做数据关键步骤:怎么写好prompt?
前言
不论是批量构建sft数据来训练通用模型,还是最近大火的Agent,其实一个核心工作就是做好prompt engineering,因为只有写好了prompt(gpt模型回复满足当前需求),才意味着我们可以批量拉数据了或者整个Agent run起来了,进而才可以训练模型等等。
总结起来一句话就是:写好prompt,才意味着有了批量数据。
那么怎么才能写好prompt呢?泛泛来说就是把自己的需求抽象化成指令,且模型能够完全遵循这些指令。但是一个常见的现象是模型不能总是很好的遵循,即使是地表最强的GPT4有时候也不能完全遵循。
所以就需要prompt engineering也即需要一定的prompt编写技巧,这是很需要实战经验的,今天就带来一篇paper,其直接给出了一些prompt,可直接拿来主义尝试。
《Principled Instructions Are All You Need for
Questioning LLaMA-1/2, GPT-3.5/4》
论文链接: https://arxiv.org/pdf/2312.16171.pdf
Github : https://github.com/VILA-Lab/ATLAS
写prompt的几大原则
- Conciseness and Clarity
如果写的prompt中包含过于冗长或含糊不清的提示,就可能会让模型困惑或导致无关的回答。所以应该尽可能简洁明了,避免不必要的信息。因为这些信息不仅对所做的任务没有贡献,反而会扰乱模型。
- Contextual Relevance:
prompt中必须要包括任务相关的背景信息,这些信息有助于帮助模型理解任务的背景和领域。比如可以写一些关键词、领域特定术语或情境描述。
- Task Alignment
写的prompt应该与当前任务尽可能对齐,比如将prompt构建为问题、命令或填空语句,以引导出当前任务希望的输入和输出格式。
- Example Demonstrations
这里就是最好举几个例子给模型,也就是大家常说的few-shot。
- Avoiding Bias
prompt应该设计为尽可能减少模型因训练数据而固有的偏见的激活。比如防止引导出敏感的话题等等。
- Incremental Prompting
对于需要一系列步骤才能完成的任务,可以通过将任务分解逐步来引导模型完成。另外,提示应根据模型的表现和迭代反馈进行动态调整。
- 小结
除了上面的几个原则,更高级的prompt可能会包含类似编程的逻辑来完成复杂的任务。例如,使用条件语句、逻辑运算符,甚至在提示中使用伪代码来引导模型的推理过程。
具体例子
基于上面几大原则,作者给出了更具体例子
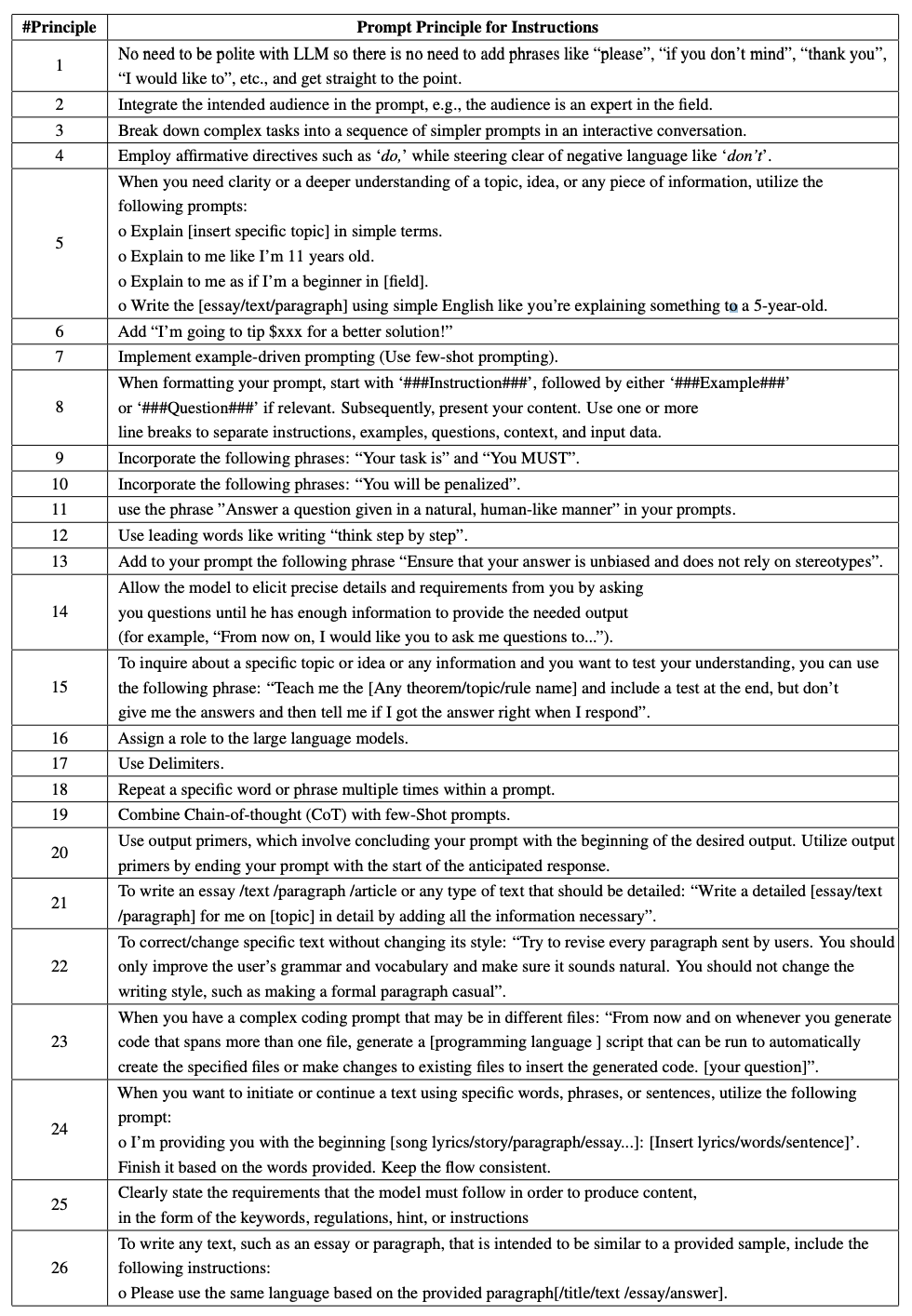
同时作者将上面的例子进行了原则归类
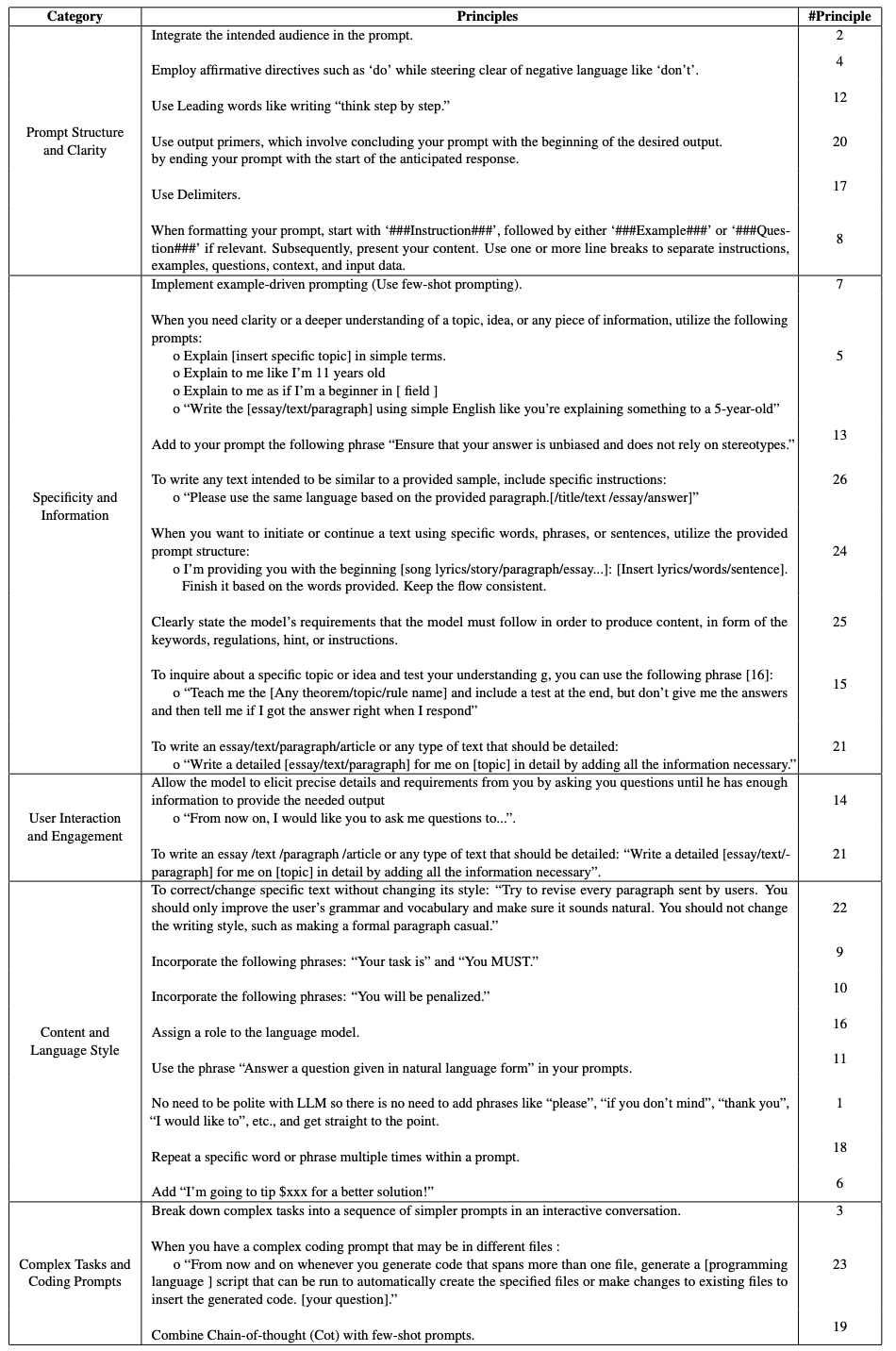
比如通过 “给小费” 来激励模型严格遵循指令。
总结
本文作者很实在,接地气,直接给了一些很具体的trick,大家在实战的时候可以试着用一下
关注
欢迎关注,下期再见啦~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Kingbase单实例场景下更新license步骤
- 级联选择器el-cascader根据下拉数据的id获取所对应的文字
- springboot解决XSS存储型漏洞
- vscode安装Prettier插件,对vue3项目进行格式化
- arcgis javascript api4.x以basetilelayer方式加载天地图web墨卡托(wkid:3857)坐标系
- 常用python代码大全-python使用csv模块进行CSV文件操作
- 七言-咏甲辰龙年
- 如何在 24 小时内构建 WordPress 网站
- 什么是抖店?不用直播带货,0粉丝可以做吗?
- FreeRTOS任务四种状态