RobotFrameWork环境搭建及使用

RF环境搭建
- 首先安装python并且配置python环境变量
- pip install robotframework
- pip install robotframework-ride 生产桌面快捷方式 不行换豆瓣源
- 检查一下pip list
RF类库和扩展库
标准库
- 按F5快捷键查询,可以看到rf自带的库不需要额外安装
- 这些标准库在python的 \Lib\site-packages\robot\libraries中
扩展库(需要通过pip命令额外安装的库)
这些扩展库在python的 \Lib\site-packages中
web自动化测试:SeleniumLibrary
安装:pip install robotframework-seleniumlibrary
接口自动化测试:RequestsLibrary
安装:pip install robotframework-requests
app自动化测试:AppiumLibrary
安装:pip install robotframework-appiumlibrary
基本使用
- 先建项目new directory -> 再建立测试套件new suit(拓展库导入包文件) ->在建立测试用例new test
case - 关键字使用提示快捷键:shift + ctrl + 空格 或者 ctrl + alt + 空格

SeleniumLibrary
下载驱动
下载驱动地址:http://npm.taobao.org/mirrors/chromedriver/,下载后解压的Chromedriver.exe放在python的目录下即可(因为这个目录会配置环境变量)
?谷歌浏览器的版本(浏览器【帮助】-【版本】)一定要和驱动兼容
1
火狐浏览器(同上方)
下载驱动地址:https://github.com/mozilla/geckodriver/releases,下载最新版本就可以了,火狐会兼容的
- 自动更新版本运用webdriver-manager
pip install webdriver-manager或者换豆瓣源下载
# selenium 3
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
#driver = webdriver.Chrome(ChromeDriverManager().install())
#driver = webdriver.Firefox(GeckoDriverManager().install())
driver = webdriver.Edge(EdgeChromiumDriverManager().install())
# selenium 4
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()))
分层:页面元素层(资源文件.txt),业务逻辑层(资源文件.txt),测试用例层(测试套件|数据驱动)
调用关系:业务逻辑层去调用页面元素层 -> 测试用例层去调用业务逻辑层 -> 测试用例层使用模板做数据驱动
页面元素层(资源文件.txt)
注意导包SeleniumLibrary
创建new user keywords,将每一步元素操作分开
数据参数化
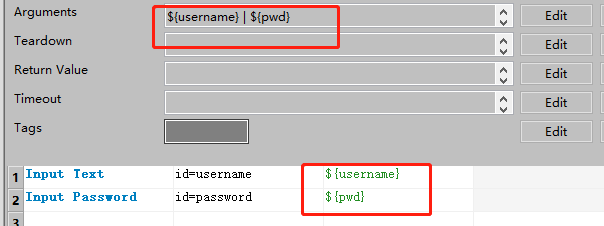
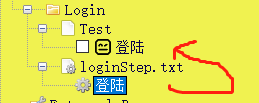
业务逻辑层(资源文件.txt)
注意需要调用页面元素层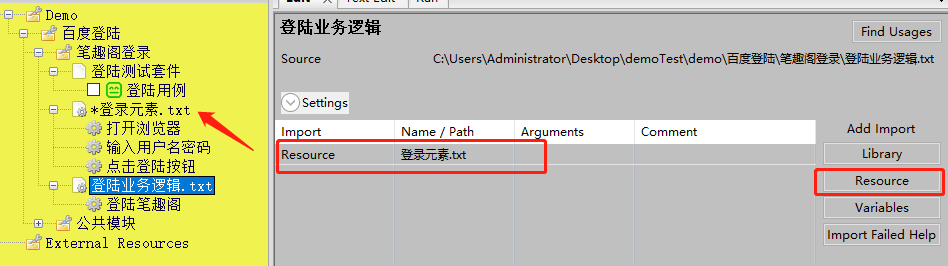
创建new user keywords,调用页面元素层的keywords(如下图)
页面元素层的参数化这边需要继续参数化调用
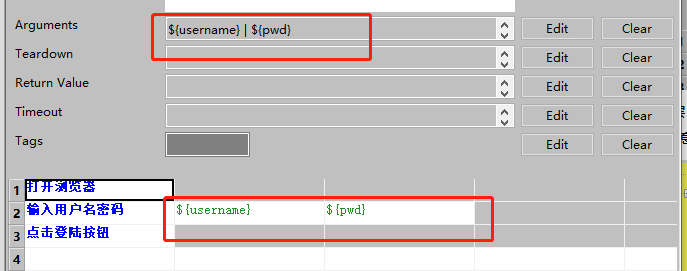
测试用例层(测试套件|数据驱动)
调用业务逻辑层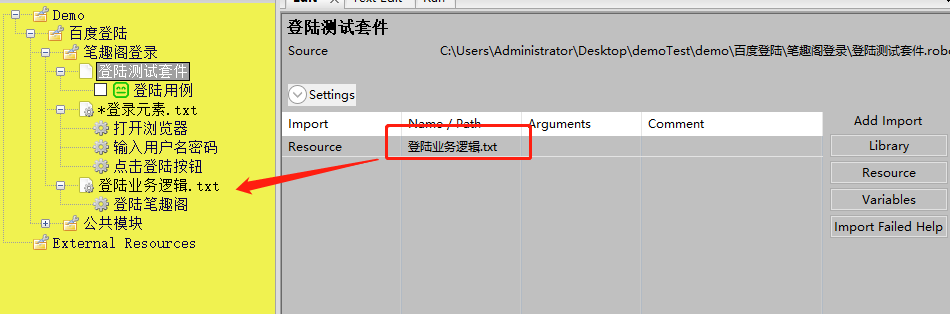
模板使用业务逻辑层的keywords
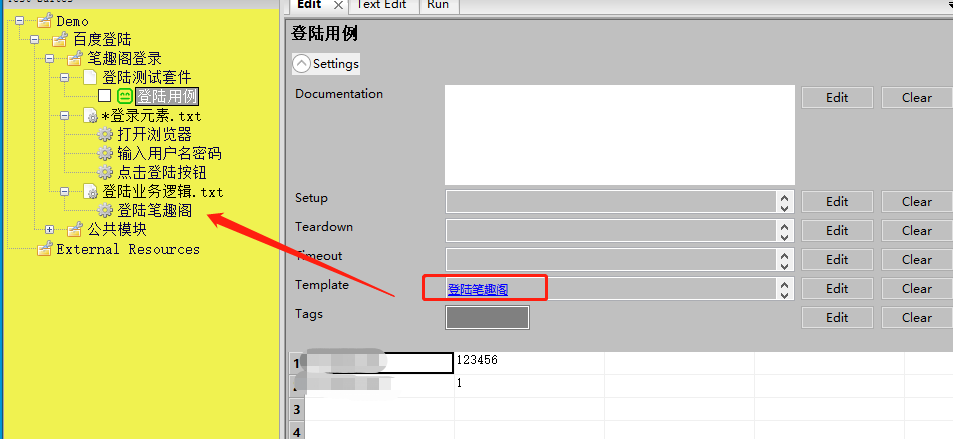
用例中下方设置的用例会逐个执行模板中的逻辑
RequestsLibrary

作为一款具有关键字驱动的软件,我们要用好这个特点,我们在设计用例的时候,尽量多的去封装一些常用的功能成关键字,例如登陆之类的功能。
和selenium库一样,测试套件下建立测试用例,测试资源txt文件下方测试关键字
create session 和 update session来创建session和更新session

最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!?

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 下一代实时数据库:Apache Doris 【三】集群部署
- 2024.1.1力扣每日一题——经营摩天轮的最大利润
- UE5 C++(十七)— 射线检测
- [小程序]样式与配置
- 阿里云服务器4核8G配置收费标准及新老用户优惠价格整理
- MySQL之锁
- leaflet学习笔记-leaflet-ajax获取数据(五)
- 27.BGP边界网关路由协议
- 用什么可以把文档变成二维码?文件通过二维码打开的方法
- 【数据结构】从顺序表到ArrayList类