac1{Z(x)}\pi_{\mathrm{ref}}(y\mid x)\exp\left(\frac1\beta r(x,y)\right)
πr?(y∣x)=Z(x)1?πref?(y∣x)exp(β1?r(x,y))
?
上述就是论文 1 - 4 的推导结果。
这个公式是从一个最大化目标函数出发来推导的,其中包含了两个部分:模型预期奖励的最大化以及KL散度的一个约束项。
KL散度是衡量两个概率分布之间差异的一个指标,在这里用于限制学习到的策略 π θ \pi_\theta πθ? 与参考策略 π r e f \pi_{\mathrm{ref}} πref? 之间的差异。
目标函数可以分解为两部分:
-
max ? π θ E x ~ D , y ~ π θ ( y ∣ x ) [ r ? ( x , y ) ] \max_{\pi_\theta}\mathbb{E}_{x\sim\mathcal{D},y\sim\pi_\theta(y|x)}\big[r_\phi(x,y)\big] maxπθ??Ex~D,y~πθ?(y∣x)?[r??(x,y)]
- 这部分表示模型试图最大化预期奖励,也就是在给定输入 x x x 的情况下,通过策略 π θ \pi_\theta πθ? 生成答案 y y y 来获得尽可能高的奖励 r ? ( x , y ) r_\phi(x,y) r??(x,y)。
-
? β D K L [ π θ ( y ∣ x ) ∣ ∣ π r e f ( y ∣ x ) ] -\beta\mathbb{D}_{\mathbf{KL}}\big[\pi_\theta(y\mid x)||\pi_{\mathbf{ref}}(y\mid x)\big] ?βDKL?[πθ?(y∣x)∣∣πref?(y∣x)]
- 这部分表示有一个正则化项,通过KL散度来限制策略 π θ \pi_\theta πθ? 不能偏离参考策略 π r e f \pi_{\mathrm{ref}} πref? 太远。 β \beta β 是一个正的权衡系数,决定了对偏离的惩罚程度。
目标函数最大,而公式 3 是相减,就意味着 ? β D K L [ π θ ( y ∣ x ) ∣ ∣ π r e f ( y ∣ x ) ] -\beta\mathbb{D}_{\mathbf{KL}}\big[\pi_\theta(y\mid x)||\pi_{\mathbf{ref}}(y\mid x)\big] ?βDKL?[πθ?(y∣x)∣∣πref?(y∣x)] 要最小。
而要从这个目标函数推导出策略 π r ( y ∣ x ) \pi_r(y\mid x) πr?(y∣x) 的表达式,我们需要用到拉格朗日乘子法来处理带有约束的优化问题。拉格朗日乘子法可以帮助我们求解在某些约束条件下的最优化问题。
在这种情况下,想要的是一个新的策略 π r ( y ∣ x ) \pi_r(y\mid x) πr?(y∣x),不仅能最大化奖励,还要满足对参考策略 π r e f ( y ∣ x ) \pi_{\mathrm{ref}}(y\mid x) πref?(y∣x) 的约束。
为了解这个带约束的优化问题,可以构建一个拉格朗日函数:
L ( π θ ) = E x ~ D , y ~ π θ ( y ∣ x ) [ r ? ( x , y ) ] ? β D K L [ π θ ( y ∣ x ) ∣ ∣ π r e f ( y ∣ x ) ] \mathcal{L}(\pi_\theta) = \mathbb{E}_{x\sim\mathcal{D},y\sim\pi_\theta(y|x)}\big[r_\phi(x,y)\big] - \beta \mathbb{D}_{\mathbf{KL}}\big[\pi_\theta(y\mid x)||\pi_{\mathbf{ref}}(y\mid x)\big] L(πθ?)=Ex~D,y~πθ?(y∣x)?[r??(x,y)]?βDKL?[πθ?(y∣x)∣∣πref?(y∣x)]
对这个函数求解最优策略 π θ \pi_\theta πθ? 的表达式时,会发现最优策略具有如下形式:
- 公式 3 到 公式 4 的详细推导:https://zhuanlan.zhihu.com/p/644911957
π r ( y ∣ x ) = 1 Z ( x ) π r e f ( y ∣ x ) exp ? ( 1 β r ? ( x , y ) ) \pi_r(y\mid x) = \frac{1}{Z(x)}\pi_{\mathrm{ref}}(y\mid x) \exp\left(\frac{1}{\beta}r_\phi(x,y)\right) πr?(y∣x)=Z(x)1?πref?(y∣x)exp(β1?r??(x,y))
这里的 Z ( x ) Z(x) Z(x) 是规范化因子(相当于做了归一化,取值 0-1),确保 π r ( y ∣ x ) \pi_r(y\mid x) πr?(y∣x) 是一个有效的概率分布。
这个推导使用了变分原理,其中 π r ( y ∣ x ) \pi_r(y\mid x) πr?(y∣x) 是 π θ ( y ∣ x ) \pi_\theta(y\mid x) πθ?(y∣x) 的一个特殊形式,它使得拉格朗日函数 L ( π θ ) \mathcal{L}(\pi_\theta) L(πθ?) 被最大化。
意思是,可以通过一个加权的参考策略来构造一个新的策略,该策略会偏向于高奖励的行为,同时保持与参考策略的相似性。
权重由奖励函数和温度参数 β \beta β 共同决定。
正在更新…
使用 DPO 微调 Llama 2
请猛击:https://github.com/huggingface/blog/blob/main/zh/dpo-trl.md
RAIHF
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【ubuntu】ubuntu 20.04安装docker,使用nginx部署前端项目,nginx.conf文件配置
- WebSocket
- 黑格尔哲学,从入门到入坟
- Mac AE 报错 “无法获取动态链路服务器”
- 基于win安装的docker内安装sonar时启动时错误
- 红警1源代码下载,编译,单步调试操作步骤
- x-cmd pkg | jless - 受 Vim 启发的命令行 JSON 查看器
- Zblog主题模板:ZblogitseanPage博客主题模板
- 从技术角度分析:HTTP 和 HTTPS 有何不同
- torch.max()函数的理解