(7-3-1)金融风险管理实战:制作信贷风控模型
请大家关注我,本文章粉丝可见,我会一直更新下去,完整代码进QQ群获取:323140750,大家一起进步、学习。
经过本章前面内容的介绍,已经了解了金融风险建模与管理的基础知识,明确了金融风险建模与管理的重要性。在本节内容中,将通过具体实例展示金融风险建模与管理在现实中的应用。本实例的功能是,使用历史贷款申请数据来预测申请人是否有能力还贷款。
7.3.1 ?读取数据集数据
在数据集中包含了大量的特征和标签,可以用于建立和测试机器学习模型,以改进信贷风险评估。
(1)列出所有可用的数据文件,具体实现代码如下所示。
print(os.listdir("input"))
#训练数据
app_train = pd.read_csv('input/application_train.csv')执行后会输出:
['POS_CASH_balance.csv', 'bureau_balance.csv', 'application_train.csv', 'previous_application.csv', 'installments_payments.csv', 'credit_card_balance.csv', 'sample_submission.csv', 'application_test.csv', 'bureau.csv']总共有9个文件:1个用于训练的主文件(包含目标),1个用于测试的主文件(不包含目标),1个示例提交文件,以及6个包含有关每笔贷款的附加信息的其他文件。
(2)打印输出训练数据的形状以及前几行数据的内容,具体实现代码如下所示。
print('Training data shape: ', app_train.shape)
print(app_train.head())执行后会输出:
Training data shape: ?(307511, 122)
???SK_ID_CURR ?TARGET ?... AMT_REQ_CREDIT_BUREAU_QRT AMT_REQ_CREDIT_BUREAU_YEAR
0 ?????100002 ??????1 ?... ??????????????????????0.0 ???????????????????????1.0
1 ?????100003 ??????0 ?... ??????????????????????0.0 ???????????????????????0.0
2 ?????100004 ??????0 ?... ??????????????????????0.0 ???????????????????????0.0
3 ?????100006 ??????0 ?... ??????????????????????NaN ???????????????????????NaN
4 ?????100007 ??????0 ?... ??????????????????????0.0 ???????????????????????0.0
[5 rows x 122 columns]数据中包含了307511行和122列,前几列包含了一些基本信息,比如贷款类型、性别、是否拥有车辆等等。最后几列包含了一些关于信用和贷款申请的信息。
(3)读取测试数据集,然后打印出测试数据的形状和前几行数据的内容。具体实现代码如下所示。
app_test = pd.read_csv('input/application_test.csv')
print('Testing data shape: ', app_test.shape)
app_test.head()执行后会输出:
Testing data shape: ?(48744, 121)
???SK_ID_CURR ?... AMT_REQ_CREDIT_BUREAU_YEAR
0 ?????100001 ?... ???????????????????????0.0
1 ?????100005 ?... ???????????????????????3.0
2 ?????100013 ?... ???????????????????????4.0
3 ?????100028 ?... ???????????????????????3.0
4 ?????100038 ?... ???????????????????????NaN
[5 rows x 121 columns]测试数据包含48744个观测值和121个特征,测试数据用于评估我们训练的模型在未见过的数据上的性能。通过上述输出可知,测试集明显较小,并且缺少TARGET列。测试集通常比训练集小,因为它用于评估模型的性能,而不需要包含目标列,因为我们的任务是预测测试集中每个申请的目标值。
7.3.2 ?探索性数据分析
探索性数据分析(Exploratory Data Analysis,EDA)是一个开放性的过程,其中我们计算统计数据并制作图表,以查找数据中的趋势、异常、模式或关系。EDA的目标是了解数据能告诉我们什么。通常从高层次的概览开始,然后随着我们在数据中找到引人注目的地方,逐渐缩小范围,关注特定领域。发现可能本身就很有趣,或者可以用来指导我们的建模选择,比如帮助我们决定使用哪些特征。
(1)检查目标列的分
目标是我们要预测的内容:0表示贷款按时还款,1表示客户有支付困难。我们首先可以查看落入每个类别的贷款数量,具体实现代码如下所示。
app_train['TARGET'].value_counts()上述代码用于查看目标列中每个类别的样本数量,即贷款按时还款(0)和贷款有支付困难(1)的数量。这有助于我们了解数据中两个类别的分布情况。执行后会输出:
0 ???282686
1 ????24825
Name: TARGET, dtype: int64然后通过如下代码将app_train中的TARGET列的数据类型转换为整数类型(int),然后绘制直方图(histogram)。
app_train['TARGET'].astype(int).plot.hist();对上述代码的具体说明如下:
- app_train['TARGET'].astype(int):将TARGET列中的数据类型转换为整数类型,这是为了确保数据可以被正确地绘制在直方图上。
- plot.hist():使用Pandas的绘图功能,绘制直方图。直方图用于可视化数据的分布情况,它将数据分成不同的区间,然后统计每个区间中数据点的数量,并将结果以柱状图的形式呈现出来。
这行代码的效果是绘制了TARGET列中的数据分布情况的直方图,如图7-2所示。通过直方图,我们可以看到不同类别的样本数量,从而更好地理解目标变量的分布。
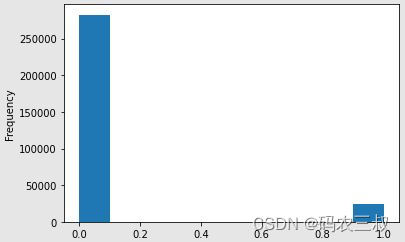
图7-2 ?TARGET列数据分布情况的直方图
(2)缺失值处理
分析数据集中的缺失值情况,并生成一个包含有关每列缺失值数量和百分比的汇总表格。具体实现代码如下所示。
# 用于按列计算缺失值的函数
def missing_values_table(df):
# 总缺失值
mis_val = df.isnull().sum()
# 缺失值的百分比
mis_val_percent = 100 * df.isnull().sum() / len(df)
# 创建包含结果的表格
mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1)
# 重命名列名
mis_val_table_ren_columns = mis_val_table.rename(
columns={0: '缺失值数量', 1: '总值百分比'})
# 按缺失值百分比降序排序表格
mis_val_table_ren_columns = mis_val_table_ren_columns[
mis_val_table_ren_columns.iloc[:, 1] != 0].sort_values(
'总值百分比', ascending=False).round(1)
# 打印一些摘要信息
print("Your selected dataframe has " + str(df.shape[1]) + " columns.\n"
"There are " + str(mis_val_table_ren_columns.shape[0]) +
" columns that have missing values.")
# Return the dataframe with missing information
return mis_val_table_ren_columns
# 缺失值
missing_values = missing_values_table(app_train)
missing_values.head(20)在上述代码中定义了一个名为 missing_values_table 的函数,该函数用于分析数据框中的缺失值并生成包含统计信息的表格。执行后会输出:
Your selected dataframe has 122 columns.
There are 67 columns that have missing values.
Missing Values % of Total Values
COMMONAREA_MEDI 214865 69.9
COMMONAREA_AVG 214865 69.9
COMMONAREA_MODE 214865 69.9
NONLIVINGAPARTMENTS_MEDI 213514 69.4
NONLIVINGAPARTMENTS_MODE 213514 69.4
NONLIVINGAPARTMENTS_AVG 213514 69.4
FONDKAPREMONT_MODE 210295 68.4
LIVINGAPARTMENTS_MODE 210199 68.4
LIVINGAPARTMENTS_MEDI 210199 68.4
LIVINGAPARTMENTS_AVG 210199 68.4
FLOORSMIN_MODE 208642 67.8
FLOORSMIN_MEDI 208642 67.8
FLOORSMIN_AVG 208642 67.8
YEARS_BUILD_MODE 204488 66.5
YEARS_BUILD_MEDI 204488 66.5
YEARS_BUILD_AVG 204488 66.5
OWN_CAR_AGE 202929 66.0
LANDAREA_AVG 182590 59.4
LANDAREA_MEDI 182590 59.4
LANDAREA_MODE 182590 59.4当开始构建机器学习模型时,我们需要填补这些缺失值(称为缺失值填充)。在后续工作中,将使用诸如XGBoost之类的模型,它可以处理缺失值,无需进行填充。另一个选择是放弃那些具有高缺失值百分比的列,尽管无法提前知道这些列是否对我们的模型有帮助。因此,目前我们将保留所有列。
(3)列的数据类型
接下来开始查看每种数据类型的列数,int64和float64是数值变量(可以是离散型或连续型)。object列包含字符串,属于分类特征。具体实现代码如下所示。
# 每种数据类型的列数
app_train.dtypes.value_counts()执行后会输出:
float64 ???65
int64 ?????41
object ????16
dtype: int64现在查看每个object(分类)列中唯一条目的数量,具体实现代码如下所示。
#每个object列中唯一类别的数量
app_train.select_dtypes('object').apply(pd.Series.nunique, axis = 0)执行后会输出:
NAME_CONTRACT_TYPE ????????????2
CODE_GENDER ???????????????????3
FLAG_OWN_CAR ??????????????????2
FLAG_OWN_REALTY ???????????????2
NAME_TYPE_SUITE ???????????????7
NAME_INCOME_TYPE ??????????????8
NAME_EDUCATION_TYPE ???????????5
NAME_FAMILY_STATUS ????????????6
NAME_HOUSING_TYPE ?????????????6
OCCUPATION_TYPE ??????????????18
WEEKDAY_APPR_PROCESS_START ????7
ORGANIZATION_TYPE ????????????58
FONDKAPREMONT_MODE ????????????4
HOUSETYPE_MODE ????????????????3
WALLSMATERIAL_MODE ????????????7
EMERGENCYSTATE_MODE ???????????2
dtype: int647.3.3 ?编码分类变量
在继续之前,我需要处理麻烦的分类变量。不幸的是,机器学习模型通常不能处理分类变量(除了一些模型,如LightGBM)。因此,我们必须找到一种方法,将这些变量编码(表示为数字),然后将它们传递给模型。有如下两种主要的方法来执行此过程:
- 标签编码:为分类变量中的每个唯一类别分配一个整数。不会创建新列。例如下图7-3是一个示例。
- 1-热编码:为分类变量中的每个唯一类别创建一个新列。每个观察值在其对应类别的列中获得1,在所有其他新列中获得0。例如下图7-4是一个示例。
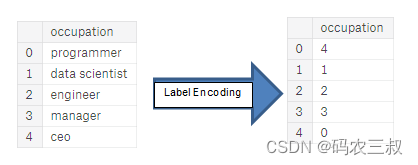
图7-3 ?标签编码
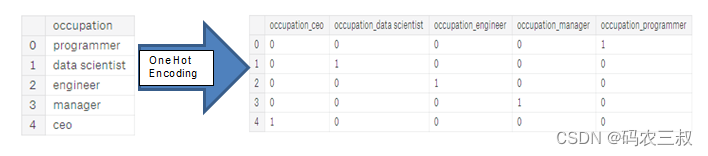
图7-4 ?1-热编码
标签编码的问题在于它会为类别分配任意的排序,分配给每个类别的值是随机的,不反映类别的任何固有特性。在图7-3所示的示例中,程序员得到了4,数据科学家得到了1,但如果我们再次执行相同的过程,标签可能会颠倒或完全不同。整数的实际分配是任意的。因此,当我们执行标签编码时,模型可能使用特征的相对值(例如程序员=4,数据科学家=1)来分配权重,这不是我们想要的。如果对于一个分类变量只有两个唯一值(例如男/女),那么标签编码是可以的,但对于超过2个唯一类别的情况,一热编码是安全的选择。
关于这些方法的相对优点存在一些争论,有些模型可以处理标签编码的分类变量而没有问题。我认为(这只是个人意见),对于具有许多类别的分类变量,1-热编码是最安全的方法,因为它不会对类别施加任意的值。1-热编码唯一的缺点是,对于具有许多类别的分类变量,特征的数量(数据的维度)可能会激增。为了应对这个问题,我们可以执行1-热编码,然后进行PCA或其他降维方法,以减少维度的数量(同时尽量保留信息)。
在本实例中,我们将对具有只有2个类别的分类变量使用标签编码,对于具有超过2个类别的分类变量,我们将使用1-热编码。随着项目的进展,这个过程可能需要更改,但目前,我们将看看这将为我们带来什么。
开始实现标签编码和1-热编码,让我们实施上述策略:对于任何具有2个唯一类别的分类变量(dtype == object),我们将使用标签编码;对于具有超过2个唯一类别的任何分类变量,我们将使用1-热编码。
对于标签编码,使用Scikit-Learn的LabelEncoder,对于1-热编码,使用pandas的get_dummies(df)函数实现。具体实现代码如下所示。
#创建数据框
le = LabelEncoder()
le_count = 0
# 遍历所有列
for col in app_train:
????if app_train[col].dtype == 'object':
????????# 如果唯一类别的数量小于或等于2
????????if len(list(app_train[col].unique())) <= 2:
????????????# 在训练数据上进行标签编码的训练
????????????le.fit(app_train[col])
????????????# 对训练和测试数据进行标签编码的转换
????????????app_train[col] = le.transform(app_train[col])
????????????app_test[col] = le.transform(app_test[col])
????????????# 记录标签编码的列数d
????????????le_count += 1
print('%d columns were label encoded.' % le_count)对上述代码的具体说明如下:
(1)创建一个标签编码器对象 le 和一个计数器 le_count 以跟踪标签编码的列数。
(2)遍历 app_train 数据集的所有列,对于数据类型为 'object'(即字符串类型)的列,执行以下操作:
- 如果该列的唯一类别数量小于或等于2,表示该列是一个二进制分类特征。
- 使用标签编码器 le 在训练数据上进行拟合(学习类别与整数标签之间的映射)。
- 对训练数据和测试数据中的相同列进行编码转换,将类别转换为整数标签。
- 增加 le_count 计数以跟踪已标签编码的列数。
(3)最后,打印输出标签编码的列数。标签编码是将分类特征转换为机器学习模型可以处理的数值特征的一种方法,特别适用于具有二进制类别的列。这有助于准备数据以供机器学习模型使用。执行后会输出:
3 columns were label encoded.接下来对分类变量进行独热编码,具体实现代码如下所示。
app_train = pd.get_dummies(app_train)
app_test = pd.get_dummies(app_test)
print('Training Features shape: ', app_train.shape)
print('Testing Features shape: ', app_test.shape)上述段代码、对分类变量的独热编码操作,独热编码是将分类变量转换成二进制编码的过程,每个类别对应一个新的二进制特征列。例如,如果原始数据有一个"颜色"列,包含"红色"、"蓝色"和"绿色"三种颜色,独热编码将创建三个新的特征列,分别代表每种颜色的存在与否。在这里,代码对训练数据集和测试数据集中的分类变量进行了独热编码,将它们转换成了二进制编码的形式,以便机器学习模型可以处理它们。最后,代码打印出了训练数据和测试数据的特征数据形状,以便确认编码后的特征维度。执行后会输出:
Training Features shape: ?(307511, 243)
Testing Features shape: ?(48744, 239)为了确保训练数据和测试数据具有相同的特征列,需要执行数据框的对齐操作。由于独热编码在训练数据中创建了更多的列,这是因为一些分类变量在测试数据中的类别在训练数据中没有表示。为了移除训练数据中不在测试数据中的列,我们需要对齐这两个数据框。首先,我们从训练数据中提取出目标列(因为这个列在测试数据中不存在,但我们需要保留这些信息)。在执行对齐操作时,必须确保设置 axis = 1,以便根据列进行数据框的对齐,而不是根据行!这样可以确保训练数据和测试数据具有相同的特征列。实现对齐处理的代码如下所示:
# 提取训练数据中的目标列
train_labels = app_train['TARGET']
# 对齐训练和测试数据,仅保留两个数据框中都存在的列
app_train, app_test = app_train.align(app_test, join='inner', axis=1)
# 将目标列重新添加到训练数据中
app_train['TARGET'] = train_labels
# 打印训练数据和测试数据的形状
print('Training Features shape: ', app_train.shape)
print('Testing Features shape: ', app_test.shape)在上述代码中,首先从训练数据中提取了目标列,保存在名为train_labels的变量中。接下来,通过使用align方法对齐训练数据和测试数据,只保留两个数据框中都存在的列,参数join='inner'表示只保留共有的列,而axis=1表示对列进行对齐操作。最后,将目标列重新添加到训练数据中,确保两个数据框的列完全一致。通过这些操作,训练数据和测试数据现在具有相同的特征列,可以用于后续的机器学习建模。在最后,打印了训练数据和测试数据的形状,以确认它们已经对齐并准备好进一步处理。执行后会输出:
Training Features shape: ?(307511, 240)
Testing Features shape: ?(48744, 239)本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【直播预告】刘军博士:科学研究中的AI计算:何助力团队协作创新
- Unity学会使用高级功能Attributes(特性),让您的程序如虎添翼
- 怎样提取视频号里的视频,视频下载小助手工具可下载吗?
- 算法:两个超级大数相加
- 【shell发送邮件】
- Spring Boot项目中校验器的使用与注意事项
- 服务器感染了.pings勒索病毒,如何确保数据文件完整恢复?
- 安全运营之安全检查和测试
- MySQL 8.0 InnoDB Tablespaces之Undo Tablespaces(UNDO表空间)
- 为什么很多人学习IT会选择Java?