13. 第13章 接口, 协议和抽象基类
发布时间:2024年01月21日
13. 接口, 协议和抽象基类
```handlebars
对接口编程, 而不是对实现编程.
--Gamma, Helm, Johnson 和 Vlissides
面向对象设计第一原则①
(注1: 出自<<设计模式>>'引言'部分.)
面向对象编程全靠接口.
如8.4节所述, 在Python中, 支撑一个类型的是它提供的方法, 也就是接口.
在不同的编程语言中, 接口的定义和使用方式不尽相同.
从Python3.8开始, 有4种方式如图13-1中的'类型图'所示.
这4种方式概述如下.
* 1. 鸭子类型
自Python诞生以来默认使用的类型实现方式.
从第1章开始, 本书一直在研究鸭子类型.
* 2. 大鹅类型
自Python 2.6开始, 由抽象基类支持的方式, 该方式会在运行时检查对象是否符合抽象基类的要求.
大鹅类型是本章的主要话题.
* 3. 静态类型
C和Java等传统静态类型语言采用的方式.
自Python 3.5开始, 由typing模块支持, 由符合'PEP 484--Type Hints'要求的外部类型检查工具实施检查.
本章不涉及该方式. 第8章的大多数内容和第15章讨论了静态类型.
* 4. 静态鸭子类型
因Go语言而流行的方式.
由typing.Protocol(Python 3.8新增)的子类支持,由外部类型检查工具实施检查.
静态鸭子类型首次出现在8.5.10节.
13.1 类型图
图13-1描述的4种类型实现方式各有优缺点, 相辅相成, 缺一不可.

图13-1: 上半部分是只使用Python解释器在运行时检查类型的方式;
下半部分则要借助外部静态类型检查工具, 例如MyPy或PyCharm等IDE.
左边两象限中的类型基于对象的结构(对象提供的方法), 与对象所属的类或超类无关;
右边两象限中的类型要求对象有明确的类型名称: 对象所属类的名称, 或者超类的名称.
这4种方式全都依靠接口, 不过静态类型可以只使用具体类型实现(效果差), 而不使用协议和抽象基类等接口抽象.
本章涵盖围绕接口实现的3种类型: 鸭子类型, 大鹅类型和静态鸭子类型.
本章主要分为4部分, 探讨类型图(参见图13-1)中4个象限里的3个.
? 13.3节比较两种依赖协议的结构类型, 即类型图的左半部分.
? 13.4节深入探讨我们熟悉的鸭子类型,
以及如何在保证灵活性这个主要优势的前提下提升鸭子类型的安全性.
? 13.5节说明如何使用抽象基类实现更严格的运行时类型检查.
这一节内容最多, 原因不是大鹅类型更重要, 而是本书其他章已经涵盖鸭子类型, 静态鸭子类型和静态类型.
? 13.6节涵盖typing.Protocol子类(针对静态和运行时类型检查)的用法, 实现和设计.
13.2 本章新增内容
本章内容改动幅度较大, 与第1版中的第11章相比, 内容增加了约24%.
虽然一些小节和很多段落没有变, 但是新增了大量内容. 主要变化如下.
? 本章的导言和类型图(参见图13-1)是新增的.
这是本章很多新增内容, 以及与Python 3.8及以上版本中类型相关的其他章的关键.
? 13.3节说明动态协议和静态协议之间的异同.
? 13.4.3节的内容基本上来自本书第1版, 不过做了更新, 为了突出重要性, 标题也改了.
? 13.6节是全新内容, 是8.5.10节的延续.
? 更新了图13-2, 图13-3和图13-4中的collections.abc类图,增加Python3.6引入的抽象基类Collection.
本书第1版有一节建议使用numbers模块中的抽象基类实现大鹅类型.
实现大鹅类型时, 除了运行时检查, 如果还打算使用静态类型检查工具, 则应该换用typing模块中的数值静态协议.
13.6.8节会解释背后的原因.
13.3 两种协议
在计算机科学中, 根据上下文, '协议'一词有不同的含义.
HTTP这种网络协议指明了客户端可向服务器发送的命令, 例如GET, PUT和HEAD.
12.4节讲过, 对象协议指明为了履行某个角色, 对象必须实现哪些方法.
第1章中的FrenchDeck示例演示了一个对象协议, 即序列协议:
一个Python对象想表现得像一个序列需要提供的方法.
完全实现一个协议可能需要多个方法, 不过m 通常可以只实现部分协议.
下面以示例13-1中的Vowels类为例.
# 示例13-1 __使用getitem__ 方法实现部分序列协议
>>> class Vowels:
... def __getitem__(self, i):
... return 'AEIOU'[i]
...
v = Vowels()
>>> v[0]
'A'
>>> v[-1]
'U'
>>> for c in v: print(c)
...
A
E
I
O
U
>>> 'E' in v
True
>>> 'Z' in v
False
只要实现__getitem__方法, 就可以按索引获取项, 以及支持迭代和in运算符.
其实, 特殊方法__getitem__是序列协议的核心.
以下内容摘自<<Python/C API参考手册>>中的'序列协议'一节.
int PySequence_Check(PyObject *o)
如果对象提供序列协议, 就返回1, 否则返回0.
注意, 除了dict子类, 如果一个Python 类有__getitem__()方法, 则也返回1......
我们预期序列支持len()函数, 也就是要实现__len__方法.
Vowels没有__len__方法, 不过在某些上下文中依然算得上是序列. 而有些时候, 这就足够了.
所以, 我经常说协议是'非正式接口'.
第一个使用'协议'这个术语的面向对象编程环境Smalltalk也是这么理解协议的.
在Python文档中, 除了有关网络编程的内容, '协议'一词基本上是指非正式接口.
Python 3.8通过'PEP 544--Protocols: Structural subtyping(static duck typing)'之后,
'协议'一词在Python中多了一种含义--联系紧密, 仍有区别.
8.5.10节讲过, PEP544提议通过typing.Protocol的子类定义一个类必须实现(或继承)的一个或多个方法
让静态类型检查工具满意.
需要区分时, 我会使用以下两个术语.
动态协议
Python一直有的非正式协议.
动态协议是隐含的, 按约定定义, 在文档中描述.
Python大多数重要的动态协议由解释器支持, 在<<Python语言参考手册>>的第3章'数据模型'中说明.
静态协议
'PEP 544--Protocols: Structural subtyping (static duck typing)'定义的协议,
自 Python 3.8开始支持. 静态协议要使用typing.Protocol子类显式定义.
二者之间的主要区别如下.
? 对象可以只实现动态协议的一部分,
但是如果想满足静态协议, 则对象必须提供协议类中声明的每一个方法, 即使程序用不到.
? 静态协议可以使用静态类型检查工具确认, 动态协议则不能.
两种协议共有一个基本特征: 类无须通过名称(例如通过继承)声明支持什么协议.
除了静态协议, Python还提供了另一种定义显式接口的方式, 即抽象基类.
本章余下的内容涵盖动态协议和静态协议, 以及抽象基类.
13.4 利用鸭子类型编程
我们以Python中两个最重要的协议(序列协议和可迭代协议)为例展开对动态协议的讨论.
即使对象只实现了这些协议的最少一部分, 也会引起解释器的注意. 详见13.4.1节.
13.4.1 Python喜欢序列
Python数据模型的哲学是尽量支持基本的动态协议.
对序列来说, 即便是最简单的实现, Python也会力求做到最好.
图13-2展示的是通过一个抽象基类确立的Sequence接口.
Python解释器和list, str等内置序列根本不依赖那个抽象基类.
我只是利用它说明一个功能完善的序列应该支持什么操作.

图13-2: Sequence抽象基类和collections.abc中相关抽象类的UML类图.
箭头由子类指向超类. 以斜体显示的是抽象方法.
Python 3.6之前的版本中没有Collection抽象基类, Sequence是Container, Iterable和Sized的直接子类.
*---------------------------------------------------------------------------------------------*
collections.abc模块中的大多数抽象基类
存在的目的是确立由内置对象实现并且由解释器隐式支持的接口--二者均早于抽象基类.
这些抽象基类可作为新类的基础,
并为运行时显式类型检查(大鹅类型)和静态类型检查工具用到的类型提示提供支持.
解释: collections.abc模块中的抽象基类是为了确立内置对象所支持的接口,
同时也为运行时和静态类型检查提供了支持.
这些抽象基类定义了一组方法和属性, 任何实现这些方法和属性的类都可以被视为该抽象基类的子类.
通常情况下, 这些抽象基类仅被用于指定一些通用的行为, 不会实现具体的功能.
同时, Python解释器还会自动支持这些接口, 这意味着内置对象可以自动支持这些接口, 而无需显式指定.
因此, 抽象基类可以作为新类的基础, 为静态类型检查工具提供类型提示, 并在运行时执行显式类型检查.
*---------------------------------------------------------------------------------------------*
从图13-2可以看出, 为了确保行为正确, Sequence的子类必须实现__getitem__和__len__(来自Sized).
Sequence中的其他方法都是具体的, 因此子类可以继承或者提供更好的实现.
再回顾一下示例13-1中的Vowels类.
那个类没有继承abc.Sequence, 而且只实现了__getiten__.
虽然没有__iter__方法, 但是Vowels实例仍然可以迭代.
这是因为如果发现有__getitem__方法. 那么Python就会调用它,
传入从0开始的整数索引尝试迭代对象(这是一种后备机制).
尽管缺少__contains__方法, 但是Python足够智能, 能正确迭代Vowels实例,
因此也能使用in运算符: Python做全面检查, 判断指定的项是否存在.
综上所述, 鉴于序列类数据结构的重要性, 如果没有__iter__方法和__contains__方法,
则Python会调用__getitem__方法, 设法让迭代和in运算符可用.
第1章定义的FrenchDeck类也没有继承abc.Sequence, 但是实现了序列协议的两个方法:
__getitem__和__len__. 如示例13-2所示.
# 示例13-2 一摞有序的纸牌 (与示例1-1相同)
import collections
Card = collections.namedtuple('Card', ['rank', 'suit'])
class FrenchDeck:
ranks = [str(n) for n in range(2, 11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [Card(rank, suit) for suit in self.suits
for rank in self.ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self, position):
return self._cards[position]
第1章中的那些示例之所以能用, 是因为Python会特殊对待看起来像序列的对象.
Python的迭代协议是鸭子类型的一种极端形式: 为了迭代对象, 解释器会尝试调用两个不同的方法.
需要明确指出的是, 本节描述的行为在解释器自身中实现,
大多数是用C语言实现的, 不依赖Sequence抽象基类的方法.
例如, Sequence类中的具体方法__iter__和__contains__是对Python解释器内置行为的模仿.
如果觉得好奇, 可以到Lib/_collections_abc.py文件中阅读这些方法的源码.
下面再分析一个示例, 强调协议的动态本性, 并解释静态类型检查工具为什么没机会处理动态协议.
13.4.2 使用猴子补丁在运行时实现协议
猴子补丁在运行时动态修改模块, 类或函数, 以增加功能或修正bug.
例如, 网络库gevent对部分Python标准库打了猴子补丁, 不借助线程或async/await实现一种轻量级并发.
示例13-2中的FrenchDeck类缺少一个重要功能: 无法洗牌.
几年前, 我在第一次编写FrenchDeck示例时实现了shuffle方法.
后来, 在对Python风格有了深刻理解后我发现, 既然FrenchDeck的行为像序列, 那么它就不需要shuffle方法,
因为有现成的random.shuffle函数可用. 根据文档, 该函数的作用是'就地打乱序列x'.
标准库中的random.shuffle函数用法如下所示.
>>> from random import shuffle
>>> l = list(range(10))
>>> shuffle(l)
[5, 2, 9, 7, 8, 3, 1, 4, 0, 6]
遵守既定协议很有可能增加利用现有标准库和第三方代码的可能性, 这得益于鸭子类型.
然而, 如果尝试打乱FrenchDeck实例, 则会出现异常, 如示例13-3所示.
# 示例13-3 random.shuffle函数不能打乱FrenchDeck实例
>>> from random import shuffle
>>> from frenchdeck import FrenchDeck
>>> deck = FrenchDeck()
>>> shuffle(deck)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File ".../random.py", line 265, in shuffle
x[i], x[j] = x[j], x[i]
TypeError: 'FrenchDeck' object does not support item assignment
错误消息相当明确:
'FrenchDeck' object does not support item assignment ('FrenchDeck对象不支持为项赋值).
这个问题的原因在于, shuffle函数会'就地'操作, 调换容器内项的位置, 而FrenchDeck只实现了不可变序列协议.
可变序列还必须提供__setitem__方法.
因为Python是动态语言, 所以可以在运行时修正这个问题, 甚至在交互式控制台中就能做到.
修正方法如示例13-4所示.
# 示例13-4为FrenchDeck 打猴子补了, 把它变成可变序列,
# 以使randon.shuffle 函数能够对其进行处理(接续示例13-3)
# 定义一个函数, 参数为deck, position和card.
>>> def set_card(deck, position, card):
... deck._cards[position] = card
...
# 把上述函数赋值给FrenchDeck类的__setitem__属性.
>>> FrenchDeck.__setitem__ = set_card
# 现在可以打乱deck了, 因为我添加了可变序列协议所需的方法.
>>> shuffle(deck)
>>> deck[:5]
[Card(rank='3', suit='hearts'), Card(rank='4', suit='diamonds'),
Card(rank='4', suit='clubs'), Card(rank='7', suit='hearts'), Card(rank='9', suit='spades')]
<<Python 语言参考手册>> 的3.3.7节定义了特殊方法__setitem__的签名.
该手册中使用的参数是self, key, value, 而这里使用的是deck, position, card.
这么做是为了告诉你, Python方法说到底就是普通函数, 把第一个参数命名为self只是一种约定.
在控制台会话中使用那几个参数没问题, 不过在Python源码文件中最好按照文档那样使用self, key和value.
这里的关键是, set_card函数要知道deck对象有一个名为_cards的属性, 而且_cards的值必须是可变序列.
然后, 我们把set_card函数依附到FrenchDeck类上, 作为特殊方法__setitem__.
这就是猴子补丁: 在运行时修改类或模块, 而不改动源码.
虽然猴子补丁很强大, 但是打补丁的代码与被打补丁的程序耦合十分紧密,
而且往往要处理文档没有明确说明的私有属性.
除了举例说明猴子补丁, 示例13-4还强调了动态鸭子类型中的协议是动态的:
random.shuffle函数不关心参数所属的类, 只要那个对象实现了可变序列协议的方法即可.
即便对象一开始没有所需的方法也没关系, 可以之后再提供.
鸭子类型的安全性看似不可控, 而且增加了调试难度, 其实不然.
13.4.3节将介绍一些检测动态协议的编程模式, 免得我们自己动手检查.
13.4.3 防御性编程和’快速失败’
防御性编程就像防御性驾驶:
有一套提高安全的实践, 即使是粗心的程序员(或司机)也不会造成灾难.
许多bug只有在运行时才能捕获, 即使主流的静态类型语言也是如此.
②对于动态类型语言, '快速失败'可以提升程序的安全性, 让程序更易于维护.
快速失败的意思是尽早抛出运行时错误, 例如, 在函数主体开头就拒绝无效的参数.
(注2: 因此需要自动化测试.)
如果一个函数接受一系列项, 在内部按照列表处理, 那么就不要通过类型检查强制要求传入一个列表.
正确的做法是立即利用参数构建一个列表. 示例13-10中的__init__方法就采用了这种编程模式.
def __init__(self, iterable):
self._balls = list(iterable)
这样写出的代码更灵活, 因为list()构造函数能处理任何在内存中放得下的可迭代对象.
如果传入的参数不是可迭代对象, 那么初始化对象时list()调用就会快速失败,
抛出意义十分明确的TypeError异常.
如果想更明确一些, 可以把list()调用放在try/except结构中, 自定义错误消息.
我只会在外部API中这么做, 因为这样方便基准代码维护人员发现问题.
无论如何, 出错的调用将出现在调用跟踪的末尾, 直指根源.
如果没有在类的构造方法中捕获无效参数,
而等到类中的其他方法需要操作self._balls时才发现它不是列表, 那就为时已晚了, 程序崩溃的根源将很难确定.
当然, 如果数据太多, 或者按照设计,
需要就地修改数据(例如random.shuffle)以满足调用方的利益, 那么调用list()复制数据就不是一个好主意.
遇到这种情况, 应该使用isinstance(x, abc.MutableSequence)做运行时检查.
如果害怕传入的是无穷生成器(不常见), 则可以先使用len()获取参数的长度.
这样可以拒绝迭代器, 安全处理元组, 数组, 以及其他现有或以后可能出现的实现Sequence接口的类.
调用len()的开销通常不大, 但是作用明显, 遇到无效参数会立即抛出错误.
另外, 如果接受任何可迭代对象, 那么要尽早调用iter(x), 获得一个迭代器(详见17.3节).
同样, 如果×不是可迭代对象, 则这也会快速失败, 抛出一个易于调试的异常.
在这两种情况下, 类型提示可以捕获部分问题, 但不是所有问题都能提前获知.
还记得吗? Any类型与任何类型都相容. 经推导得出的类型就可能是Any.
这时, 类型检查工具发挥不了什么作用. 而且, 类型提示不在运行时强制检查. 快速失败是最后一道防线.
利用鸭子类型做防御性编程, 无须使用isinstance()或hasattr()测试就能处理不同的类型.
再举一个例子, 模仿collections.namedtuple处理field_names参数的方式.
field_nanes参数既可以是各个标识符以空格或逗号分隔的字符串, 也可以是标识符序列.
利用鸭子类型, 可以像示例13-5那样处理.
# 示例13-5 利用鸭子类型处理一个字符串或由字符串构成的可迭代对象
# 假设是一个字符串(EAFP原则: 取得原谅比获得许可容易).
try:
# 把逗号替换成空格, 再拆分(按空格拆分)成名称列表.
field_names = field_names.replace(',', ' ').split()
# 抱歉, field_names 的行为不像是字符串; 没有, replace方法, 或者返回的结果无法拆分.
except AttributeError:
# 如果抛出AttributeError, 说明field_names不是字符串,
# 那就假设field_names是由名称构成的可迭代对象.
pass
# 为了确保是可迭代对象, 也为了留存一份副本, 根据现有数据创建一个元组.
# 元组比列表紧凑, 还能防止代码意外改动名称.
field_names = tuple(field_names)
# 使用str.isidentifier确保每个名称都是有效的标识符.
if not all(s.isidentifier() for s in field_names):
raise ValueError('field_names must all be valid identifiers')
示例13-5展示的情况说明, 有时鸭子类型比静态类型提示更具表现力.
类型提示无法表达'field_names必须是一个字符串, 各个标识符以空格或逗号分隔.'
(在使用鸭子类型时, 我们不关心对象的具体类型,
而是关注对象的属性和方法是否满足我们的需求只要满足就可以使用.)
在typeshed项目中, namedtuple签名的相关部分如下所示(完整源码见stdlib/3/collections/__init__.pyi).
def namedtuple(
typename: str
field_names: Union[str, Iterable[str]],
*,
# 余下的签名省略了
可以看到, field_names的类型注解是Union[str, Iterable[str]],这个注解基本够用, 但是不能捕获所有问题.
研究过动态协议之后, 接下来换个话题, 讨论运行时类型检查更为外显的一种形式, 即大鹅类型.
13.5 大鹅类型
抽象类表示接口.
--Bjarne Stroustrup
C++之父③
(注3: 出自<<C++语言的设计和演化>>.)
Python没有interface关键字. 我们使用抽象基类定义接口, 在运行时显式检查类型(静态类型检查工具也支持).
在Python术语表中, '抽象基类'词条很好地解释了抽象基类为鸭子类型语言带来的好处.
抽象基类是对鸭子类型的补充, 提供了一种定义接口的方式.
相比之下, 其他技术(例加hasattr())则显得笨拙或者不太正确(例如使用魔法方法).
抽象基类引入了虚拟子类, 这种类不继承其他类, 却能被isinstance()和issubclass()识别.
详见abc模块文档. ④ (注4: 2020年10月18日摘录.)
大鹅类型是一种利用抽象基类实现的运行时检查方式. 接下来将由Alex Martelli详细说明,
参见'水禽和抽象基类'附注栏.
**-------------------------------------------------------------------------------------------**
非常感谢我的朋友Alex Martelli 和Anna Ravenscroft.
我在OSCON 2013上把本书的原始提纲给二位看时. 他们鼓励我提交给O'Reilly出版.
后来, 他们还担任了本书的技术审校, 对本书做了全面审查.
本书引用最多的就是Alex的话. 他甚至提出撰写下面这篇短文. 接下来交给你了, Alex!
**-------------------------------------------------------------------------------------------**
*-----------------------------------------水禽和抽象基类---------------------------------------*
作者: Alex Martelli
维基百科上说是我协助传播了'鸭子类型'(忽略对象的真正类型, 转而关注对象有没有实现所需的方法, 签名和语义)
这种言简意眩的说法.
对Python来说, 这基本上是指避免使用isinstance检查对象的类型
(更别提type(foo)is bar这种更糟的检查方式了, 这样做没有任何好处, 甚至禁止最简单的继承方式).
总的来说, '鸭子类型'在很多情况下十分有用.
但是在其他情况下, 随着发展,通常有更好的方式, 事情是这样的......
近代, 属和种(包括但不限于水禽所属的鸭科)基本上是根据'表征学'(phenetics)分类的.
表征学关注的是形态和举止的相似性......主要是容易观察的特征.
因此使用'鸭子类型'做比喻是贴切的.
然而, 平行进化往往会导致不相关的种产生相似的特征,
形态和举止方面都是如此, 但是生态龛位的相似性是偶然的, 不同的种仍属不同的生态龛位.
编程语言中也有这种'偶然的相似性', 比如下面这个经典的面向对象编程示例.
# 画家
class Artist:
def draw(self): ...
# 神枪手
class Gunslinger:
def draw(self): ...
# 抽奖
class Lottery:
def draw(self): ...
显然, 只因为×和y这两个对象刚好都有一个名为draw的方法,
而且调用时不用传入参数(例如x.draw()和y.draw()), 远远不能确保二者可以相互调用, 或者具有相同的抽象.
也就是说, 从这样的调用中不能推导出语义相似性.
相反, 我们需要一位渊博的程序员主动把这种等价维持在一定层次上(意思是为x和y的draw的方法继承同一个基类).
生物和其他学科遇到的这个问题, 迫切需要(从很多方面来说, 是催生)表征学之外的分类方式解决,
这就引出了支序学(cladistics). 这种分类学主要根据从共同祖先那里继承的特征分类, 而不是单独进化的特征.
(近些年, DNA测序变得既便宜又快速, 这使支序学的实用地位变得更高.)
例如, 草雁(以前认为与其他鹅类比较相似)和麻鸭(以前认为与其他鸭类比较相似)现在被分到麻鸭亚科
(表明二者的相似性比鸭科中其他动物高, 因为它们的共同祖先比较接近).
此外, DNA分析表明,白翅木鸭与美洲家鸭(属于麻鸭)不是很像, 至少没有形态和举止看起来那么像,
因此把木鸭单独分成了一属, 完全不在麻鸭亚科中.
知道这些有什么用呢? 视情况而定!
比如, 逮到一只水禽后, 决定如何烹制才最美味时, 显著的特征(不是全部, 例如一身羽毛并不重要)
主要是口感和风味(过时的表征学), 这比支序学重要得多.
但在其他方面, 如对不同病原体的抗性(圈养水禽还是放养), DNA接近性的作用就大多了......
因此, 参照水禽的分类学演化,
我建议在鸭子类型的基础上补充(不是完全取代, 因为在某些时候, 鸭子类型还有它的作用)'大鹅类型'.
大鹅类型指的是, 只要cls是抽象基类(cls的元类是abc.ABCMeta), 就可以使用isinstance(obj, cls).
collections.abc中有很多有用的抽象类(Python标准库文档的numbers模块中还有一些). ⑤
(注5: 当然, 还可以自己定义抽象基类, 但是不建议高级Python程序员之外的人这么做.
同样, 也不建议自己定义元类......我说的'高级Python程序员'是指对Python语言的一招一式都了如指掌的人.
即便对这类人来说, 抽象基类和元类也不是常用工具.
如此'深层次的元编程'(如果可以这么讲的话), 适合框架的作者使用,
这样便于众多不同的开发团队独立扩展框架......
真正需要这么做的'高级Python程序员'不超过 1%. --Alex Martelli)
与具体类相比, 抽象基类有很多理论上的优点
(参阅<<More Effective C++: 35个改善编程与设计的有效方法(中文版)>>一书中的
"条款33: 将非尾端类设计为抽象类").
Python的抽象基类还有一个重要的实用优势:
终端用户可以使用register类方法在代码中把某个类'声明'为一个抽象基类的'虚拟'子类.
(为此, 被注册的类必须满足抽象基类对方法名称和签名的要求, 最重要的是要满足底层语义契约.
但是, 开发那个类时不用了解抽象基类, 更不用继承抽象基类.)
这大大打破了严格的强耦合, 与面向对象编程人员掌握的知识有很大出入, 因此使用继承时要小心.
有时, 为了让抽象基类识别子类, 甚至不用注册.
其实, 抽象基类的本质就是几个特殊方法.
>>> class Struggle:
... def __len__(self): return 23
...
>>> from collections import abc
>>> isinstance(Struggle(), abc.Sized)
True
可以看出, 无须注册, abc.Sized也能把Struggle识别为自己的子类, 只要实现了特殊方法__len__即可.
(要使用正确的句法和语义实现, 前者要求没有参数, 后者要求返回一个非负整数, 指明对象的'长度'.
如果不使用规定的句法和语义实现诸如__len__之类的特殊方法, 那么将导致非常严重的问题.)
最后我想说的是: 如果实现的类体现了numbers, collections.abc或其他框架中抽象基类的概念,
则要么继承相应的抽象基类(必要时), 要么把类注册到相应的抽象基类中.
开始开发程序时, 不要使用提供注册功能的库或框架, 要自己动手注册.
作为最常见的情况, 如果必须检查参数的类型(例如检查是不是'序列'), 则可以像下面这样做.
isinstance(the_arg, collections.abc.Sequence)
此外, '不要'在生产代码中定义抽象基类(或元类)......如果很想这样做, 我打赌可能是因为你想'找碴儿'.
刚拿到新工具的人都有大干一场的冲动. 如果能避开这些深奥的概念,
那么你(以及未来的代码维护人员)的生活将更愉快, 因为代码会变得简洁明了. '再会'!
*---------------------------------------------------------------------------------------------*
综上所述, 大鹅类型要求:
? 定义抽象基类的子类, 明确表明你在实现既有的接口;
? 运行时检查类型时, isinstance和issubclass的第二个参数要使用抽象基类, 而不是具体类.
Alex指出, 继承抽象基类其实就是实现必要的方法--这也明确表明了开发人员的意图.
这个意图还可以通过注册虚拟子类明确表述.
*-----------------------------------------------解读-------------------------------------------*
在这篇文章中, 提到了"鸭子类型"和抽象基类在Python中的使用.
"鸭子类型"是一种编程概念, 表示只关注对象是否实现了所需的方法, 签名和语义, 而不关注对象的真正类型.
这种方式避免了使用isinstance检查对象类型的做法, 使代码更加灵活.
然而, 在某些情况下, 鸭子类型可能不是最佳选择, 因此作者提出了"大鹅类型"的概念.
"大鹅类型"指的是使用抽象基类来进行类型检查.
"抽象基类"是一种在Python中定义和使用接口的方法.
抽象基类是一种特殊的类, 它定义了一组需要在其子类中实现的方法.
它们用于描述类的接口, 而不是具体的实现细节.
通过继承抽象基类, 子类必须实现指定的方法, 以满足接口的要求.
在Python中, 抽象基类是指继承自'abc.ABCMeta'元类的类,
并且可以使用isinstance(obj, cls)来检查一个对象是否是抽象基类cls的实例.
抽象基类通过明确表明实现的接口, 以及使用register方法将类声明为抽象基类的虚拟子类,
提供了更好的类型检查方式.
对比:
鸭子类型更加动态和灵活, 它关注对象的行为, 而不关心对象的具体类型.
优势: 可以让我们更加自由地处理对象, 只要它们具有所需的方法和行为.
抽象基类更加静态和明确, 它定义了一组规定的接口, 子类必须实现这些接口.
它们提供了一种强制性的方式来确保类的一致性和正确性.
优势: 当我们面对需要明确的接口和类型检查时, 抽象基类可以更好地满足我们的需求,
可以帮助我们在编写代码时遵循一致的设计和规范.
*---------------------------------------------------------------------------------------------*
**-------------------------------------------------------------------------------------------**
register的具体用法将在13.5.6节说明.
这里先举一个简单的例子:对于FrenchDeck类, 如果想通过issubclass(FrenchDeck, Sequence)检查,
那么可以使用以下几行代码把FrenchDeck注册为抽象基类Sequence的虚拟子类.
from collections.abc import Sequence
Sequence.register(FrenchDeck)
**-------------------------------------------------------------------------------------------**
使用isinstance和issubclass测试抽象基类(而不是具体类)更为人接受.
如果用于测试具体类, 则类型检查将限制多态--面向对象编程的一个重要功能. 用于测试抽象基类更加灵活.
毕竟, 如果某个组件没有通过子类实现抽象基类(但是实现了必要的方法),
那么事后还可以注册, 让显式类型检查通过.
然而, 即使是抽象基类, 也不能滥用isinstance检查,
因为用得多了可能导致代码异味, 即表明面向对象设计不佳.
在一连串if/elif/elif中使用isinstance做检查, 然后根据对象的类型执行不同的操作, 往往是不好的做法.
此时应该使用多态, 即采用一定的方式定义类, 让解释器把调用分派给正确的方法,
而不使用if/elif/elif块硬编码分派逻辑.
另外, 如果必须强制执行API契约, 那么通常可以使用isinstance检查抽象基类.
正如本书技术审校Lennart Regebro所说: '老兄, 如果你想调用我, 则必须实现这个.'
这对采用插入式架构的系统来说特别有用.
在框架之外, 鸭子类型通常比类型检查更简单且更灵活.
在那篇短文的最后, Alex多次强调, 要抑制住创建抽象基类的冲动.
滥用抽象基类会造成灾难性后果, 表明语言太注重表面形式, 这对以实用和务实著称的Python可不是好事.
在审阅本书的过程中, Alex在一封电子邮件中写道:
抽象基类是用于封装框架所引入的一般性概念和抽象的, 例如'一个序列'和'一个确切的数'.
(读者)基本上不需要自己编写新的抽象基类, 只要正确使用现有的抽象基类, 就能获得99.9%的好处,
而不用冒着设计不当导致的巨大风险.
面通过实例讲解大鹅类型.
13.5.1 子类化一个抽象基类
我们将遵循Martelli的建议, 先利用现有的抽象基类collections.MutableSequence.
然后再'斗胆'自己定义.
示例13-6明确地把FrenchDeck2声明为了collections.MutableSequence的子类.
# 示例13-6frenchdeck2.py: collections.MutableSequence的子类 FrenchDeck2
from collections import namedtuple, abc
Card = namedtuple('Card', ['rank', 'suit'])
class FrenchDeck2(abc.MutableSequence):
ranks = [str(n) for n in range(2, 11)] + list('JQKA')
suits = 'spades diamonds clubs hearts'.split()
def __init__(self):
self._cards = [Card(rank, suit) for suit in self.suits
for rank in self.ranks]
def __len__(self):
return len(self._cards)
def __getitem__(self, position):
return self._cards[position]
# 为了支持洗牌, 只需实现__setitem__方法即可.
def __setitem__(self, position, value):
self._cards[position] = value
# 但是, 继承MutableSequence的类必须实现__delitem__方法,
# 这是Mutablesequence类的一个抽象方法.
def __delitem__(self, position):
del self. _cards[position]
# 此外, 还要实现insert方法, 这是MutableSequence类的第三个抽象方法.
def insert(self, position, value):
self._cards.insert(position, value)
Python在导入时(加载并编译frenchdeck2.py模块时)不检查抽象方法的实现,
在运行时实例化FrenchDeck2类时才真正检查.
因此, 如果没有正确实现某个抽象方法, 那么Python就会抛出TypeError异常, 错误消息为
"Can't instantiate abstract class FrenchDeck2 with abstract methods __delitem__, insert".
正是这个原因, 即便FrenchDeck2类不需要__delitem__和insert提供的行为, 也要实现,
这是MutableSequence抽象基类的要求.
如图13-3所示, 抽象基类Sequence和MutableSequence的方法不全是抽象的.
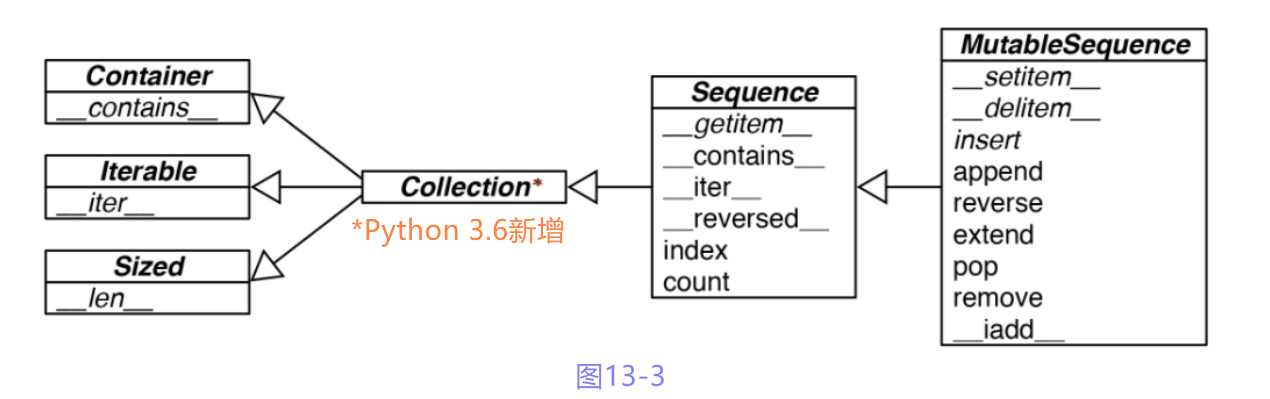
图13-3: MutableSequence抽象基类和collections.abc中它的超类的UML类图
(箭头由子类指向祖先, 以斜体显示的名称是抽象类和抽象方法)
为了把FrenchDeck2声明为MutableSequence的子类,
我不得不实现例子中用不到的__delitem__方法和insert方法.
作为回报, FrenchDeck2从Sequence继承了5个具体方法:
__contains__, __iter__, __reversed__, index和count.
另外, FrenchDeck2还从MutableSequence继承了6个方法:
append, reverse, extend, pop, renove和__iadd__(为就地拼接的+运算符提供支持).
在collections.abc中, 每个抽象基类的具体方法都是作为类的公开接口实现的, 因此天须知道实例的内部结构.
*---------------------------------------------------------------------------------------------*
作为实现具体子类的人, 你可以覆盖从抽象基类继承的方法, 以更高效的方式重新实现.
例如, __contains__方法会全面扫描序列, 但是, 如果你定义的序列按顺序保存元素,
则可以重新定义__contains__方法, 使用标准库中的bisect函数做二分查找, 从而提升搜索速度.
详见本书配套网站中的'Managing Ordered Sequences with Bisect'一文.
*---------------------------------------------------------------------------------------------*
为了充分利用抽象基类, 要知道有哪些抽象基类可用. 接下来介绍collections包中的抽象基类.
13.5.2 标准库中的抽象基类
从Python2.6开始, 标准库提供了多个抽象基类, 大都在collections.abc模块中定义, 不过其他地方也有,
例如, io包和numbers包中就有一些抽象基类. 但是, collections.abc中的抽象基类最常用.
*---------------------------------------------------------------------------------------------*
标准库中有两个名为abc的模块, 这里说的是collections.abc.
为了减少加载时间, Python 3.4在collections包之外实现这个模块(在Lib/_collections_abc.py中),
因此要与collections分开导入. 另一个abc模块就是abc(Lib/abc.py), 这里定义的是abc.ABC类.
每个抽象基类都依赖abc模块, 但是不用导入它, 除非自己动手定义新抽象基类.
*---------------------------------------------------------------------------------------------*
图13-4是collections.abc模块中17个抽象基类的UML类图(简图, 没有属性名称).
collections.abc的文档中有一张不错的表格, 对这些抽象基类做了总结,
说明了它们相互之间的关系, 以及各个基类提供的抽象方法和具体方法(叫作'混入方法').
图13-4中有很多多重继承.
第14章将着重说明多重继承, 在讨论抽象基类时通常无须考虑多重继承. ⑥
(注6: Java认为多重继承有危害, 因此没有提供支持, 但是提供了接口:
Java接口可以扩展多个接口, 而且Java类可以实现多个接口.)

图13-4: collections.abc模块中抽象基类的UML类图.
下面详述一下图13-4中那一群基类.
Iterable, Container和Sized:
每个容器都应该继承这3个抽象基类, 或者实现兼容的协议.
Iterable通过__iter__方法支持迭代,
Container通过__contains__方法支持in运算符,
Sized通过__len__方法支持len()函数.
Collection:
这个抽象基类是Python3.6新增的, 自身没有方法, 目的是方便子类化Iterable, Container和Sized.
'子类化'(Subclassing)是面向对象编程中的一个概念,
指的是通过已有的类创建一个新类, 新类包括已有类的所有属性和方法, 并且可以添加自己的属性和方法.
Sequence, Mapping和Set:
这3个抽象基类是主要的不可变容器类型, 而且各自都有可变的子类.
MutableSequence的详细类图见图13-3, MutableMapping和MutableSet的类图见图3-1和图3-2.
MappingView
在Python3中, 映射方法.items(), .keys()和.values()返回的对象分别实现了
ItensView, KeysView和ValuesView定义的接口.
前两个还实现了丰富的Set接口, 拥有'集合运算'一节讲到的所有运算符.
Iterator
注意它是Iterable的子类. 第17章将详细讨论.
Callable和Hashable:
这两个不是容器, 只不过因为collections.abc是标准库中定义抽象基类的第一个模块,
而它们又太重要了, 因此才被放在这里.
它们可以在类型检查中用于指定可调用和可哈希的对象.
检查对象能不能调用, 内置函数callable(obj)比tinsinstance(obj, Callable)使用起来更方便.
如果insinstance(obj, Hashable)返回False, 那么可以确定obj不可哈希.
然而, 返回True则可能是误判. 详见下面的附注栏, 结果可能不准确.
*---------------------使用isinstance检查Hashable和Iterable, 结果可能不准确----------------------*
使用isinstance和issubclass测试抽象基类Hashable和Iterable, 结果很有可能让人误解.
如果isinstance(obj, Hashable)返回True, 那么仅仅表示obj所属的类实现或继承了__hash__方法.
假如obj是包含不可哈希项的元组, 那么即便isinstance的检查结果为真, obj仍是不可哈希对象.
>>> from collections.abc import Hashable
>>> my_tuple = (1, 2, [3, 4])
>>> isinstance(my_tuple, Hashable)
True
>>> hash(my_tuple)
Traceback (most recent call last):
...
TypeError: unhashable type: 'list'
技术审校Jürgen Gmach指出, 利用鸭子类型判断一个实例是否可哈希是最准确的,
即调用hash(obj). 如果obj不可哈希, 那么该调用就会抛出TypeError.
另外, 即使isinstance(obj, Iterable)返回False,
Python依然可以通过__getitem__(基于0的索引)迭代obj(参见第1章和13.4.1节).
collections.abc.Iterable的文档指出:
判断一个对象是否可以迭代, 唯一可靠的方式是调用iter(obj).
(通常情况下, 只要一个对象实现了__getitem__(index)方法, 它就可以被迭代.)
了解了一些现有的抽象基类之后, 下面从零开始实现一个抽象基类, 然后实际使用, 以此实践大鹅类型.
这么做的目的不是鼓励所有人自己动手定义抽象基类, 而是借此教你如何阅读标准库和其他包中的抽象基类源码.
13.5.3 定义并使用一个抽象基类
本书第1版在讲'接口'那一章中给出了如下警告.
抽象基类与描述符和元类一样, 是用于构建框架的工具.
因此, 只有少数Python开发者编写的抽象基类不会对用户施加不必要的限制, 让他们做无用功.
如今, 抽象基类的作用更广, 可用在类型提示中, 支持静态类型.
8.5.7节讲过, 把函数参数类型提示中的具体类型换成抽象基类能为调用方提供更大的灵活性.
为了证明有必要定义抽象基类, 需要在框架中找到使用它的场景. 想象一下这个场景:
你想在网站或移动应用程序中显示随机广告, 但是在整个广告清单轮转一遍之前, 不重复显示广告.
假设我们在构建一个名为ADAM的广告管理框架. 它的职责之一是, 支持用户提供随机挑选的无重复类.
⑦为了让ADAM的用户明确理解'随机挑选的无重复'组件是什么意思, 我们将定义一个抽象基类.
(注7: 客户可能要审查随机发生器, 或者代理想作弊......谁知道呢!)
受到'栈'和'队列'(以物体的排放方式说明抽象接口)的启发,
我将使用现实世界中的物品命名这个抽象基类:
宾果机和彩票机是随机从有限的集合中挑选物品的机器, 选出的物品没有重复, 直到选完为止.
把这个抽象基类命名为Tombola, 这是宾果机和打乱数字的滚动容器的意大利语名.
抽象基类Tombola有4个方法, 其中两个是抽象方法.
.load(...) 把元素放入容器.
.pick() 从容器中随机拿出一个元素, 再返回这个元素.
另外两个是具体方法.
.loaded() 如果容器中至少有一个元素, 就返回True.
.inspect() 返回由容器中现有的元素构成的元组, 不改变容器的内容(内部的顺序不保留).
图13-5展示了抽象基类Tombola和3个具体实现.

图13-5: 一个抽象基类和3个子类的UML类图.
根据UML的约定, 抽象基类Tombola和它的抽象方法使用斜体.
虚线箭头表示接口实现, 这里表示Tombolist不仅实现了Tombola接口,
还被注册为Tombola的虚拟子类(详见本章后文) ⑧
(注8: <<registeredn>>和<<virtual subclass>>不是标准的UML术语. 这里使用二者表示Python类之间的关系.)
抽象基类Tombola的定义如示例13-7所示.
# 示例13-7 tombola.py: Tombola是有两个抽象方法和两个具体方法的抽象基类
import abc
# 继承abc.ABC, 定义一个抽象基类.
class Tombola(abc.ABC):
# 抽象方法使用@abstractmethod装饰器标记, 主体通常只有文档字符串. ⑨
@abc.abstractmethod
def load(self, iterable):
"""从可迭代对象中添加元素"""
# 根据文档字符串, 如果没有元素可选, 那么应该抛出LookupError.
@abc.abstractmethod
def pick(self):
"""
随机删除元素, 再返回被删除的元素。
如果实例为空, 那么这个方法应该抛出LookupError
"""
# 抽象基类可以包含具体方法.
def loaded(self):
"""如果至少有一个元素, 就返回True, 否则返回False"""
# 抽象基类中的具体方法只能依赖抽象基类定义的接口
# (只能使用抽象基类中的其他具体方法, 抽象方法或特性).
return bool(self.inspect())
def inspect(self):
"""返回由容器中的当前元素构成的有序元组"""
items = []
# 我们不知道具体子类如何存储元素, 但可以不断调用.pick()方法, 把Tombola清空......
while True:
try:
items.append(self.pick())
except LookupError:
break
# ......然后再使用.load(...)把所有元素放回去.
self.load(items)
return tuple(items)
(注9: 在抽象基类出现之前, 抽象方法会抛出NotImplementedError, 表明由子类负责实现.
在Smalltalk-80中, 抽象方法的主体会调用从object继承的subclassResponsibility方法, 抛出错误,
错误消息为"My subclass should have overridden one of my messages".)
*---------------------------------------------------------------------------------------------*
其实, 抽象方法可以有实现代码. 即便实现了, 子类也必须覆盖抽象方法,
但是在子类中可以使用super()函数调用抽象方法, 在此基础上添加功能, 而不是从头开始实现.
@abstractmethod装饰器的用法请参见abc模块的文档.
*---------------------------------------------------------------------------------------------*
虽然示例13-7中的.inspect()方法的实现方式有些笨拙, 但是表明, 有了.pick()方法和.load(...)方法,
如果想查看Tombola中的内容, 可以先把所有元素挑出, 然后再放回去--毕竟我们不知道元素具体是如何存储的.
这个示例的目的是强调抽象基类可以提供具体方法, 只要仅依赖接口中的其他方法就行.
Tombola的具体子类知晓内部数据结构, 可以使用更聪明的实现覆盖.inspect()方法, 但这不是强制要求.
示例13-7中的, loaded()方法只有一行代码, 但是耗时:
调用.inspect()方法构建有序元组的目的仅仅是在其上调用bool()函数.
虽然这样做没问题, 但是具体子类可以做得更好, 后文见分晓.
注意, 实现.inspect()方法采用的迁回方式要求捕获self.pick()抛出的LookupError.
self.pick()会抛出LookupError这一事实也是接口的一部分,
但是在Python中没办法明确表明, 只能在文档中说明(参见示例13-7中抽象方法pick的文档字符串).
选择使用LookupError异常的原因是, 在Python的异常层次关系中, 它与IndexError和KeyError有关,
而这两个是具体实现Tombola所用的数据结构最有可能抛出的异常.
因此, 实现代码可能会抛出LookupError, IndexError, KeyError, 或者符合要求的LookupError自定义子类.
异常的部分层次结构如图13-6所示.
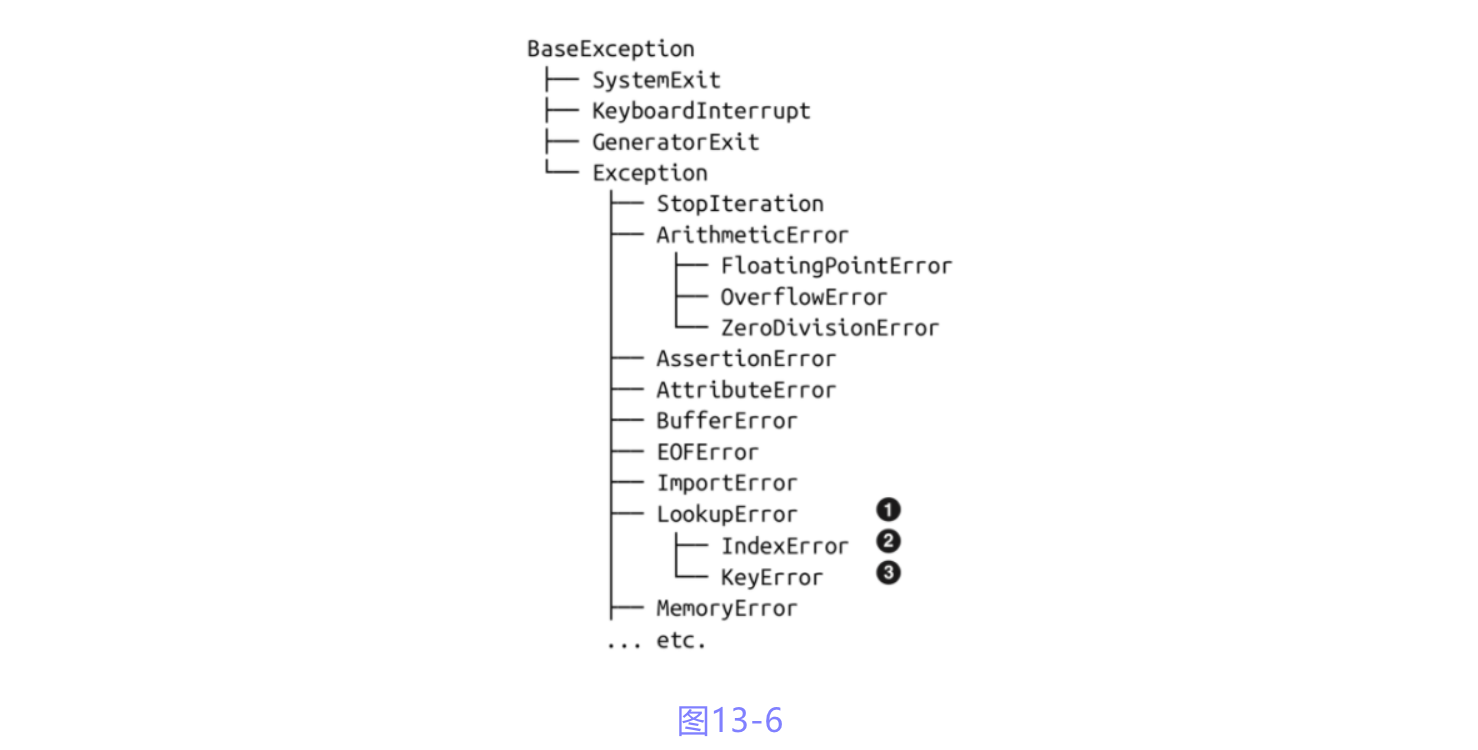
图13-6:Exception类的部分层次结构. ⑩
(注10: 完整的层次结构参见 Python标准库文档中的'5.4. Exceptionhierarchy'一节.)
1. 在Tombola.inspect方法中处理的是LookupError异常.
2. IndexError是LookupError的子类, 会在尝试从序列中获取索引超过最后位置的元素时抛出.
3. 当使用不存在的键从映射中获取元素时, 抛出KeyError异常.
我们自己定义的抽象基类Tombola完成了.
为了一睹抽象基类对接口所做的检查, 下面尝试使用一个有缺陷的实现来'糊弄'Tombola, 如示例13-8所示.
# 示例13-8 不符合Tombola要求的子类无法蒙混过关
>>> from tombola import Tombola
# 把Fake声明为Tombola的子类.
>>> class Fake(Tombola):
... def pick(self):
... return 13
...
# 创建了Fake类, 目前没有错误.
>>> Fake
<class'_main_.Fake'>
# 尝试实例化Fake时抛出了TypeError.
# 错误消息十分明确, Python认为Fake是抽象类, 因为它没有实现抽象基类Tombola声明的抽象方法之一load.
>>> f = Fake()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: Can't instantiate abstract class Fake with abstract method load
我们的第一个抽象基类定义好了, 而且还用它实际验证了一个类.
稍后将定义抽象基类Tombola的子类, 在此之前必须说明抽象基类的一些编程规则.
13.5.4 抽象基类句法详解
声明抽象基类的标准方式是继承abc.ABC或其他抽象基类.
除了ABC基类和@abstractmethod装饰器,
abc模块还定义了@abstractclassmethod装饰器, @abstractstaticnethod装饰器和@abstractproperty装饰器.
然而, 后3个装饰器在Python 3.3中弃用了,
因为现在可以在@abstractmethod之上叠放装饰器, 那3个就显得多余了.
例如, 声明抽象类方法的推荐做法如下所示.
class MyABC(abc.ABC):
@classmethod # 类方法装饰器
@abc.abstractmethod # ABC基类提供的装饰器
def an_abstract_classmethod(cls,...):
pass
***-----------------------------------------------------------------------------------------***
在函数上叠放装饰器的顺序通常很重要, @abstractmethod的文档就特别指出:
与其他方法描述符一起使用时, abstractmethod()应该放在最里层......?
(注11: 摘自abc模块文档中的@abc.abstractmethod词条.)
***-----------------------------------------------------------------------------------------***
也就是说, 在@abstractmethod和def语句之间不能有其他装饰器.
说明抽象基类的句法之后, 接下来要实现几个具体子代, 实际使用Tombola.
13.5.5 子类化抽象基类Tombola
定义好抽象基类Tombola之后, 要开发两个具体子类, 满足Tombola规定的接口.
这两个子类的类图如图13-5所示, 图中还有13.5.6节将要讨论的一个虚拟子类.
示例13-9中的BingoCage类是在示例7-8的基础上修改的, 使用了更好的随机发生器.
BingoCage实现了所需的抽象方法load和pick.
# 示例13-9 bingo.py: BingoCage是Tombola的具体子类
import random
from tombola import Tombola
# BingoCage类会显式扩展Tombola类.
class BingoCage(Tombola):
def __init__(self, items):
"""
假设将在线上游戏中使用这个随机发生器.
random.SystemRandon使用os.urandom(...)函数实现randon API.
根据os模块的文档, os.urandon(...)函数生成'适合用于加密'的随机字节序列.
"""
self._randomizer = random.SystemRandom()
self._items = []
# 委托.load(...)方法实现初始加载.
self.load(items)
def load(self, items):
self._items.extend(items) # 往列表末尾追加元素.
# 没有使用random.shuffle()函数, 而是使用了SystemRandom实例的.shuffle()方法.
self._randomizer.shuffle(self._items)
# pick方法的实现方式与示例7-8一样.
def pick(self):
try:
return self._items.pop()
except IndexError:
raise LookupError('pick from empty Bingocage')
# __call__方法也跟示例7-8中的一样.
# 为了满足Tombola接口, 无须实现这个方法, 不过额外增加方法也没有危害.
def __call__(self):
self.pick()
BingoCage从Tombola中继承了耗时的loaded方法和笨拙的inspect方法.
这两个方法都可以覆盖, 变成示例13-10中速度更快的一行代码.
这里想表达的观点是, 我们可以偷懒, 直接从抽象基类中继承不是那么理想的具体方法.
从Tombola中继承的方法没有BingoCage自己定义的那么快,
不过只要Tombola的子类正确实现pick方法和load方法, 就能提供正确的结果.
示例13-10是Tombola接口的另一种实现, 虽然与之前不同, 但完全有效.
LottoBlower打乱'数字球'后没有取出最后一个, 而是取出了一个随机位置上的球.
# 示例13-10 loto.py:LottoBlower是Tombola的具体子类, 覆盖了继承的inspect方法和loaded方法
import random
from tombola import Tombola
class LottoBlower(Tombola):
# 初始化方法接受任何可迭代对象, 使用传入的参数构建一个列表.
def __init__(self, iterable):
self.balls = list(iterable)
def load(self, iterable):
self._balls.extend(iterable)
def pick(self):
try:
# 如果范围为空, 那么random.randrange(...)函数就会抛出ValueError.
# 为了兼容Tombola, 可以捕获该异常, 重新抛出LookupError.
position = random.randrange(len(self._balls))
except ValueError:
raise LookupError('pick from empty LottoBlower')
# 否则, 从self._balls中取出随机选中的元素.
return self._balls.pop(position)
# 覆盖loaded方法, 避免调用inspect方法(示例13-7中的Tombola.loaded方法就是这么做的).
# 可以直接处理self._balls, 而不必构建整个元组, 从而提升速度.
def loaded(self):
return bool(self._balls)
# 覆盖inspect方法, 仅用一行代码.
def inspect(self):
return tuple(self._balls)
示例13-10中有个习惯做法值得指出: 在__init__方法中, self.balls存储的是list(iterable),
而不是iterable的引用(没有直接把iterable赋值给self._balls, 为参数创建别名).
13.4.3节说过, 这样做使得LottoBlower更灵活, 因为iterable参数可以是任何可迭代类型.
把元素存入列表中还可以确保能取出元素. 就算iterable参数始终传入列表,
list(iterable)也会创建参数的副本, 这依然是好的做法, 因为要从中删除元素,
而客户可能不希望自己提供的列表被修改. ?
(注12: 6.5.2节专门讨论过这种防止混淆别名的问题.)
接下来介绍大鹅类型的重要动态特性: 使用register方法声明虚拟子类.
13.5.6 抽象基类的虚拟子类
大鹅类型的一个基本特征(也是值得用水禽来命名的原因之一)是, 即便不继承,
也有办法把一个类注册为抽象基类的虚拟子类.
这样做时, 我们承诺注册的类忠实地实现了抽象基类定义的接口, 而Python会相信我们, 不再检查.
如果我们说谎了, 那么常规的运行时异常会把我们捕获.
注册虚拟子类的方式是在抽象基类上调用register类方法.
这么做之后, 注册的类就变成了抽象基类的虚拟子类, 而且issubclass函数能够识别这种关系,
但是注册的类不会从抽象基类中继承任何方法或属性.
*--------------------------------------------------------------------------------------------*
虚拟子类不继承注册的抽象基类, 而且任何时候都不检查它是否符合抽象基类的接口, 即便在实例化时也不会检查.
另外, 静态类型检查工具目前也无法处理虚拟子类.
详见Mypy的2922号工单, 即'ABCMeta.register support'.
*--------------------------------------------------------------------------------------------*
register方法通常作为普通函数调用(参见13.5.7节), 不过也可以作为装饰器使用.
在示例13-11中, 我们使用装饰器句法实现了Tombola的虚拟子类TomboList, 如图13-7所示.

图13-7: TomboList的UML类图, 它既是list的真实子类, 也是Tombola的虚拟子类.
# 示例13-11 tombolist.py: TomboList是Tombola的虚拟子类
from random import randrange
from tombola import Tombola
# 把Tombolist注册为Tombola的虚拟子类.
@Tombola.register
class Tombolist(list): # Tombolist扩展list.
def pick(self):
# Tombolist从list继承布尔值行为, 在列表不为空时返回True。
if self:
position = randrange(len(self))
# pick调用从list继承的self.pop方法, 传入一个随机的元素索引.
return self.pop(position)
else:
raise LookupError('pop from empty TomboList')
# Tombolist.load 等同于 list.extend. (对象.load(self) == list.extend(self))
load = list.extend
# loaded 委托bool. ?
def loaded(self):
return bool(self)
def inspect(self):
return tuple(self)
# 始终可以这样调用register. 如果需要注册不是自己维护的类, 却能满足指定的接口就可以这么做.
# Tombola.register(TomboList) # 不使用语法糖, 使用函数形式注册.
(注13: loaded()不能采用load()那种方式, 因为list类型没有实现loaded所需的__bool__方法.
而内置函数bool不需要__boo1__方法, 因为它还可以使用__len__方法.
详见Python文档中'Built-in Types'一章的'4.1.Truth Value Testing')
注册之后, 可以使用issubclass函数和isinstance函数判断TomboList是不是Tombola的子类.
>>> from tombola import Tombola
>>> from tombolist import TomboList
>>> issubclass(Tombolist, Tombola)
True
>>> t = TomboList(range(100))
>> isinstance(t, Tombola)
True
然而, 类的继承关系是在一个名为__mro__(Method Resolution Order, 方法解析顺序)的特殊类属性中指定的.
这个属性的作用很简单, 它会按顺序列出类及其超类, 而Python会按照这个顺序搜索方法.
?查看TomboList类的__mro__属性, 你会发现它只列出了'真实'的超类, 即list和object. (没有虚拟的超类.)
(注14: 14.4节将专门讲解__mro__类属性. 现在知道这个简单的解释就行了.)
>>> Tombolist.__mro__
(<class'tombolist. Tombolist'>, <class 'list'>, <class 'object'>)
Tombolist.__mro__中没有Tombola, 因此Tombolist没有从Tombola中继承任何方法.
对抽象基类Tombola的研究到此结束.
13.5.7节将介绍register函数在标准库中的使用.
13.5.7 register的实际使用
在示例13-11中, 我们把Tombola.register当作一个类装饰器使用.
在Python3.3之前, register不能这样使用, 必须像示例13-11末尾的注释那样,
作为一个普通函数在类主体之后调用,
然而, 即便是现在, 仍然经常把register当作普通函数调用, 注册其他地方定义的类.
例如, 在collections.abc模块的源码中,
内置类型tuple, str, range和memoryview 会像下面这样被注册为Sequence的虚拟子类。
Sequence.register(tuple)
Sequence.register(str)
Sequence.register(range)
Sequence.register(memoryview)
另外, 还有几个内置类型也会在_collections_abc.py中注册为抽象基类的虚拟子类.
注册过程仅在导入模块时发生是没有问题的, 因为如果想使用抽象基类, 则必须导入模块.
例如, 从collections.abc中导入MutableMapping之后才能执行isinstance(my_dict, MutableMapping)检查.
子类化抽象基类或者注册到抽象基类上都能让类通过issubclass检查和isinstance检查(后者依赖前者).
但是, 有些抽象基类还支持结构类型, 详见13.5.8节.
13.5.8 使用抽象基类实现结构类型
抽象基类最常用于实现名义类型.
假如一个类Sub会显式继承抽象基类AnABC, 或者注册到AnABC上,
那么AnABC这个名称就和Sub连在了一起, 因此在运行时, issubclass(AnABC, Sub)会返回True.
(issubclass: 用于检查一个类是否是另一个类或其他类的子类.)
相比之下, '结构类型': 通过对象公开接口的结构判断对象的类型,
如果一个对象实现了某个类型定义的方法, 那么该对象就与该类型相容.
?动态鸭子类型和静态鸭子类型是实现结构类型的两种方式.
(注15: 类型相容问题详见8.5.1节的'子类型与相容'.)
其实, 某些抽象基类也支持结构类型.
Alex在'水禽和抽象基类'附注栏中说过, 未注册的类也可能被识别为抽象基类的子类.
下面再次给出他举的例子(增加了issubclass测试).
>>> class Struggle:
... def __len__(self):
... return 23
>>> from collections import abc
>> isinstance(Struggle(), abc.Sized)
True
# abc.Sized是Python中的一个抽象基类, 用于表示具有固定大小的对象.
# 这个基类定义了一个抽象方法__len__, 任何实现了__len__方法的类, 都可以被视为abc.Sized的子类.
>>> issubclass(Struggle, abc.Sized)
True
经issubclass函数判断, Struggle类是abc.Sized的子类(进而isinstance也得出同样的结论),
因为abc.Sized实现了一个名为__subclasshook__的特殊的类方法.
sized类的__subclasshook__方法会检查通过参数传入的类有没有名为__len__的属性.
如果有, 就认为是Sized的虚拟子类. 详见示例13-12.
# 示例13-12 源文件 Lib/_collections_abc.py中Sized的定义
class Sized(metaclass=ABCMeta):
__slots__ = ()
@abstractmethod
def __len__(self):
return 0
@classmethod
def __subclasshook__(cls, C):
if cls is Sized:
# 如果C.__mro__列出的某个类(C及其超类)的__dict__中有名为__len__的属性......
if any("__len__" in B.__dict__ for B in C.__mro__):
# ......就返回True, 表明C是Sized的虚拟子类.
return True
# 否则, 返回NotImplemented, 让子类检查继续下去.
return NotImplemented
**-------------------------------------------------------------------------------------------**
如果对子类检查的细节感兴趣, 可以阅读Python 3.6中ABCMeta.__subclasscheck__方法的源码,
该源码位于Lib/abc.py文件中. 注意, 源码中有大量条件判断和两个递归调用.
在Python 3.7中, Ivan Levkivskyi和Inada Naoki使用C语言重写了abc模块的大多数逻辑, 性能更好,
详见Python 31333号工单.
ABCMeta.__subclasscheck__目前的实现只是调用__abc_subclasscheck__.
相关的C语言源码在cpython/Modules/_abc.c文件第605行.
**-------------------------------------------------------------------------------------------**
抽象基类对结构类型的支持就是通过__subclasshook__实现的.
可以使用抽象基类确立接口, 使用isinstance检查该抽象基类,
一个完全无关的类仍然能通过issubclass检查, 因为该类实现了特定的方法
(或者该类竭力说服了__subclasshook__为它'担保').
那么, 自己定义的抽象基类应该实现__subclasshook__方法吗? 或许不应该.
在Python源码中, 我只见过Sized这种仅有一个特殊方法的抽象基类实现了__subclasshook__方法,
而且只检查那个特殊方法的名称.
由于__len__是'特殊'方法, 因此我们可以十分肯定它的作用符合预期.
然而, 即便是特殊方法和基本的抽象基类, 这种假设也是有风险的.
例如, 虽然映射实现了__len__, __getitem__和__iter__, 但是肯定不能把它看作Sequence的子类型,
因为无法通过整数偏移或切片从映射中获取元素.
鉴于此, abc.Sequence类没有实现__subclasshook__方法.
对于我们自己编写的抽象基类, __subclasshook__的可信度并不高.
假如有一个名为Spam的类, 它实现或继承了load, pick, inspect和loaded等方法,
但是我并不能百分之百确定它的行为与Tombola类似.
让程序员把Spam定义为Tonbola的子类, 或者使用Tombola.register(Spam)注册, 这样才能板上钉钉.
当然, 实现__subclasshook__方法时还可以检查方法签名和其他功能, 但是我认为没这个必要.
# issubclass函数在判断一个类是否是另一个类的子类时会调用__subclasshook__方法.
from abc import ABC
# 必须将MyABC类设置为抽象化子类.
class MyABC(ABC):
@classmethod
def __subclasshook__(cls, C):
if hasattr(C, 'my_method'):
return True
return NotImplemented
class MyClass:
pass
class MySubClass:
def my_method(self):
pass
print(issubclass(MyClass, MyABC)) # False
print(issubclass(MySubClass, MyABC)) # True
13.6 静态协议
8.5.10节介绍过静态协议.
我本来打算到本章时再全面讲解协议, 但是函数类型提示又不得不提到协议, 因为鸭子类型是Python的重要基石,
而且不涉及协议的静态类型检查无法很好地处理Python风格的API.
本节将通过两个简单的示例来讲解静态协议, 顺带讨论一下数值抽象基类和协议.
首先说明如何利用静态协议来注解8.4节见过的double()函数, 并对它做类型检查.
13.6.1 为double函数添加类型提示
在向更习惯静态类型语言的程序员介绍Python时, 我喜欢用简单的double函数举例.
>>> def double(x):
... return x * 2
...
>>> double(1.5)
3.0
>>> double('A')
'AA'
>>> double([10,20,30])
[10, 20, 30, 10, 20, 30]
>>> from fractions import Fraction
# Fraction(2, 5) 创建分数 2/5
>>> double(Fraction(2, 5))
Fraction(4, 5) # 分数的分子乘以2, 分母保持不变.
引入静态协议之前, 几乎不可能为double函数添加完美的类型提示, 用途总会受到限制. ?
(注16: 好吧, 除了用作示例, double()函数没什么太大的用处.
不过, 在Python 3.8增加静态协议之前, 标准库中也有很多函数无法准确注解.
我使用协议添加类型提示, 修正了typeshed项目中的很多bug.
比如说, 修正'Should Mypy warn about potential invalid arguments to max?'
工单的拉取请求利用_SupportsLessThan协议改进了max, min, sorted和list.sort的注解.)
得益于鸭子类型, double函数甚至支持未来可能出现的类型, 例如16.5节的增强的Vector类.
>>> from vector_v7 import Vector
# vector_v7中实现了__mul__方法 返回Vector(n * factor for n in self)
>>> double(Vector([11.0, 12.0,13.0]))
Vector([22.0, 24.0, 26.0])
Python最初实现类型提示利用的是名义类型系统,
注解中的类型名称要与实参的类型名称(或者某个超类的名称)匹配.
我们知道, 支持必要操作的类型就算实现了协议, 而这样的类型可能很多, 无法一一列出,
因此在Python3.8之前, 类型提示无法描述鸭子类型.
有了typing.Protocol之后, 现在可以告诉Mypy, double函数接受支持x*2运算的参数×, 如示例13-13所示.
# 示例13-13 double_protocol.py: 使用Protocol定义double函数
from typing import Typevar, Protocol
# T在__mul__签名中使用.
T = TypeVar('T')
class Repeatable(Protocol):
# __mul__是Repeatable协议的核心. self参数通常不注解, 因为默认假定为所在的类.
# 这里使用T是为了确保返回值的类型与self相同. 另外注意, 这个协议把repeat_count限制为int类型.
def __mul__(self: T, repeat_count:int)->T:...
# 类型变量RT的上界由Repeatable协议限定, 类型检查工具将要求具体使用的类型实现Repeatable协议.
RT = TypeVar('RT', bound=Repeatable)
# 现在, 类型检查工具可以确认×参数是一个可以乘以整数的对象, 而且返回值的类型与×相同.
def double(x: RT)-> RT:
return x * 2
通过这个示例可以看出, 为什么PEP544的标题为'Protocols: Structural subtyping(statio duck typing)'.
提供给double函数的实参×是什么名义类型无关紧要, 只要实现了_mul_方法就行--这就是鸭子类型的好处.
13.6.2 运行时可检查的静态协议
在类型图(参见图13-1)中, typing.Protocol位于静态检查区域, 即图的下半部分.
然而, 定义typing.Protocol的子类时,
可以借由@runtime_checkable装饰器让协议支持在运行时使用isinstance/issubclass检查.
这背后的原因是, typing.Protocol是一个抽象基类, 因此它支持13.5.8节讲过的__subclasshook__.
从Python3.9开始, typing模块提供了7个可在运行时检查的协议.
下面是其中两个, 直接摘自typing模块的文档.
class typing.SupportsComplex
抽象基类, 有一个抽象方法__complex__.
class typing.SupportsFloat
抽象基类, 有一个抽象方法__float__.
这些协议旨在检查数值类型可否转换类型.
如果对象o实现了__complex__, 那么调用complex(o)应该得到一个complex值,
因为在背后支持内置函数complex()的就是特殊方法__complex__.
示例13-14 是typing.SupportsComplex 协议的源码.
# 示例13-14 typing.SupportsComplex协议的源码
@runtime_checkable
class SupportsComplex(Protocol):
"""具有一个抽象方法__complex__的抽象基类"""
__slots__ = ()
@abstractmethod
def __complex__(self) -> complex:
pass
这个协议的核心是抽象方法__complex__.
?在静态类型检查中, 如果一个对象实现了__complex__方法, 而且只接受参数self, 并且返回一个complex值,
那么就认为该对象与SupportsComplex协议相容.
(注17: __slots__属性与目前讨论的话题无关, 它是11.11节讲过的一种优化措施.)
由于SupportsComplex应用了@runtine_checkable类装饰器,
因此该协议也可以使用isinstance检查, 如示例13-15所示.
# 示例 13-15在运行时使用SupportsComplex
>>> from typing import SupportsComplex
>>> import numpy as np
# complex64是NumPy提供的5种复数类型之一.
>>> c64 = np.complex64(3+4j)
# NumPy中的复数类型均不是内置类型complex的子类.
>>> isinstance(c64, complex)
False
# 但是, NumPy中的复数类型实现了__complex__方法, 因此符合SupportsComplex协议.
>>> isinstance(c64, SupportsComplex)
True
# 因此, 可以使用NumPy中的复数类型创建内置的complex对象
>>> c = complex(c64)
>>> c
(3+4j)
# 可惜, 内置类型complex没有实现__complex__方法.
# 不过, 当c是一个complex值时complex(c)能得到正确的结果.
>>> isinstance(c, SupportsComplex)
False
>>> complex(c)
(3+4j)
根据最后一点, 如果想测试对象c是不是complex或SupportsComplex,
那么可以为isinstance的第二个参数提供一个类型元组, 如下所示.
isinstance(c, (complex, SupportsComplex))
另外, 还可以使用numbers模块中定义的抽象基类Complex.
内置类型complex, 以及NumPy中的complex64类型和complex128类型都被注册为numbers.Complex的虚拟子类了,
因此可以像下面这样检查.
>>> import numbers
>>> isinstance(c, numbers.Complex)
True
>>> isinstance(c64, numbers.Complex)
True
本书第1版建议使用numbers模块中的抽象基类, 现在这个建议已经过时,
因为静态类型检查工具无法识别那些抽象基类(详见13.6.8节).
本节的目的本是说明运行时可检查的协议可使用isinstance测试,
但是后来才发现这个示例不是特别适合使用isinstance, 具体原因见后面的'充分利用鸭子类型'附注栏.
*---------------------------------------------------------------------------------------------*
对于外部类型检查工具, 使用isinstance明确检查类型有一个好处:
在条件为isinstance(o, MyType)的if语句块内, Mypy可以推导出o对象的类型与MyType相容.
*---------------------------------------------------------------------------------------------*
*-------------------------------------充分利用鸭子类型------------------------------------------*
在运行时, 鸭子类型往往是类型检查的最佳方式.
不要调用isinstance或hasattr, 直接在对象上尝试执行所需的操作, 如果抛出异常, 就处理异常. 下面举个例子.
接着前面讨论的内容, 假如我们想把对象0当作复数使用, 那么可以这么做.
if isinstance(o, (complex, SupportsComplex)):
# 当o可以转换成复数时执行一些操作
else:
raise Typeerror('o must be convertible to complex')
对于大鹅类型, 则要使用抽象基类numbers.Complex.
if isinstance(o, numbers.Complex):
# 当o是Complex实例时执行一些操作
else:
raise TypeError('o must be an instance of Complex')
然而, 我更喜欢利用鸭子类型, 因为取得原谅比获得许可容易(EAFP原则).
try:
c = complex(o)
except TypeError as exc:
raise Typeerror('o must be convertible to complex') from exc
(from 关键字引发异常确实可以在异常追踪中保留原始异常的上下文信息, 没有这句好像也不影响, 以后再探索.)
但是, 如果只想抛出TypeError, 就省略try/except/raise语句, 直接写成如下形式.
c = complex(o)
这时, 如果o不是可接受的类型, 那么Python将抛出异常, 输出非常明确的消息,
例如, 当o是一个元组时, 输出的消息如下所示.
TypeError: complex() first argument must be a string or a number, not 'tuple'
'tuple我觉得在这种情况下使用鸭子类型效果好得多.
*--------------------------------------------------------------------------------------------*
现在, 我们知道, 在运行时可以利用静态协议检查诸如complex和numpy.complex64之类的现有类型.
接下来讨论运行时可检查协议的局限性.
13.6.3 运行时协议检查的局限性
如前所述, 类型提示在运行时一般会被忽略.
使用isinstance或issubclass检查静态协议有类似的影响.
例如, 实现__float__方法的类在运行时都被认定是SupportsFloat的虚拟子类,
不管__float__方法是否返回一个float值.
请看下面的控制台会话.
>>> import sys
>>> sys.version
'3.9.5(V3.9.5:0a7dcbdb13, May 3 2021, 13:17:02) \n[Clang 6.0 (clang-600.0.57)]"
>>> c = 3+4j
>>> c.__float__
<method-wrapper '__float__' of complex object at 0x10a16c590>
>>>c.__float__()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can't convert complex to float
在Python 3.9中, complex类型确实有__float__方法,
不过该方法仅仅抛出TypeError并输出一个明确的错误消息.
如果那个__float__方法有注解, 则返回值类型应该是NoReturn(参见8.5.12节).
但是, typeshed项目中complex.__float__的类型提示解决不了这个问题,
因为Python的运行时一般会忽略类型提示, 而且根本无法访问typeshed项目中的存根文件.
继续前面的Python3.9控制台会话.
>>> from typing import SupportsFloat
>>> c = 3+4j
>>> isinstance(c, SupportsFloat)
True
>>> issubclass(complex, SupportsFloat)
True
检查的结果容易让人误解.
运行时对SupportsFloat的检查表明, 可以把一个complex值转换成float值,
而实际情况却是抛出类型错误.
***-----------------------------------------------------------------------------------------***
Python 3.10.0b4删除了complex.__float__方法, 解决了complex类型的这个问题.
但是, 类似的问题普遍存在.
isinstance或issubclass只检查有没有特定的方法, 不检查方法的签名, 更不会检查方法的类型注解.
这种行为不会改变, 因为在运行时大规模检查类型损耗的性能是不可接受的. ?
(注18: 感谢PEP544(关于协议)的作者之一Ivan Levkivskyi指出,
类型检查不是检查×的类型是不是T, 而是判断×的类型是否与T相容, 检查相容的开销更大,
难怪即便是很短的Python脚本, Mypy也要用几秒才能完成类型检查.)
***-----------------------------------------------------------------------------------------***
下面来看一下如何在用户定义的类中实现静态协议.
13.6.4 支持静态协议
请回忆一下第11章中构建的Vector2d类.
既然一个复数和一个Vector2d实例都由一对浮点数构成, 那么顺理成章, 应该支持把Vector2d转换成complex.
示例13-16给出了__complex__方法的实现, 在示例11-11中最后一版的基础上增强Vector2d类.
为了支持双向转换, 还定义了类方法fromcomplex, 执行反向操作, 根据complex值构建Vector2d实例.
# 示例13-16 vector2d_v4.py: 与complex 相互转换的方法
def __complex__(self):
return complex(self.x, self.y)
@classmethod
def fromcomplex(cls, datum):
return cls(datum.real, datum.imag)
假设datum有.real属性和.imag属性. 更好的实现参见示例13-17.
根据上述代码, 以及Vector2d现有的_abs_方法(参见示例11-11), 可以执行以下操作.
>>> from typing import SupportsComplex, SupportsAbs
>>> from vector2d_v4 import Vector2d
>>> v = Vector2d(3, 4)
>>> isinstance(v, SupportsComplex)
True
>>> isinstance(v, SupportsAbs)
True
>>> complex(v)
(3+4j)
>>> abs(v)
5.0
>>> Vector2d.fromcomplex(3+4j)
Vector2d(3.0, 4.0)
对于运行时类型检查, 示例13-16可以胜任, 但是为了让Mypy更好地做静态检查和错误报告,
__abs__方法, __complex__方法和fromcomplex方法应该有类型提示, 如示例13-17所示.
# 示例13-17 vector2d v5.py: 为当前研究的方法添加注解
# 需要把返回值类型注解为float, 否则Mypy推导出的类型是Any, 而且不检查方法主体.
def __abs__(self) -> float:
return math.hypot(self.x, self.y)
# 即使不注解, Mypy也能推导出该方法返回一个complex值.
# 在Mypy的某些配置下这个注解可以避免一个警告.
def __complex__(self)-> complex:
return complex(self.x, self.y)
# SupportsComplex确保datum可以转换成要求的类型.
@classmethod
def fromcomplex(cls, datum: SupportsComplex) -> Vector2d:
# 有必要显式转换, 因为SupportsComplex类型没有声明下一行用到的.real属性和.imag属性.
# 例如, 虽然Vector2d没有这两个属性, 但是实现了__complex__方法.
c = complex(datum)
return cls(c.real, c.imag)
如果该模块的顶部有 from __future__ import annotations,
那么fromcomplex的返回值类型可以是Vector2d.
有了那个导入语句, 类型提示将存储为字符串, 在导入时(求解函数定义时)不做求解.
不从__future__中导入annotations, Vector2d在那一刻(类尚未完整定义)就是无效引用,
应该写为字符串'Vector2d', 假装是向前引用.
这个__future__导入由'PEP 563-Postponed Evaluation of Annotations'引入, 在Python 3.7中实现.
原本计划在Python 3.10中把这个行为定为默认行为, 但是后来推迟到下一个版本了.
?到那时, 这个导入语句就是多余的了, 但是也没有危害.
(注19: Python指导委员会在python-dev中发布的决定.

接下来介绍如何创建一个静态协议(稍后再扩展).
13.6.5 设计一个静态协议
研究大鹅类型时, 我们定义了抽象基类Tombola(参见13.5.3节),
现在将使用静态协议定义一个类似的接口.
抽象基类Tombola有两个抽象方法: pick和load.
定义具有这两个方法的静态协议也不难, 不过, 我从Go语言社区学到一项知识:
单方法协议实现的静态鸭子类型更有用且更灵活.
Go语言标准库中有多个这样的接口, 例如Reader, 这是一个I/O接口, 只要求一个read方法.
以后, 如果觉得需要一个更完整的协议, 可以把多个协议合而为一.
可以随机从中选择元素的容器, 不一定需要重新加载容器, 但是肯定需要选择元素的方法,
因此, 我决定为精简的Randompicker协议实现这样一个方法.
该协议的代码如示例13-18所示, 演示用法的测试如示例13-19所示.
# 示例13-18 randompick.py: 定义RandomPicker
from typing import Protocol, runtime_checkable, Any
# 继承Protocol类设计一个协议.
@runtime_checkable # runtime_checkable装饰器将该协议标记为在运行时可检查.
class RandomPicker(Protocol):
# 其他类中定义pick方法, 就可以使用isinstance(obj, RandomPicker)检查.
# 实现了不继承RandomPicker类, 却为RandomPicker类的子类.
def pick(self) -> Any: ...
**-------------------------------------------------------------------------------------------**
pick方法的返回值类型是Any.
15.8节将说明如何让RandomPicker支持泛型参数, 允许协议的用户指定pick方法的返回值类型.
**-------------------------------------------------------------------------------------------**
# 示例13-19 randompick_test.py: 使用RandomPicker
import random
from typing import Any, Iterable, TYPE_CHECKING
# 定义实现协议的类无须先导入静态协议.
# 这里导入RandomPicker是因为后面的test_isinstance会用到.
from randompick import Randompicker
# SimplePicker实现RandomPicker协议, 但不是后者的子类. 这就是静态鸭子类型.
class SimplePicker:
def __init__(self, items: Iterable) -> None: # __init__没有返回值.
self._items = list(items)
# 打乱顺序.
random.shuffle(self._items)
# 默认的返回值类型就是Any, 因此严格来说, 不需要这个注解.
# 但是, 加上注解可以明确表明我们实现的是示例13-18中的RandomPicker协议.
def pick(self)-> Any:
return self._items.pop()
# 如果想让Mypy检查, 那么别忘了加上类型提示->None.
def test_isinstance() -> None:
# 我为popper变量添加了类型提示, 指出Mypy知道SimplePicker是相容的.
popper: Randompicker = SimplePicker([1])
# 这个测试证明, SimplePicker的实例也是RandomPicker的实例.
# 背后的原因是, RandonPicker应用了@runtime_checkable装饰器, 而且SimplePicker有所需的pick方法.
assert isinstance(popper, RandomPicker)
# 这个测试在SimplePicker实例上调用pick方法,
# 确认返回一个提供给SimplePicker的元素, 然后对返回的元素做静态检查和运行时检查.
def test_item_type()-> None:
items = [1, 2]
popper = SimplePicker(items)
item = popper.pick()
assert item in items
# 如果TYPE_CHECKING的标志位为True则会调用reveal_type()函数来显示变量item的类型.
# 最后, 使用assert语句断言变量item的类型应该是整数类型.
if TYPE_CHECKING:
reveal_type(item) # 这一行在Mypy的输出中生成一个说明.
assert isinstance(item, int)
我们在示例8-22中见过的reveal_type是能被Mypy识别的'魔法'函数,
无须导入, 而且只能在受typing.TYPE_CHECKING条件保护的if块中调用.
typing.TYPE_CHECKING条件只在静态类型检查工具眼中为True, 在运行时为False.
示例13-19中的两个测试均能通过, Mypy也没有发现任何错误.
对于pick方法返回的item, reveal_type输出的结果如下所示.
$ mypy randompick_test.py
randompick_test.py:24: note: Revealed type is 'Any'
这是我们创建的第一个协议. 下面介绍一些设计协议的建议.
13.6.6 协议设计最佳实践
Go语言10年的静态鸭子类型经验表明, 窄协议(narrow protocol)更有用.
通常, 窄协议只有一个方法, 很少超过两个.
Martin Fowler写了一篇定义角色接口(role interface)的文章, 设计协议时可做考虑.
另外, 有时你会发现, 协议在使用它的函数附近定义, 即在'客户代码'中而不是在库中定义.
这样方便调用相关函数创建新类型, 也有利于扩展和使用驭件(mock)测试.
窄协议和客户代码协议都能有效避免紧密耦合, 正符合接口隔离原则(Interface Segregation Principle).
这个原则可用一句话概括:'不应强迫客户依赖用不到的接口.'
'Contributing to typeshed'页面建议静态协议采用以下命名约定(以下3点直接引用原文, 未做改动).
? 使用朴素的名称命名协议, 清楚表明概念(例如Iterator和Container).
? 使用Supportsx形式命名提供可调用方法的协议(例如SupportsInt, SupportsRead和SupportsReadSeek). ?
? 使用Hasx形式命名有可读属性和可写属性, 或者有读值方法和设值方法的协议(例如HasItems和HasFileno).
(注20: 所有方法均可调用, 因此这一条建议没有说到点子上.
改成'提供一个或两个方法; 会不会好一点儿? 反正这是建议, 不是严格规定.)
我喜欢Go语言标准库采用的一种命名约定:
对于只有一个方法的协议, 如果方法名称是动词, 就在末尾加上'-er'或'-or', 变成名词.
例如, 不要命名为SupportsRead, 而要命名为Reader.
此外还有一些例子: Formatter, Animator和Scanner.
如果想寻找灵感, 可以阅读 Asuka Kenji 写的'Go(Golang)Standard Library Interfaces(Selected)'一文.
保持协议精简的好处是以后方便扩展.
通过13.6.7节你会发现, 衍生现有协议, 额外添加方法并不难.
13.6.7 扩展一个协议
13.6.6节开头提到, Go语言开发人员定义接口(他们对静态协议的称呼)时倾向于极简主义.
很多广泛使用的Go语言接口只有一个方法.
如果实际使用中发现协议需要多个方法, 那么不要直接为协议添加方法, 最好衍生原协议, 创建一个新协议.
在Python中, 扩展静态协议有几个问题需要注意, 如示例13-20所示.
# 示例13-20 randompickload.py: 扩展RandomPicker协议
from typing import Protocol, runtime_checkable
from randompick import Randompicker
# 如果希望衍生的协议可在运行时检查, 则必须再次应用这个装饰器, 因为该装饰器的行为不被继承. ?
@runtime_checkable
# 每个协议都必须明确把typing.Protocol列出来, 作为基类.
# 另外, 再列出要扩展的协议, 这与Python中的继承不是一回事. ?
class LoadableRandomPicker(RandomPicker, Protocol):
# 现在是符合'常规'的面向对象编程方式了: 只需要声明衍生协议新增的方法.
# pick方法的声明继承自RandomPicker。
def load(self, Iterable) -> None: ...
注21: 详细原因见'PEP 544--Protocols: Structural subtyping (static duck typing)'
中关于@runtime_checkable那一节.
注22: 同样, 详细原因见PEP544中的'Merging and extending protocols'一节.
*----------------------------------------解读-------------------------------------------------*
每个协议都必须明确把typing.Protocol列出来, 作为基类.
另外, 再列出要扩展的协议, 这与Python中的继承不是一回事.
LoadableRandomPicker协议的定义不是在Python中的继承方式.
它使用关键字class声明, 但紧接着列出的RandomPicker和Protocol并不是在Python中的继承关系.
相反, RandomPicker和Protocol在这里是用于定义协议的.
RandomPicker是一个现有的协议, 而Protocol是一个特殊的基类, 用于指示一个类是一个协议.
通过将这两个名称列在LoadableRandomPicker的定义中,
代码表达的是LoadableRandomPicker协议继承自RandomPicker协议,
并且它还满足Protocol基类的要求, 即被解析为一个协议.
这样的定义方式不同于在Python中的普通类继承关系.
普通的类继承关系:
class MyClass(BaseClass):
...
MyClass通过class关键字继承自BaseClass, 表示MyClass是BaseClass的子类, 将继承BaseClass类的属性和方法.
协议的继承关系:
class MyProtocol(BaseProtocol, Protocol):
...
MyProtocol通过class关键字声明一个协议, 它继承自BaseProtocol和Protocol,
表示MyProtocol是BaseProtocol和Protocol的子协议.
这里的继承关系是针对协议的, 它并不意味着MyProtocol会继承BaseProtocol的属性和方法,
而是表示MyProtocol扩展了BaseProtocol和Protocol的定义, 新增了一些要求的方法或属性.
协议的继承关系不同于普通类的继承关系, 协议的继承主要用于组合多个协议的要求, 并不会继承具体的实现.
*---------------------------------------------------------------------------------------------*
本章对静态协议的定义和使用就讨论到这里了.
最后, 再讲一下数值抽象基类, 以及取而代之的数值协议.
13.6.8 numbers模块中的抽象基类和Numeric协议
'论数字塔的倒下'一节讲过, 标准库中numbers包内的抽象基类可用于做运行时类型检查.
如果想检查是不是整数, 可以使用isinstance(x, numbers.Integral).
int, bool(int的子类), 以及外部库中注册为numbers包中某个抽象基类的虚拟子类的整数类型, 都能通过这个测试.例如, NumPy提供了21个整数类型, 另外还有注册为numbers.Real的虚拟子类的多个浮点数类型,
以及注册为numbers.Complex的虚拟子类的不同位宽度(bit width)的复数.
有点儿奇怪的是, decimal.Decimal没有注册为numbers.Real的虚拟子类.
原因也很好理解, 如果在程序中需要使用Decimal提供的精度, 那么你肯定不想与精度低的浮点数混淆.
可惜, numbers包定义的数字塔不是为静态类型检查设计的.
根抽象基类numbers.Number没有方法, 因此, 对于x: Number声明,
Mypy不会允许你对x做任何算术运算或者调用任何方法.
既然如此, 应该怎么做呢? typeshed项目是一个很好的选择.
这个项目为Python标准库提供类型提示, 例如, statistics模块的类型提示在存根文件statistics.pyi中.
在这个文件中你能找到以下定义, 很多函数的注解用到了这两个类型.
_Number = Union[float, Decimal, Fraction]
_NumberT = Typevar('_NumberT', float, Decimal, Fraction)
这种方式是不错, 但是不全面, 不支持标准库以外的数值类型.
numbers包中的抽象基类支持在运行时检查外部数值类型, 即那些注册为虚拟子类的数值类型.
目前的趋势是使用typing模块提供的数值协议(参见13.6.2节).
然而, 数值协议在运行时可能会让你失望.
13.6.3节讲过, 在Python 3.9中, complex类型虽然实现了__float__方法,
但是该方法仅仅抛出TypeError, 警告'无法把复数转换为浮点数'.
complex类型实现的__int__方法也是如此.
在Python 3.9中, 这些方法的存在导致isinstance返回的结果让人误解.
Python 3.10把complex类型无条件抛出TypeError的那些方法删除了. ?
(注23: 详见41974号工单, 即'Remove complex._float_, complex._floordiv_, etc'.)
另外, NumPy中复数类型实现的__float__方法和__int__方法就好一些, 只在第一次使用时发出警告.
>>> import numpy as np
>>> cd = np.cdouble(3+4j)
>>> cd
(3+4j)
>>> float(cd)
<stdin>:1: Complexwarning: Casting complex values to real
discards the imaginary part
3.0
反向转换也有问题. 内置类型complex, float和int,
以及numpy.float16和numpy.uint8, 没有实现__complex__方法,
因此isinstance(x, SupportsComplex)返回False.
?'NumPy中的复数类型, 比如np.complex64, 则实现了__complex__方法, 可以转换成内置类型complex.
(注24: 我没有测试NumPy提供的其他浮点数类型和整数类型.)
然而, 实际使用中, 内置构造函数complex()能正确处理所有这些类型的实例, 不报错也不发出警告.
>> import numpy as np
>>> from typing import SupportsComplex
>>> sample = [1+0j, np.complex64(1+0j), 1.0, np.float16(1.0), 1, np.uint8(1)]
>>> [isinstance(x, SupportsComplex) for x in sample]
[False, True, False, False, False, False]
>>> [complex(x) for x in sample]
[(1+0j), (1+0j), (1+0j), (1+0j), (1+0j), (1+0j)]
由上述代码可知, isinstance对SupportsComplex的检查, 有些是失败的,
但是全部都可以成功转换成complex类型.
Guido van Rossum在typing-sig邮件列表中指出, 内置构造函数complex只接受一个参数, 所以全都可以转换.
另外, 对于下面的to_complex()函数, 使用Mypy检查时, 参数可以接受全部6种类型.
def to_complex(n: SupportsComplex) -> complex:
return complex(n)
写作本书时, NumPy没有类型提示, 因此NumPy中的所有数值类型都是Any.
?然而, 不知为何, 虽然在typeshed项目中仅内置类complex有__complex__方法,
但Mypy'知道'内置类型int和float可以转换成complex. ?
注25: NumPy中的数值类型全都注册为numbers包中相应抽象基类的虚拟子类, 但是全被Mypy忽略了.
注26: 这是typeshed项目的善意谎言, 截至Python 3.9, 内置类型complex并没有__complex__方法.
综上所述, 虽然数值类型不应该这么难做类型检查, 但是现在的情况是, 'PEP 484-Type Hints'有意避开数字塔,
含蓄地建议类型检查工具硬编码内置类型complex, float和int之间的子类型关系.
Mypy就是这样做的, 而且从实用角度出发, 还认定int和float与SupportsComplex相容,
尽管二者没有实现__complex__方法.
*---------------------------------------------------------------------------------------------*
我只在测试与complex相互转换的操作时发现,
使用isinstance检查与数值相关的Supports*协议得到的结果出乎意料.
如果不使用复数, 则可以依赖那些协议, 而不使用numbers包中的抽象基类.
*---------------------------------------------------------------------------------------------*
本节的主要结论如下.
? numbers包中的抽象基类对运行时类型检查来说没有问题, 但是不适合做静态类型检查.
? SupportsComplex, SupportsFloat等数值相关的静态协议完美支持静态类型,
但是当涉及复数时, 运行时类型检查的结果不可靠.
下面简单总结一下本章内容.
13.7 本章小结
类型图(参见图13-1)是理解本章内容的关键.
简要介绍4种类型方式之后, 我们对比了分别支持鸭子类型和静态鸭子类型的动态协议和静态协议.
这两种协议有一个共同的基本特征, 即类不需要显式声明对任何特定协议的支持.
只要实现了协议要求的方法, 类就支持那个协议.
接下来, 重要的一节是13.4节.
这一节深入探讨了Python解释器实现序列和可迭代动态协议的方式, 包括对二者的部分实现.
我们说明了如何利用猴子补丁为类添加额外的方法, 在运行时实现协议.
之后又提到了防御性编程, 包括不显式使用isinstance或在try/except结构中使用hasattr检查结构类型,
以及快速失败原则.
Alex Martelli在13.5节的'水禽和抽象基类'附注栏中介绍大鹅类型之后,
我们说明了如何子类化现有的抽象基类, 考察了标准库中重要的抽象基类, 还从头开始自己创建了一个抽象基类,
后来又利用传统的子类化和注册机制提供了具体实现.
最后我们了解到, 即使是不相关的类, 只要提供了抽象基类定义的接口要求的方法,
也能被特殊方法__subclasshook__识别, 从而让抽象基类支持结构类型.
13.6节也很重要, 这一节接着8.5.10节继续探讨了静态鸭子类型.
我们了解到, @runtime_checkable装饰器也利用_subclasshook_方法在运行时支持结构类型.
不过, 静态协议最好结合静态类型检查工具使用, 连同类型提示, 实现更可靠的结构类型.
我们还讨论了静态协议的设计和实现, 以及如何扩展.
最后的13.6.8节讲述了被抛弃的数字塔的悲伤故事, 还指出了现有替代方案的一些缺点,
包括SupportsFloat等数值静态协议, 以及Python 3.8在typing模块中增加的协议.
本章的主旨是告诉你, 在现代的Python中, 我们有4种互补的接口编程方法, 它们各有优缺点.
对于现代的Python基准代码, 只要体量够大, 4种类型模式都有用武之地.
抛下哪一种类型, 作为Python程序员, 你的日子都不会好过.
话又说回来, 当初Python只支持鸭子类型时可是大受欢迎.
JavaScript, PHP和Ruby这些受欢迎的语言, 以及不太流行,
但是影响深远的Lisp, Smalltalk, Erlang和Clojure, 都从鸭子类型的强大和简单中受益匪浅.
13.8 延伸阅读
如果想了解类型的优缺点, 以及typing.Protocol对经过静态检查的基准代码健康状况的重要性,
强烈推荐阅读Glyph Lefkowitz写的文章
'I Want ANew Duck: typing.Protocol and the future of duck typing'.
我还从他的另一篇文章中学到了很多, 题为
'Interfaces and Protocols——Comparing zope.interface and typing.Protocol'.
zope.interface是为松耦合插件系统定义接口的一种早期机制.
Plone CMS, Web框架Pyramid和异步编程框架Twisted(Glyph 发起的项目)当时采用的都是zope.interface. ?
(注27: 感谢技术审校Jürgen Gmach推荐'Interfaces and Protocols'一文. )
优秀的Python图书几乎不可避免要讲到鸭子类型.
我最喜欢的两本书在本书第1版发布后都有更新: <<Python 快速入门(第3版)>>
和Python in a Nutshell, 3rd ed.(Alex Martei, Anna Ravenscroft和Steve Holden著).
Bill Venners 对Guido van Rossum的访谈讨论了动态类型的优缺点,
访谈内容记录在'Contracts in Python: A Conversation with Guido van Rossum, Part IV'一文中.
Martin Fowler在;Dynamic Typing;一文中对这场辩论做了全面而深入的分析.
Martin还写了'Role Interface'一文, 13.6.6节提到过.
那篇文章讲的虽然不是鸭子类型, 但是与Python协议设计密切相关, 比较了窄角色接口和类的广义公开接口.
与Python中静态类型(包括静态鸭子类型)相关的信息, 最好的资源通常是Mypy文档.
详见'Protocols and structural subtyping'一章.
下面的资料全与大鹅类型有关.
<<PythonCookbook(第3版)中文版>> 的8.12节讲了抽象基类的定义.
该书写在Python3.4之前, 因此没有使用推荐的句法声明抽象基类(子类化abc.ABC),
而是使用了metaclass关键字(本书第24章才用到).
除了这个小问题, 8.12节很好地讲解了抽象基类的主要功能.
<<Python 标准库>>中有一章讲了abc模块.
那一章在Python Module of the Week 网站中可以在线阅读.
该书作者Hellmann使用的也是声明抽象基类的旧方式,
即PluginBase(metaclass=abc.ABCMeta),
从Python3.4开始, 可简化成PluginBase(abc.ABC).
对于抽象基类, 多重继承不可避免, 经常用到.
基本的容器抽象基类Sequence, Mapping和Set扩展自Collection,
而Collection又扩展自多个抽象基类(参见图13-4).
第14章会深入探讨这个重要话题.
'PEP 3119—Introducing Abstract Base Classes'讲解了抽象基类的基本原理.
'PEP 3141—A Type Hierarchy for Numbers'引入了numbers模块中的一众抽象基类.
Mypy的3186号工单'int is not a Number?'展开了一场论战,
讨论数字塔为什么不适合在静态类型检查中使用.
Alex Waygood在StackOverflow中写了一篇全面的解答, 详述注解数值类型的各种方式.
我会继续关注3186号工单的进展, 但愿最后有一个圆满结局, 让静态类型与大鹅类型兼容--本该如此.
*---------------------------------------------杂谈---------------------------------------------*
'Python 静态类型的MVP之旅'
我在Thoughtworks工作, 这家公司是敏捷软件开发领域的全球领导者.
在Thoughtworks, 我们经常建议客户创建和部署MVP, 即最简可用产品(minimal viable product).
按照我的同事Paulo Caroli在'Lean Inception'一文(发表在Martin Fowler的集体博客中)中给出的定义,
最简可用产品是'为用户提供产品的简单版本, 用于验证关键业务设想'.
自2006年以来. Guido van Rossum和其他核心开发人员在设计和实现静态类型时一直遵循MVP策略.
首先, Python 3.0实现的'PEP 3107—Function Annotations'提供了非常有限的语义,
只有为函数的参数和返回值附加注解的句法.
这样做显然是为了实验并收集反馈--MVP的关键优势.
8年后, 'PEP484-Type Hints'提出并获得批准, 在Python3.5中实现, 语言和标准库都没有变化,
只是增加了标准库中其他部分均未依赖的typing模块.
PEP 484仅支持具有泛型的名义类型(类似于Java), 把具体的静态检查工作交给外部工具.
那时, 关键功能有所缺失, 比如变量注解, 内置泛型和协议.
尽管有这些限制, 但是这个最简可用的类型系统已经体现出了价值,
足以吸引拥有特大型Python基准代码的公司(例如Dropbox, 谷歌和Facebook)投入使用,
吸引专业的IDE(例如PyCharm, Wing和VSCode)提供支持.
'PEP 526-Syntax for Variable Annotations'是演进路上的第一步, Python 3.6对解释器做出了改动.
为了支持'PEP 563—Postponed Evaluation of Annotations'和
'PEP 560—Core support for typing module and generic types',
Python 3.7对解释器做了更多改动.
加上'PEP 585—Type Hinting Generics In Standard Collections',
Python 3.9中内置的和标准库中的容器开始接受泛化类型提示.
那几年, 一些Python用户, 包括我, 并没有对类型提起兴趣.
学习Go语言之后, 我更加认为Python缺少静态鸭子类型是不可理解的, 毕竟这门语言的核心优势就是鸭子类型.
可这就是MVP策略的本质啊, 最简可用产品或许不能让所有潜在用户满意,
但是实现起来不费劲, 而且可以借助实际使用中得到的反馈指导下一步开发.
如果说我们从Python3中学到了什么, 那肯定是渐进式开发比一股脑发布新功能安全.
很高兴我们不用等到Python 4(如果真能等到的话)才能引起大公司的注意,
因为大公司已经发现, 与静态类型带来的好处相比, 增加的那点儿复杂性不值一提.
'流行语言实现类型的方式'
图13-8稍微修改了类型图(参见图13-1), 加上了支持各种类型实现方式的流行语言.

图13-8: 类型检查的4种方式, 以及支持各种方式的部分语言.
在我随机考察的有限样本中, 只有TypeScript和Python 3.8及以上版本支持全部4种方式.
Go语言显然是一门像Pascal那样传统的静态类型语言,
但是它开创了静态鸭子类型的先河--至少在当今广泛使用的语言中是这样.
我还把Go语言放在了大鹅类型象限中, 因为它的类型断言允许在运行时检查和适应不同的类型.
如果我在2000年画一个类似的图, 那么只有鸭子类型和静态类型象限中有语言.
据我所知, 20年前没有支持静态鸭子类型或大鹅类型的语言.
可以看到, 4个象限中都至少有3门流行语言, 这表明很多人发现了4种类型实现方式各自的价值.
'猴子补丁':
猴子补丁的名声不太好. 如果滥用, 则会导致系统难以理解和维护.
补丁通常与目标紧密耦合, 因此很脆弱.
还有一个问题是, 打了猴子补丁的两个库可能相互牵绊, 因为第二个库可能撤销了第一个库的补丁.
不过猴子补丁也有它的作用, 例如可以在运行时让类实现协议.
适配器设计模式通过实现全新的类解决了这种问题.
为Python打猴子补丁不难, 但是有些局限.
与Ruby和JavaScript不同, Python不允许为内置类型打猴子补丁.
其实, 我觉得这是优点, 因为这样可以确保str对象的方法始终是那些.
这一局限能减少外部库打的补丁出现冲突的概率.
'接口中的隐喻和习惯用法':
隐喻能打破壁垒, 让人更易于理解.
使用'栈'和'队列'描述基本的数据类型就有这样的功效: 这两个词清楚地道出了添加或删除元素的方式.
另外, Alan Cooper等人在<<About Face 4: 交互设计精髓>>一书中写道:
严格奉行隐喻设计毫无必要, 却把界面死死地与物理世界的运行机制捆绑在一起.
他说的是用户界面, 但对API同样适用.
不过Cooper同意, 当'真正合适的'隐喻'正中下怀'时,
可以使用隐喻(他用的词是'正中下怀',因为合适的隐喻可遇不可求).
我觉得本章用宾果机做比喻是合适的, 我相信自己
我读过不少UI设计方面的书, <<About Face: 交互设计精髓>>是最好的.
我从Cooper的书中学到的最宝责的知识是, 不把隐喻当作设计范式, 而代之以'习惯用法的界面'.
前面说过, Cooper说的不是API, 但是, 越深入思考他的观点, 我越觉得可以将之运用到Python中.
Python语言的基本协议就是Cooper所说的'习惯用法'.
知道'序列'是什么之后, 可以把这些知识应用到不同的场合.
这正是本书的主要目的: 着重讲解这门语言的基本惯用法, 让你的代码简洁, 高效且可读,
把你打造成能流畅写出Python代码的程序员.
文章来源:https://blog.csdn.net/qq_46137324/article/details/135725619
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 十、Three场景实现多个物体的合并
- 安卓fragment监听文本内容取值
- 基于ssm高校后勤保修系统可做毕业设计参考源码免费获取
- LINUX基础培训十一之日志管理
- Spring Cloud和Zookeeper的集成,构建高可扩展的分布式系统
- 钉钉学习笔记
- 虚拟专用网络(VPN):远程访问与点对点连接及其在Linux中的IPSec实现与日志管理
- 【已解决】Pytorch RuntimeError: expected scalar type Double but found Float
- Linux基础——进程初识(三)
- Python小说阅读器制作教程