FPGA时序分析实例篇(下)------底层资源刨析之FDCE和Carry进位链的合理利用
声明:
本文章部分转载自傅里叶的猫,作者猫叔
本文章部分转载自FPGA探索者,作者肉娃娃
本文以Xilinx 7 系列 FPGA 底层资源为例。
?FPGA?主要有六部分组成:可编程输入输出单元(IO)、可编程逻辑单元(CLB)、完整的时钟管理、嵌入块状RAM、布线资源、内嵌的底层功能单元和内嵌专用硬件模块。其中最为主要的是可编程输出输出单元、可编程逻辑单元和布线资源。这些逻辑单元的内部结构像大型“停车场”。

可配置逻辑单元
????可配置逻辑单元(Configurable Logic Block,CLB)在 FPGA 中最为丰富,由两个 SLICE 组成。由于 SLICE 有?SLICEL(L:Logic)和 SLICEM(M:Memory)之分,因此 CLB 可分为 CLBLL 和 CLBLM 两类。
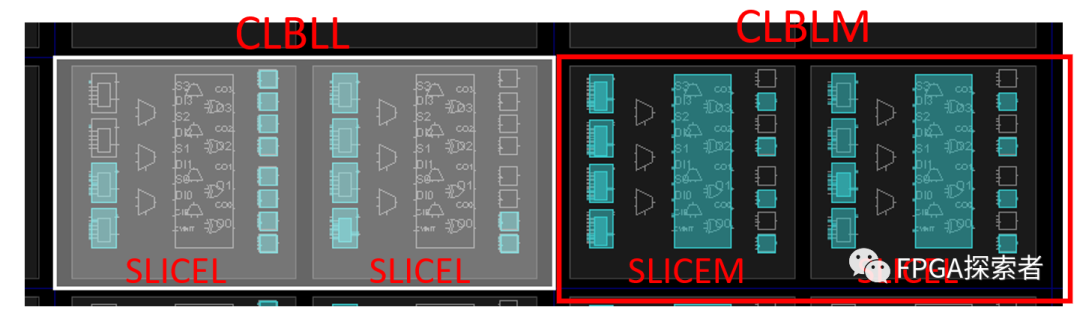
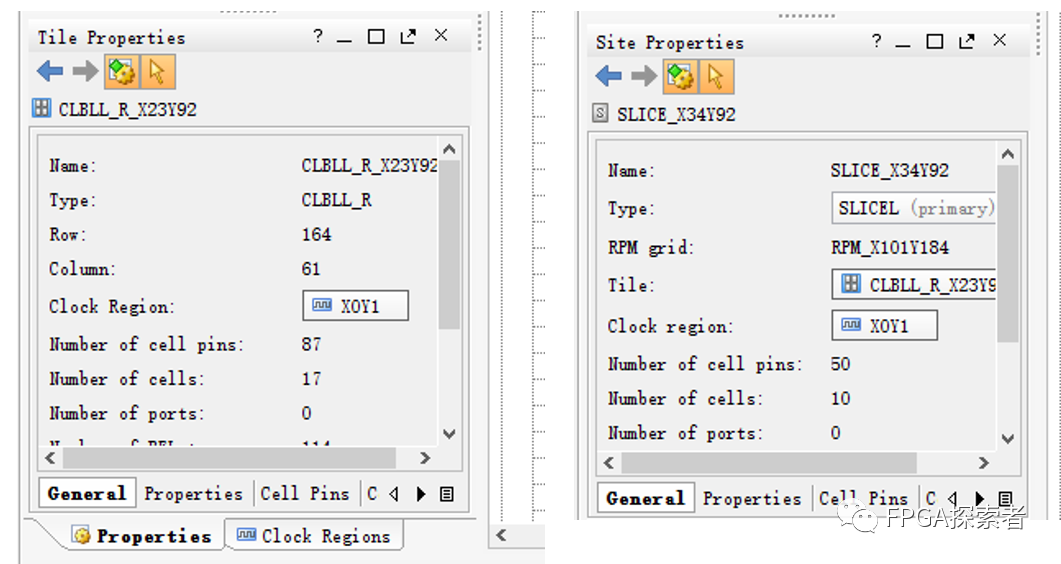
????点击内部的逻辑单元,通过阴影区别包含的范围,你可以清晰的看到结构划分的层级。在旁边窗口可以清晰的看到选中部分的属性(Properties)。
????来,再放大,放大到一个?SLICEL,如下图所示。
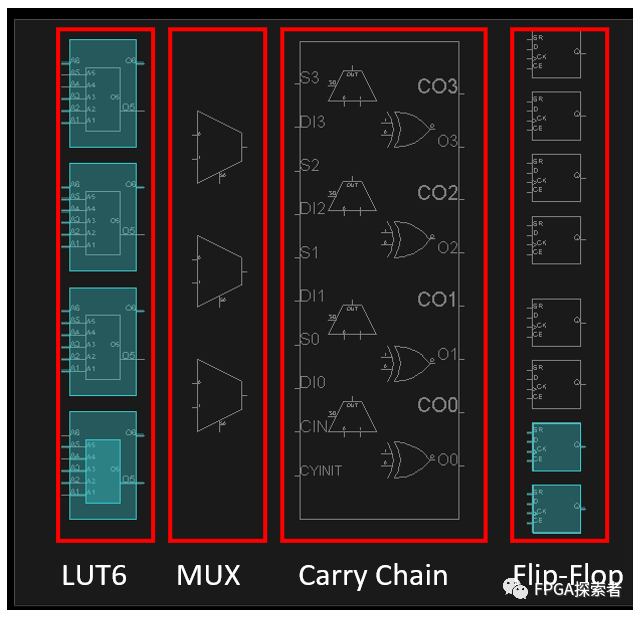
????SLICEL 和 SLICEM 内部都包含 4 个 6 输入查找表(Look-Up-Table,LUT6)、3 个数据选择器(MUX)、1 个进位链(Carry Chain)和 8 个触发器(Flip-Flop),下面分部分介绍的时候,时不时可以再回头看这张结构图。
?输入查找表(LUT6)
????虽然?SLICEL 和 SLICEM?的结构组成一样,但两者更细化的结构上略有不同,区别在于 LUT6?上(如下图所示),从而导致LUT6的功能有所不同(如下表格所示)。
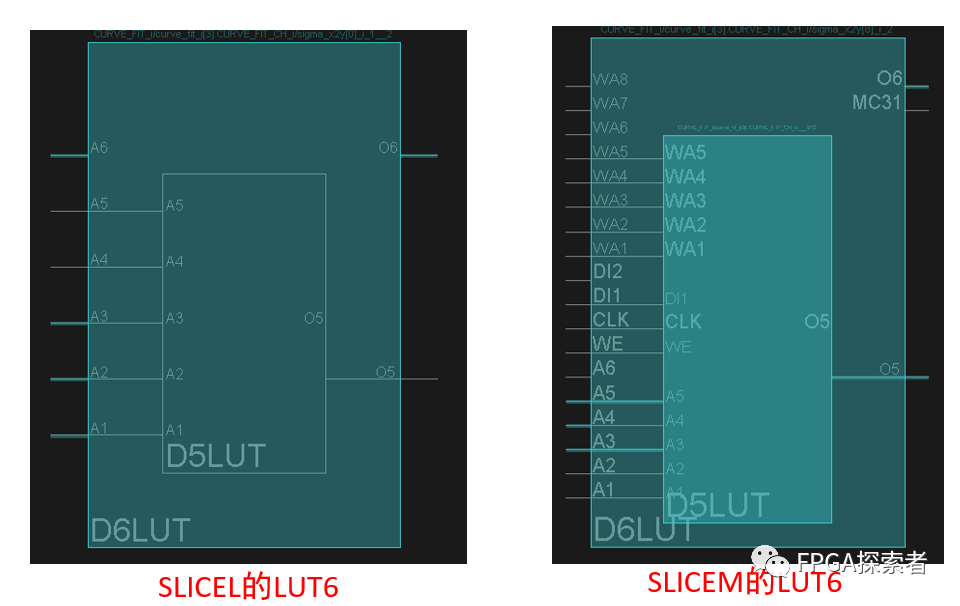
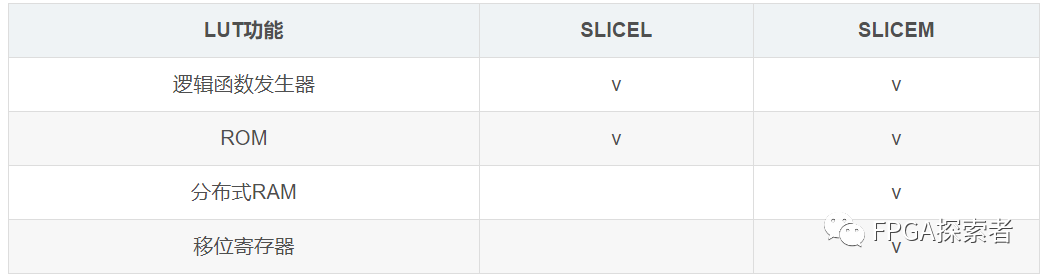
????上边的功能可以看到,不论是 SLICEL 还是 SLICEM,他们的 LUT6 都可以作为 ROM 使用,配置为 64x1(占用 1 个 LUT6,64 代表深度,1 代表宽度)、128x1(占用 2 个 LUT6)和 256(占用 4 个 LUT6)的 ROM。
????另外既然 SLICEM 中的 M 代表 memory 的意思,所以增加了更多存储功能。可以配置为 RAM,尤其指分布式 RAM。其中 RAM 的写操作为同步,而读操作是异步的,即与时钟信号无关。如果要实现同步读操作,则要额外占用一个触发器,从而增加了意识时钟的延迟(Latency),但提升了系统的性能。
????这就解释了为什么我们实现RAM同步读写的时候,读出输出要延迟一个 clk。一个 LUT6 可配置 64x1 的 RAM,当 RAM 的深度大于 64 时,会占用额外的 MUX(F7AMUX,F7BMUX,F8MUX,即一个 SLICE 中的那 3 个 MUX)。
??? SLICEM 中的 LUT 还可以配置为移位寄存器,每个 LUT6 可实现深度为 32 的移位寄存器,且同一个 SLICEM 中的 LUT6(4个)可级联实现 128 深度的移位寄存器。
选择器(MUX)
??? SLICE 中的三个 MUX(Multiplexer:F7AMUX,F7BMUX 和 F8MUX)可以和 LUT6 联合共同实现更大的MUX。事实上,一个 LUT6 可实现 4 选 1 的 MUX。
??? SLICE 中的 F7MUX(F7AMUX 和 F7BMUX)的输入数据来自于相邻的两个 LUT6 的 O6 端口。
????一个 F7MUX 和相邻的两个 LUT6 可实现一个 8 选 1 的 MUX。因此,一个 SLICE 可实现 2 个 8 选 1 的 MUX。
??? 4 个 LUT6、F7AMUX、F7BMUX 和 F8MUX 可实现一个 16 选 1 的 MUX。因此,一个 SLICE 可实现一个 16 选 1 的 MUX。
进位链(Carry Chain)
????进位链用于实现加法和减法运行。就是结构图中,中间那个大的部分,可以看到它内部实际还包含 4 个 MUX 和 4 个 2 输入异或门(XOR)。
????异或运算是加法运算中必不可少的运算。
? ? ?在下面我们会详细讨论并给出代码解释。
2.4 触发器(Flip-Flop)
????每个 SLICE 中有 8 个触发器。这 8 个触发器可分为两大类:4 个只能配置为边沿敏感的 D 触发器(Flip-Flop)和 4 个即可配置为边沿敏感的 D 触发器又可配置为电平敏感的锁存器(Flop & Latch)。当后者被用作锁存器的时候,前者将无法使用。
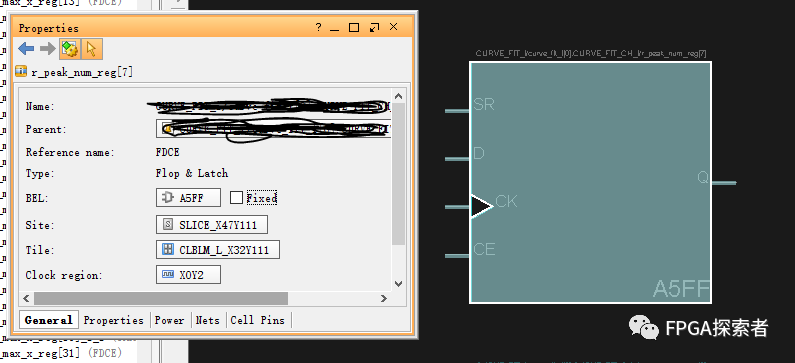
????当这 8 个触发器都用作 D 触发器时,他们的控制端口包括使能端 CE、置位/复位端口 S/R 和时钟端口 CLK 是对应共享的,也就是就是说共用的。???????{CE,S/R,CLK}称为触发器的控制集。显然,在具体的设计中,控制集种类越少越好,这样可以提高触发器的利用率。那么怎样减少控制集种类呢?我的理解是:
????减少时钟种类,即频率越少越好;
????统一规范的设计逻辑,如复位。
????S/R端口可配置为同步/异步置位或同步/异步复位,且高有效,因此可形成4种D触发器,如下表所示。
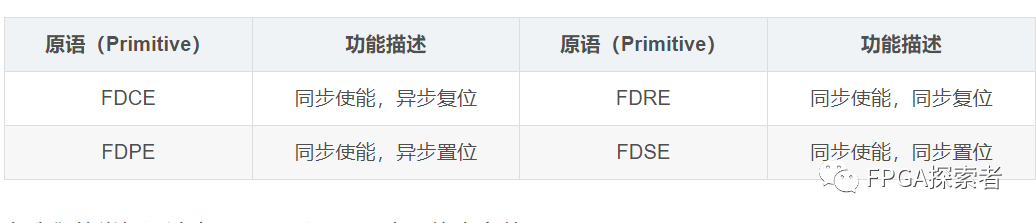
????在我们的常规设计中,FDCE 和 FDPE 占了绝大多数。
????上一篇电路结构中的FDCE其实就是我们日常时序逻辑中会出现的DFF。
FDCE/FDPE/FDRE/FDSE区别:

? ? ? FDPE作为带有异步预置位的DFF,一般用作复位电路中,可以作为MMCM中不同时钟域中复位的输出。
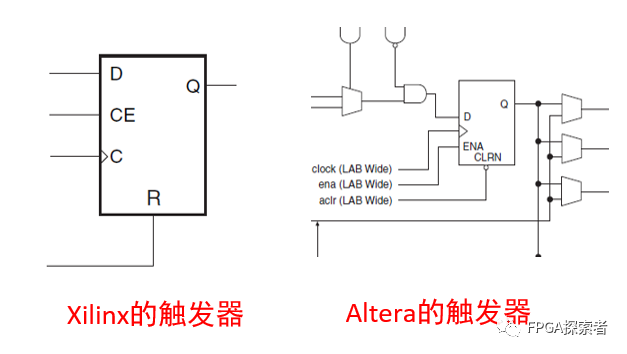
????说到高有效,让我想起了一个大家习以为常,但很少深究的问题:为什么一开始接触 FPGA 的时候,都告诉我们低电平复位?后来查了一些资料,有说从功耗、噪声可靠性方面考虑等等,但是偶然看到 Xilinx 和 Altera 两家芯片的触发器不一样!如下图所示,Xilinx 的触发器是高电平复位,而 Altera 的触发器时低电平复位。所以这也是需要考虑的一点吗?
??在FPGA中我们写的最多的逻辑是什么?相信对大部分朋友来说应该都是计数器,从最初板卡的测试时我们会闪烁LED,到复杂的AXI总线中产生地址或者last等信号,都会用到计数器,使用计数器那必然会用到进位链。
??我们这里再回顾一下。FPGA的三个主要资源为:
-
可编程逻辑单元CLB
-
逻辑单元
-
存储单元
-
运算单元(DSP48)
-
-
可编程I/O资源
-
布线资源
??其中,CLB在FPGA中最为丰富,在7系列的FPGA中,一个CLB中有两个Slice,Slice中包含4个LUT6、3个数据选择器MUX、两个独立进位链(Carry4,Ultrascale是CARRY8)和8个触发器。
不同器件可能进位链个数不同,这里参考的资料所涉及的器件和上文参考的资料有所不同
??首先,我们来看下Carry Chain的结构原理,其输入输出接口如下:

其中,
-
CI是上一个CARRY4的进位输出,位宽为1;
-
CYINT是进位的初始化值,位宽为1;
-
DI是数据的输入(两个加数的任意一个),位宽为4;
-
SI是两个加数的异或,位宽为4;
-
O是加法结果输出,位宽为4;
-
CO是进位输出,位宽为4;(为什么进位输出是4bit?后面有解释)
Carry4的内部结构如下图所示:

?这里我们要先解释一下FPGA中利用Carry Chain实现加法的原理,比如两个加数分别为a = 4'b1000和b=4'b1100,其结果应该是8+12=20。
a = 4'b1000;
b = 4'b1100;
S = a ^ b = 4'b0100;
D = b = 4'b1100; //D取a也可以
CIN = 0; //没有上一级的进位输入
CYINIT = 0; //初始值为0
// 下面为CARRY4的计算过程,具体的算法跟上图中过程一样
S0 = 0; //S的第0位
O0 = S0 ^ 0 = 0 ^ 0 = 0;
CO0 = DI0 = 0; //上图中的MUXCY,S0为0时,选择1,也就是DI0,S0为1是选择2
S1 = 0;
O1 = S1 ^ CO0 = 0 ^ 0 = 0;
CO1 = DI1 = 0;
S2 = 1;
O2 = S2 ^ CO1 = 0 ^ 1 = 1;
CO2 = CO1 = 0;
S3 = 0;
O3 = S3 ^ CO2 = 0 ^ 0 = 0;
CO3 = DI3 = 1;???加法最终的输出结果为:{CO3,O3,O2,O1,O0} = 5'b10100 = 20。进位输出在CARRY4的内部也使用到了,因此有4个bit的进位输出CO,但输出给下一级的只是CO[3]。
????????再来看完下面的例子就更清晰了。Example的代码如下:
module top(
input clk,
input [7:0] din_a,
input [7:0] din_b,
output reg[7:0] dout
);
always @ ( posedge clk )
begin
dout <= din_a + din_b;
end
endmodule综合之后的电路如下:
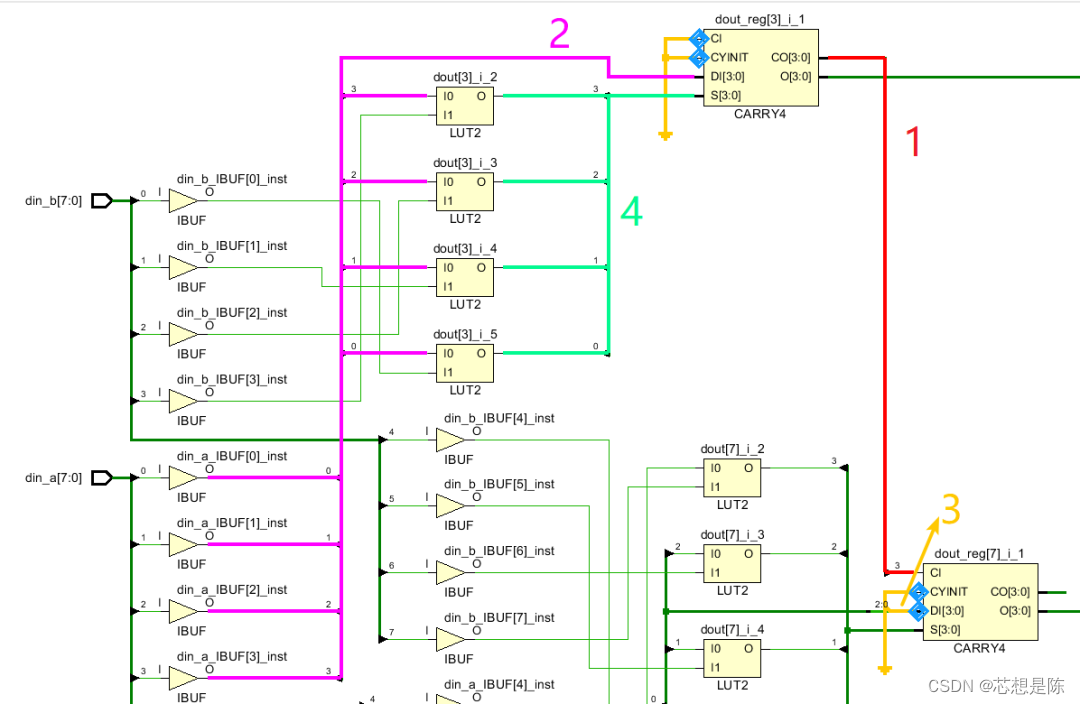
?在本程序中,加数为din_a和din_b,图中
-
1表示CARRY4的进位输出到下一级的进入输入;
-
2表示输入的一个加数din_a(换成din_b也是可以的);
-
3表示第二级输入的DI端口,因为第二级CARRY是通过第一级的进位输出进行累加,因此该接口为0;
-
4表示输入两个加数的异或结果。
??可以看出,当进行两个8bit的数据进行加法操作时,会使用两个CARRY4级联,那如果是对48位的数据进行相加,那就会用到12个的CARRY4的级联,这样明显就会使逻辑延迟过大,很容易造成时序不收敛。(这里需要注意的是,在Vivado的默认设置下,如果进行的是12bit以下的数据加1'b1的操作,那么Vivado综合的结果并不会使用CARYY4,而是使用LUT来实现加法器)。
??那如何解决这种问题呢?我们可以把加法操作进行拆解,比如拆解成3个16bit的计数器,那这样就会只有4个CARRY4的级联,时序情况就好了很多。
对比程序如下:
module top(
input clk,
input [47:0] din1,
input [47:0] din2,
output reg[47:0] dout1,
output [47:0] dout2
);
always @ ( posedge clk )
begin
dout1 <= din1 + 1'b1;
end
genvar i;
generate
for(i = 0;i < 3;i=i+1) begin:LOOP
wire carry_co;
reg [15:0] carry_o=0;
wire ci;
if(i==0) begin
always @ ( posedge clk )
begin
carry_o <= din2[i*16+:16] + 1'b1;
end
end //if
else begin
always @ (posedge clk) begin
if(LOOP[i-1].carry_co == 1)
carry_o <= carry_o + 1'b1;
end
end //else
assign LOOP[i].carry_co = (LOOP[i].carry_o==16'hffff)?1'b1:1'b0;
assign dout2[i*16+:16] = LOOP[i].carry_o;
end //for
endgenerate
endmodule??打开综合后的schematic后可以发现,在dout2的输出中,每4个CARRY4后都会有一级的触发器,这样时序就会好很多,但这样做的代价是LUT会增加。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 快速上手的AI工具-文心一言绘画达人
- HTTP3/QUIC 性能测试与配套组件
- 4 errors detected in the compilation of “render_utils_kernel.cu“
- 前端-基础 表格标签 - 相关属性详解
- 22. 从零用Rust编写正反向代理,一个数据包的神奇HTTP历险记!
- ThreadPoolExecutor线程池
- 【教程】代码混淆详解
- 深兰科技陈海波出席“2023浙商年度主题大会”并与知名主持人白岩松对话
- 【数据库原理】(2)数据库管理系统(DBMS)介绍
- C Primer Plus(第六版)11.13 编程练习 第16题