在学习爬虫前的准备
发布时间:2024年01月09日
1. 写一个爬虫程序需要分几步
-
获取网页内容。
我们会通过代码给一个网站服务器发送请求,它会返回给我们网页上的内容。
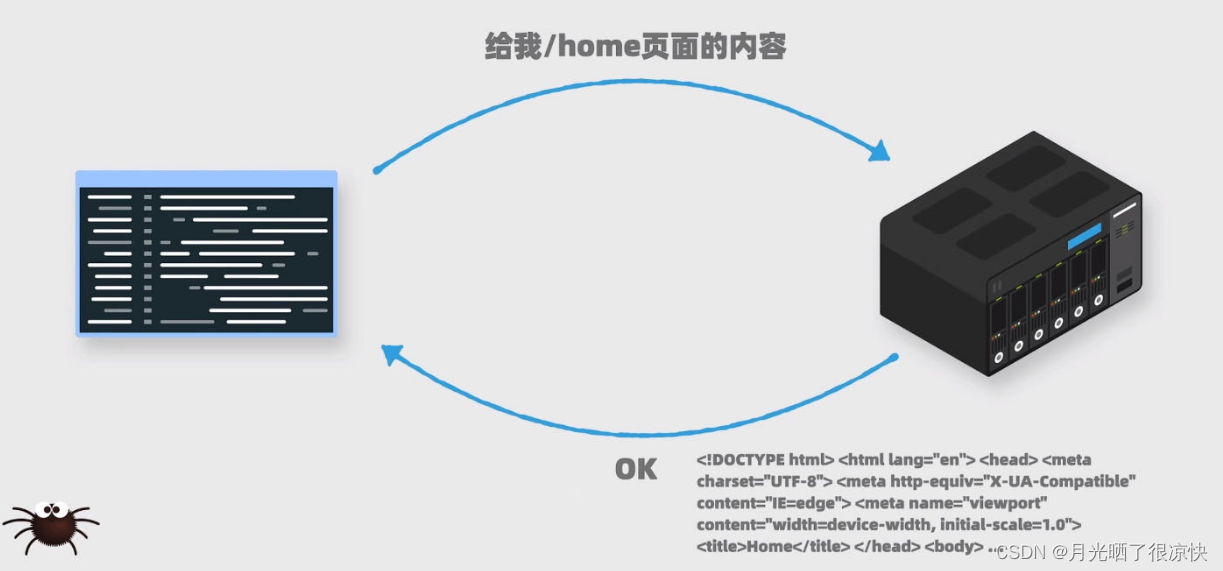
在我们平时使用浏览器访问服务器内容是,本质上也是向服务器发送一个请求,然后服务器返回网页上的内容。只不过浏览器还会进行一个额外的步骤,就是把内容渲染成直观优美的页面,方便给用户展现。而用程序获取的内容,因为没有经过渲染,所以我们看到的内容更加原始。
-
解析网页内容。
我们在上一步可以获取到整个网页的内容,由于内容过于繁杂,可能有许多数据是我们并不想要的。比如我们在一个电商平台,我们可能只对商品名和价格感兴趣,至于活动信息和用户评论等信息我们都不需要,所以需要对内容进行解析,把想要的内容提取出来。
-
储存或分析数据。
这一步主要取决于具体需求,比如我们一开始是想要获取数据集,所以这一步骤可能就是要把数据储存进数据库。如果我们一开始是为了分析数据,那么这一步骤就是把数据做成可视化图表。如果一开始是为了做舆情监控,那么这一步骤就可能是用AI做文本情绪分析。
以上步骤使用于爬取一个网页的情况,当然我们也可以给一串网址,让程序一个个去爬取,或者让程序以某个网址为根,顺着把那个网页上链接指向的地址也爬取一遍。
2. 爬虫注意事项
俗话说爬虫学的好,牢饭吃的早。其实技术本身是无罪的,重要的是如何去使用这项技术。在爬虫过程中,我们必须遵守一些规则:
- 不要爬取公民隐私数据;
- 不要爬取受著作权保护的内容;
- 不要爬取国家事务、国防建设、尖端科学技术领域的计算机系统等。
除了上述红线之外,我们还必须确保自己写的爬虫是一只温和善良的虫:
- 它的请求数量和频率不能过高,否则可能无异于DDoS攻击。DDoS攻击就是通过给服务器发送海量高频的请求,让网站资源被耗尽,无法服务其他正常用户;
- 网站如果明显做出了反爬限制,比如有些内容要登录后才可查看,或是有验证码等限制机器的机制,就不要强行去突破;
- 我们可以通过查看网站的
robots.txt,了解可爬取的网页路径范围。这个文件会指明哪些网页允许被爬取,那些不允许被爬取,有些还会列出专门针对搜索引擎爬虫的许可范围。
文章来源:https://blog.csdn.net/weixin_45605541/article/details/135469508
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- EMT(light sr):Efficient Mixed Transformer for Single Image Super-Resolution
- 气象数据预测分析与可视化:天气趋势预测揭秘
- 第21节: Vue3 计算缓存与方法
- [LeetCode周赛复盘] 第 379 场周赛20240107
- <script setup>中pinia的使用
- 如何在vscode当中预览html文件运行结果
- 数据结构学习 jz30 包含 min 函数的栈
- 【采药.】
- 微信浏览器不显示视频原因
- MySQL - 使用 MySQL 存储过程来生成大量数据并插入到 MySQL 数据库中