【征服redis15】分布式锁的功能与整体设计方案
目录
?1. 分布式锁的概念
从现在开始,我们来研究分布式锁相关的问题。在单机环境下,我们可以使用JDK提供的大量工具来完成线程安全与高并发相关的任务,这其中最重要的一个就是锁。
在单进程的系统中,当存在多个线程可以同时改变某个变量(可变共享变量)时,就需要对变量或代码块做同步,使其在修改这种变量时能够线性执行消除并发修改变量。而同步的本质是通过锁来实现的。为了实现多个线程在一个时刻同一个代码块只能有一个线程可执行,那么需要在某个地方做个标记,这个标记必须每个线程都能看到,当标记不存在时可以设置该标记,其余后续线程发现已经有标记了则等待拥有标记的线程结束同步代码块取消标记后再去尝试设置标记。这个标记可以理解为锁。
不同地方实现锁的方式也不一样,只要能满足所有线程都能看得到标记即可。如 Java 中 synchronize 是在对象头设置标记,JUC包里的Lock 接口的实现类基本上都只是某一个 volitile 修饰的 int 型变量其保证每个线程都能拥有对该 int 的可见性和原子修改,linux 内核中也是利用互斥量或信号量等内存数据做标记。
除了利用内存数据做锁其实任何互斥的都能做锁(只考虑互斥情况),如流水表中流水号与时间结合做幂等校验可以看作是一个不会释放的锁,或者使用某个文件是否存在作为锁等。只需要满足在对标记进行修改能保证原子性和内存可见性即可。
如果我们思考一下,如果是在分布式场景下,又该如何实现共享变量的安全访问呢?很多时候我们需要保证一个方法在同一时间内只能被同一个线程执行。在单机环境中,通过 Java 提供的并发 API 我们可以解决,但是在分布式环境下,就没有那么简单啦。其中最典型的问题是:
- 分布式与单机情况下最大的不同在于其不是多线程而是多进程。
- 多线程由于可以共享堆内存,因此可以简单的采取内存作为标记存储位置。而进程之间甚至可能都不在同一台物理机上,因此需要将标记存储在一个所有进程都能看到的地方。
为此,我们就需要来设计分布式环境下可以保证资源安全访问的锁。具体来说,应该满足如下几个要求:
- 在分布式模型下,数据只有一份(或有限制),此时需要利用锁的技术控制某一时刻修改数据的进程数。
- 与单机模式下的锁不仅需要保证进程可见,还需要考虑进程与锁之间的网络问题。分布式情况下之所以问题变得复杂,主要就是需要考虑到网络的延时和不可靠。
- 分布式锁还是可以将标记存在内存,只是该内存不是某个进程分配的内存而是公共内存如 Redis、Memcache。至于利用数据库、文件等做锁与单机的实现是一样的,只要保证标记能互斥就行。
该如何实现分布式锁呢?在Java领域,主要有三个组件可以帮助我们实现:Mysql数据库、redis和Zookeeper。我们分别来看如何使用这三个组件实现分布式锁。
2.基于数据库做分布式锁
我们知道,即使在复杂的微服务环境下,我们最终要访问的数据只会在一个地方,例如某个学生某个时间学习某课的记录一定是在一个表里的(不考虑主备和异地保活的因素),而不会将这个数据存放在好几个地方,因此,不管有几个请求,只要最后在访问这条记录的时候,我们实现安全访问 ,其他的请求等待或者拒绝掉,就可以做到分布式锁的效果。
这就是数据库可以做分布式锁的核心思想,具体来说,根据数据库表的情况,我们又有多种方案。
2.1 基于表主键唯一做分布式锁
利用主键唯一的特性,如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,当方法执行完毕之后,想要释放锁的话,删除这条数据库记录即可。
上面这种简单的实现有以下几个问题:
- 这把锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用。
- 这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁。
- 这把锁只能是非阻塞的,因为数据的 insert 操作,一旦插入失败就会直接报错。没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作。
- 这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了。
- 这把锁是非公平锁,所有等待锁的线程凭运气去争夺锁。
- 在 MySQL 数据库中采用主键冲突防重,在大并发情况下有可能会造成锁表现象。
当然,我们也可以有其他方式解决上面的问题。
- 数据库是单点?搞两个数据库,数据之前双向同步,一旦挂掉快速切换到备库上。
- 没有失效时间?只要做一个定时任务,每隔一定时间把数据库中的超时数据清理一遍。
- 非阻塞的?搞一个 while 循环,直到 insert 成功再返回成功。
- 非重入的?在数据库表中加个字段,记录当前获得锁的机器的主机信息和线程信息,那么下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给他就可以了。
- 非公平的?再建一张中间表,将等待锁的线程全记录下来,并根据创建时间排序,只有最先创建的允许获取锁。
- 比较好的办法是在程序中生产主键进行防重。
不过整体来看,在复杂场景下,这个分布式锁会非常脆弱,很容易出问题。
2.2 基于表字段版本号做分布式锁
这个策略源于 mysql 的 mvcc 机制,使用这个策略其实本身没有什么问题,唯一的问题就是对数据表侵入较大,我们要为每个表设计一个版本号字段,然后写一条判断 sql 每次进行判断,增加了数据库操作的次数,但是在高并发的要求下,这会严重影响性能,对数据库连接的开销也是无法忍受的。
2.3 基于数据库排他锁做分布式锁
在查询语句后面增加for update,数据库会在查询过程中给数据库表增加排他锁 (注意: InnoDB 引擎在加锁的时候,只有通过索引进行检索的时候才会使用行级锁,否则会使用表级锁。这里我们希望使用行级锁,就要给要执行的方法字段名添加索引,值得注意的是,这个索引一定要创建成唯一索引,否则会出现多个重载方法之间无法同时被访问的问题。重载方法的话建议把参数类型也加上。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。
我们可以认为获得排他锁的线程即可获得分布式锁,当获取到锁之后,可以执行方法的业务逻辑,执行完方法之后,通过connection.commit()操作来释放锁。
这种方法可以有效的解决上面提到的无法释放锁和阻塞锁的问题。
- 这种锁是阻塞锁,
for update语句会在执行成功后立即返回,在执行失败时一直处于阻塞状态,直到成功。 - 这种锁定之后服务宕机,是否会出现无法释放的问题呢?使用这种方式,服务宕机之后数据库会自己把锁释放掉。
所以这种方式比较简单在实际工程里是很多应用的。例如在转账的时候,我们需要先从A扣减10,然后再给B加10,此时就可以使用for update,保证这个操作要么一定完成,要么都不执行。
这里可能有一个问题,就是我们要使用排他锁来进行分布式锁的 lock,那么一个排他锁长时间不提交,就会占用数据库连接。一旦类似的连接变得多了,就可能把数据库连接池撑爆。
而且,这种方式还是无法直接解决数据库单点和可重入问题,适合处理比较简单的分布式锁问题。
优点:简单,易于理解
缺点:会有各种各样的问题(操作数据库需要一定的开销,使用数据库的行级锁并不一定靠谱,性能不靠谱)
3.使用Redis做分布式锁
这个是我们后面要重点学习方式,做分布式锁是redis的一大强项。
这篇文章写的不错,我们直接参考啦!
3.1 redis实现分布式锁的基本原理
我们主要使用redis的setnx命令来实现。setnx是SET if not exists(如果不存在,则 SET)的简写。
先看一个例子:
127.0.0.1:6379> setnx lock value1 #在键lock不存在的情况下,将键key的值设置为value1 (integer) 1
127.0.0.1:6379> setnx lock value2 #试图覆盖lock的值,返回0表示失败
(integer) 0 127.0.0.1:6379> get lock #获取lock的值,验证没有被覆盖 "value1"
127.0.0.1:6379> del lock #删除lock的值,删除成功
(integer) 1
127.0.0.1:6379> setnx lock value2 #再使用setnx命令设置,返回0表示成功
(integer) 1 127.0.0.1:6379> get lock #获取lock的值,验证设置成功
"value2"
上面这几个命令就是最基本的用来完成分布锁的命令。
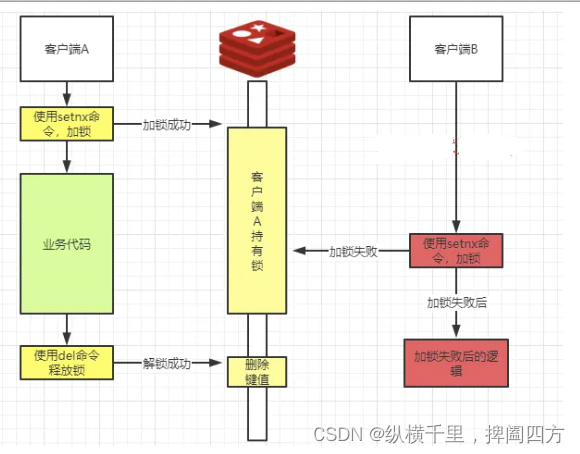
加锁:使用setnx key value命令,如果key不存在,设置value(加锁成功)。如果已经存在lock(也就是有客户端持有锁了),则设置失败(加锁失败)。
解锁:使用del命令,通过删除键值释放锁。释放锁之后,其他客户端可以通过setnx命令进行加锁。
key的值可以根据业务设置,比如是用户中心使用的,可以命令为USER_REDIS_LOCK,value可以使用uuid保证唯一,用于标识加锁的客户端。保证加锁和解锁都是同一个客户端。
那么接下来就可以写一段很简单的加锁代码:
private static Jedis jedis = new Jedis("127.0.0.1");
private static final Long SUCCESS = 1L;
/**
* 加锁
*/
public boolean tryLock(String key, String requestId) {
//使用setnx命令。
//不存在则保存返回1,加锁成功。如果已经存在则返回0,加锁失败。
return SUCCESS.equals(jedis.setnx(key, requestId));
}
//删除key的lua脚本,先比较requestId是否相等,相等则删除
private static final String DEL_SCRIPT = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
/**
* 解锁
*/
public boolean unLock(String key, String requestId) {
//删除成功表示解锁成功
Long result = (Long) jedis.eval(DEL_SCRIPT, Collections.singletonList(key), Collections.singletonList(requestId));
return SUCCESS.equals(result);
}上面代码加锁和解锁的基本原理是:
3.2 问题一:增加超时机制,防止长期持有的情况
上面过程其实仍然是有问题的,上面的过程仅仅满足上述的第一个条件和第三个条件,保证上锁和解锁都是同一个客户端,也保证只有一个客户端持有锁。
但是第二点没法保证,因为如果一个客户端持有锁的期间突然崩溃了,就会导致无法解锁,最后导致出现死锁的现象。

所以要有个超时的机制,在设置key的值时,需要加上有效时间,如果有效时间过期了,就会自动失效,就不会出现死锁。然后加锁的代码就会变成这样。
public boolean tryLock(String key, String requestId, int expireTime) {
//使用jedis的api,保证原子性
//NX 不存在则操作 EX 设置有效期,单位是秒
String result = jedis.set(key, requestId, "NX", "EX", expireTime);
//返回OK则表示加锁成功
return "OK".equals(result);
}

3.3 问题2:重入的问题
但是聪明的同学肯定会问,有效时间设置多长,假如我的业务操作比有效时间长,我的业务代码还没执行完就自动给我解锁了,不就完蛋了吗。
这个问题就有点棘手了,在网上也有很多讨论,第一种解决方法就是靠程序员自己去把握,预估一下业务代码需要执行的时间,然后设置有效期时间比执行时间长一些,保证不会因为自动解锁影响到客户端业务代码的执行。
但是这并不是万全之策,比如网络抖动这种情况是无法预测的,也有可能导致业务代码执行的时间变长,所以并不安全。
有一种方法比较靠谱一点,就是给锁续期。在Redisson框架实现分布式锁的思路,就使用watchDog机制实现锁的续期。当加锁成功后,同时开启守护线程,默认有效期是30秒,每隔10秒就会给锁续期到30秒,只要持有锁的客户端没有宕机,就能保证一直持有锁,直到业务代码执行完毕由客户端自己解锁,如果宕机了自然就在有效期失效后自动解锁。

但是聪明的同学可能又会问,你这个锁只能加一次,不可重入。可重入锁意思是在外层使用锁之后,内层仍然可以使用,那么可重入锁的实现思路又是怎么样的呢?
在Redisson实现可重入锁的思路,使用Redis的哈希表存储可重入次数,当加锁成功后,使用hset命令,value(重入次数)则是1。
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; "如果同一个客户端再次加锁成功,则使用hincrby自增加一。?
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);"
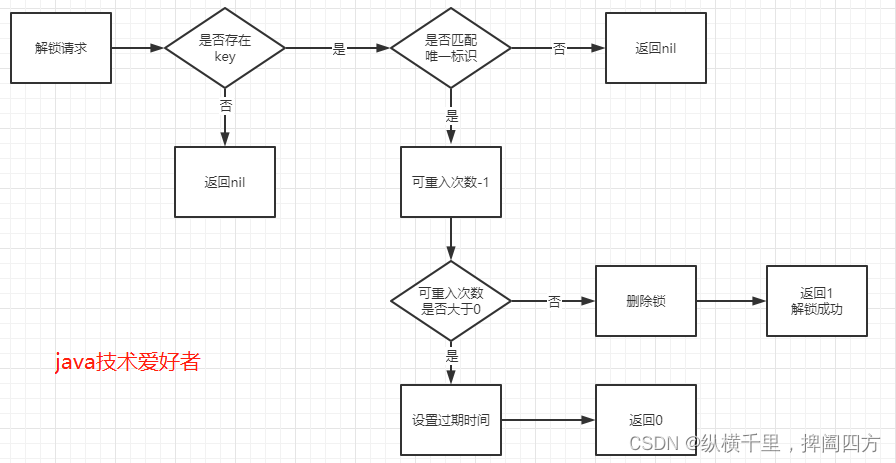
解锁时,先判断可重复次数是否大于0,大于0则减一,否则删除键值,释放锁资源。
protected RFuture<Boolean> unlockInnerAsync(long threadId) {
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +
"return nil;" +
"end; " +
"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +
"if (counter > 0) then " +
"redis.call('pexpire', KEYS[1], ARGV[2]); " +
"return 0; " +
"else " +
"redis.call('del', KEYS[1]); " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; "+
"end; " +
"return nil;",
Arrays.<Object>asList(getName(), getChannelName()), LockPubSub.UNLOCK_MESSAGE, internalLockLeaseTime, getLockName(threadId));
}
3.4 问题三:优化轮询加锁的问题
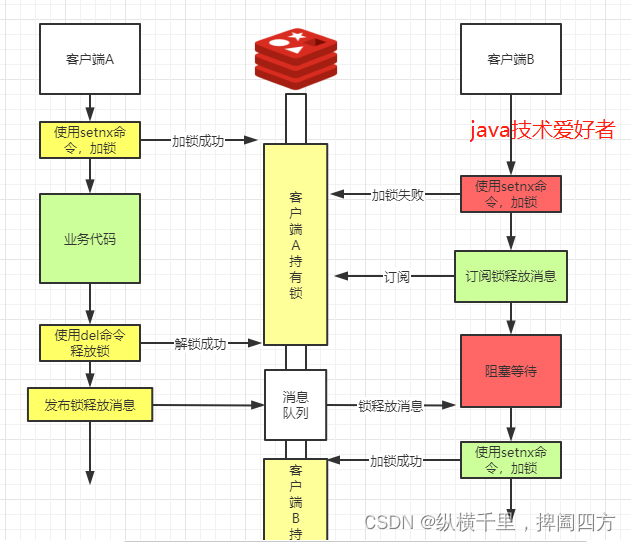
上面的加锁方法是加锁后立即返回加锁结果,如果加锁失败的情况下,总不可能一直轮询尝试加锁,直到加锁成功为止,这样太过耗费性能。所以需要利用发布订阅的机制进行优化。
步骤如下:
- 当加锁失败后,订阅锁释放的消息,自身进入阻塞状态。
- 当持有锁的客户端释放锁的时候,发布锁释放的消息。
- 当进入阻塞等待的其他客户端收到锁释放的消息后,解除阻塞等待状态,再次尝试加锁。
3.5?总结
以上的实现思路仅仅考虑在单机版Redis上,如果是集群版Redis需要考虑的问题还要再多一点。Redis由于他的高性能读写能力,所以在并发高的场景下使用Redis分布式锁会多一点。
上面的问题一,二,三其实就是redis分布式锁不断改良发展的过程,第一个问题是设置有效期防止死锁,并且引入守护线程给锁续期,第二个问题是支持可重入锁,第三个问题是加锁失败后阻塞等待,等锁释放后再次尝试加锁。Redisson框架解决这三个问题的思路也非常值得学习。
参考:阿里云开发者
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- WPF 导航界面悬浮两行之间的卡片 漂亮的卡片导航界面 WPF漂亮渐变颜色 WPF漂亮导航头界面 UniformGrid漂亮展现
- 流式湖仓增强,Hologres + Flink构建企业级实时数仓
- linux shell脚本 条件语句
- 天猫生意参谋的各模块功能
- 庙算兵棋推演AI开发初探(3-编写策略(下))
- 第二章习题回顾(谢希仁)
- 什么是迁移学习
- WAVENET: A GENERATIVE MODEL FOR RAW AUDIO
- Java面试题21-35
- Java自定义注解