【论文阅读】Non-blocking Lazy Schema Changes in Multi-Version
Non-blocking Lazy Schema Changes in Multi-Version Database Management Systems
1. Intro
1.1 Motivation
一个是online能够提供不停机的更新的能力,在很多业务系统里面是必要的。第二个是满足高可用,SaaS、PaaS要提供高可用的系统给用户,停机更新是不可以的。
高可用且不牺牲一致性的系统要有以下特点:
- 隔离级别:事务中不能发生schema view的变化,开始看到table什么样子就只能在这个基础上修改数据。
- 不允许对同一schema的DDL进行并发,一个事务想要修改schema,其他的txn不能同时修改这个schema。
- DDL和DML可以并发:其他事务可以在安装新模式的同时对表进行检索和更新。
- DDL txn commit之后其他事务才能看到这个新表的模式。
1.2 Contributions
- 三种不同的MVCC+schema的实现方式
- 对多版本内存数据库提供了一个非阻塞的实现。
- 和Blocking进行了性能对比
- 在具有热点的数据库中,从模式更新导致的性能下降中快速恢复性能。
2. Background
该领域的研究已经提出了几种替代解决方案,如查询重写[8]、模式版本控制和时态查询[20,29]、模式租赁[35]、模式映射[41,45]或模式匹配[36]。然而,这些解决方案提供的灵活性必须与潜在的成本和操作限制进行权衡。例如,在某些系统中,重写的查询会带来永久性的开销,并且平均比原始查询慢4.5倍[8]。这种解决方案对于性能关键的在线应用程序的适用性可能有限。
本研究的目的是通过为多版本数据库系统存储多个版本的数据表,提供非阻塞模式更改的高性能实现。
2.1 Multi-Version Concurrency Control
事务的四个属性,ACID中,隔离性决定了事务的完整性对其他user或者系统的可见性,最简单的是用锁,但是锁会导致争用,尤其是在长读事务和更新事务之间,这一点在MDL中讨论过很多了。
2.1.2 Isolation Levels
隔离级别定义并发事务执行期间可能发生的异常。
- 最高隔离级别serializable只允许并发执行的事务的操作产生与串行执行相同的效果。
- 最低隔离级别(读取未提交)可以检索已被修改但未被其他事务提交的数据。
- 快照隔离(Snapshot isolation, SI)是一种隔离级别,它保证在事务中进行的所有读取都能看到数据库的一致快照,并且只有当事务本身所做的更新与自该快照以来所做的任何并发更新没有冲突时,事务本身才能成功提交。在使用SI进行并发控制的DBMS中,读不会因为并发事务的写而阻塞,读也不会导致写事务的延迟。SI允许非可串行化执行,会导致写倾斜(本地事务设计(5)-写倾斜与幻读到底是什么? - 知乎 (zhihu.com))。可串行快照隔离(Serializable Snapshot Isolation, SSI)[4]是一种可串行化的并发控制算法,它使SI可串行化。在一定条件下,整体事务吞吐量接近于SI所允许的吞吐量,并且远远优于严格的两阶段锁定。
2.1.4 Indexing in MVCC
索引中某个键的存在意味着该键的某个版本存在,但索引项不包含有关元组的哪个版本匹配的信息。index value is pointer,指向数据项的版本链。
Primary Key需要指向元组的当前版本,然而,DBMS更新主键索引的频率取决于它的版本存储方案是否在元组更新时创建新版本。对于二级索引,情况更加复杂,因为索引条目的键和指针都可以更改。
MVCC DBMS中二级索引的两种管理方案在这些指针的内容上有所不同。第一种方法使用逻辑指针间接映射到物理版本的位置。DBMS使用固定的标识符,该标识符不会对其索引条目中的每个元组更改。这样就避免了在修改元组时必须更新所有表索引以指向新物理位置的问题,但是由于索引没有指向确切的版本,因此DBMS从HEAD遍历版本链以查找可见版本。
第二种方案,DBMS将版本的物理地址存储在索引项中。当更新表中的任何元组时,DBMS将新创建的版本插入所有二级索引中。通过这种方式,DBMS可以从辅助索引中搜索元组,而无需将辅助键与所有索引版本进行比较。
2.2 System Overview
原型系统Terrier,CMU自己开发的内存数据库。
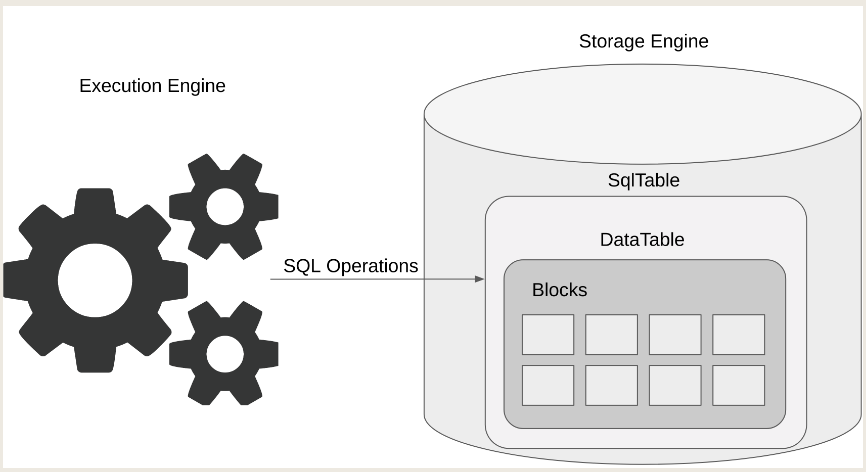
2.2.1 Storage Engine
在Terrier中,存储引擎与执行引擎是分离的,pluggable。该系统将存储层与并发控制系统和垃圾回收机制集成在一起。它实现了内存中的MVCC[27],具有增量存储,newest-to-oldest and in-place updates。
增量存储:DBMS在主表维护元组的master versions,在单独的增量存储中维护一系列增量版本。在mysql和oracle中叫做回滚段。
Newest-to-oldest:DBMS将元组的当前版本存储在主表中。为了更新现有的元组,DBMS从增量存储中获取一个连续空间,用于创建新的增量版本。这个增量版本包含修改属性的原始值,而不是整个元组。然后,DBMS直接对主表中的主版本执行就地更新。
存储引擎中的DataTable和SqlTable。DataTable实现了MVCC,它由内存块组成。SqlTable是DataTable的包装,它支持SQL操作。
-
DataTables
datatables就行blocks连起来,代表系统中的物理表,实现了MVCC支持事务,因此事务可以看到同一元组不同的值,给定dataTable和txn,可以判断可见性。
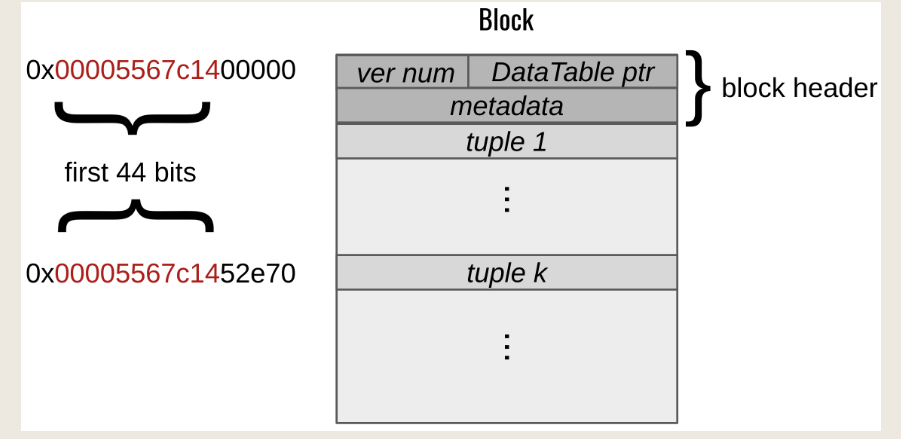
Block结构:Terrier在块头中存储了一个版本号,该版本号是为多版本模式保留的。它还存储一个指向该块所属的DataTable的指针。系统使用其余元数据来解释块的布局。
-
SqlTables
SqlTable是datatable的封装,提供sql操作的接口,它是事务访问表中存储的数据的入口点,负责事务和DataTable之间的通信。它作为数据库中存在的逻辑表。sqtable支持以下SQL操作:
- select
- insert
- update
- delete
- scan
最初一个sqltable 包含 一个datatable,需要全表加锁,进行swap实现更新新表。
每个元组系统维护一个undo log list,这就是一个无锁的版本链。Terrier中的目录表本身就是sqtables,是txnal的,
为了在MVCC中保持必要的版本数量,系统需要删除不再使用的版本。这个过程称为垃圾收集,garbage collection。记录的时间戳小于活动快照的时间戳,标记为候选,进行安全的删除。在terrier里面,GC作为一个后台线程会定期轮询来回收已经完成的事务。
3. Non-Blocking Schema Change
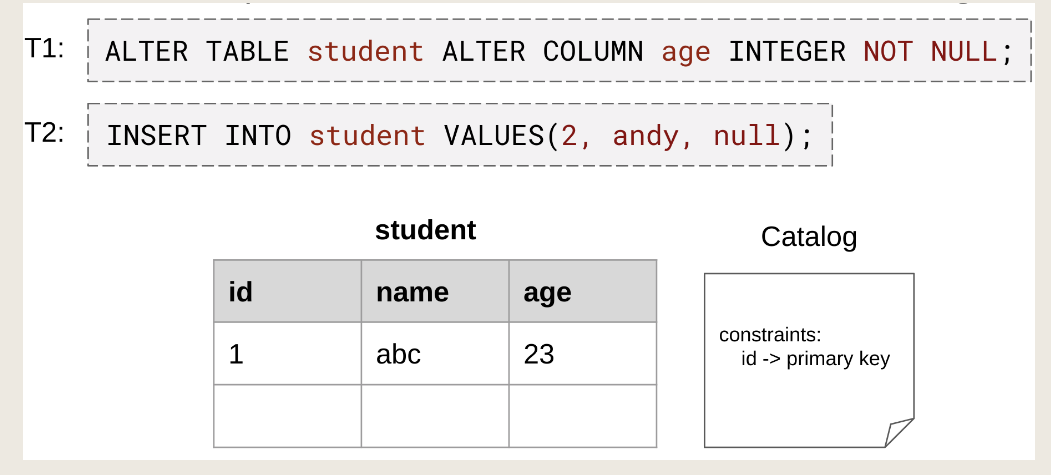
讨论如何在多版本dbms中实现数据表和sqtable的非阻塞模式更改。—Lazy schema change method:不从旧模式复制到新模式,只是创建新的空块然后返回,但是不填充,在后续的操作中进行迁移。
3.1 Design
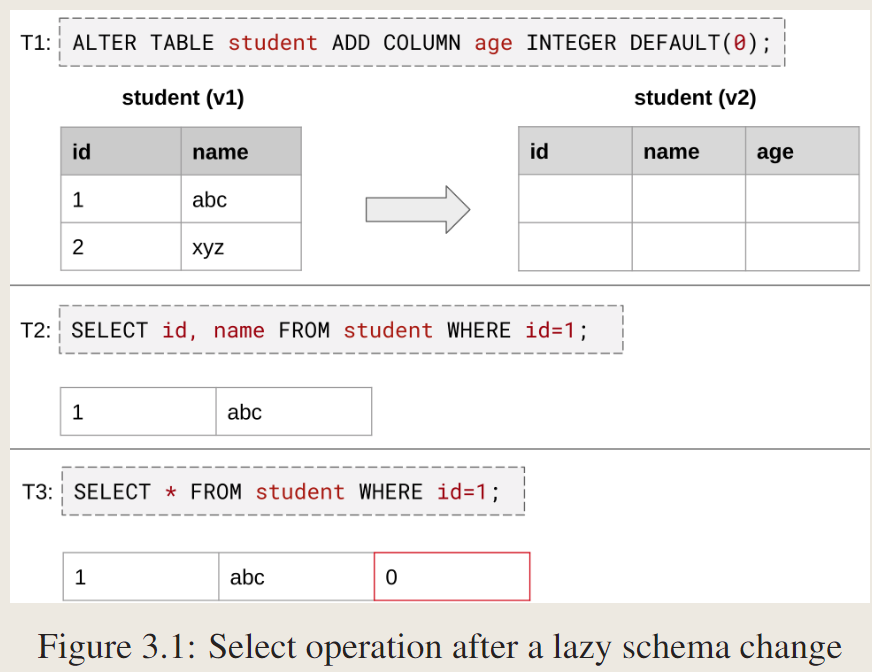
对select:模式更改事务添加第三列age,默认值为0,T2查询系统检测到id和name是前一个模式中的属性,因此它从旧表中检索值并返回。T3首先从旧表中检索前两列的值,系统知道第三列的默认值为0,动态追加0,然后返回。第二个物理表仍然是空的,未动过。
对update:
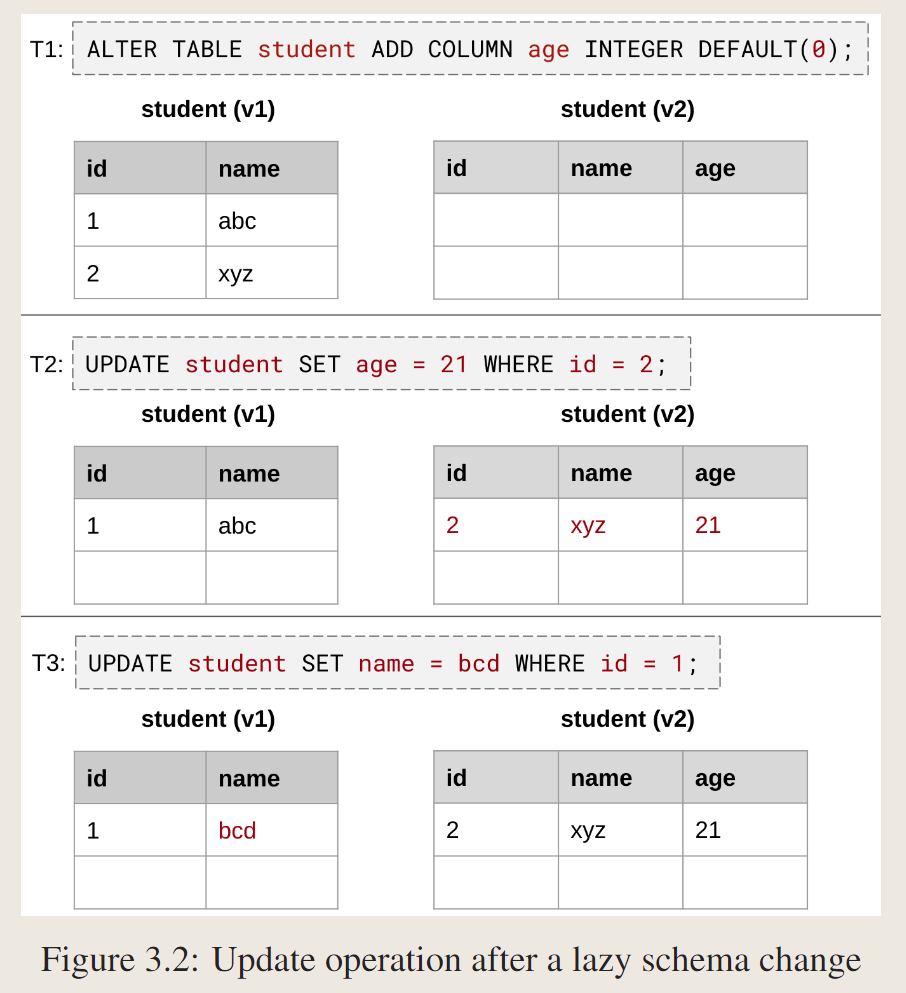
T2只能按照新表schema来更新,更新后的tuple到新表,T3可以在原表上更新。应用程序驱动数据迁移,因为系统只迁移事务触及的元组。
3.1.1 Multiple DataTables in SqlTable
相比大多数通过用新模式创建一个新表,并将元组从旧表移动到新表来实现阻塞模式更改。在迁移过程中,这两个具有不同模式的物理表共存,但是它们都不能被事务访问或修改。在迁移过程中,这两个具有不同模式的物理表共存,但是它们都不能被事务访问或修改。惰性模式更改是该迁移过程的一种relax。它允许事务同时访问不同模式的多个物理表。
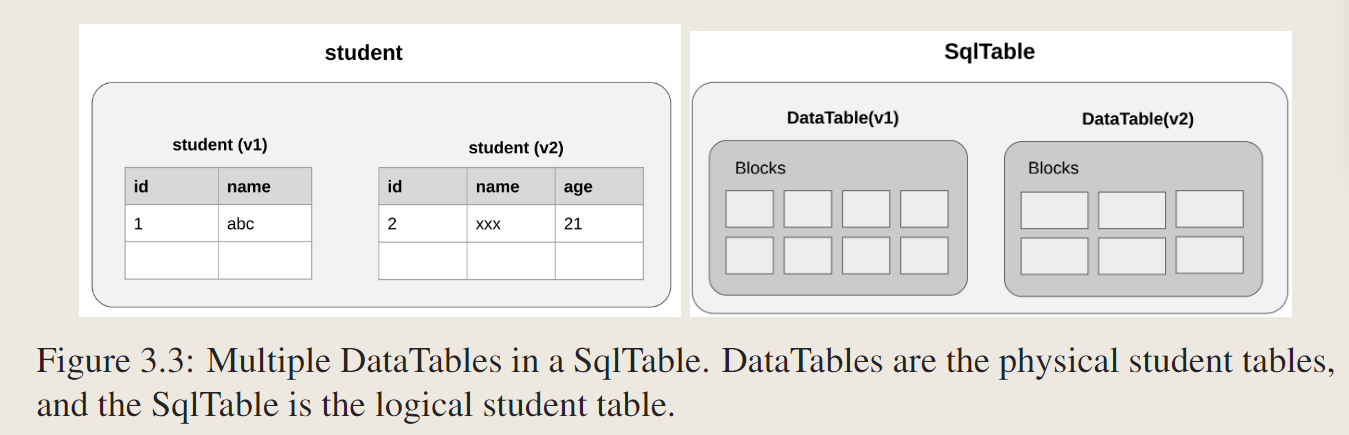
系统有两个版本的物理表(DataTables),具有两个完整的模式,但只有一个逻辑学生表(SqlTable)。
3.1.2 Version Table in Catalog
为sqtable开发一种机制,将适当版本的datatable公开给事务。
在catalog中维护version table,记录了表和对应的versions。catalog table是实现事务性的sqltable,可以让事务看到不同版本的表,事务id+访问表的版本号传递给sql Table。事务可以缓存对应的表的版本号。
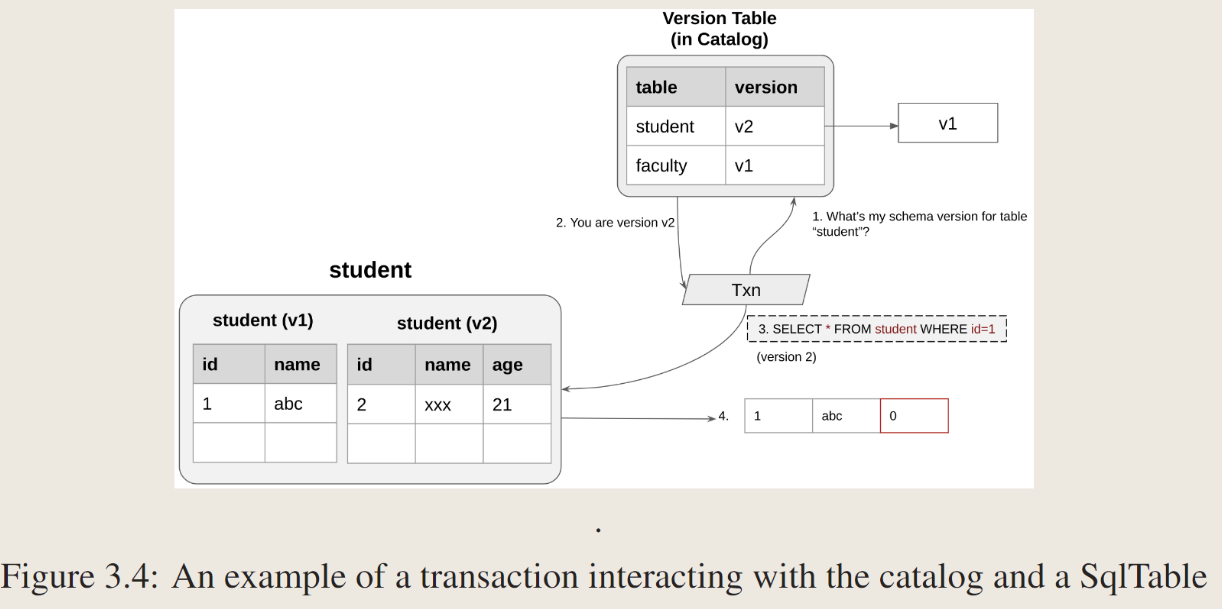
一个事务试图select student table
- 访问catalog的version table来获取student表的版本号
- v2
- 发给sqltable请求,version=v2
- sqltable检索v1中的数据转化为模式v2,返回(1,abc, 0)
version translation:the process of transforming a tuple from one schema version into another schema version
3.1.3 Physical Addresses in Indexes
R是table,T是txn。
- txn version:是事务T从catalog的版本表中获取的R的version
- addr version: 在datatable中拿到的version号。
version mismatch是指:事务提供的地址 address_version和txn_version不匹配。
-
Version Mismatch: addr version less than txn version
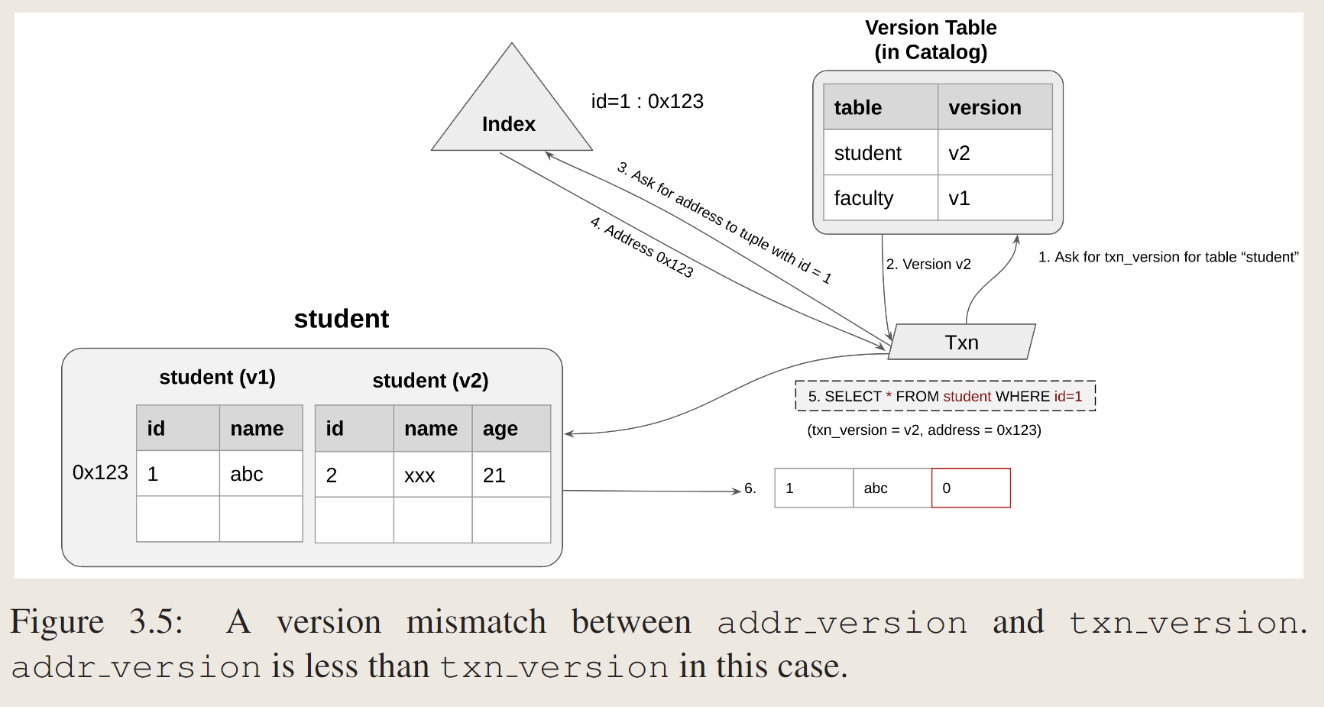
- 事务查询version table 得到student表的txn_version
- v2
- 通过index 得到tuple id = 1的地址
- 返回address = 0x123,123其实是v1的地址。
- Txn_version = v2,address = 0x123,查询datatable
- 此时txn_Version = v2,addr_version = v1,不匹配,且address_Version < Txn_Version说明tuple位于旧版本的dataTable中。
-
Version Mismatch: addr version greater than txn version
这种情况不会发生,索引不能返回addr版本大于txn版本的地址。
如何保证的呢?
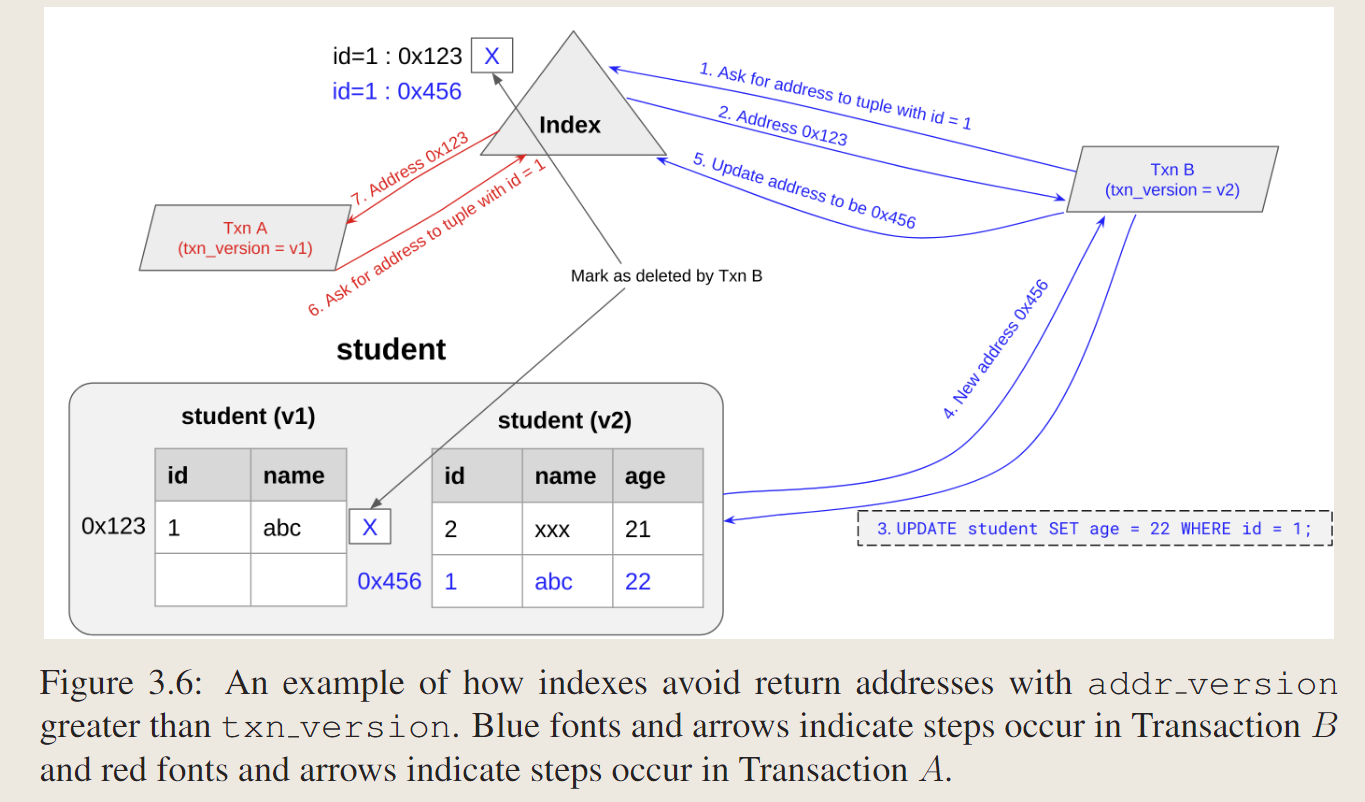
- 背景:事务B是在模式更改后启动的事务,因此它看到第二个模式。TransactionA是在模式更改之前启动的事务,因此它仍然看到第一个模式。
- txn B修改id =1的tuple,事务B更新元组,并导致SqlTable通过逻辑删除v1中的元组并将元组插入v2来将元组从v1迁移到v2。SqlTable将新地址0x456返回给事务B,事务B用新地址更新索引。索引标记要被事务B逻辑删除的旧键-值对,并插入新的键-值对。
- 事务A请求id=1的元组的地址。索引检测到旧地址对事务A仍然可见,而新地址对事务A不可见,因此它返回旧地址0x123,地址版本为v1,然后事务A仍然可以访问旧元组,即使它被事务b标记为删除。因此,索引永远不会返回地址版本大于txn版本的地址
3.2 Implemention
事务可以通过从索引获得的物理地址访问元组,即addr_version,事务有一个txn_Version,index确保addr_version ≤ txn_Version。根据两个版本是否匹配,操作将转到不同的代码路径。如果txn version等于addr version,则表示元组以与模式的事务视图一致的形式存储。另一方面,如果txn版本大于addr版本,则元组位于具有旧模式的DataTable中。SqlTable执行版本转换,并在必要时将元组移动到较新的DataTable。
-
select
如果txn版本等于addr版本,SqlTable知道该地址属于具有预期模式的数据表,因此它直接从该数据表检索元组并将其返回给事务。
如果txn版本大于addr版本,则意味着所需元组驻留在具有旧模式的DataTable中。在从旧的DataTable中检索元组之后,SqlTable在返回到事务之前执行版本转换,将元组转换为预期的模式,方法是填写新模式中存在的列的值,删除新模式中不存在的列的值,并在必要时附加默认值。
-
Update
如果txn version大于addr version,则它确定事务修改的属性集是否是旧模式和新模式的子集。如果事务只修改两个模式相交处的属性,那么SqlTable将更新旧DataTable中的元组。否则,它删除旧数据表中的元组,将元组复制到新数据表中,并直接在新数据表中更新元组。迁移之后,元组将保留在DataTable中,在事务的其余部分使用正确的模式版本。
3.2.2 SELECT Migration Policies
当它访问仅包含在新模式中的列时,根据版本转换后SqlTable是否将元组移动到新版本的DataTable中,有两种迁移策略:
- Migration on Reads:只要进行过version translation之后就迁移到新模式
- Migration on Writes:只有update才进行迁移。
3.2.3 Single-Version Cache
一个SqlTable内部维护一个从版本号到数据表的映射。它添加了一个间接层来查找正确的DataTable。
3.3 Unsafe Schema Changes
ADD CONSTRANT可能是unsafe的schema change,比如一个事务加列的约束,一个向该列插入符合old schema的数据,就会出现问题。
3.3.1 Serializable Isolation Level
如果能保证SI或者SSI,则不会有问题。其实只需要schema change txn和其他任何并发事务能够保证可串行化即可,其他事务之间可以更低的隔离级别,比如快照隔离。本文自己实现了一个一致性检查,只强制模式更改事务和任何其他并发事务之间的序列化性。此外,这些检查仅在运行模式更改事务时存在。因此,它们以低开销保持快照隔离所允许的高并发性。
3.3.2 Invariant and Consistency
三步来解决这个问题
-
Step I: T1 Refreshes Its Timestamp
- 左边是有问题的调度,T1不会看到T2的修改,解决:T1刷新自己的时间戳,然后scan check。

-
Step II: T2 Check Pending Constraints During Commit
- 仅用step1是不够保证一致性的,出现下面左边这种情况,T1加完约束T2才开始,而且T1 check完了 T2才插入,刚好都提交了。
- 添加一个特殊的数据结构:pending constraint list,<constraintion, bool>,T1不仅加constraint到catalog,也同时加到pending list,当T2进入commit phase的时候:
- check pending list
- 把T2违反的约束的violate flag设置为true?
- 提交T2
- 当T1commit的时候
- 检查约束里面的violate flag
- 如果这个violate flag set了,就说明T1需要abort了。
- 否则commit
这种设计使用了先提交者获胜的策略。

-
Step III: T1 Enforces Constraints During Commit
- 该步骤主要解决如果DDL在和冲突的DML之前先提交的情形,T1先check,没问题提交了,T2才进行check,也会正常提交。
- 在pending list 里面加一个enforce flag,(constraint, violation flag, enforcing flag).
- 当T1提交时,约束不再挂起,应该对所有新事务和并发事务强制执行。提交时,T1
- 检查violate flag
- 如果,abort
- 否则,set enforcing flag,然后commit
- T2提交的时候
- check pending list
- 如果违反enforced constraint,abort
- 否则,设置violate flag
- commit

3.3.3 Execution Steps
系统中,任何时候对某个表最多有一个schema change txn进行。

3.3.4 Pending Constraint List
当不安全的事务abort,版本表和约束的修改可以自动回滚,因为他们是sql table实现了回滚语义,但是对挂起列表的更改要手动回滚。
当schema changing txn终止,删除pending list里面的约束。
schema changing txn commit,在mvcc中接受一个commit 时间戳写到约束上,作为pending list的enforce check。
并发事务只检查带enforce flag的或者是commit ts在自己begin ts之后的约束。
在提交的模式更改事务之后开始的新事务不需要检查其约束。这些强制约束变得过时,垃圾收集最终会清除它们。
3.4 Alternative Designs
3.4.1 Global DataTable Approach
global table维护了一个table,dt_address,后者是指向DataTable的指针。
给定一个事务,SqlTable可以查找这个全局表并检索指向具有正确模式版本的DataTable的指针。
为了检索存储在以前的数据表的元组,它遍历版本链来找到指向旧数据表的指针,因为Terrier中的数据表是用2.2.1节描述的从最新到最老的增量链实现的。这个全局表不需要是持久的。如果系统重新启动,所有的地址信息都是无效的,系统需要用新地址填充它。
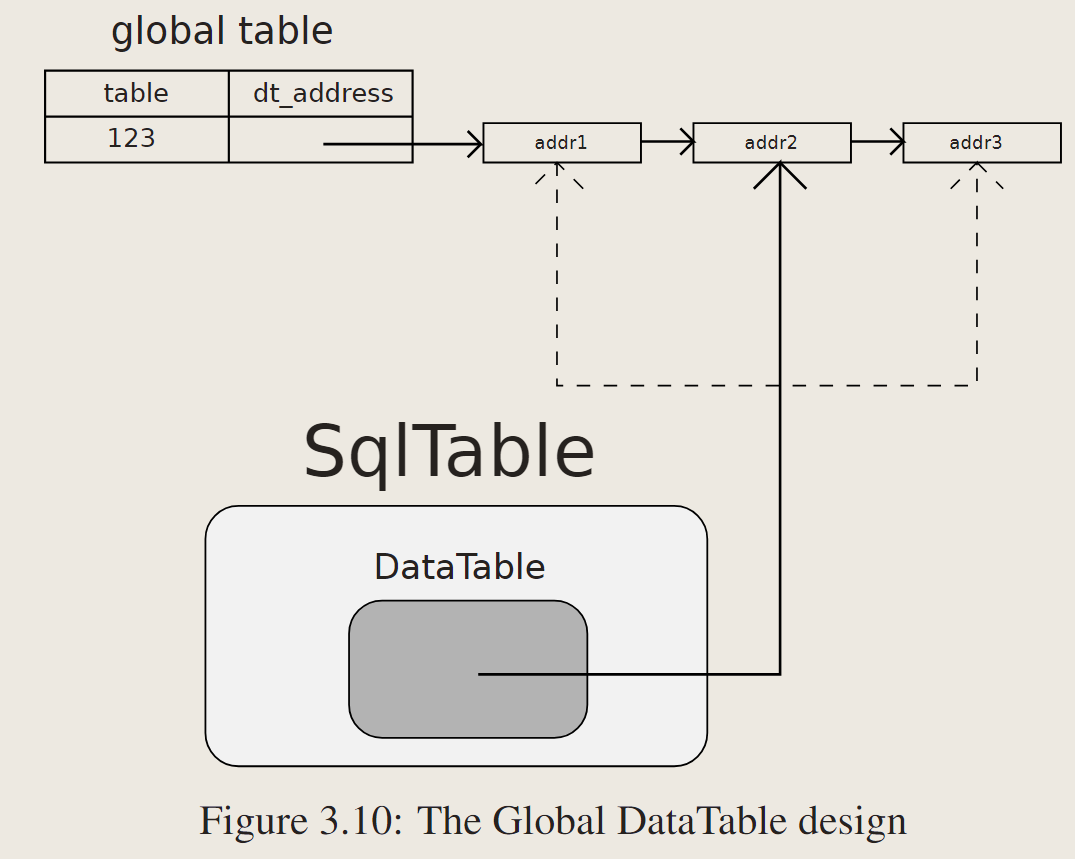
这种是把dt 当作物理表,sqltable当作逻辑表。事务可以直接获得dt的指针。
因为如果一些元组存储在旧模式中,单个事务可能需要多个DataTable指针,所以设计要求事务可以看到多个版本并遍历版本链。带快照隔离的MVCC不支持此功能。即使SqlTable可以遍历版本链,当版本链很长时,它也会产生性能开销。
另一个缺点是:GC管理增量记录,删除无人访问的记录之后,可能会丢失这些仍然有有效tuple的旧表的地址。
3.4.2 Multi-Block Approach
允许DataTable具有多个不同模式头的块。
最初,DataTable维护一个用于在同一模式中存储元组的块列表。与这种设计形成对比的是,DataTable维护多个块列表,每个块在单独的模式中存储元组。
系统为每个表分配一个版本号,以便DataTable可以识别正确的块集。
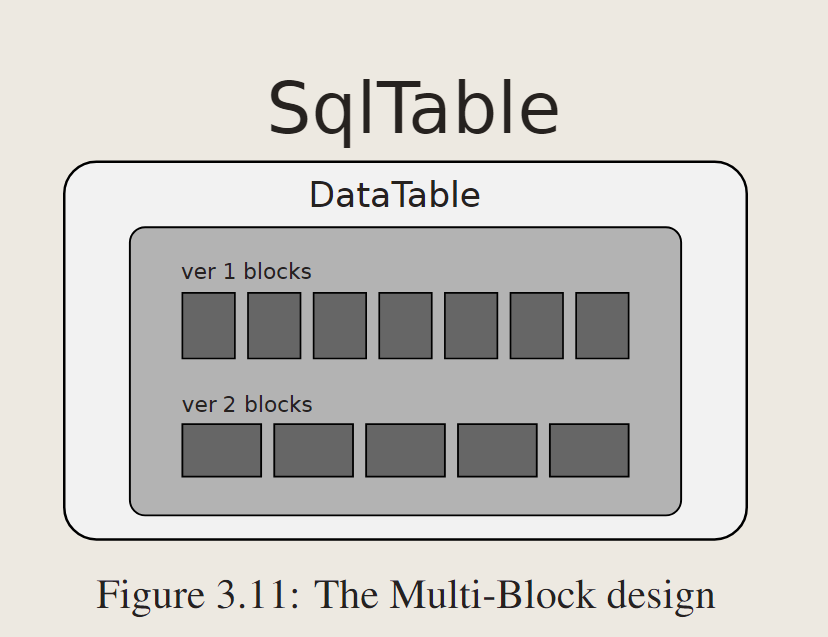
这种方法将多版本控制的逻辑推到物理表级别,因此SqlTable不需要维护映射。此外,它更节省空间,因为系统只创建一个块,而不是为模式更改创建一个新表。
它打破了每个DataTable代表一个模式的物理表的假设。将所有逻辑推到块级别可能会降低系统速度,因为当只有一种类型的块时,可以在DataTable中进行许多优化。例如,如果只有一个块列表,DataTable可以使用比较-交换指令在开始处附加一个块。否则,DataTable需要一个锁存器来保护多个块列表,这可能会导致性能损失。
4. Evaluation
4.2.1 SQL Operation Performance
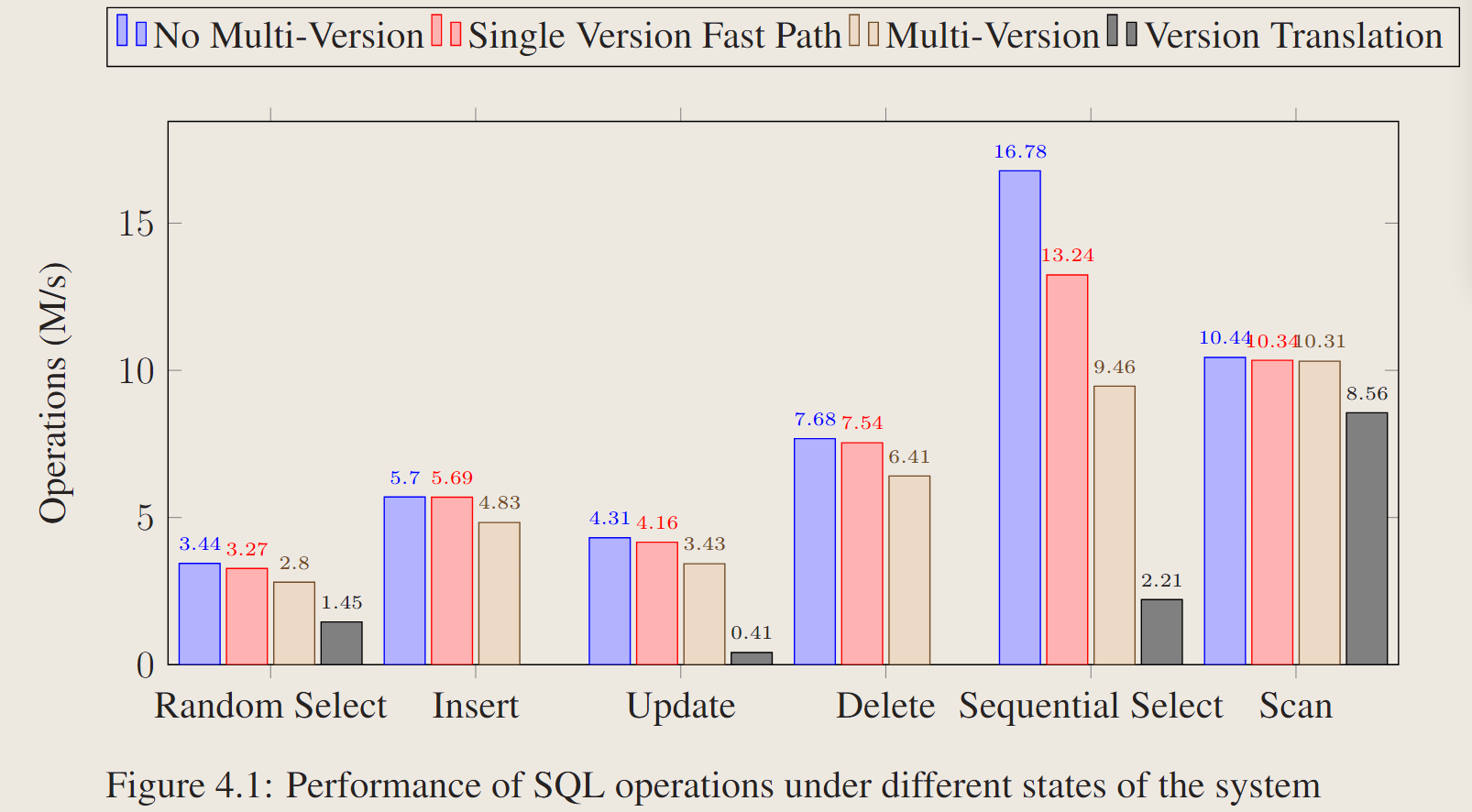
- No Multi-Version:这是系统没有惰性模式更改实现时的性能。
- Single Version Fast Path:这是实现lazy schema change,然后只有一个schema version的情况
- Multi-Version: 这是表有两个模式版本,并且所有元组都迁移到最新版本时的性能。
- Version Translation:这是表有两个模式版本时的性能,并且所有元组仍然在旧的DataTable中,在这种情况下,选择和更新元组都需要进行版本转换。
4.2.2 Performance Overhead
测试schema change txn对Update事务的影响。
表填充1000万条数据,10列8byte int
- No schema change:没有模式更新
- Uniform Data Access: 每个Update事务统一更新1000万个元组中的一个元组
- Hotspot: 5%的数据是表内的热点数据,每个update事务 80%概率更新热点,20%更新冷点。
- Blocking:系统执行阻塞模式更新。当模式更新发生时,它会锁定表,阻塞所有正在运行的事务。它将元组从旧表复制到新表并释放锁。
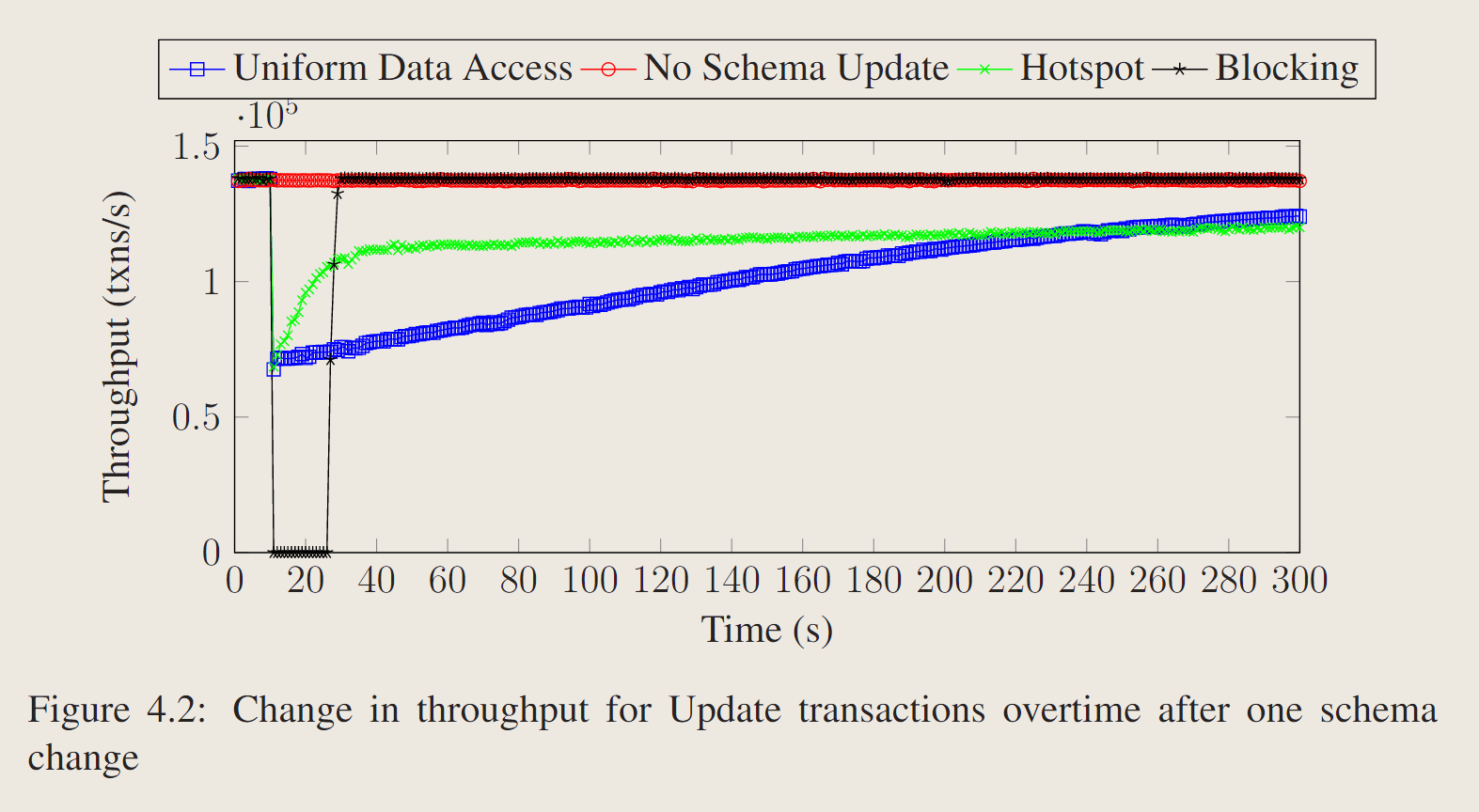
模式更新最初会降低吞吐量,因为对旧DataTable中元组的update操作需要版本转换。随着越来越多的元组移动到最新的DataTable,我们观察到吞吐量逐渐增加。
蓝色和绿色相比,表明具有热点的表从性能下降中恢复的速度要快得多。
5分钟后,在统一数据访问情况下,系统将大约94%的元组移动到新的DataTable中,在热点情况下,系统将52%的元组移动到新的DataTable中。(可能是lazy处理下,只用了hotspot的data,所以相对百分比少)
4.2.3 High-Frequency Schema Change
表最初填充了1000万个元组,这些元组由两列8字节长的整数组成,具有5%的热点。
工作负载由三种类型的事务组成:选择事务、插入事务和更新事务。基准测试每隔10/50/100毫秒触发一次模式更改,并在120秒内测量平均吞吐量。比较惰性模式更改和阻塞模式更改。
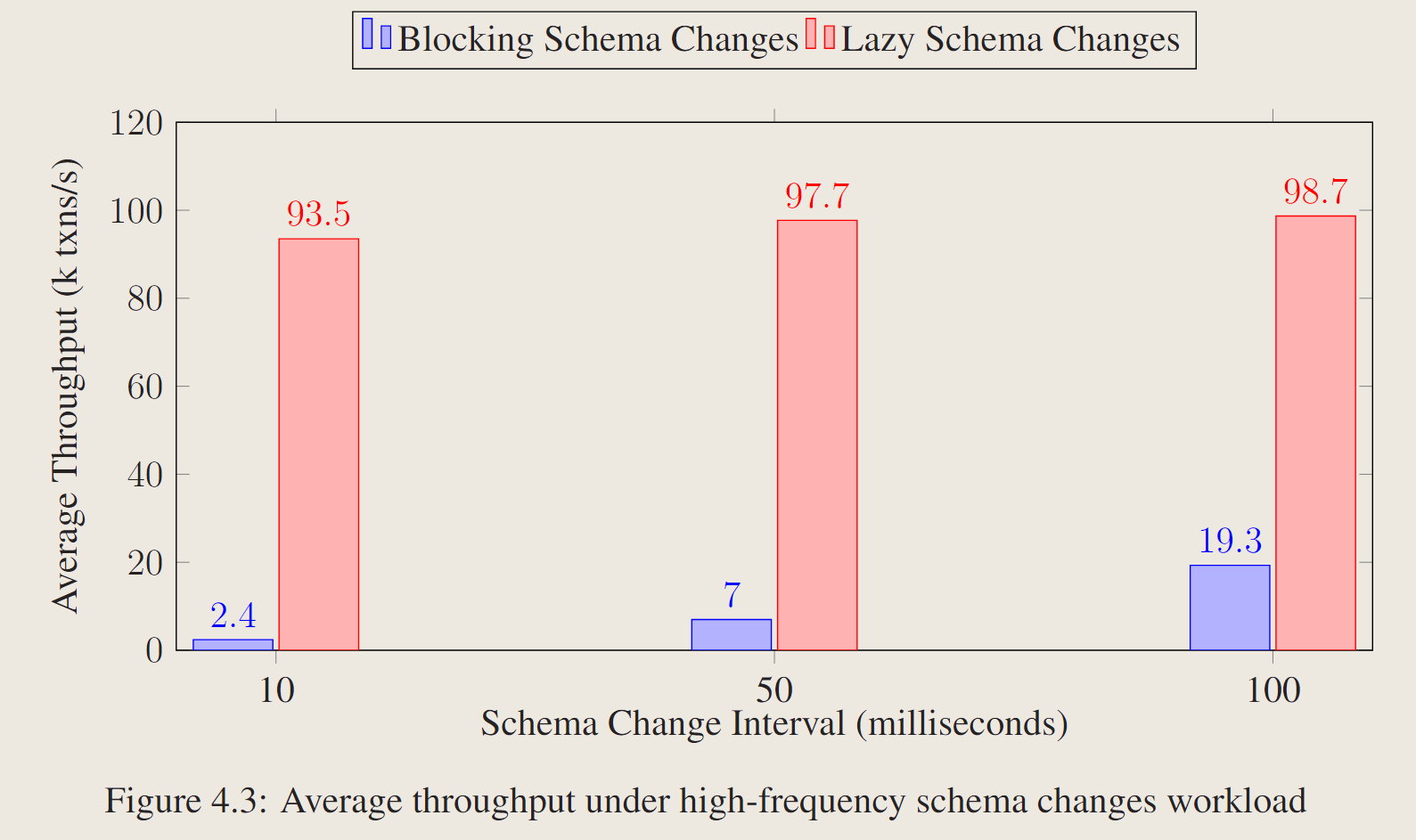
10ms一次schema change,性能约为40倍。
5. Related Work
5.1 Existing Systems
-
MySQL 8.0
MySQL存元数据在InnoDB存储引擎中,它将catalog作为字典表上的view实现,从而允许对catalog查询进行优化。
消除了在动态执行期间为每个Catalog查询创建临时表和扫描文件系统目录等成本。
支持instant,ADD COLUMN、Change index option、Rename table、SET/DROP DEFAULT、MODIFY COLUMN和ADD /DROP virtual columns。
mysql的non-blocking的 schema changes是在data dictionary上进行的,不需要获取锁,因为底层数据没有更改。每个record都有一个flag存在info_bits,使用info_bits来track record是否在第一个即时ADD COLUMN之后创建。
发出instant add column后,更新都会按照新模式来写,和lazy恰恰相反。
非阻塞操作在MySQL 8.0中是有限的。它只支持在一条语句中添加列,也就是说,如果同一语句中有其他非instant操作,则不能立即完成。此外,它只支持最后添加列,而不是在现有列的中间添加列,而我们的方法允许在中间添加列或重新排列列,因为它使用新模式创建了一个新表。
-
PostgreSQL 11
PostgreSQL 11将模式信息存储在catalog中的pg_tables中。PG中schema change都是阻塞的,设计了好多锁,然后锁表来处理。在DDL和DML操作之间没有并发性。在执行DDL操作时,该表不可用,这会导致停机。
-
MemSQL 6.7
MemSQL是一种分布式的、内存的RDBMS。支持online的alter table,每个node都存着schema infos。
MemSQL 6.7 supports online ALTER TABLE as it does not require doubling the disk or memory use of the table while executing, does not lock the table or prevent querying it for long periods, and does not use excessive system resources.
即memsql不需要锁表,他只使用一个short-lived表锁来lock 每个节点metadata,当然是分布式锁,需要同步,以便它们可以同时开始显示新列。在元数据更改时设置新的内存空间,以便为新的表模式分配行。它通过动态生成默认值来服务SELECT查询。写查询将新行插入到新表和旧表中。一个单独的线程开始将行数据从旧格式迁移到新格式。相比本文:1. 本文的方法可以在旧内存空间中写入更新 2.本文方法中的迁移过程是由工作负载驱动的,而不是由单独的线程驱动的。
MemSQL不支持ALTER TABLE启动后的回滚。因为它需要分布式锁来更改元数据,所以可能需要等待长时间运行的查询完成才能获取锁。
5.2 Research
-
Schema Evolution Benchmarks
17130.pdf (scitepress.org)SCHEMAEVOLUTIONINWIKIPEDIA TowardaWebInformationSystemBenchmark.第一个基准测试是针对支持软模式更改的系统,它允许新事务和旧事务(即基于旧模式版本的事务)并发地访问同一个数据库。它还包含使用任何模式版本访问数据库的real and synthetic查询。
第二个基准测试是针对支持硬模式更改的系统,它在模式更改事务提交后中止任何旧事务[A Benchmark for Online Non-blocking Schema Transformations]。它基于作为存储过程实现的TPC-C[7]工作负载。第二个基准测试的目标是并发地运行数据定义语言(DDL)和数据操作语言(DML)操作,同时最小化模式更改对TPC-C事务的性能影响。每个模式更改事务包括修改模式的DDL操作,以及更新存储过程以使TPC-C事务适应新模式。
-
Online Schema Evolution Through Query Rewriting
查询重写-PRISM:自动重写访问旧版本模式的遗留查询,以适应模式的最新版本。它不保留以前模式版本中的旧数据。换句话说,每次用户更新模式时,都会进行数据迁移,但它会将所有模式更改保存在单独的元数据DB中。但是,它不支持读取历史记录或临时查询,并且重写的查询运行时会产生永久性开销,平均速度比原始查询慢4.5倍。
PRIMA:它将历史数据和历史模式信息存储在单独的面向文档的数据库中,以支持临时查询,同时在关系模型中维护当前或快照数据库,以支持常规查询。用户仅基于当前模式版本表达查询。然后PRIMA自动将这个输入查询转换为针对所有适用模式版本的等效查询,并针对这些模式底层的数据库执行这些查询。这种方法的一个缺点是,在计算模式版本之间的映射时,系统在每次模式更改时可能出现长达30秒的响应滞后
-
Online Schema Evolution Through Copying
Lazy Copying:允许在实际模式更改完成之前提交模式更改事务。虽然系统可能没有将数据移动到新的模式,但是访问数据的查询不会被阻塞。这些查询动态地将数据转换为新的格式。系统生成一个线程,在后台将元组从旧模式转换为新模式。这种方法的一个缺点是,每次模式更新都会在后台迁移整个表。当表的模式频繁更改时,这样做的效率太低。(不是负载驱动)
External Tools: 建了一个在dbms之上运行的工具,当迁移到新模式版本时,它可以在单个事务中创建新表并复制旧表中的所有数据。它在旧表上添加触发器,以避免丢失对数据的任何并发更新。
6. Conclusion and Future Work
conclusion:
- 提出了MVCC 的 non-blocking的schema change,即lazy schema change,这种方法根据需要将元组从旧表惰性地迁移到新表,它依赖于在SqlTable中维护多个datatable,并在catalog中保留一个version table。
- 讨论了ddl txn 和 dml txn的隔离级别,以及需要模式更改事务和任何其他并发事务之间的序列化性,以避免不安全的模式更改造成的不一致,但它允许并发的非模式更改事务在系统先前设置的较低隔离级别下继续运行。
- 性能上,hotspot tuples的性能恢复很快,尽管希望通过多版本进行非阻塞模式更改,但应该注意维护单版本常见情况下的性能。
future work:
- 集成表迁移技术
- 版本压缩,缩小模式版本链,以便可以清理多版本表并返回到单个版本状态。使用机器学习来智能地确定何时进行版本压缩
- 当工作负载驱动数据迁移时,评估不同的迁移策略。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Hadoop集群环境下HDFS实践编程过滤出所有后缀名不为“.abc”的文件时运行报错:java.net.ConnectException: 拒绝连接;
- 机器学习中的过采样和欠采样
- WEB前端demo3
- NAS下2023年最常用的Docker服务
- Postman 如何传递 Date 类型参数
- GitHub Copilot 快速入门指南
- 海外市场调研为什么要用独享静态代理IP?
- java数组在多线程中安全问题,HashMap是不安全的,Hashtable安全(但每次都加锁,效率低),ConcurrentHashMap完美
- 读取colmap中database.db里的匹配结果,并且写入images.txt和point3D.txt
- 【Qt】对象树与坐标系