一文搞懂性能测试(超详细总结)
🍅 视频学习:文末有免费的配套视频可观看
🍅?关注公众号【互联网杂货铺】,回复 1?,免费获取软件测试全套资料,资料在手,涨薪更快
性能测试概念
我们经常看到的性能测试概念,有人或称之为性能策略,或称之为性能方法,或称之为性能场景分类,大概可以看到性能测试、负载测试、压力测试、强度测试等一堆专有名词的解释。
针对这些概念,我不知道你看到的时候会不会像我的感觉一样:乱!一个小小的性能测试,就延伸出了这么多的概念,并且概念之间的界限又非常模糊。
就拿“压力测试”、“容量测试”和“极限测试”这三个概念来说吧。
网上针对这三个名词的解释是这样的:
压力测试
压力测试是评估系统处于或超过预期负载时系统的运行情况。压力测试的关注点在于系统在峰值负载或超出最大载荷情况下的处理能力。在压力级别逐渐增加时,系统性能应该按照预期缓慢下降,但是不应该崩溃。压力测试还可以发现系统崩溃的临界点,从而发现系统中的薄弱环节。
容量测试
确定系统可处理同时在线的最大用户数,使系统承受超额的数据容量来发现它是否能够正确处理。
极限测试
在过量用户下的负载测试。
“压力测试是在超过预期负载时系统的运行情况”,“容量测试是使系统承受超额的数据容量来发现它是否能够正确处理”。
来吧,就算我语文不好,我也认字的,谁能告诉我这两者的区别是什么?除了字不一样。
如果再抽象一层说一下这些概念,那就是,这些概念都在描述性能测试的不同侧面。而这些侧面本身构不成策略,构不成方法,不能说是概念,也不能说是理论。
此文一出,肯定会有人说,既然你评价当前的概念混乱,那你有什么好建议呢?作为可能被集体轰炸的话题,既然已经摆上了台面,我还是要冒死给一个自己认为的合理定义:
性能测试针对系统的性能指标,建立性能测试模型,制定性能测试方案,制定监控策略,在场景条件之下执行性能场景,分析判断性能瓶颈并调优,最终得出性能结果来评估系统的性能指标是否满足既定值。
这是我觉得唯一合理的概念定义,下面我就把这个概念详细解释一下。
性能测试需要有指标
有人说,我们在做项目的时候,就没有指标,老板只说一句,系统压死为止。听起来很儿戏,但这样的场景不在少数。在我看来,把系统压死也算是一种指标。至于你用什么手段把系统“压死”,那就是实现的问题了。你可以采用很多种手段,告诉老板,这系统还没压就死了! 这也是你的贡献。
而对“有指标”这个定义来说,理论上合理的,并且应该有的指标是:时间指标、容量指标和资源利用率指标。
而这里的指标又会有细分,细分的概念又是一团乱。这个话题我们后面再描述。
性能测试需要有模型
模型是什么?它是真实场景的抽象,可以告诉性能测试人员,业务模型是什么样子。比如说,我们有100种业务,但不是每个业务都需要有并发量,可能只有50个业务有,那就要把这些有并发的业务统计出来,哪个业务并发多,哪个业务并发少,做压力时就要控制好这样的比例。
这种做法需要的数据通常都是从生产环境中的数据中统计来的,很多在线上不敢直接压测的企业都是这样做的。
而随着互联网中零售业、云基础架构的全面发展,有些企业直接在线上导流来做性能测试,这种思路上的转变来源于架构的发展及行业的真实需要。但这并不能说明性能测试不需要模型了,因为这个模型已经从生产流量中导过来了。这一点,还是需要你认清的。
但是对于其他的一些行业,比如银行这类金融机构,线上一个交易都不能错。像上面这样做的难度就太大了。所以这些行业中,仍然需要在测试环境中用业务模型来模拟出生产的流量。
同时也请你认清一点,现在的全链路压测,并没有像吹嘘得那么神乎其神,很多企业也只是在线上的硬件资源上做压力而已,并不是真正的逻辑链路修改。
我在工作中经常会被问到,性能流量直接从生产上导的话,是不是就可以不用性能测试人员了?性能测试人员就要被淘汰了?
这未免太短视了,大家都盯着最新鲜的技术、方法、概念,各层的领导也都有自己的知识偏好,万一做了一个决定,影响了最终的结果,有可能会让很多人跟着受罪。
我之前带过的一个团队中,开发架构们一开始就规划了特别详细的微服务架构,说这一套非常好。我说这个你们自己决定,我只要在这里面拿到可用的结果就行。结果开发了不到两个月,一个个微服务都被合并了,还得天天加班做系统重构,只留了几大中台组件。这是为什么呢?因为不适用呀。
同理,性能测试也要选择适合自己系统业务逻辑的方式,用最低的成本、最快的时间来做事情。
性能测试要有方案
方案规定的内容中有几个关键点,分别是测试环境、测试数据、测试模型、性能指标、压力策略、准入准出和进度风险。基本上有这些内容就够了,这些内容具体的信息还需要精准。
你可能会说,怎么没有测试计划?我的建议是,用项目管理工具单独画测试计划,比如用Project或OmniPlan之类的工具。这是因为在方案中,写测试计划,基本上只能写一个里程碑,再细化一点,就是在里面再加几个大阶段的条目。但是用项目管理工具做计划就不同了,它不仅可以细分条目,还能跟踪各个工作的动态进度,可以设置前后依赖关系,填入资源和成本以便计算项目偏差。
性能测试中要有监控
这个部分的监控,要有分层、分段的能力,要有全局监控、定向监控的能力。关于这一点,我将在第三模块详细说明。
性能测试要有预定的条件
这里的条件包括软硬件环境、测试数据、测试执行策略、压力补偿等内容。要是展开来说,在场景执行之前,这些条件应该是确定的。
有人说,我们压力中也会动态扩展。没问题,但是动态扩展的条件或者判断条件,也是有确定的策略的,比如说,我们判断CPU使用率达到80%或I/O响应时间达到10ms时,就做动态扩展。这些也是预定的条件。
关于这一点,在我的工作经历中,经常看到有性能测试工程师,对软硬件资源、测试数据和执行策略分不清楚,甚至都不明白为什么要几分钟加几个线程。在这种情况之下,就不能指望这个场景是有效的了。
性能测试中要有场景
可以说,“性能场景”这个词在性能测试中占据着举足轻重的地位,只是我们很多人都不理解“场景”应该如何定义。场景来源于英文的scenario,对性能场景中的“场景”比较正宗的描述是:在既定的环境(包括动态扩展等策略)、既定的数据(包括场景执行中的数据变化)、既定的执行策略、既定的监控之下,执行性能脚本,同时观察系统各层级的性能状态参数变化,并实时判断分析场景是否符合预期。
这才是真正的场景全貌。
性能场景也要有分类,在我有限的工作经验中,性能场景从来都没有超出过这几个分类。
-
基准性能场景:这里要做的是单交易的容量,为混合容量做准备(不要跟我说上几个线程跑三五遍脚本叫基准测试,在我看来,那只是场景执行之前的预执行,用来确定有没有基本的脚本和场景设计问题,不能称之为一个分类)。
-
容量性能场景:这一环节必然是最核心的性能执行部分。根据业务复杂度的不同,这部分的场景会设计出很多个,在概念部分就不细展开了,我会在后面的文章中详细说明。
-
稳定性性能场景:稳定性测试必然是性能场景的一个分类。只是现在在实际的项目中,稳定性测试基本没和生产一致过。在稳定性测试中,显然最核心的元素是时间(业务模型已经在容量场景中确定了),而时间的设置应该来自于运维周期,而不是来自于老板、产品和架构等这些人的心理安全感。
-
异常性能场景:要做异常性能场景,前提就是要有压力。在压力流量之下,模拟异常。这个异常的定义是很宽泛的,在下一篇文章里,我们再细说。
很多性能测试工程师,都把场景叫成了测试用例。如果只是叫法不同,我觉得倒是可以接受,关键是内容也出现了很大的偏差,这个偏差就是,把用例限定在了描述测试脚本和测试数据上,并没有描述需要实时的判断和动态的分析。这就严重影响了下一个概念:性能结果。
性能测试中要有分析调优
一直以来,需不需要在性能测试项目中调优,或者说是不是性能测试工程师做调优,人们有不同的争论。
从性能市场的整体状态来看,在性能测试工程师中,可以做瓶颈判断、性能分析、优化的人并不多,所以很多其他职位上的人对性能测试的定位也就是性能验证,并不包括调优的部分。于是有很多性能项目都定义在一两周之内。这类项目基本上也就是个性能验证,并不能称之为完整的性能项目。而加入了调优部分之后,性能项目就会变得复杂。对于大部分团队来说,分析瓶颈都可能需要很长时间,这里会涉及到相关性分析、趋势分析、证据链查找等等手段。
所以,就要不要进行调优,我做了如下划分。
对性能项目分为如下几类。
-
新系统性能测试类:这样的项目一般都会要求测试出系统的最大容量,不然上线心里没底。
-
旧系统新版本性能测试类:这样的项目一般都是和旧版本对比,只要性能不下降就可以根据历史数据推算容量,对调优要求一般都不大。
-
新系统性能测试优化类:这类的系统不仅要测试出最大容量,还要求调优到最好。
对性能团队的职责定位有如下几种。
-
性能验证:针对给定的指标,只做性能验证。第三方测试机构基本上都是这样做的。
-
性能测试:针对给定的系统,做全面的性能测试,可以得到系统最大容量,但不涉及到调优。
-
性能测试+分析调优:针对给定的系统,做全面的性能测试,同时将系统调优到最优状态。
当只能做性能验证的团队遇到旧系统新版本性能测试类和新系统性能测试优化类项目,那就会很吃力,这样的团队只能做新系统性能测试类项目。
当做性能测试的团队,遇到需要新系统性能测试优化类项目,照样很吃力。这样的团队能做前两种项目。
只有第三个团队才能做第三种项目。
性能测试肯定要有结果报告
性能结果如何来定义呢?有了前面监控的定义,有了场景执行的过程,产生的数据就要整理到结果报告中了。这个文档工作也是很重要的,是体现性能团队是否专业的一个重要方面。并不是整理一个Word,美化一下格式就可以了。测试报告是需要汇报或者归档的。
如果是内部项目,测试报告可能就是一个表格,发个邮件就完整了,另外归档也是必须的。而对一些有甲乙方的项目,就需要汇报了。
那么,如何汇报呢?
我们要知道,大部分老板或者上司关心的是测试的结果,而不是用了多少人,花了多少时间这些没有意义的数字。我们更应该在报告中写上调优前后的TPS、响应时间以及资源对比图。
有了上面的的解析,相信你对性能测试的定义有了明确的感觉了。这个定义其实就是描述了性能测试中要做的事情。
当然,也许会有人跳出来说,你这个说得太重了,不够敏捷。现在不都用DevOps了吗?还要按这个流程来走一遍吗?
显然有这种说法的人,没有理解我要说的主旨。以上的内容是针对一个完整的项目,或系统或公司的系统演进。对于一些半路就跟着版本和新需求一轮轮迭代做下去的人的处境会不同,因为这样的人只看到了当前的部分,而不是整个过程。
并且这个过程也是不断在迭代演进的。
不管是敏捷开发过程还是DevOps,你可以一条条去仔细分析下项目中的各个环节(我说的是整个项目从无到有),都不会跳出以上定义,如果有的话,请随时联系我,我好改定义。:)
通过图示最后总结一下性能测试的概念:

有了这个图示之后,就比较清晰了。
所以,前面所说的压力测试、容量测试、负载测试等等,在实际的项目实施过程中,都不具备全局的指导价值。我个人认为,你应该在性能领域中抛弃这些看似非常有道理实则毫无价值的概念。
性能场景TPS和响应时间
前面我们说了性能要有场景,也说了性能场景要有基准性能场景、容量性能场景、稳定性性能场景、异常性能场景。下面我将对前面说到的概念进行一一对应。
学习性能的人,一定看吐过一张图,现在让你再吐一次。如下:
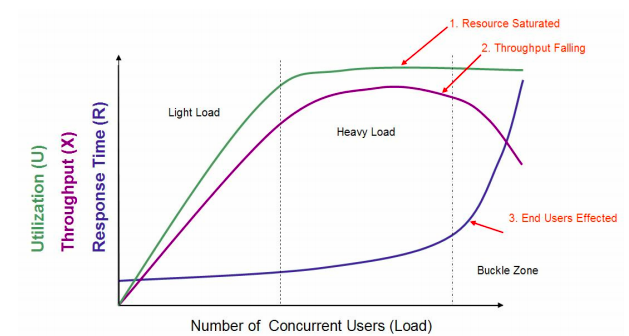
在这个图中,定义了三条曲线、三个区域、两个点以及三个状态描述。
-
三条曲线:吞吐量的曲线(紫色)、利用率(绿色)、响应时间曲线(深蓝色)。
-
三个区域:轻负载区(Light Load)、重负载区(Heavy Load)、塌陷区(Buckle Zone)。
-
两个点:最优并发用户数(The Optimum Number of Concurrent Users)、最大并发用户数(The Maximum Number of Concurrent Users)。
-
三个状态描述:资源饱和(Resource Saturated)、吞吐下降(Throughput Falling)、用户受影响(End Users Effected)。
我在很多地方,都看到了对这张图的引用。应该说,做为一个示意图,它真的非常经典,的确描述出了一个基本的状态。但是,示意图也只能用来做示意图,在具体的项目中,我们仍然要有自己明确的判断。
我们要知道,这个图中有一些地方可能与实际存在误差。
首先,很多时候,重负载区的资源饱和,和TPS达到最大值之间都不是在同样的并发用户数之下的。比如说,当 CPU 资源使用率达到 100% 之后,随着压力的增加,队列慢慢变长,响应时间增加,但是由于用户数增加的幅度大于响应时间增加的幅度之前,TPS 仍然会增加,也就是说资源使用率达到饱和之后还有一段时间TPS才会达到上限。
大部分情况下,响应时间的曲线都不会像图中画得这样陡峭,并且也不一定是在塌陷区突然上升,更可能的是在重负载区突然上升。
另外,吞吐量曲线不一定会出现下降的情况,在有些控制较好的系统中会维持水平。曾经在一个项目中,因为TPS维持水平,并且用户数和响应时间一直都在增加,由于响应时间太快,一直没有超时。我跟我团队那个做压力的兄弟争论了三个小时,我告诉他接着压下去已经没有意义,就是在等超时而已。他倔强地说,由于没有报错,时间还在可控范围,所以要一直加下去。关于这一点争论,我在后续的文章中可能还会提及。
最优并发数这个点,通常只是一种感觉,并没有绝对的数据用来证明。在生产运维的过程中,其实我们大部分人都会更为谨慎,不会定这个点为最优并发,而是更靠前一些。
最大并发数这个点,就完全没有道理了,性能都已经衰减了,最大并发数肯定是在更前的位置呀。这里就涉及到了一个误区,压力工具中的最大用户数或线程数和TPS之间的关系。在具体的项目实施中,有经验的性能测试人员,都会更关心服务端能处理的请求数即TPS,而不是压力工具中的线程数。
这张图没有考虑到锁或线程等配置不合理的场景,而这类场景又比较常见。也就是我们说的,TPS上不去,资源用不上。所以这个图默认了一个前提,只要线程能用得上,资源就会蹭蹭往上涨。
这张图呢,本来只是一个示意,用以说明一些关系。但是后来在性能行业中,有很多没有完全理解此图的人将它做为很有道理的“典范”给一些人讲,从而引起了越来越多的误解。
我们简化出另一个图形,以说明更直接一点的关系。如下所示:

上图中蓝线表示TPS,黄色表示响应时间。
在TPS增加的过程中,响应时间一开始会处在较低的状态,也就是在A点之前。接着响应时间开始有些增加,直到业务可以承受的时间点B,这时TPS仍然有增长的空间。再接着增加压力,达到C点时,达到最大TPS。我们再接着增加压力,响应时间接着增加,但TPS会有下降(请注意,这里并不是必然的,有些系统在队列上处理得很好,会保持稳定的TPS,然后多出来的请求都被友好拒绝)。
最后,响应时间过长,达到了超时的程度。
在我的工作中,这样的逻辑关系更符合真实的场景。我不希望在这个关系中描述资源的情况,因为会让人感觉太乱了。
为什么要把上面描述得如此精细?这是有些人将第一张图中的Light load对应为性能测试,Heavy Load对应为负载测试,Buckle Zone对应为压力测试……还有很多的对应关系。
事实上,这是不合理的。
下面我将用场景的定义来替换这些混乱的概念。
为什么我要如此划分?因为在具体场景的操作层面,只有场景中的配置才是具体可操作的。而通常大家认为的性能测试、负载测试、压力测试在操作的层面,只有压力工具中线程数的区别,其他的都在资源分析的层面,而分析在很多人的眼中,都不算测试。
拿配置测试和递增测试举例吧。
在性能中,我们有非常多的配置,像JVM参数、OS参数、DB参数、网络参数、容器参数等等。如果我们把测试这些配置参数,称为“配置测试”,我觉得未免过于狭隘了。因为对于配置参数来说,这只是做一个简单的变更,而性能场景其实没有任何变化呀。配置更改前后,会用同样的性能场景来判断效果,最多再增加一些前端的压力,实际的场景并没有任何变化,所以,我觉得它不配做为一个单独的分类。
再比如递增测试,在性能中,基准性能场景也好,容量性能场景也好,哪个是不需要递增的呢?我知道现在市场上经常有测试工程师,直接就上了几百几千线程做压力(请你不要告诉我这是个正常的场景,鉴于我的精神有限,承受不了这样的压力)。除了秒杀场景,同时上所有线程的场景,我还没有见到过。在一般的性能场景中,递增都是必不可少的过程。同时,递增的过程,也要是连续的,而不是100线程、200线程、300线程这样断开执行场景,这样是不合理的。关于这一点,我们将在很多地方着重强调。所以我觉得递增也不配做一个单独的分类。
其他的概念,就不一一批驳了。其实在性能测试中,在实际的项目实施中,我们并不需要这么多概念,这些杂七杂八的概念也并没有对性能测试领域的发展起到什么推进作用。要说云计算、AI、大数据这些概念,它们本身在引导着一个方向。
而性能测试中被定为“测试”,本身就处在软件生存周期的弱势环节,当前的市场发展也并不好。还被这些概念冲乱了本来应该有的逻辑的思路,实在是得不偿失。
理解TPS、QPS、RT、吞吐量这些性能指标
通常我们都从两个层面定义性能场景的需求指标:业务指标和技术指标。
这两个层面需要有映射关系,技术指标不能脱离业务指标。一旦脱离,你会发现你能回答“一个系统在多少响应时间之下能支持多少TPS”这样的问题,但是回答不了“业务状态是什么”的问题。
举例来说,如果一个系统要支持1000万人在线,可能你能测试出来的结果是系统能支持1万TPS,可是如果问你,1000万人在线会不会有问题?这估计就很难回答了。
我在这里画一张示意图以便你理解业务指标和性能指标之间的关系。
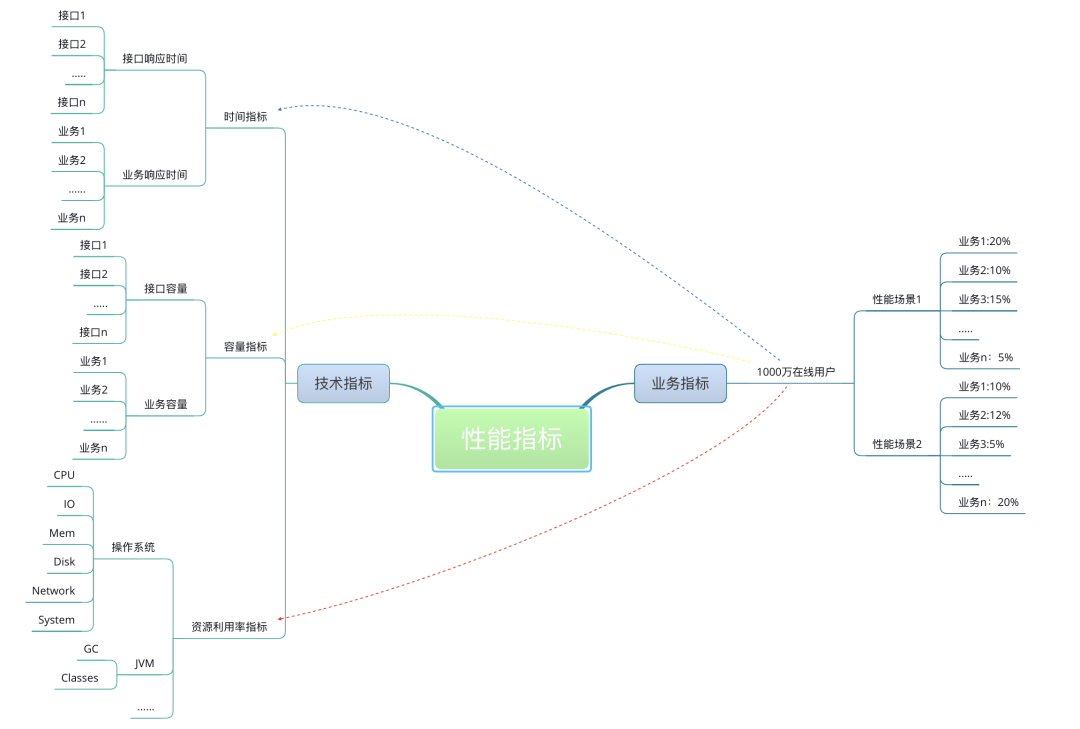
这个示意显然不够详细,但也能说明关系了。所有的技术指标都是在有业务场景的前提下制定的,而技术指标和业务指标之间也要有详细的换算过程。这样一来,技术指标就不会是一块飞地。同时,在回答了技术指标是否满足的同时,也能回答是否可以满足业务指标。
有了这样的关联关系,下面我们看一下性能测试行业常用的性能指标表示法。
我将现在网上能看到的性能指标做了罗列,其中不包括资源的指标。因为资源类的比较具体,并且理解误差并不大,但业务类的差别就比较大了。
对这些性能指标都有哪些误解
我记得我还年轻的时候,还没有QPS、RPS、CPS这样的概念,只有TPS。那个时候,天总是那么蓝,时间总是那么慢,“你锁了人家就懂了”。
QPS一开始是用来描述MySQL中SQL每秒执行数Query Per Second,所有的SQL都被称为Query。后来,由于一些文章的转来转去,QPS被慢慢地移到了压力工具中,用来描述吞吐量,于是这里就有些误解,QPS和TPS到底是什么关系呢?
RPS指的是每秒请求数。这个概念字面意思倒是容易理解,但是有个容易误解的地方就是,它指的到底是哪个层面的Request?如果说HTTP Request,那么和Hits Per Second又有什么关系呢?
HPS,这也是个在字面意思上容易理解的概念。只是Hit是什么?有人将它和HTTP Request等价,有人将它和用户点击次数等价。
CPS,用的人倒是比较少,在性能行业中引起的误解范围并不大。同时还有喜欢用CPM(Calls Per Minute,每分钟调用数)的。这两个指标通常用来描述Service层的单位时间内的被其他服务调用的次数,这也是为什么在性能行业中误解不大的原因,因为性能测试的人看Service层东西的次数并不多。
为了区分这些概念,我们先说一下TPS(Transactions Per Second)。我们都知道TPS是性能领域中一个关键的性能指标概念,它用来描述每秒事务数。我们也知道TPS在不同的行业、不同的业务中定义的粒度都是不同的。所以不管你在哪里用TPS,一定要有一个前提,就是?所有相关的人都要知道你的T是如何定义的。
经常有人问,TPS应该如何定义?这个实在是没有具体的“法律规定”,那就意味着,你想怎么定就怎么定。
通常情况下,我们会根据场景的目的来定义TPS的粒度。如果是接口层性能测试,T可以直接定义为接口级;如果业务级性能测试,T可以直接定义为每个业务步骤和完整的业务流。
我们用一个示意图来说明一下。

如果我们要单独测试接口1、2、3,那T就是接口级的;如果我们要从用户的角度来下一个订单,那1、2、3应该在一个T中,这就是业务级的了。
当然,这时我们还要分析系统是如何设计的。通常情况下,积分我们都会异步,而库存不能异步哇。所以这个业务,你可以看成只有1、2两个接口,但是在做这样的业务级压力时,3接口也是必须要监控分析的。
所以,性能中TPS中T的定义取决于场景的目标和T的作用。一般我们都会这样来定事务。
-
接口级脚本:
——事务start(接口1)
接口1脚本
——事务end(接口1)
——事务start(接口2)
接口2脚本
——事务end(接口2)
——事务start(接口3)
接口3脚本
——事务end(接口3)
-
业务级接口层脚本(就是用接口拼接出一个完整的业务流):
——事务start(业务A)
接口1脚本 - 接口2(同步调用)
接口1脚本 - 接口3(异步调用)
——事务end(业务A)
-
用户级脚本
——事务start(业务A)
点击0 - 接口1脚本 - 接口2(同步调用)
点击0 - 接口1脚本 - 接口3(异步调用)
——事务end(业务A)
你要创建什么级别的事务,完全取决于测试的目的是什么。
一般情况下,我们会按从上到下的顺序一一地来测试,这样路径清晰地执行是容易定位问题的。
重新理解那些性能指标概念
搞清楚了TPS的T是什么,下面就要说什么是TPS了。字面意思非常容易理解,就是:?每秒事务数。
在性能测试过程中,TPS之所以重要,是因为它可以反应出一个系统的处理能力。我在很多场景中都说过,事务就是统计了一段脚本的执行时间,并没有什么特别的含义。而现在又多加了其他的几个概念。
首先是QPS,如果它描述的是数据库中的Query Per Second,从上面的示意图中来看,其实描述的是服务后面接的数据库中SQL的每秒执行条数。如果描述的是前端的每秒查询数,那就不包括插入、更新、删除操作了。显然这样的指标用来描述系统整体的性能是不够全面的。所以不建议用QPS来描述系统整体的性能,以免产生误解。
RPS(Request per second),每秒请求数。看似简单的理解,但是对于请求数来说,要看是在哪个层面看到的请求,因为请求这个词,实在是太泛了。我们把上面的图做一点点变化来描述一下请求数。
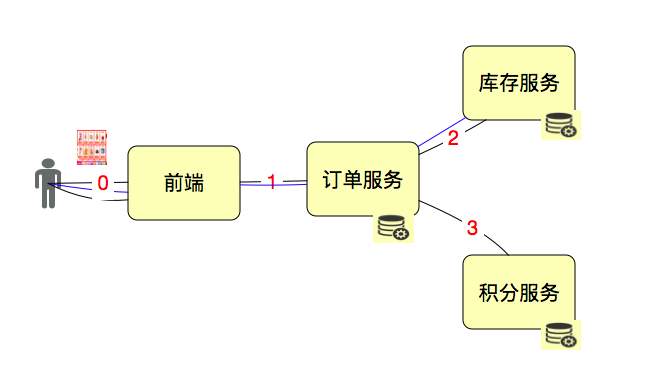
如果一个用户点击了一次,发出来3个HTTP Request,调用了2次订单服务,调用了2次库存服务,调用了1次积分服务,那么这个Request该如何计算?如果你是算GDP的专家,我觉得可能会是:3+2+2+1=8(次)。而在具体的项目中,我们会单独描述每个服务,以便做性能统计。如果要描述整体,最多算是有3个RPS。如果从HTTP协议的角度去理解,那么HTTP Request算是一个比较准确的描述了,但它本身的定义并没有包含业务。如果赋予它业务的含义,那么用它来描述性能也是可以的。
HPS(Hits Per Second),每秒点击数。Hit一般在性能测试中,都用来描述HTTP Request。但是,也有一些人用它描述真正的客户在界面上的点击次数。关于这一点,就只有在具体的项目中才能规定得具体一些。当它描述HTTP Request时,如果RPS也在描述HTTP Request,那这两个概念就完全一样了。
CPS/CPM:Calls Per Second/ Calls Per Minutes,每秒/每分钟调用次数。这个描述在接口级是经常用到的,比如说上面的订单服务。显然一次客户界面上的点击调用两次。这个比较容易理解。但是,在操作系统级,我们也经常会听到系统调用用call来形容,比如说用strace时,你就会看见Calls这样的列名。
这些概念本身并没有问题,但是当上面的概念都用来描述一个系统的性能能力的时候,就混乱了。对于这种情况,我觉得有几种处理方式:
-
用一个概念统一起来。我觉得直接用TPS就行了,其他的都在各层面加上限制条件来描述。比如说,接口调用1000 Calls/s,这样不会引起混淆。
-
在团队中定义清楚术语的使用层级。
-
如果没有定义使用层级,那只能在说某个概念的时候,加上相应的背景条件。
所以,当你和同事在沟通性能指标用哪些概念时,应该描述得更具体一些。在一个团队中,应该先有这些术语统一的定义,再来说性能指标是否满足。
响应时间RT
在性能中,还有一个重要的概念就是响应时间(Response Time)。这个比较容易理解。我们接着用这张示意图说明:

RT = T2-T1。计算方式非常直接简单。但是,我们要知道,这个时间包括了后面一连串的链路。
响应时间的概念简单至极,但是,响应时间的定位就复杂了。
性能测试工具都会记录响应时间,但是,都不会给出后端链路到底哪里慢。经常有人问问题就直接说,我的响应时间很慢。问题在哪呢?在这种情况下,只能回答:不知道。
因为我们要先画架构图,看请求链路,再一层层找下去。比如说这样:
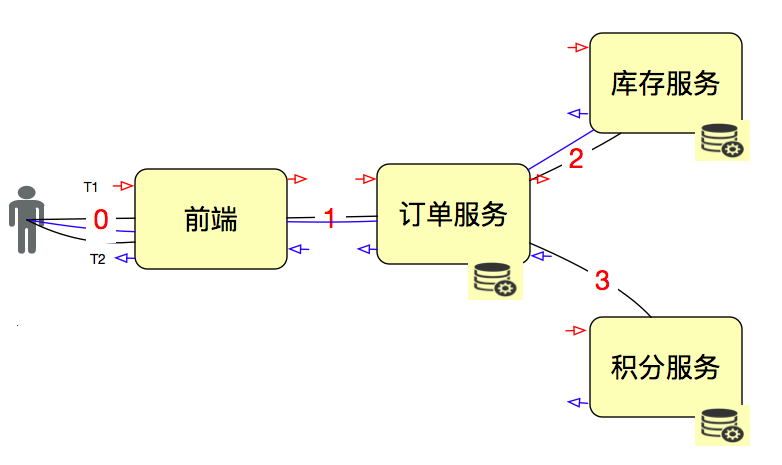
在所有服务的进出口上都做记录,然后计算结果就行了。在做网关、总线这样的系统时,基本上都会考虑这个功能。
而现在,随着技术的发展,链路监控工具和一些Metrics的使用,让这个需求变得简单了不少。比如说这样的展示:

它很直观地显示了,在一个请求链路上,每个节点消耗的时间和请求的持续时间。
我顺便在这里说一下调优在当前性能项目中的状态。
对于响应时间来说,时间的拆分定位是性能瓶颈定位分析中非常重要的一节。但是请注意,这个环节并不是性能测试工程师的最后环节。
在工作中,我经常看到有很多性能测试工程师连时间拆分都不做,只报一个压力工具中看到的响应时间,就给一个通过不通过的结论,丝毫没有定位。
另外,有一些性能测试工程师,倒是用各种手段分析了时间的消耗点,但是也觉得自己的工作就此结束了,而不做根本原因的分析或协调其他团队来分析。
当然在不同的企业里,做分析的角色和要求各不相同,所以也要根据实际的企业现状来说。
在我的观点中,性能只测不调,那就是性能验证的工作,称不上是完整的性能项目。第三方性能测试的机构可以这样做,但是在一个企业内部这样做的话,性能团队的价值肯定就大打折扣了。
但是现在有很多人都不把性能调优做为性能团队的工作,主要原因有几点:
-
性能测试团队的人能力有限做不到;
-
性能调优代价高,耗时长,不值得做。
在我带的性能项目中,基本上调优的工作都是我的团队主导的。性能团队当然不可能完全没有技术弱点,所以在很多时候都是协调其他团队的人一起来分析瓶颈点。那为什么是我的团队来主导这个分析的过程呢?
因为每个技术人员对性能瓶颈的定义并不相同,如果不细化到具体的计数器的值是多少才有问题,有误解的可能性就很大。
曾经我在某零售业大厂做性能咨询的时候,一房间的技术人员,开发、运维、DBA都有,结果性能瓶颈出现了,所有人都说自己的部分是没问题的。于是我一个个问他们是如何判断的,判断的是哪个计数器,值又是多少。结果发现很多人对瓶颈的判断都和我想像的不一样。
举例来说,DB的CPU使用率达到90%以上,DBA会觉得没有问题,因为都是业务的SQL,并不是DB本身有问题。开发觉得SQL执行时间慢是因为DB有问题,而不是自己写的有问题,因为业务逻辑并没有错,有问题的点应该是DB上索引不合理、配置不合理。
你看,同样的问题,每个人的看法都有区别。当然也不能排除有些人就是想推诿责任。
这时怎么办呢?如果你可以把执行计划拿出来,告诉大家,这里应该创建索引,而那里应该修改业务条件,这时就具体了。
压力工具中的线程数和用户数与TPS
总是有很多人在并发线程数和TPS之间游荡,搞不清两者的关系与区别。这两个概念混淆的点就是,好像线程是真实的用户一样,那并发的线程是多少就描述出了多少真实的用户。
但是做性能的都会知道,并发线程数在没有模拟真实用户操作的情况下,和真实的用户操作差别非常远。
在LoadRunner还比较红火的时候,Mercury提出一个BTO的概念,就是业务科技优化。在LoadRunner中也提出”思考时间“的概念,其实在其他的性能工具中是没有“思考时间”这个词的。这个词的提出就是为了性能工具模拟真实用户。
但是随着性能测试的地位不断下降,以及一些概念和名词不断地被以讹传讹,导致现在很多人都没有明白压力工具中的线程数和用户以及TPS之间是怎样的关系。同样,我们先画一个示意图来说明一下。

这里先说明一个前提,上面的一个框中有四个箭头,每个都代表着相同的事务。
在说这个图之前,我们要先说明“并发”这个概念是靠什么数据来承载的。
在上面的内容中,我们说了好多的指标,但并发是需要具体的指标来承载的。你可以说,我的并发是1000TPS,或者1000RPS,或者1000HPS,这都随便你去定义。但是在一个具体的项目中,当你说到并发1000这样没有单位的词时,一定要让大家都能理解这是什么。
在上面这张示意图中,其实压力工具是4个并发线程,由于每个线程都可以在一秒内完成4个事务,所以总的TPS是16。这非常容易理解吧。而在大部分非技术人的脑子里,这样的场景就是并发数是4,而不是16。
要想解释清楚这个非常困难,我的做法就是,直接告诉别人并发是16就好了,不用关心4个线程这件事。这在我所有项目中几乎都是一样的,一直也没有什么误解。
那么用户数怎么来定义呢?涉及到用户就会比较麻烦一点。因为用户有了业务含义,所以有些人认为一个系统如果有1万个用户在线,那就应该测试1万的并发线程,这种逻辑实在是不技术。通常,我们会对在线的用户做并发度的分析,在很多业务中,并发度都会低于5%,甚至低于1%。
拿5%来计算,就是10000用户x5%=500(用户级TPS),注意哦,这里是TPS,而不是并发线程数。如果这时响应时间是100ms,那显然并发线程数是500TPS/(1000ms/100ms)=50(并发线程)。
通过这样简单的计算逻辑,我们就可以看出来用户数、线程数和TPS之间的关系了。

但是!响应时间肯定不会一直都是100ms的嘛。所以通常情况下,上面的这个比例都不会固定,而是随着并发线程数的增加,会出现趋势上的关系。
所以,在性能分析中,我一直在强调着一个词:?趋势!
业务模型的28原则是个什么鬼?
我看到有些文章中写性能测试要按28原则来计算并发用户数。大概的意思就是,如果一天有1000万的用户在使用,系统如果开10个小时的话,在计算并发用户数的时候,就用2小时来计算,即1000万用户在2小时内完成业务。
我要说的是,这个逻辑在一个特定的业务系统中是没有任何价值的。因为每个系统的并发度都由业务来确定,而不是靠这样的所谓的定律来支配着业务。
如果我们做了大量的样本数据分析,最后确实得出了28的比例,我觉得那也是可以的。但是如果什么数据都没有分析,直接使用28比例来做评估和计算,那就跟耍流氓没有区别。
业务模型应该如何得到呢?这里有两种方式是比较合理的:
-
根据生产环境的统计信息做业务比例的统计,然后设定到压力工具中。有很多不能在线上直接做压力测试的系统,都通过这种方式获取业务模型。
-
直接在生产环境中做流量复制的方式或压力工具直接对生产环境发起压力的方式做压力测试。这种方式被很多人称为全链路压测。其实在生产中做压力测试的方式,最重要的工作不是技术,而是组织协调能力。相信参与过的人都能体会这句话的重量。
响应时间的258原则合理吗?
对于响应时间,有很多人还在说着258或2510响应时间是业内的通用标准。然后我问他们这个标准的出处在哪里?谁写的?背景是什么?几乎没有人知道。真是不能想像,一个谁都不知道出处的原则居然会有那么大的传播范围,就像谣言一样,出来之后,再也找不到源头。
其实这是在80年代的时候,英国一家IT媒体对音乐缓冲服务做的一次调查。在那个年代,得到的结果是,2秒客户满意度不错;5秒满意度就下降了,但还有利润;8秒时,就没有利润了。于是他们就把这个统计数据公布了出来,这样就出现了258 principle,翻译成中文之后,它就像一个万年不变的定理,深深影响着很多人。
距离这个统计结果的出现,已经过去快40年了,IT发展的都能上天了,这个时间现在已经完全不适用了。所以,以后出去别再提258/2510响应时间原则这样的话了,太不专业。
那么响应时间如何设计比较合理呢?这里有两种思路推荐给你。
-
同行业的对比数据。
-
找到使用系统的样本用户(越多越好),对他们做统计,将结果拿出来,就是最有效的响应时间的制定标准。
性能指标的计算方式
我们在网上经常可以看到有人引用这几个公式。
公式(1):
并发用户数计算的通用公式:
其中C是平均的并发用户数;n是login session的数量;L是login session的平均长度;T指考察的时间段长度。
公式(2):
并发用户数峰值:?
C’指并发用户数的峰值,C就是公式(1)中得到的平均的并发用户数。该公式是假设用户的login session产生符合泊松分布而估算得到的。
仔细搜索之后发现会发现这两个公式的出处是2004年一个叫Eric Man Wong的人写的一篇名叫《Method for Estimating the Number of Concurrent Users》的文章。中英文我都反复看到很多篇。同时也会网上看到有些文章中把这个文章描述成“业界公认”的计算方法。
在原文中,有几个地方的问题。
-
C并不是并发用户,而是在线用户。
-
这两个公式做了很多的假设条件,比如说符合泊松分布什么的。为什么说这个假设有问题?我们都知道泊松分布是一个钟型分布,它分析的是一个系统在全周期中的整体状态。
-
如果要让它在实际的项目中得到实用,还需要有大量的统计数据做样本,代入计算公式才能验证它的可信度。
-
峰值的计算,我就不说了,我觉得如果你是做性能的,应该一看就知道这个比例不符合大部分真实系统的逻辑。
-
有些人把这两个公式和Little定律做比较。我要说Little定律是最基础的排队论定律,并且这个定律只说明了:系统中物体的平均数量等于物体到达系统的平均速率和物体在系统中停留的平均时间的乘积。我觉得这句话,就跟秦腔中的”出门来只觉得脊背朝后“是一样一样的。
有人说应该如何来做系统容量的预估呢。我们现在很多系统的预估都是在一定的假设条件之下的,之所以是预估,说明系统还不在,或者还没达到那样的量。在这种情况下,我们可以根据现有的数据,做统计分析、做排队论模型,进而推导以后的系统容量。
但是我们所有做性能的人都应该知道,系统的容量是演进来的,而不是光凭预估就可以得出准确数值的。
总结
在性能测试的概念中,性能指标、性能模型、性能场景、性能监控、性能实施、性能报告,这些既是概念中的关键词,也可以说是性能测试的方法和流程。
而这些概念我们在实际的工作中,都是非常重要的。因为它们要抹平沟通的误解。让不同层级,不同角色的人,可以在同样的知识背景下沟通,也可以让做事情的人有清晰的逻辑思路,同时对同行间的交流,也有正向的促进作用。
性能测试策略、性能测试场景、性能测试指标,这些关键的概念在性能测试中深深地影响着很多人。我们简化它的逻辑,只需要记住几个关键字就可以,其他的都不必使用。
-
性能测试概念中:性能指标、性能模型、性能场景、性能监控、性能实施、性能报告。
-
性能场景中:基准场景、容量场景、稳定性场景、异常场景。
-
性能指标中:TPS、RT。 (记住T的定义是根据不同的目标来的)
在具体的性能项目中,性能场景是一个非常核心的概念。因为它会包括压力发起策略、业务模型、监控模型、性能数据(性能中的数据,我一直都不把它称之为模型,因为在数据层面,测试并没有做过什么抽象的动作,只是使用)、软硬件环境、分析模型等。
同时,在这我为大家准备了一份软件测试视频教程(含面试、接口、自动化、性能测试等),就在下方,需要的可以直接去观看,也可以直接【点击文末小卡片免费领取资料文档】
软件测试视频教程观看处:【性能测试P46开始】
【2024最新版】Python自动化测试15天从入门到精通,10个项目实战,允许白嫖。。。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C++ 编程必备:对象生命周期管理的最佳实践
- Pexpect 是一个 Python 库,用于自动化与终端交互的任务
- Flink(十三)【Flink SQL(上)】
- opencv入门到精通——图像的几何变换
- 有什么好用的C/C++源代码混淆工具?
- uniapp在中app,登录页能记住多个账号以及密码功能完整代码
- 设计模式-GOF对各个模式的定义
- Qt Q_DECL_OVERRIDE
- C++封装MySQL整体流程,并在Navicat展示
- Lua的垃圾回收机制详解