深入理解强化学习——马尔可夫决策过程:策略迭代与价值迭代的区别
分类目录:《深入理解强化学习》总目录
我们来看一个马尔可夫决策过程控制的动态演示,下图所示为网格世界的初始化界面:
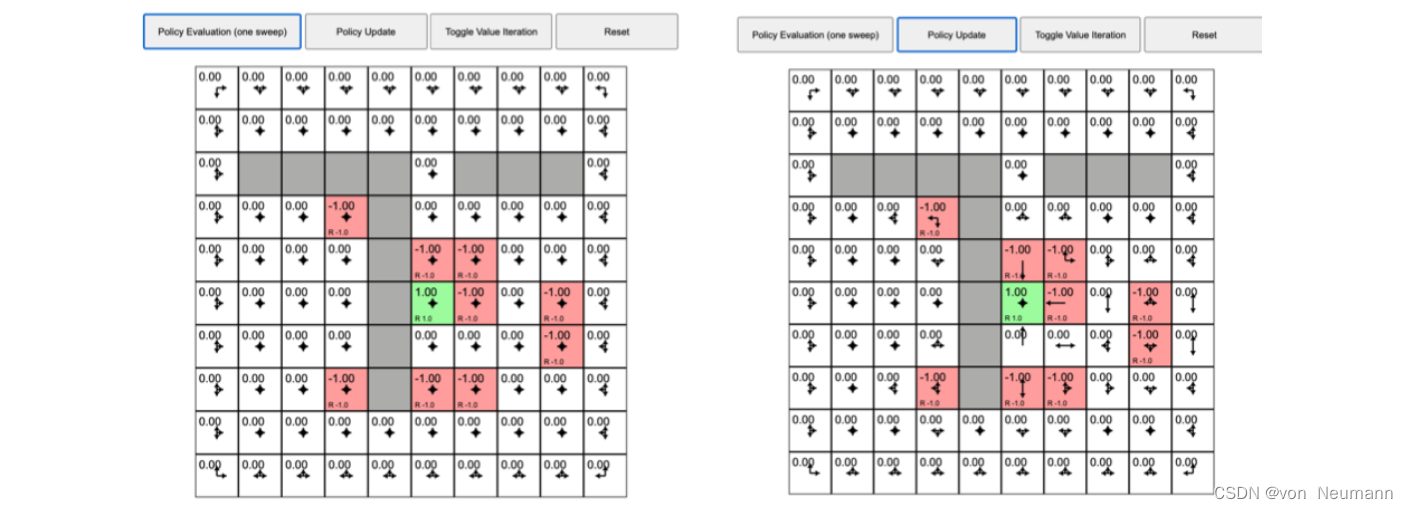
首先我们来看看策略迭代,之前的例子在每个状态都采取固定的随机策略,每个状态都以0.25的概率往上、下、左、右,没有策略的改变。但是我们现在想进行策略迭代,每个状态的策略都进行改变。如图下图(a)所示,我们先执行一次策略评估,得到价值函数,每个状态都有一个价值函数。如下图(b)所示,我们接着进行策略改进,单击“策略更新(Policy Update)”,这时有些格子里面的策略已经产生变化。比如对于中间
?
1
?1
?1的这个状态,它的最佳策略是往下走。当我们到达
?
1
?1
?1状态后,我们应该往下走,这样就会得到最佳的价值。绿色右边的格子的策略也改变了,它现在选取的最佳策略是往左走,也就是在这个状态的时候,最佳策略应该是往左走。
如图下图(a)所示,我们再执行下一轮的策略评估,格子里面的值又被改变了。多次之后,格子里面的值会收敛。如图下图(b) 所示,我们再次执行策略更新,每个状态里面的值基本都改变了,它们不再上、下、左、右随机改变,而是会选取最佳的策略进行改变。
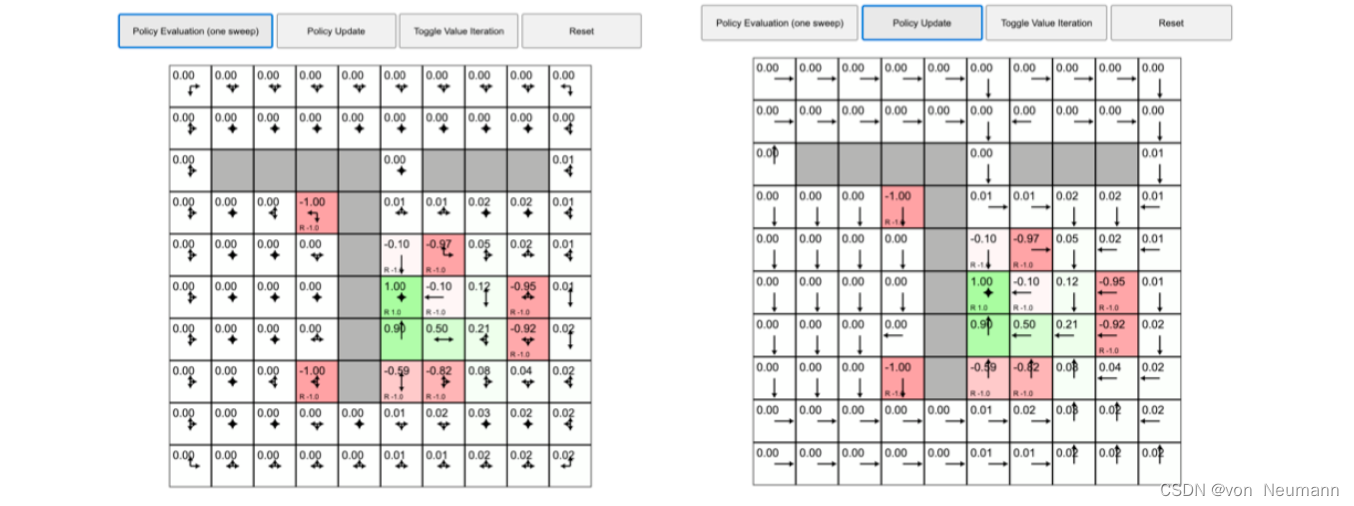
如下图(a)所示,我们再次执行策略评估,格子的值又在不停地变化,变化之后又收敛了。如下图(b)所示,我们再执行一次策略更新。现在格子的值又会有变化,每一个状态中格子的最佳策略也会产生一些改变。
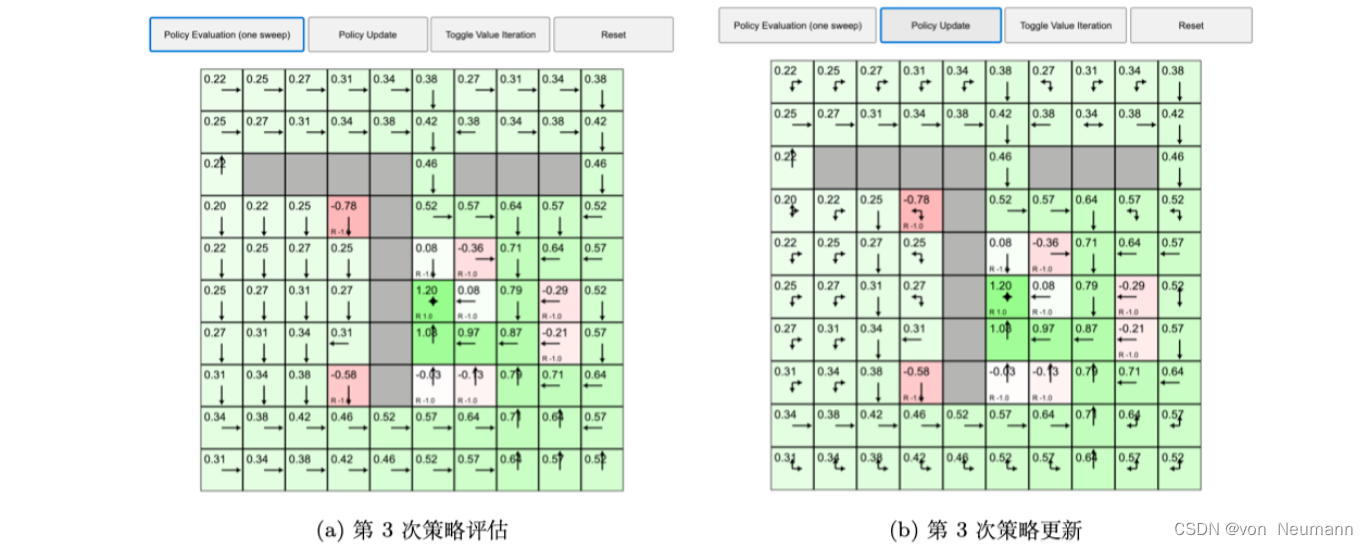
如下图(a)所示,我们再执行一遍策略更新,格子的值没有发生变化,这说明整个马尔可夫决策过程已经收敛了。所以现在每个状态的值就是当前最佳的价值函数的值,当前状态对应的策略就是最佳的策略。通过这个例子,我们知道策略迭代可以把网格世界“解决掉”。“解决掉”是指,不管在哪个状态,我们都可以利用状态对应的最佳的策略到达可以获得最多奖励的状态。
如图下图(b)所示,我们再用价值迭代来解马尔可夫决策过程,单击“切换成价值迭代”。 当格子的值确定后,就会产生它的最佳状态,最佳状态提取的策略与策略迭代得出的最佳策略是一致的。在每个状态,我们使用最佳策略,就可以到达得到最多奖励的状态。
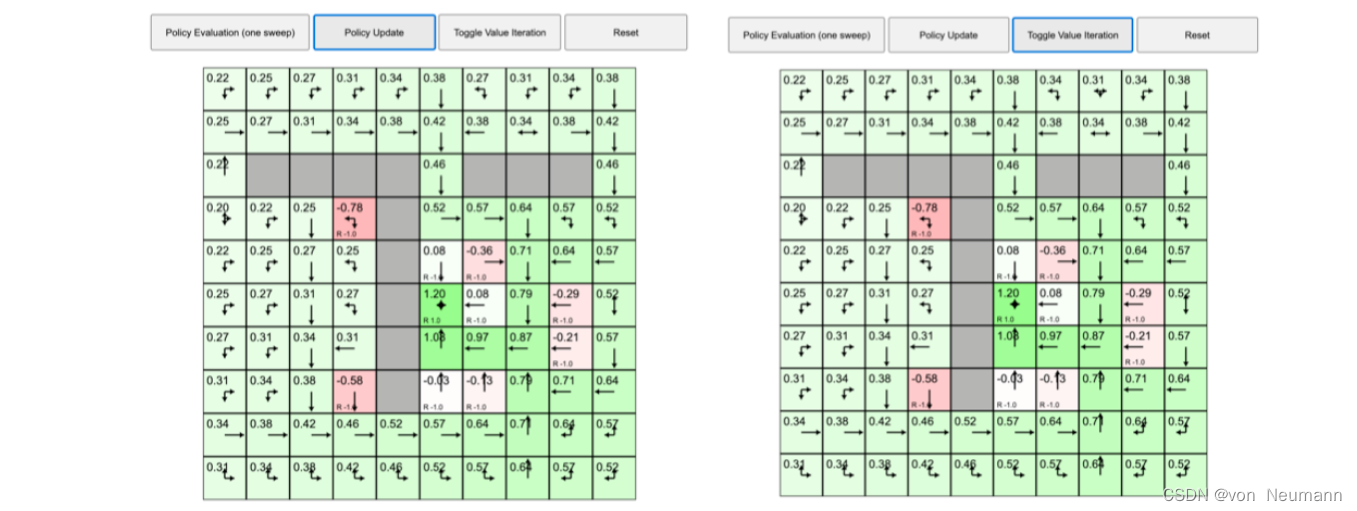
我们再来对比策略迭代和价值迭代,这两个算法都可以解马尔可夫决策过程的控制问题。策略迭代分两步。首先进行策略评估,即对当前已经搜索到的策略函数进行估值。得到估值后,我们进行策略改进,即把Q函数算出来,进行进一步改进。不断重复这两步,直到策略收敛。价值迭代直接使用贝尔曼最优方程进行迭代,从而寻找最佳的价值函数。找到最佳价值函数后,我们再提取最佳策略。
参考文献:
[1] 张伟楠, 沈键, 俞勇. 动手学强化学习[M]. 人民邮电出版社, 2022.
[2] Richard S. Sutton, Andrew G. Barto. 强化学习(第2版)[M]. 电子工业出版社, 2019
[3] Maxim Lapan. 深度强化学习实践(原书第2版)[M]. 北京华章图文信息有限公司, 2021
[4] 王琦, 杨毅远, 江季. Easy RL:强化学习教程 [M]. 人民邮电出版社, 2022
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!