Python - 深夜数据结构与算法之 BloomFilter

目录
一.引言
布隆过滤器 BloomFilter 是位运算在工业级场景应用的典范,其通过 bit 位保存元素是否存在,大大降低了判重所需的空间,下面我们看下其原理与实现。
二.BloomFilter 简介
1.Hash Table
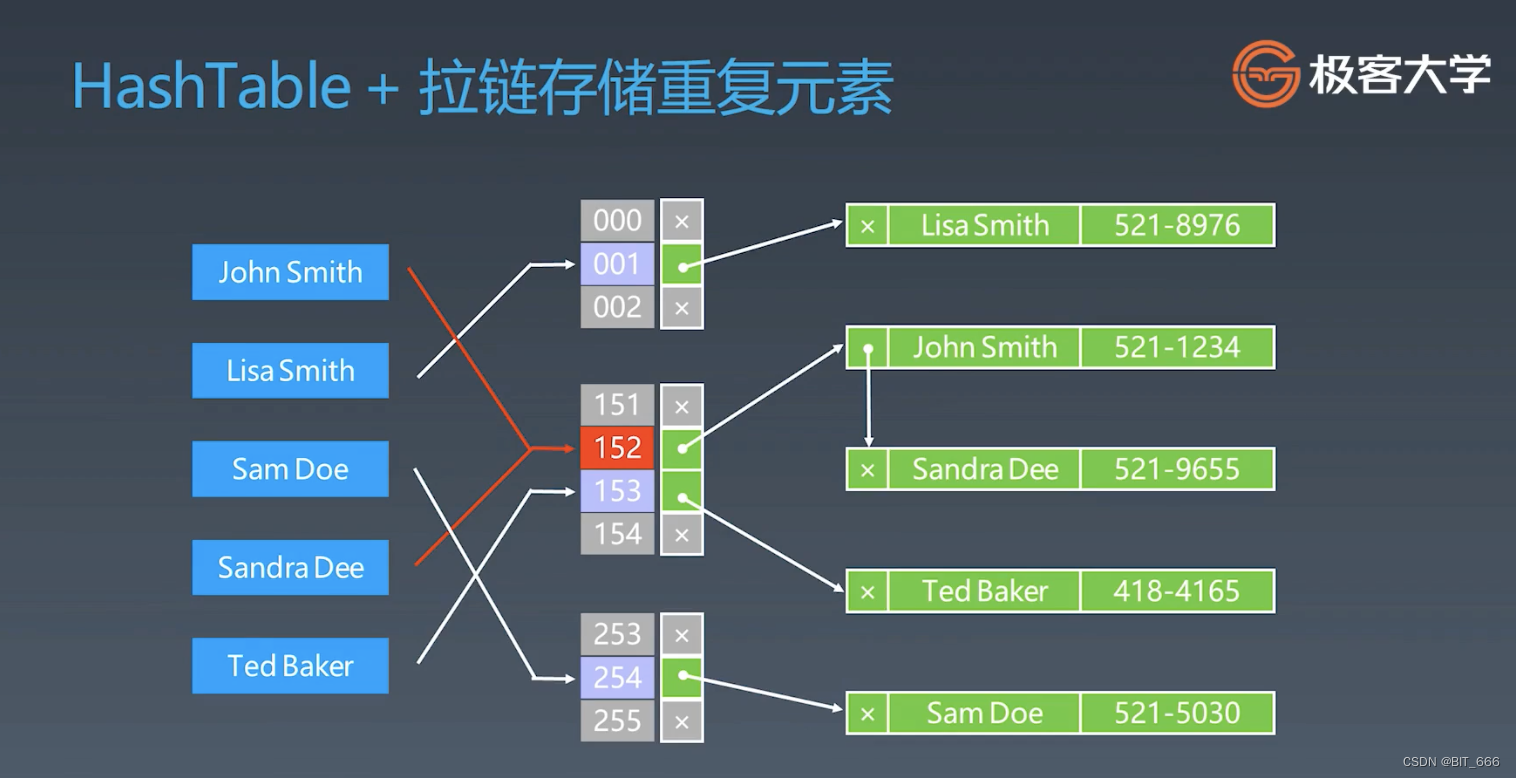
假设原始元素为 String,这里通过一个 hash 函数就可以得到其对应的数组索引, 然后获取其相关信息。如果存在 Hash 冲突,例如 John Simith 与 Sandra Dee 的 Hash 值均为 152,此时一种方式是构造链表,然后 o(n) 的时间复杂度寻找当前 key 的信息。
2.Bloom Filter

工业级应用中一个场景的场景就是元素的去重,此时我们无需存储完整的 String,只需知道当前元素在不在表中即可,所以衍生了布隆过滤器。?
- 效率高
因为使用二进制向量,通过 bit 存储,所以空间效率非常高
- 误识别
参考上面 Hash 值相同的情况,A、B Hash 相同时,如果 A 已存在,则 B 判断时会造成误判
3.Bloom 示意图
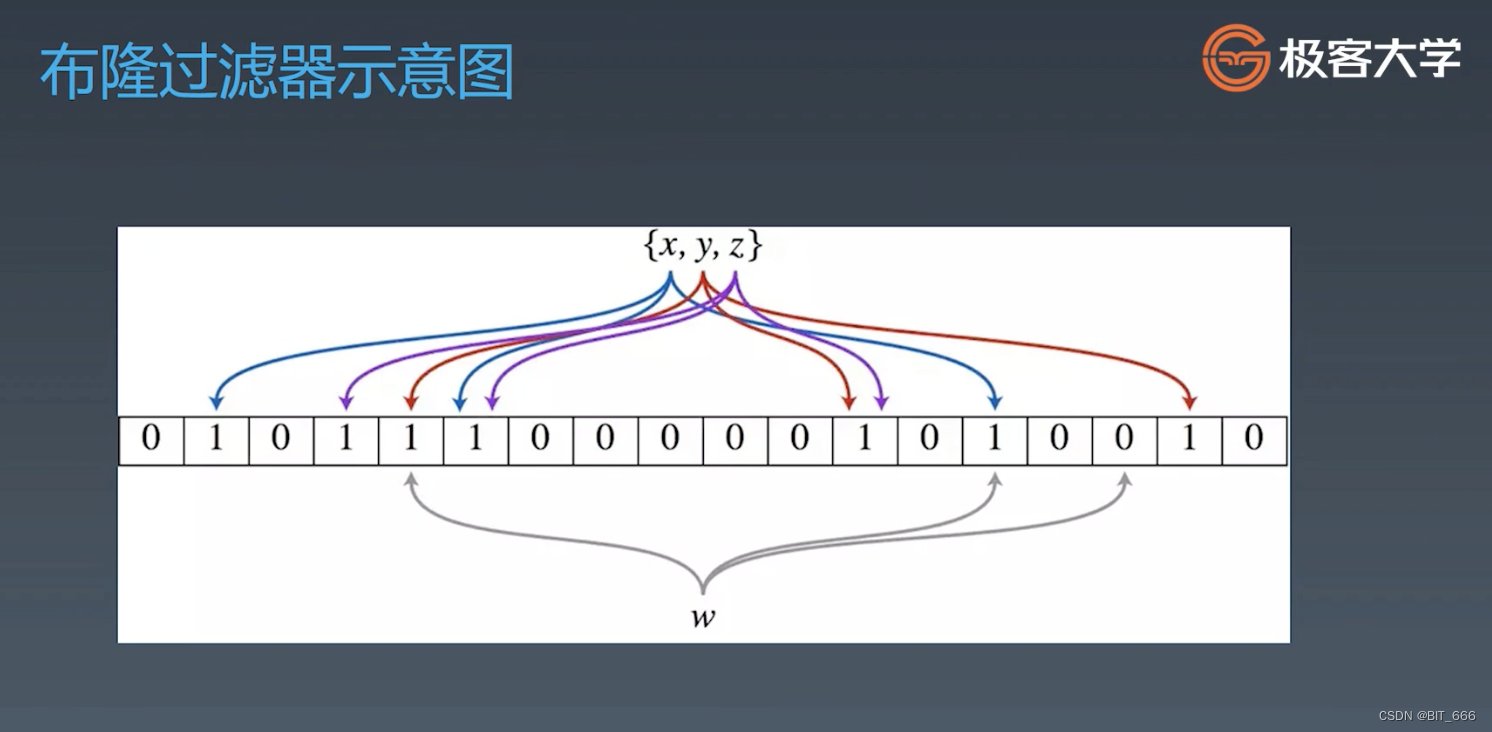
应用场景中,二进制数组会非常大,同时元素不会只获取一个 Hash 值,而是通过多个 Hash 函数获取多个 Hash 值,再将对应位置索引置位 1。当我们判断 w 是否存在于表中时,我们将 w 分别用相同的 hash 函数去 hash,如果多个位置均为 1,则认为其已存在,否则不存在。
- hash 后索引有 0: 当前元素一定不存在
- hash 后索引全 1: 当前元素可能存在
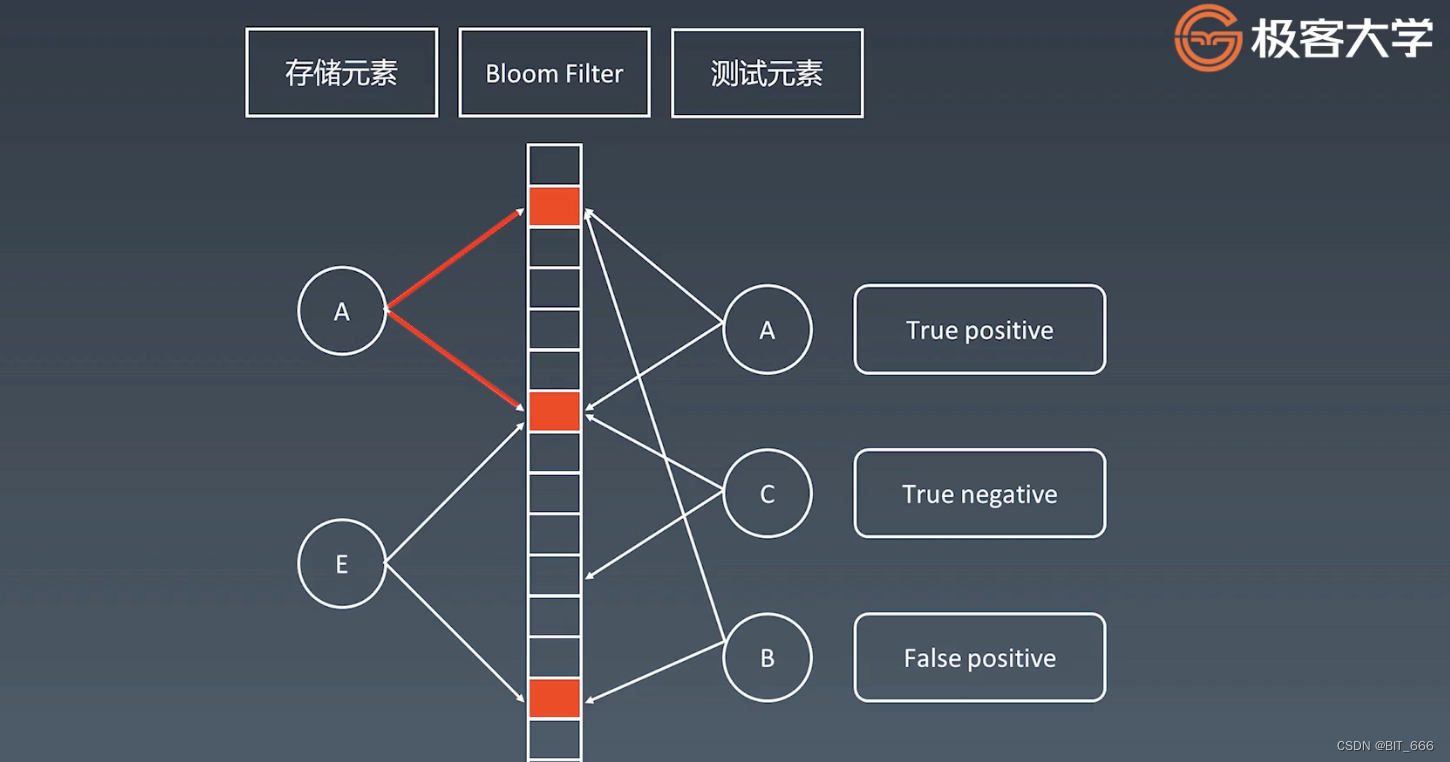
如图所示,添加 AE 后的 Bloom Filter 在判断 B 是否存在时出现了误判。?此时布隆过滤器只是一个外置的快速查询缓存,当检测到 B 可能存在后,我们还会去后端的 DB 确认其是否存在;而对于 C 而言,我们直接将其添加至 Bloom 过滤器中即可。
4.Bloom 应用

网络节点的索引查询、分布式系统的节点查询以及一些过滤和缓存中经常使用 Bloom Filter 做前端的缓存。
三.Bloom Filter 实现
1.Python 实现
from bitarray import bitarray
import mmh3
class BloomFilter:
def __init__(self, size, hash_num):
self.size = size
self.hash_num = hash_num
self.bit_array = bitarray(self.size)
self.bit_array.setall(0)
def add(self, s):
for seed in range(self.hash_num):
result = mmh3.hash(s, seed) % self.size
self.bit_array[result] = 1
def lookup(self, s):
for seed in range(self.hash_num):
result = mmh3.hash(s, seed) % self.size
if self.bit_array[result] == 0:
return "Nope"
return "Probably"2.Python 测试
if __name__ == '__main__':
bf = BloomFilter(500000, 7)
bf.add("bit666")
print(bf.lookup("bit666"))
print(bf.lookup("bit678"))
bit666 -> Probably
bit678 -> Nope虽然我们的 bit666 明面上看是存在的,但是为了返回的严谨性,这里返回的是 Probably 可能。
四.总结
这里简单介绍了 Bloom Filter 布隆过滤器的原理与实现方式,其需要初始化 ByteArray 存放下标,同时需要 k 个 hash 函数得到 hash_index。
除此之外还有误判概率 P 的计算,最佳 Hash 函数 K 的推导以及工业级应用代码博主放在另外一篇博客,有兴趣的同学可以加深学习:?Bloom Filter 应用与推导。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!