掌握HQL--HQL语法全面指南
开篇之前,我们先为HQL做一个简单介绍
HiveSQL是Hive的查询语言,是一种类SQL语言,见名知意,它类似于传统数据库中的SQL。这使得对Hadoop中的数据执行查询变得更加容易,尤其是对那些熟悉SQL的用户.
为什么会有HQL出现呢?
通过Java 或者 Python直接操作MapReduce, 也可以做分析, 但是开发难度稍大.举例在SQL中计算表数据中有多少个‘word’这个单词只需要轻飘飘的一个selece查询一行代码即可,但是在Java,Python这种语言中却需要很多行代码才能完成,所以通过SQL做分析, 相对简单易上手,但是MapReduce并不支持SQL语法,所以HQL应运而生,可以让我们写类SQL语法, 然后Hive底层将其解析成MR来执行,简单的完成我们的需求.
好那么好,我们话不多说直接进入到HQL语法的学习中.
在正式使用Hive之前, 务必确保你的环境是搭建完成并且顺利开启的, 即: 以后你每天开启虚拟机之后, 需要做的事情是:
? ? 1. 在node1中启动 hadoop环境, 历史任务服务, metastore服务, hiveserver2服务.
? ? 2. 查看hiveserver2服务是否成功启动, 如果OK, 则用DataGrip直连Hive即可, 这样就能写HiveSQL语句了.
HQL DDL语句
-
HQL DDL语句--建表(完整格式)
我们直接上干货

HQL DDL语句-之 (完整的)建表语法:
? ? create [external] table 表名(
? ? ? ? 列名1 数据类型 comment '字段的描述信息',
? ? ? ? 列名2 数据类型 comment '字段的描述信息',
? ? ? ? 列名3 数据类型 comment '字段的描述信息',
? ? ? ? ......
? ? ) comment '表的描述信息'
? ? 分区 ? ? ? ? ?partitioned by(分区字段1 数据类型 comment '字段的描述信息', 分区字段2...)
? ? 分桶 ? ? ? ? ?clustered by(分桶字段1, 分桶字段2...) sorted by (排序字段1 asc | desc, 排序字段2...) into 桶的个数 buckets
? ? 行格式切割符 ? row format delimited | SerDe '指定其它的SerDe类, 即: 不同的切割方式'
? ? 存储方式 ? ? ?stored as TextFile | Orc ? ? ?行存储或者列存储
? ? 存储位置 ? ? ?location hdfs的文件路径
? ? 表属性信息 ? ?tblproperties('属性名'='属性值') 例如: 内外部表, 创建者信息, 压缩协议...
? ? ;
上面的建表语法,基本上可以满足我们所有的建表需求,可能有一些大家会看不懂但是在后面都会一一的给大家讲解清楚.
-
HQL涉及到的常用的数据类型
HQL 常用的数据类型: ? ? 原生类型: ? ? ? ? int ? ? ? ? 整数 ? ? ? ? double ? ? ?小数 ? ? ? ? string ? ? ?字符串 ? ? ? ? timestamp ? 时间戳, 单位: 毫秒 ? ? ? ? date ? ? ? ?日期 ? ? 复杂类型; ? ? ? ? array ? 列表(序列) ? ? ? ? map ? ? 映射 ? ? ? ? struct ?结构体 ? ? ? ? union ? 联合体
-
内部表和外部表的区别
关于内部表和外部表的区别,首先我们要知道怎么创建内部表和外部表,直接上代码演示.
创建内部表:
create database day06; use day06; show tables; -- 2. 创建内部表, 射手表. create table t_archer_inner( id int comment 'ID', name string comment '英雄', hp_max int comment '最大生命', mp_max int comment '最大法力', attack_max int comment '最高物攻', defense_max int comment '最大物防', attack_range string comment '攻击范围', role_main string comment '主要定位', role_assist string comment '次要定位' ) comment '射手表' row format delimited fields terminated by '\t'; -- 3. 上传源文件到上述Hive表的HDFS路径下, -- 然后就可以查看表数据了. -- 前提是使用的是Hadoop3,否则使用load上传 select * from t_archer_inner;
怎么才能知道他是内部表呢?
desc formatted t_archer_inner;使用 desc formatted来查看此表的详细信息
我们可以得到如图显示的结果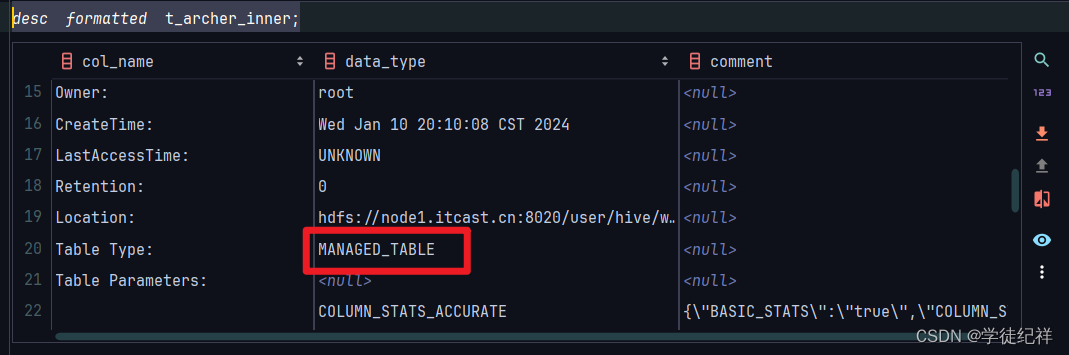
在Table Type(表的类型)一类中,我们可以看到显示的为MANFED_TABLE(受管理的表)也就是内部表
PS.查看表的字段如果发现发现中文注释乱码情况,点这里
下面我们创建外部表:
-- 6. 创建外部表 create external table t_archer_outer( id int comment 'ID', name string comment '英雄', hp_max int comment '最大生命', mp_max int comment '最大法力', attack_max int comment '最高物攻', defense_max int comment '最大物防', attack_range string comment '攻击范围', role_main string comment '主要定位', role_assist string comment '次要定位' ) comment '射手表' row format delimited fields terminated by '\t'; -- 7. 上传源文件到上述Hive表的HDFS路径下, 然后就可以查看表数据了. select * from t_archer_outer;
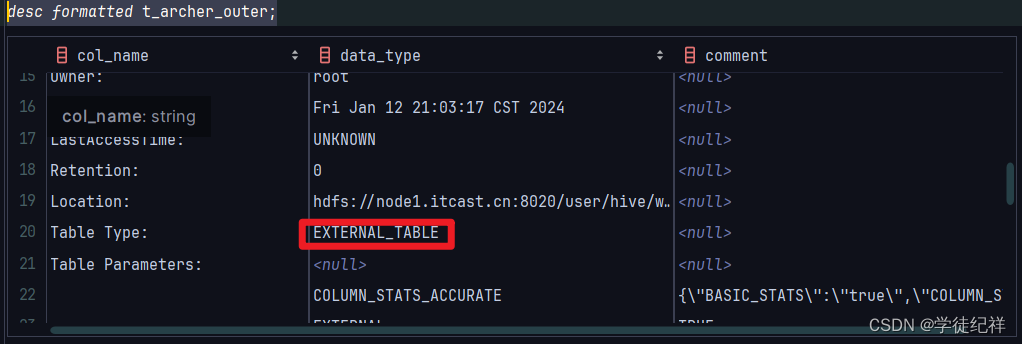
使用 desc formatted来查看此表的详细信息
desc formatted t_archer_outer;?在Table Type(表的类型)一类中,我们可以看到显示的为EXTERNAL_TABLE(不受管理的表)也就是外部表
然后我们尝试删除内部表和外部表
drop table t_archer_inner; -- 不仅会删除元数据, 还会删除源文件.
drop table t_archer_outer; -- 只会删除元数据, 不会删除源文件.我们会发现当内部表被删除时,不仅会删除元数据, 还会删除源文件.
而外部表在被删除时,只会删除元数据, 不会删除源文件.
所以我们就可以回答这个问题
? 1. 建表格式不同.
? ? ? ? 内部表: 直接创建即可, 默认就是内部表.
? ? ? ? 外部表: 建表是需要加 external关键字.
? ? 2. 权限不同, 是否会删除源文件.
? ? ? ? 内部表: 也叫受管理表, 删除内部表时, 不仅会删除元数据(Hive中查不到了), 还会删除源文件(HDFS也查不到了)
? ? ? ? 外部表: 只会删除元数据(Hive中查不到了), 不会删除源文件(HDFS中还在)细节:
? ? 1. 如果某个文件想持久存在(除了Hive用, 其它的框架 例如HBase, Spark也要用), 建Hive表时就选择外部表.
? ? 2. 如果某个HDFS文件是随着Hive表的删除而删除的, 就用内部表.
思考:
? ? 如果我把外部表删了, 又重新的把外部表创建了出来, 请问: 里边还有之前的数据吗?
答案:
? ? 如果表结构, 切割方式, 表的存储位置, 表名等信息不发生改变, 则: 创建出该表后, 默认就有之前的数据.
?
HQL DDL--备份表和删除表数据
问题1: 如何备份表?
答案:
? ? 方式1: 只复制表结构, 包括: 行切割方式.
? ? ? ? create table 备份表名 like 原表名; ? ? ? ?-- 底层不会转成MR任务, 而是直接执行.
? ? 方式2: 复制表结构及表数据, 不包括: 行切割方式.
? ? ? ? create table 备份表名 as select语句; ? ? ?-- 底层会转MR任务, 来执行.
-- 1. 切库, 查表.
use day06;
show tables;
-- 2. 备份表, 方式1: 只复制表结构.
drop table t1;
create table t1 like t_archer_inner; ? ? ? ?-- 底层不会转成MR任务, 而是直接执行.
-- 2.1 查看表结构
desc t1; ? ? ? ? ? ? ? ? ?-- 查看表结构信息, 简单信息
desc formatted t1; ? ? ? ?-- 查看表结构信息, 详细信息
show create table t1; ? ? -- 查看表结构信息, 建表信息
-- 2.2 查看备份表数据
select * from t1; ? ? ? -- 没有数据
-- 2.3 思考: 把 t_archer.txt源文件上传到该表的HDFS路径下, 表中有数据吗, 能成功映射吗?
select * from t1; ? -- 备份的时候, 行切割方式也同步备份了.
-- 3. 备份表, 方式2: 复制表结构及表数据
drop table t2;
create table t2 as select * from t_archer_inner limit 3; ? ? ? ?-- 会转MR
-- 3.1 查看表结构
desc t2; ? ? ? ? ? ? ? ? ?-- 查看表结构信息, 简单信息
desc formatted t2; ? ? ? ?-- 查看表结构信息, 详细信息
show create table t2; ? ? -- 查看表结构信息, 建表信息
-- 3.2 查看表数据.
select * from t2;-- ?思考: 把 t_archer.txt源文件上传到该表的HDFS路径下, 能成功解析吗?
select * from t2; ? -- 备份表只备份结构(列名, 数据类型, 数据), 不会备份表的 切割方式.
HQL DDL--查看及修改表信息
-- ----------- 案例6: HQL DDL--查看及修改表信息 ----------------- -- 1. 查看所有的数据表 show tables; -- 2. 查看表信息. desc t_archer_inner; -- 查看简单信息, 列名, 数据类型, 描述信息 desc formatted t_archer_inner; -- 查看详细信息. show create table t_archer_inner; -- 查看建表信息 -- 3. 修改表名, 格式: alter table 旧表名 rename to 新表名 alter table t_archer_inner rename to t_archer_i; -- alter table t_archer_i rename t_archer_inner; -- 不能省略to, 报错. -- 4. 修改表的存储路径, 看看就行了, 不建议做, 建议: 统一存储, 统一管理. select * from t_archer_i; -- 如果是修改hive表在HDFS的存储路径了, 则hive表数据可能会丢失. show create table t_archer_i; -- 格式: alter table 表名 set location 'hdfs文件的路径' alter table t_archer_i set location '/aa'; -- 5. 修改表属性信息, 内外部表切换. desc formatted t_archer_i; alter table t_archer_i set tblproperties('EXTERNAL'='true'); -- 设置为: 外部表, EXTERNAL必须大写, 后边的true或者false大小写均可(建议大写) alter table t_archer_i set tblproperties('EXTERNAL'='FALSE'); -- 设置为: 内部表, EXTERNAL必须大写, 后边的true或者false大小写均可(建议大写) -- 6. 修改列的相关操作. -- 6.0 查看表结构(列名, 数据类型) desc t_archer_i; select * from t_archer_i; -- 6.1 给表新增列. alter table t_archer_i add columns (kongfu string comment '功夫'); -- 6.2 单独修改指定的列. 注意: string不能直接转成int类型, 反之可以. -- 格式: alter table 表名 change 旧列名 新列名 新数据类型; alter table t_archer_i change attack_max a_m string; alter table t_archer_i change kongfu kf string; -- 修改kongfu列名为 kf alter table t_archer_i change kongfu kf int; -- 报错, string不能直接转int -- 6.3 修改表中给所有的列. -- 格式: alter table 表名 replace columns(列1 数据类型, 列2 数据类型) alter table t_archer_i replace columns (new_id int, new_name string); -- 用新的2列, 替换之前所有的列(10列)
HQL DQL语句--建表-默认切割符
在创建Hive表的时候, 我们可以直接指定 行格式切割符, 即: 按照什么规则来切割HDFS源文件的每行数据.
如果我们没有指定行格式切割符, 则hive表会用默认的行格式切割符, 即: '\001', 它是1个特殊的字符.
? ? 在Linu文件x系统中, 显示为: ^A ? ? ? ?快捷键: ctrl + v, ctrl + a
? ? 在windows文件系统中, 显示为: SOH
? ? 在HDFS文件系统中, 显示为: 口
-- 场景1: 建表, 手动插入数据.
-- 1. 建表.
create table test(
id int comment '编号',
name string comment '姓名'
) ; -- 如果没有指定行格式分隔符, 其实相当于是: row format delimited fields terminated by '\001'
-- 2. 手动往表中添加数据.
insert into test values(1, '乔峰');
-- 3.查看表数据.
-- show create table test;
select * from test;
-- 场景2: 建表, 用于映射指定的文本数据.
drop table team_ace_player;
-- 1. 建表.
create table team_ace_player(
id int comment '战队编号',
team_name string comment '战队名',
ace_name string comment '明星玩家名'
); -- 默认的切割符是'\001', 不写, 其实相当于写了 row format delimited fields terminated by '\001';
-- 2. 上传源文件.
-- 3. 查看表结果.
select * from team_ace_player;HQL DDL语句--快速映射表
Hive的本质就是: 把HDFS文件映射成Hive表, 然后就可以写HQL来操作它了, 底层会被解析成MR任务, 交由Yarn调度执行, 所需的数据源及执行结果会保存到HDFS上.
HQL DML语句
数据导入-load data方式
1. 你要分清楚 数据导入 和 数据导出分别指的是什么.
? ? ? ? 数据导入:
? ? ? ? ? ? Linux, Windows 导入到 Hive表中
? ? ? ? 数据导出:
? ? ? ? ? ? Hive表 导出到?windows, Linux
2. 数据导入相关语法如下:
? ? ? ? 方式1: load data 方式
? ? ? ? 方式2: insert into方式
3. 数据导出相关语法如下:? ?insert??或者 overwrite
数据导入之 load data语法详解:
? ? 格式:
? ? ? ? load data [local] inpath '源文件路径' [overwrite] into table 表名 [partition by(分区字段1, 分区字段2...)];
? ? 格式详解:
? ? ? ? load data ? ? ? 固定格式, 表示: 数据导入
? ? ? ? local ? ? ? ? ? 如果不写, 表示从HDFS路径导入到Hive表, 如果写了, 代表从Linux路径导入到Hive表.
? ? ? ? ? ? ? ? ? ? ? ? Linux系统是本地文件系统, 文件路径前缀为: ?file:/// ? ? 而HDFS文件路径的前缀为: hdfs://node1:8020/
? ? ? ? inpath ? ? ? ? ?后边跟的是具体的(源)文件路径
? ? ? ? overwrite ? ? ? 如果写了, 就是覆盖写入, 不过不写, 就是追加写入.
? ? ? ? into table ? ? ?表示具体导入数据到哪个表中.
? ? ? ? partition by ? ?表示具体的分区, 即: 把数据导入到哪个文件夹中. ? 回顾: 分区 = 分文件夹
?
?核心细节:
? ? ? ? 如果是从Linux文件系统, 导入数据到Hive表, 是从Linux系统中 拷贝一份 上传到HDFS中的.
? ? ? ? 如果是从HDFS文件系统, 导入数据到Hive表, 是从HDFS系统中 剪切该文件 到该Hive表的HDFS路径下.
? ? 简单记忆:
? ? ? ? load data导入的时候, Linux是拷贝, HDFS是剪切
实操:
-- 1. 创建王者英雄表, 存储所有英雄的信息.
create table t_all_hero(
id int comment 'ID',
name string comment '英雄',
hp_max int comment '最大生命',
mp_max int comment '最大法力',
attack_max int comment '最高物攻',
defense_max int comment '最大物防',
attack_range string comment '攻击范围',
role_main string comment '主要定位',
role_assist string comment '次要定位'
) comment '王者荣耀英雄表'
row format delimited fields terminated by '\t';
-- 2. load方式加载数据到上述的表中.
-- 方式1: 从Linux路径 -> 导入到Hive表中.
-- 加载 射手数据, Linux路径, 文件前缀是: file:/// 还可以省略不写.
load data local inpath 'file:///export/hivedata/archer.txt' into table t_all_hero; -- 底层不转MR, 相当于直接把源文件上传到HDFS中.
-- 加载 刺客数据
load data local inpath '/export/hivedata/assassin.txt' into table t_all_hero;
-- 加载 战士数据, 写了overwrite, 表示: 覆盖写入.
load data local inpath '/export/hivedata/warrior.txt' overwrite into table t_all_hero;
-- 方式2: 从HDFS路径 -> 导入到Hive表中.
-- 加载 法师数据到表中. overwrite: 不写就是追加, 写了就是覆盖. local不写就是HDFS路径, 写了就是Linux路径.
-- 细节: hdfs://node1:8020 前缀可以省略不写
load data inpath 'hdfs://node1:8020/hivedata/mage.txt' into table t_all_hero;
-- 细节: hdfs://node1:8020 前缀可以省略不写,
load data inpath '/hivedata/tank.txt' overwrite into table t_all_hero;
-- 3. 查看表数据.
select * from t_all_hero;
HQL DML语句--数据导入-insert方式
格式:
? ? insert into | overwrite table 表名 [partition by(分区字段1, 分区字段2...)] select 语句;
格式解释:
? ? 1. into是追加, overwrite是覆盖.
? ? 2. into的时候, table关键字可以省略不写, overwrite的时候, table关键字必须写.
? ? 3. 上述的语句, 底层会转成MR来执行.
实操:
-- 1. 创建t_all_hero_tmp, 临时的王者荣耀英雄表.
create table t_all_hero_tmp(
id int comment 'ID',
name string comment '英雄',
hp_max int comment '最大生命',
mp_max int comment '最大法力',
attack_max int comment '最高物攻',
defense_max int comment '最大物防',
attack_range string comment '攻击范围',
role_main string comment '主要定位',
role_assist string comment '次要定位'
) comment '王者荣耀英雄表'
row format delimited fields terminated by '\t';
-- 2. 往上述的表中添加数据.
insert into table t_all_hero_tmp select * from t_all_hero limit 5;
insert into t_all_hero_tmp select * from t_all_hero limit 5; -- 细节: into的时候, table可以省略不写.
-- overwrite: 表示 覆盖写入
insert overwrite table t_all_hero_tmp select * from t_all_hero limit 3; -- table不能省略
-- 3. 查看结果.
select * from t_all_hero_tmp;HQL DML语句--导出数据
格式:
? ? insert overwrite [local] directory '存储该文件的路径' [row format delimited fields terminated by '行格式分隔符']
? ? select 语句;
细节:
? ? 1. 不写local就是HDFS路径, 写了就是Linux路径.
? ? 2. 行格式分隔符, 表示导出文件后, 内容之间的 分隔符.
? ? 3. 导出的时候, 是覆盖导出的, 建议要导出到的目录, 内容为空, 否则啥都没了.
实操:
-- 1. 查看数据.
select * from t_all_hero; -- 10条数据
-- 2. 导出 t_all_hero表的数据到 hdfs的 /hivedata 目录下, 该目录下是有3个文件的.
insert overwrite directory '/hivedata'
select * from t_all_hero; -- 默认分隔符.
-- 3. 路径同上, 指定 分隔符
insert overwrite directory '/hivedata'
row format delimited fields terminated by ':'
select * from t_all_hero;
-- 4. 导出 t_all_hero表的数据到 linux的 /hivedata 目录下, 该目录下是有3个文件的.
insert overwrite local directory '/export/hivedata'
row format delimited fields terminated by '$'
select * from t_all_hero;HQL DDL语句
然后我们接着回来说DDL语句,可能有人就要好奇了,为什么不在前面的DDL中一起说了呢,是我忘了吗?并不是,而是接下来讲的必须要学完DML之后才能理解.
分区表-由来
先建一个表
-- -------------------------- 案例1: HQL DDL语句--分区表的由来 -----------------------
-- 需求: 创建t_all_hero表, 存储所有的英雄数据, 要求: 不使用分区表.
-- 1. 建表.
create table t_all_hero(
id int comment 'ID',
name string comment '英雄',
hp_max int comment '最大生命',
mp_max int comment '最大法力',
attack_max int comment '最高物攻',
defense_max int comment '最大物防',
attack_range string comment '攻击范围',
role_main string comment '主要定位',
role_assist string comment '次要定位'
) comment '射手表'
row format delimited fields terminated by '\t';
-- 2. 上传(6个)源文件到该hive表的HDFS路径下.
-- 3. 查看表数据.
select * from t_all_hero;思考: 目前我们已经把所有的数据放到了一张表中, 思考, 这种方式好吗?
4. 新需求: 查询出所有的射手数据.
select * from t_all_hero where role_main='archer';虽然我们实现了需求, 但是需要进行全表扫描, 如何精准的获取到我们想要的数据呢?
答案: 可以采用分区表的思路来管理, 把各个职业的数据放到不同的文件夹中即可.
例如: role=sheshou, 这个文件夹中都是射手的数据role=cike, 这个文件夹中都是刺客的数据, 这样我们检索时, 就可以避免全表扫描, 减少扫描次数, 提高查询效率.
分区表-静态分区
-- 1. 创建分区表, 指定分区字段.
create table t_all_hero_part(
id int comment 'ID',
name string comment '英雄',
hp_max int comment '最大生命',
mp_max int comment '最大法力',
attack_max int comment '最高物攻',
defense_max int comment '最大物防',
attack_range string comment '攻击范围',
role_main string comment '主要定位',
role_assist string comment '次要定位'
) comment '射手表'
partitioned by (role string comment '角色字段-充当分区字段')
-- 核心细节: 分区字段必须是表中没有的字段.
row format delimited fields terminated by '\t';
-- 2. 请问, 上述的分区表, 一共有多少个字段.
desc t_all_hero_part; -- 10个, 9个基础字段 + 1个分区字段
-- 3. 如何往分区表中添加数据呢?
-- 方式1: 静态分区, 即: 手动指定分区字段 和 字段值. 类似于: 静态ip
-- 细节: partition(role='sheshou') 静态分区
load data local inpath '/export/hivedata/archer.txt' into table t_all_hero_part partition(role='sheshou');
load data local inpath '/export/hivedata/assassin.txt' into table t_all_hero_part partition(role='cike');
load data local inpath '/export/hivedata/mage.txt' into table t_all_hero_part partition(role='fashi');
load data local inpath '/export/hivedata/support.txt' into table t_all_hero_part partition(role='fuzhu');
load data local inpath '/export/hivedata/tank.txt' into table t_all_hero_part partition(role='tanke');
load data local inpath '/export/hivedata/warrior.txt' into table t_all_hero_part partition(role='zhanshi');
-- 方式2: 动态分区, 即: 手动指定分区字段即可, 分区字段值一样的数据, 会被放到一起. 类似于: 动态ip
-- 细节: partition(role) 这就是动态分区
-- 下个案例讲解.
-- 4. 查询分区表的数据.
select * from t_all_hero_part;
-- 5. 回顾刚才的新需求: 查询出所有的射手数据.
-- 细节: 如果你设置了分区表, 查询时, 建议带上分区字段.
select * from t_all_hero_part where role_main='archer'; -- 依旧进行了全表扫描.
select * from t_all_hero_part where role='sheshou'; -- 精准扫描某个分区(目录), 避免全表扫描.分区表-动态分区
之前我们已经实现了静态分区, 即: 手动指定分区字段 和 分区字段值, 如果分区过多, 每次写分区字段值比较繁琐, 且有可能写错.
如何解决这个问题呢?
非常简单, 可以通过 动态分区的方式实现, 即: 手动指定分区字段即可, 该字段值一样的数据, 会被自动放到一起.
细节:
? ? 1. 在进行动态分区的时候, 建议: 手动关闭严格模式.
? ? 2. 分区的严格模式要求: 在进行动态分区的时候, 至少要有1个静态分区. 如果都是动态分区, 则: 报错.
? ? ? ?静态分区: ? partition(role='sheshou') ? ? ? ?partition(分区字段='值')
? ? ? ?动态分区: ? partition(role) ? ? ? ? ? ? ? ? ?partition(分区字段)
? ? 3. 动态分区不支持load方式加载数据, 采用 insert into | overwrite方式导入数据.
? ? 4. set 参数名=值; 是在 设置参数值.
? ? ? ?set 参数名; ? ?是在 是在获取(查看)该参数的值.
-- 1. 创建分区表.
create table t_all_hero_part_dynamic(
id int comment 'ID',
name string comment '英雄',
hp_max int comment '最大生命',
mp_max int comment '最大法力',
attack_max int comment '最高物攻',
defense_max int comment '最大物防',
attack_range string comment '攻击范围',
role_main string comment '主要定位',
role_assist string comment '次要定位'
) comment '射手表'
partitioned by (role string comment '角色字段-充当分区字段')
-- 核心细节: 分区字段必须是表中没有的字段.
row format delimited fields terminated by '\t';
-- 2. 尝试用load方式加载数据.
-- 报错, 动态分区不支持load语法, 只支持 insert into | overwrite语法.
load data local inpath '/export/hivedata/archer.txt' into table t_all_hero_part_dynamic partition(role);
-- 3. 关闭严格模式.
set hive.exec.dynamic.partition.mode=nonstrict;
-- nonstrict 非严格模式, strict: 严格模式(默认)
-- 4. 动态分区的方式, 添加数据.
insert into table t_all_hero_part_dynamic partition(role)
select *, role_main from t_all_hero;
-- 5. 查询分区表的数据.
select * from t_all_hero_part_dynamic;
-- 5. 回顾刚才的新需求: 查询出所有的射手数据.
-- 细节: 如果你设置了分区表, 查询时, 建议带上分区字段.
select * from t_all_hero_part_dynamic where role_main='archer';
-- 依旧进行了全表扫描.
select * from t_all_hero_part_dynamic where role='sheshou';
-- 精准扫描某个分区(目录), 避免全表扫描.分区表--多级分区相关操作
到目前为止, 我们已经学会了静态分区 和 动态分区, 但是上述的分区案例都是 单级分区, 实际开发中, 如果数据量比较大的情况下,
可以考虑采用 多级分区的思路来解决, 多级分区一般用 时间来分区, 可以是: 年, 月, 日...
细节: 多级分区的时候, 分区层级不建议超过 3级, 一般是: 年, 月2级就够了.
-- 1. 创建商品表, 按照: 年, 月分区.
create table products(
pid int,
pname string,
price int,
cid string
) comment '商品表'
partitioned by (year int, month int) -- 按照年, 月分区, 2级分区
row format delimited fields terminated by ',';
-- 2. 查看所有的分区信息.
show partitions products;
-- 3. 手动添加分区.
-- 3.1 添加1个分区.
alter table products add partition(year=2023, month=1);
-- 3.2 添加多个分区.
alter table products add partition(year=2023, month=4) partition(year=2023, month=5) partition(year=2023, month=11);
alter table products add partition(year=2024, month=1) partition(year=2024, month=5) partition(year=2024, month=10);
-- 4. 修改分区. 例如: 把2024年10月 => 2024年8月
alter table products partition(year=2024, month=10) rename to partition(year=2024, month=08);
-- 5. 删除分区.
alter table products drop partition(year=2023, month=4); -- 删除2023年4月 这个分区
alter table products drop partition(month=1); -- 删除所有的1月 这个分区
alter table products drop partition(year=2023); -- 删除2023年 及其所有的子分区.
-- 6. 查看商品表数据.
select * from products;
-- 7. 精准查看某个分区的数据.
select * from products where year=2023; -- 查找2023年 分区内, 所有的数据.
select * from products where year=2023 and month=1; -- 查找2023年, 1月 分区内, 所有的数据.分桶表-入门
分桶表介绍:
? ? 概述:
? ? ? ? 分桶 = 分文件, 相当于把数据 根据分桶字段, 拆分成N个文件.
? ? 作用:
? ? ? ? 1. 方便进行数据采样.
? ? ? ? 2. 减少join的次数, 提高查询效率.
? ? 细节:
? ? ? ? 1. 分桶字段必须是表中已有的字段.
? ? ? ? 2. 分桶数量 = HDFS文件系统中, 最终的文件数量.
实操:
-- 1. 创建普通的学生表(充当数据源表), 上传源文件, 然后查看数据.
create table student(
sid int,
name string,
gender string,
age int,
major string
) comment '学生信息表'
row format delimited fields terminated by ',';
select * from student;
-- 2. 创建分桶表-学生表, 按照学生id进行分桶, 分成 3 个桶.
create table student_buckets(
sid int,
name string,
gender string,
age int,
major string
) comment '学生信息表'
clustered by (sid) into 3 buckets -- 按照学生id进行分桶, 分成 3 个桶.
row format delimited fields terminated by ',';
-- 3. 往 分桶表中插入数据.
insert into table student_buckets select * from student;
-- 4. 查看分桶表结果.
select * from student_buckets;分桶表--分桶+排序
-- 1. 创建分桶表-学生表, 按照学生id进行分桶, 分成 3 个桶, 桶内部按照 age 降序排列.
drop table student_buckets_sort;
create table student_buckets_sort(
sid int,
name string,
gender string,
age int,
major string
) comment '学生信息表'
-- clustered by (sid) sorted by (sid) into 3 buckets
-- 按照学生id进行分桶, 分成 3 个桶, 桶内部按照 sid 升序排列.
clustered by (sid) sorted by (age desc) into 3 buckets
-- 按照学生id进行分桶, 分成 3 个桶, 桶内部按照 age 降序排列.
row format delimited fields terminated by ',';
-- 2.往上述的分桶排序表中, 添加数据.
insert into student_buckets_sort select * from student;
-- 3. 查询结果.
select * from student_buckets_sort;复杂类型--array
-- 数据格式为: "zhangsan beijing,shanghai,tianjin,hangzhou"
-- 1. 建表.
create table t_array(
name string comment '姓名',
city array<string> comment '出差城市' -- array类似于Python的列表, 就是容器类型. <string>意思是: 泛型, array中只能存储字符串类型数据.
)
row format delimited fields terminated by '\t' -- 切割后, 数据格式为: "zhangsan", "beijing,shanghai,tianjin,hangzhou"
collection items terminated by ','; -- 切割后, 数据格式为: "zhangsan", ["beijing", "shanghai" ,"tianjin", "hangzhou"]
-- 2. 上传源文件, Hive表自动解析.
-- 3. 查看表结果.
select * from t_array;
-- 4. 完成如下的需求.
-- 查询所有数据
select * from t_array;
-- 查询city数组中第一个元素
select name, city[0] from t_array; -- 字段名[索引], 索引从刚开始计数.
-- 查询city数组中元素的个数
select name, city, size(city) from t_array; -- size(复杂类型) 可以查看该复杂类型的元素个数.
-- 查询city数组中包含tianjin的信息
-- 格式: array_contains(复杂类型字段, 要判断的值) 判断该值是否在 该复杂类型的变量中, True: 在, False: 不在.
select name, city, array_contains(city, 'tianjin') from t_array;
-- 只获取 city列 包含 'tianjin' 的数据
select name, city from t_array where array_contains(city, 'tianjin') = true;
-- 最终版写法: 因为 array_contains()函数返回结果就是True 或者False, 所以可以直接写.
select name, city from t_array where array_contains(city, 'tianjin'); -- 要city列 包含tianjin的
select name, city from t_array where not array_contains(city, 'tianjin'); -- 要city列 不包含tianjin的复杂类型--struct
结构体类型较之于数组类型, 区别是: 结构体类型可以设置 子列的类型和名称.
对比为: array<string>, ? ?struct<name:string, age:int>
相同点是: 都可以存储多个元素.
-- 1. 建表. 数据源格式为: "1#周杰轮:11"
create table t_struct(
id int,
info struct<name:string, age:int>
)
row format delimited fields terminated by '#' -- 切割后: "1", "周杰轮:11"
collection items terminated by ':'; -- collection items 是负责切割: 数组, 结构体的
-- 2. 上传源文件.
-- 3. 查看表数据.
select * from t_struct;
-- 4. 细节: 列名.子列名 可以获取子列的信息.
select id, info.name, info.age from t_struct;复杂类型--map
map映射类型: 类似于Python的字典, Java中的Map集合, 存储的是键值对数据, 左边的叫: 键(key), 右边的叫: 值(value)
create table t_map(
id int comment '编号',
name string comment '姓名',
members map<string, string> comment '家庭成员', -- 左边的string: 键的类型, 右边的string: 值的类型.
age int comment '年龄'
)
row format delimited fields terminated by ','
collection items terminated by '#'
map keys terminated by ':';
-- 2. 上传源文件.
-- 3. 查看表数据.
select * from t_map;HQL DQL语句
HQL DQL--基本查询
与SQL规则一致,不多做阐述了
HQL DQL语句--join连接查询
join连接查询是多表查询的方式, 它具体有 6种查询方式, 分别是: 交叉连接, 内连接, 左外连接, 右外连接, 满外连接(全外连接), 左半连接,
与SQL不同的就是多两项?满外连接(全外连接), 左半连接?
演示上面两项
CREATE TABLE employee(
id int, -- 员工id
name string,
deg string,
salary int,
dept string
) row format delimited fields terminated by ',';
--table2:员工家庭住址信息表
CREATE TABLE employee_address (
id int, -- 员工id
hno string,
street string,
city string
) row format delimited fields terminated by ',';
-- 2. 查看表数据.
select * from employee;
select * from employee_address;
-- 满外连接(全外连接)查询, full outer join, 其中outer可以省略不写, 查询结果为: 左表全集 + 右表全集 + 表的交集.
-- 细节: 满外连接 = 左外连接 + 右外连接 查询结果.
select * from employee e1 full outer join employee_address e2 on e1.id = e2.id; -- 6条
select * from employee e1 full join employee_address e2 on e1.id = e2.id; -- 6条
-- 左半连接, left semi join, , 查询结果为: 表的交集.
-- 细节: 左半连接 相当于 内连接的查询结果, 只要左表部分.
select * from employee e1 left semi join employee_address e2 on e1.id = e2.id; -- 4条, 只有左表的数据.HQL DQL语句--分桶查询
分桶查询介绍:
? ? 概述:
? ? ? ? 分桶查询就是根据分桶字段, 把表数据分成n份, 但是: 是逻辑划分, 不是物理划分.
? ? ? ? 逻辑划分: 类似于分组, 就是根据分桶字段值 进行分组, HDFS上文件还是1个.
? ? ? ? 物理划分: 就是昨天的分桶建表, HDFS上存储数据的时候, 已经变成了N个文件.
? ? 格式:
? ? ? ? cluster by 分桶排序字段 | distribute by 分桶字段 sort by 排序字段 asc | desc
? ? 细节:
? ? ? ? 1. 分桶查询是 逻辑分桶, 把数据分成n组进行查询, 但是HDFS上还是1个文件.
? ? ? ? ? ?分桶建表是 物理分桶, 数据在HDFS上会被存储到N个文件几种.
? ? ? ? 2. 分桶查询需要用到 set mapreduce.job.reduces = n; 这个n就是ReduceTask任务的数量, 即: 分几个桶.
? ? ? ???3. mapreduce.job.reduces 参数的值默认是 -1, 即: 程序会按照数据量, 任务量自动分配ReduceTask的个数, 一般是1个, 即: 1个桶.
? ? ? ? 4. distribute by 表示分桶, sort by表示对桶内的数据进行排序(局部排序), 如果分桶字段和排序字段是同1个, 则可以简写为: cluster by
HQL DQL--随机抽样
随机抽样解释:
? ? 概述:
? ? ? ? 随机采样指的是 tablesample()函数, 通过它, 我们可以用 类似于分桶的思路, 对数据进行采样.
? ? 格式:
? ? ? ? select .. from 表名 tablesample(bucket x out of y on 列名 | rand());
? ? 格式解释:
? ? ? ? 1. y表示: 把数据分成y个桶. ? 逻辑分桶.
? ? ? ? 2. x表示: 从y个分桶中, 获取第x份数据.
? ? ? ? 3. 如果是列名方式, 列名采样, 在列名等其它条件不发生改变的情况下, 每次采样获取的数据都是一样的.
? ? ? ? 4. 如果是rand()函数, 随机采样, 则: 每次获取的数据都是不一样的.
? ? ? ? 5. x 不能大于 y
HQL DQL--union联合查询
union 联合查询介绍:
? ? 概述:
? ? ? ? 就是对表数据做纵向拼接的, 类似于书本的 上, 下册, 有两种拼接方式.
? ? 分类:
? ? ? ? union distinct ? ? ?-- distinct可以省略不写, 合并 并去重.
? ? ? ? union all ? ? ? ? ? -- 合并 不去重.
? ? 细节:
? ? ? ? 1. union all 和 distinct 作用类似, 都是纵向合并, 区别就是: 去不去重的问题.
? ? ? ? 2. 直接写union 默认是 union distinct, 即: 去重合并.
? ? ? ? 3. 要进行union联合查询的数据, 列的个数, 对应的数据类型都要一致.
? ? ? ? 4. 如果条件写到上边的 查询语句后, 则: 单独作用于该SQL.
? ? ? ? ? ?如果条件写到下边的 查询语句后, 则: 作用于全局.
那么文章到此截止,不足之处请各位大佬多多指教
愿你在大数据的海洋中航行顺风,发现属于你的数据宝藏!🚢💻
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 前端桌面通知(Desktop Notifications)API
- 比 Eslint 快 100 倍!新一代 JS Linter 发布!
- Nestjs 微服务实战 - 动态微服务创建链接
- TypeScript基础(三)扩展类型-接口和类型兼容性
- 如何防勒索病毒
- 广州华锐互动:汽车电子线束加工VR仿真培训与实际生产场景相结合,提高培训效果
- 【打卡】牛客网:BM69 把数字翻译成字符串
- vue3-elementPlus主题色定制
- matlab Robotics System Toolbox
- 关于网络安全 的 ARP欺骗 实验操作