Pytorch基础知识点复习
文章目录
本篇博客是本人对pytorch使用的查漏补缺,参考资料来自 深入浅出PyTorch,本文主要以提问的方式对知识点进行回顾,小伙伴们不记得的知识点可以查一下前面的教程哦。
并行计算
??现在并行计算的策略是不同的数据分布到不同的设备中,执行相同的任务(Data parallelism)。
??它的逻辑是,我不再拆分模型,我训练的时候模型都是一整个模型。但是我将输入的数据拆分。所谓的拆分数据就是,同一个模型在不同GPU中训练一部分数据,然后再分别计算一部分数据之后,只需要将输出的数据做一个汇总,然后再反传。其架构如下:
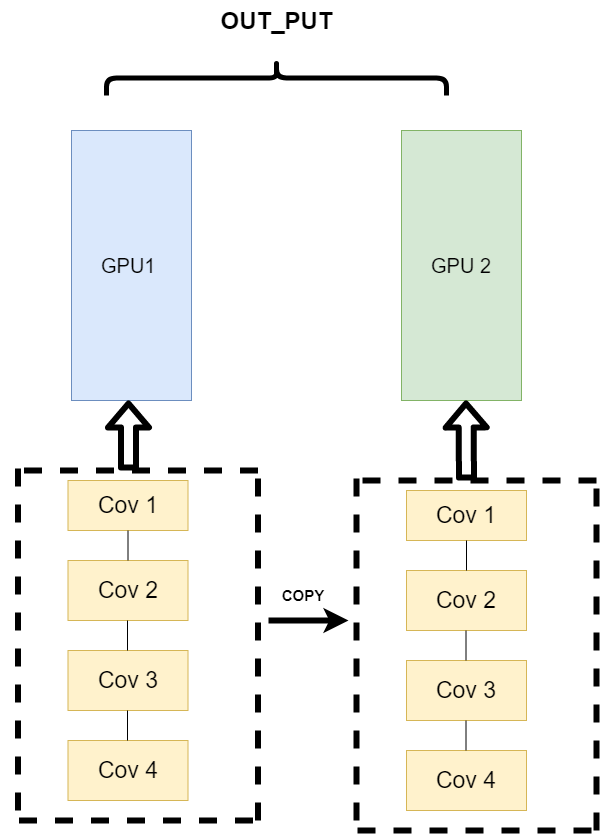
单卡训练
在PyTorch框架下,CUDA的使用变得非常简单,我们只需要显式的将数据和模型通过.cuda()方法转移到GPU上就可加速我们的训练。如下:
model = Net()
model.cuda() # 模型显示转移到CUDA上
for image,label in dataloader:
# 图像和标签显示转移到CUDA上
image = image.cuda()
label = label.cuda()
多卡训练
单机多卡DP
先我们来看单机多卡DP,通常使用一种叫做数据并行 (Data parallelism) 的策略,即将计算任务划分成多个子任务并在多个GPU卡上同时执行这些子任务。主要使用到了nn.DataParallel函数,它的使用非常简单,一般我们只需要加几行代码即可实现
model = Net()
model.cuda() # 模型显示转移到CUDA上
if torch.cuda.device_count() > 1: # 含有多张GPU的卡
model = nn.DataParallel(model) # 单机多卡DP训练
除此之外,我们也可以指定GPU进行并行训练,一般有两种方式
- nn.DataParallel函数传入device_ids参数,可以指定了使用的GPU编号
model = nn.DataParallel(model, device_ids=[0,1]) # 使用第0和第1张卡进行并行训练
- 要手动指定对程序可见的GPU设备
os.environ["CUDA_VISIBLE_DEVICES"] = "1,2"
多机多卡DDP
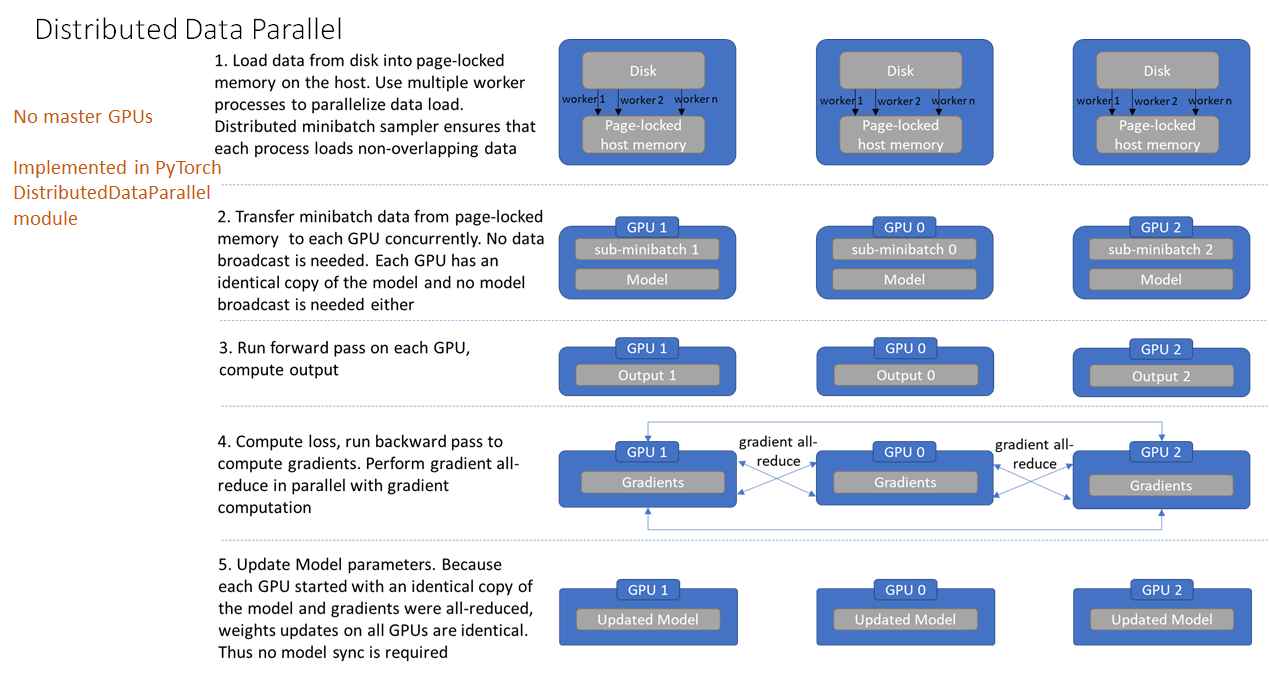
针对每个GPU,启动一个进程,然后这些进程在最开始的时候会保持一致(模型的初始化参数也一致,每个进程拥有自己的优化器),同时在更新模型的时候,梯度传播也是完全一致的,这样就可以保证任何一个GPU上面的模型参数就是完全一致的,所以这样就不会出现DataParallel那样显存不均衡的问题。
进程组的相关概念
-
GROUP:进程组,默认情况下,只有一个组,一个 job 即为一个组,也即一个 world。(当需要进行更加精细的通信时,可以通过 new_group 接口,使用 world 的子集,创建新组,用于集体通信等。)
-
WORLD_SIZE:表示全局进程个数。如果是多机多卡就表示机器数量,如果是单机多卡就表示 GPU 数量。
-
RANK:表示进程序号,用于进程间通讯,表征进程优先级。rank = 0 的主机为 master 节点。 如果是多机多卡就表示对应第几台机器,如果是单机多卡,由于一个进程内就只有一个 GPU,所以 rank 也就表示第几块 GPU。
-
LOCAL_RANK:表示进程内,GPU 编号,非显式参数,由 torch.distributed.launch 内部指定。例如,多机多卡中 rank = 3,local_rank = 0 表示第 3 个进程内的第 1 块 GPU。
DDP的基本用法 (代码编写流程)
- 在使用 distributed 包的任何其他函数之前,需要使用 init_process_group 初始化进程组,同时初始化 distributed 包。
- 使用 torch.nn.parallel.DistributedDataParallel 创建 分布式模型 DDP(model, device_ids=device_ids)
- 使用 torch.utils.data.distributed.DistributedSampler 创建 DataLoader
- 使用启动工具 torch.distributed.launch 在每个主机上执行一次脚本,开始训练
添加参数 --local_rank,这里的local_rank参数,可以理解为torch.distributed.launch在给一个GPU创建进程的时候,给这个进程提供的GPU号,这个是程序自动给的,不需要手动在命令行中指定这个参数。
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int) # 这个参数很重要
args = parser.parse_args()
local_rank = int(os.environ["LOCAL_RANK"]) #也可以自动获取
然后在所有和GPU相关代码的前面添加如下代码,如果不写这句代码,所有的进程都默认在你使用CUDA_VISIBLE_DEVICES参数设定的0号GPU上面启动
torch.cuda.set_device(args.local_rank) # 调整计算的位置
接下来我们得初始化backend,也就是俗称的后端,pytorch介绍了以下后端:
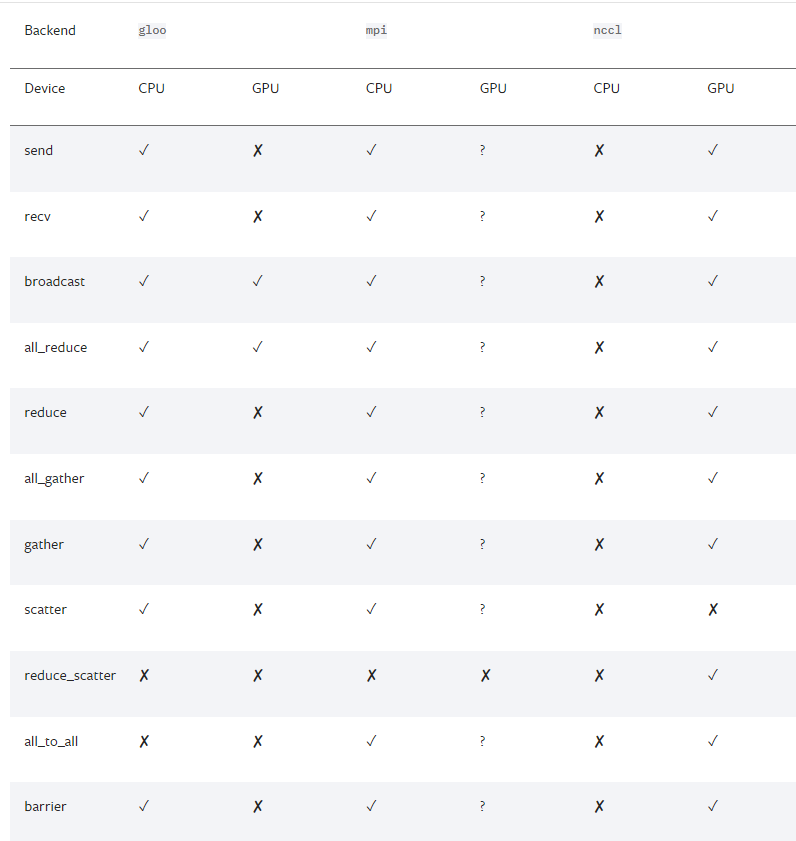
-
经验之谈
-
如果是使用cpu的分布式计算, 建议使用gloo,因为表中可以看到 gloo对cpu的支持是最好的
-
如果使用gpu进行分布式计算, 建议使用nccl。
-
-
GPU主机
-
InfiniBand连接,建议使用nccl,因为它是目前唯一支持 InfiniBand 和 GPUDirect 的后端。
-
Ethernet连接,建议使用nccl,因为它的分布式GPU训练性能目前是最好的,特别是对于多进程单节点或多节点分布式训练。 如果在使用 nccl时遇到任何问题,可以使用gloo 作为后备选项。 (不过注意,对于 GPU,gloo 目前的运行速度比 nccl 慢。)
-
-
CPU主机
-
InfiniBand连接,如果启用了IP over IB,那就使用gloo,否则使用mpi
-
Ethernet连接,建议使用gloo,除非有不得已的理由使用mpi。
-
当后端选择好了之后, 我们需要设置一下网络接口, 因为多个主机之间肯定是使用网络进行交换, 那肯定就涉及到IP之类的, 对于nccl和gloo一般会自己寻找网络接口,不过有时候如果网卡比较多的时候,就需要自己设置,可以利用以下代码
import os
# 以下二选一, 第一个是使用gloo后端需要设置的, 第二个是使用nccl需要设置的
os.environ['GLOO_SOCKET_IFNAME'] = 'eth0'
os.environ['NCCL_SOCKET_IFNAME'] = 'eth0'
可以通过以下操作知道自己的网络接口,输入ifconfig, 然后找到自己IP地址的就是, 一般就是em0, eth0, esp2s0之类的
我们一般还是会选择nccl后端,设置GPU之间通信使用的后端和端口:
# ps 检查nccl是否可用
# torch.distributed.is_nccl_available ()
torch.distributed.init_process_group(backend='nccl') # 选择nccl后端,初始化进程组
之后,使用 DistributedSampler 对数据集进行划分。它能帮助我们将每个 batch 划分成几个 partition,在当前进程中只需要获取和 rank 对应的那个 partition 进行训练:
# 创建Dataloader
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=16, sampler=train_sampler)
然后使用torch.nn.parallel.DistributedDataParallel包装模型:
# DDP进行训练
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
如何启动DDP
那么如何启动DDP,这不同于DP的方式,需要使用torch.distributed.launch启动器,对于单机多卡的情况:
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 main.py
# nproc_per_node: 这个参数是指你使用这台服务器上面的几张显卡
有时候虽然说,可以简单使用DP,但是DDP的效率是比DP高的,所以很多时候单机多卡的情况,我们还是会去使用DDP
DP 与 DDP 的优缺点
-
DP的优点:
- nn.DataParallel没有改变模型的输入输出,因此其他部分的代码不需要做任何更改,非常方便,一行代码即可搞定。
-
DP的缺点:
- DP进行分布式多卡训练的方式容易造成负载不均衡,第一块GPU显存占用更多,因为输出默认都会被gather到第一块GPU上,也就是后续的loss计算只会在cuda:0上进行,没法并行。
- 除此之外DP只能在单机上使用,且DP是单进程多线程的实现方式,比DDP多进程多线程的方式会效率低一些。
-
DDP的优点:
- 每个进程对应一个独立的训练过程,且只对梯度等少量数据进行信息交换。
-
DDP在每次迭代中,每个进程具有自己的optimizer,并独立完成所有的优化步骤,进程内与一般的训练无异。 -
在各进程梯度计算完成之后,各进程需要将梯度进行汇总平均,然后再由
rank=0的进程,将其broadcast到所有进程。之后,各进程用该梯度来独立的更新参数。而DP是梯度汇总到主 GPU,反向传播更新参数,再广播参数给其他的 GPU。 -
DDP中由于各进程中的模型,初始参数一致 (初始时刻进行一次broadcast),而每次用于更新参数的梯度也一致,因此,各进程的模型参数始终保持一致。而在DP中,全程维护一个optimizer,对各 GPU 上梯度进行求和,而在主 GPU 进行参数更新,之后再将模型参数broadcast到其他 GPU。 -
相较于DP,DDP传输的数据量更少,因此速度更快,效率更高。
-
- 每个进程包含独立的解释器和
GIL- 一般使用的 Python 解释器
CPython:是用 C 语言实现 Pyhon,是目前应用最广泛的解释器。全局锁使 Python 在多线程效能上表现不佳,全局解释器锁(Global Interpreter Lock)是 Python 用于同步线程的工具,使得任何时刻仅有一个线程在执行。 - 由于每个进程拥有独立的解释器和
GIL,消除了来自单个 Python 进程中的多个执行线程,模型副本或 GPU 的额外解释器开销和 GIL-thrashing ,因此可以减少解释器和 GIL 使用冲突。这对于严重依赖 Python runtime 的 models 而言,比如说包含 RNN 层或大量小组件的 models 而言,这尤为重要。
- 一般使用的 Python 解释器
- 每个进程对应一个独立的训练过程,且只对梯度等少量数据进行信息交换。
-
DDP的缺点:
- 暂时来说,DDP是采用多进程多线程的方式,并且训练速度较高,他的缺点主要就是,需要修改比较多的代码,比DP的一行代码较为繁琐许多。
PyTorch的主要组成模块
Pytorch的主要组成模块包括那些呢?
- 基本配置:一些常用的函数,GPU配置等等
- 数据读取:通过Dataset+DataLoader的方式完成
- 模型构建:PyTorch中神经网络构造一般是基于nn.Module类的模型来完成的
- 模型初始化:为了利于训练和减少收敛时间,我们需要对模型进行合理的初始化。PyTorch也在torch.nn.init中为我们提供了常用的初始化方法。
- 损失函数:一个模型想要达到很好的效果需要学习,也就是我们常说的训练。一个好的训练离不开优质的负反馈,这里的损失函数就是模型的负反馈
- 训练和评估:我们在完成了模型的训练后,需要在测试集/验证集上完成模型的验证
- PyTorch优化器:优化器是根据网络反向传播的梯度信息来更新网络的参数,以起到降低loss函数计算值,使得模型输出更加接近真实标签
- 可视化(可选)
Dataset和DataLoader的作用是什么,我们如何构建自己的Dataset和DataLoader?
Dataset定义好数据的格式和数据变换形式,DataLoader用iterative的方式不断读入批次数据。
神经网络的一般构造方法?
Module 类是 torch.nn 模块里提供的一个模型构造类,是所有神经网络模块的基类,我们可以继承它来定义我们想要的模型。一般我们会重载 Module 类的 __init__ 函数和 forward 函数。
常见的初始化函数有哪些,我们怎么使用它们?
PyTorch在torch.nn.init中为我们提供了常用的初始化方法
常见的损失函数以及它们的作用?
Pytorch模型的定义
我们可以通过那些方式对模型进行定义?
- 基于nn.Module,我们可以通过Sequential,ModuleList和ModuleDict三种方式定义PyTorch模型
- Sequential适用于快速验证结果,因为已经明确了要用哪些层,直接写一下就好了,不需要同时写__init__和forward;
- ModuleList和ModuleDict在某个完全相同的层需要重复出现多次时,非常方便实现,可以”一行顶多行“;
- 当我们需要之前层的信息的时候,比如 ResNets 中的残差计算,当前层的结果需要和之前层中的结果进行融合,一般使用 ModuleList/ModuleDict 比较方便。
如何利用模型块构建复杂网络?
以U-Net为例子:
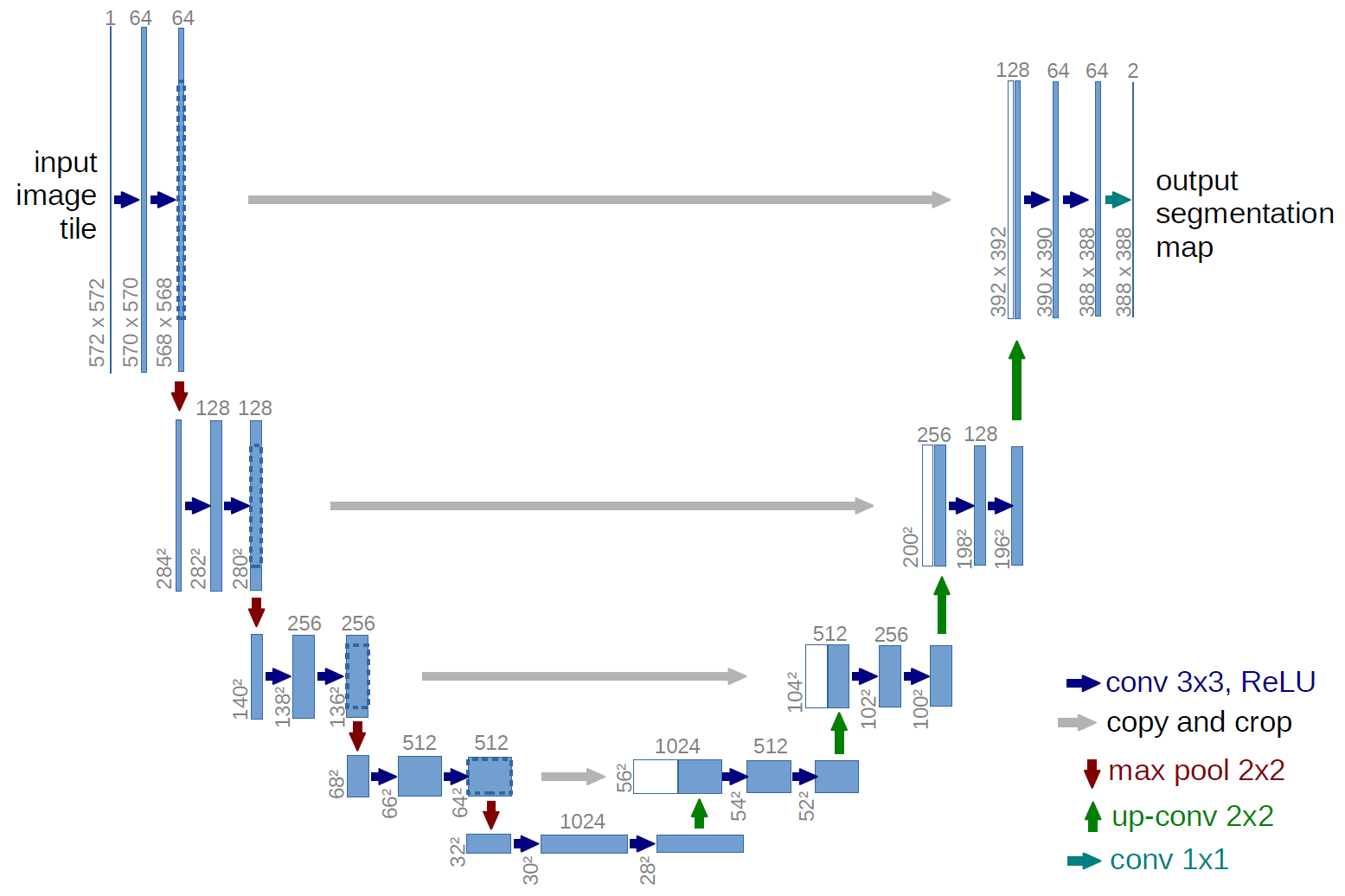
组成U-Net的模型块主要有如下几个部分:
-
每个子块内部的两次卷积(Double Convolution)
-
左侧模型块之间的下采样连接,即最大池化(Max pooling)
-
右侧模型块之间的上采样连接(Up sampling)
-
输出层的处理
这里的基础部件对应上一节分析的四个模型块,根据功能我们将其命名为:DoubleConv, Down, Up, OutConv。下面给出U-Net中模型块的PyTorch 实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
DoubleConv的实现:
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
Down下采样的实现:
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
up上采样的实现:
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=False):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
# if you have padding issues, see
# https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a
# https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
OutConv输出层的处理的实现:
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
最后利用模型块组装U-Net:
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=False):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logits
PyTorch如何修改模型?
如何在已有模型的基础上:
- 修改模型若干层
- 添加额外输入
- 添加额外输出
PyTorch模型保存与读取
PyTorch的模型的存储格式有哪些?
PyTorch存储模型主要采用pkl,pt,pth三种格式。对于PyTorch而言,pt, pth和pkl三种数据格式均支持模型权重和整个模型的存储,因此使用上没有差别。
模型如何存储内容?
一个PyTorch模型主要包含两个部分:模型结构和权重。其中模型是继承nn.Module的类,权重的数据结构是一个字典(key是层名,value是权重向量)。存储也由此分为两种形式:存储整个模型(包括结构和权重),和只存储模型权重。
from torchvision import models
model = models.resnet152(pretrained=True)
save_dir = './resnet152.pth'
# 保存整个模型
torch.save(model, save_dir)
# 保存模型权重
torch.save(model.state_dict, save_dir)
单卡和多卡模型存储的区别?
PyTorch中将模型和数据放到GPU上有两种方式——.cuda()和.to(device)
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0' # 如果是多卡改成类似0,1,2
model = model.cuda() # 单卡
model = torch.nn.DataParallel(model).cuda() # 多卡
多卡并行的模型每层的名称前多了一个“module”
针对单卡/多卡我们如何加载模型?
- 单卡保存+单卡加载
在使用os.envision命令指定使用的GPU后,即可进行模型保存和读取操作。注意这里即便保存和读取时使用的GPU不同也无妨。
import os
import torch
from torchvision import models
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #这里替换成希望使用的GPU编号
model = models.resnet152(pretrained=True)
model.cuda()
save_dir = 'resnet152.pt' #保存路径
# 保存+读取整个模型
torch.save(model, save_dir)
loaded_model = torch.load(save_dir)
loaded_model.cuda()
# 保存+读取模型权重
torch.save(model.state_dict(), save_dir)
loaded_model = models.resnet152() #注意这里需要对模型结构有定义
loaded_model.load_state_dict(torch.load(save_dir))
loaded_model.cuda()
- 单卡保存+多卡加载
这种情况的处理比较简单,读取单卡保存的模型后,使用nn.DataParallel函数进行分布式训练设置即可
import os
import torch
from torchvision import models
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #这里替换成希望使用的GPU编号
model = models.resnet152(pretrained=True)
model.cuda()
# 保存+读取整个模型
torch.save(model, save_dir)
os.environ['CUDA_VISIBLE_DEVICES'] = '1,2' #这里替换成希望使用的GPU编号
loaded_model = torch.load(save_dir)
loaded_model = nn.DataParallel(loaded_model).cuda()
# 保存+读取模型权重
torch.save(model.state_dict(), save_dir)
os.environ['CUDA_VISIBLE_DEVICES'] = '1,2' #这里替换成希望使用的GPU编号
loaded_model = models.resnet152() #注意这里需要对模型结构有定义
loaded_model.load_state_dict(torch.load(save_dir))
loaded_model = nn.DataParallel(loaded_model).cuda()
- 多卡保存+单卡加载
这种情况下的核心问题是:如何去掉权重字典键名中的"module",以保证模型的统一性。
对于加载整个模型,直接提取模型的module属性即可:
import os
import torch
from torchvision import models
os.environ['CUDA_VISIBLE_DEVICES'] = '1,2' #这里替换成希望使用的GPU编号
model = models.resnet152(pretrained=True)
model = nn.DataParallel(model).cuda()
# 保存+读取整个模型
torch.save(model, save_dir)
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #这里替换成希望使用的GPU编号
loaded_model = torch.load(save_dir).module
对于加载模型权重,有以下几种思路: 保存模型时保存模型的module属性对应的权重
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2' #这里替换成希望使用的GPU编号
import torch
from torchvision import models
save_dir = 'resnet152.pth' #保存路径
model = models.resnet152(pretrained=True)
model = nn.DataParallel(model).cuda()
# 保存权重
torch.save(model.module.state_dict(), save_dir)
#这样保存下来的模型参数就和单卡保存的模型参数一样了,可以直接加载。也是比较推荐的一种方法。 去除字典里的module麻烦,往model里添加module简单
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2' #这里替换成希望使用的GPU编号
import torch
from torchvision import models
model = models.resnet152(pretrained=True)
model = nn.DataParallel(model).cuda()
# 保存+读取模型权重
torch.save(model.state_dict(), save_dir)
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #这里替换成希望使用的GPU编号
loaded_model = models.resnet152() #注意这里需要对模型结构有定义
loaded_model.load_state_dict(torch.load(save_dir))
loaded_model = nn.DataParallel(loaded_model).cuda()
loaded_model.state_dict = loaded_dict
遍历字典去除module
from collections import OrderedDict
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #这里替换成希望使用的GPU编号
loaded_dict = torch.load(save_dir)
new_state_dict = OrderedDict()
for k, v in loaded_dict.items():
name = k[7:] # module字段在最前面,从第7个字符开始就可以去掉module
new_state_dict[name] = v #新字典的key值对应的value一一对应
loaded_model = models.resnet152() #注意这里需要对模型结构有定义
loaded_model.state_dict = new_state_dict
loaded_model = loaded_model.cuda()
使用replace操作去除module
loaded_model = models.resnet152()
loaded_dict = torch.load(save_dir)
loaded_model.load_state_dict({k.replace('module.', ''): v for k, v in loaded_dict.items()})
- 多卡保存+多卡加载
由于是模型保存和加载都使用的是多卡,因此不存在模型层名前缀不同的问题。但多卡状态下存在一个device(使用的GPU)匹配的问题,即保存整个模型时会同时保存所使用的GPU id等信息,读取时若这些信息和当前使用的GPU信息不符则可能会报错或者程序不按预定状态运行。具体表现为以下两点:
读取整个模型再使用nn.DataParallel进行分布式训练设置
这种情况很可能会造成保存的整个模型中GPU id和读取环境下设置的GPU id不符,训练时数据所在device和模型所在device不一致而报错。
读取整个模型而不使用nn.DataParallel进行分布式训练设置
这种情况可能不会报错,测试中发现程序会自动使用设备的前n个GPU进行训练(n是保存的模型使用的GPU个数)。此时如果指定的GPU个数少于n,则会报错。在这种情况下,只有保存模型时环境的device id和读取模型时环境的device id一致,程序才会按照预期在指定的GPU上进行分布式训练。
相比之下,读取模型权重,之后再使用nn.DataParallel进行分布式训练设置则没有问题。因此多卡模式下建议使用权重的方式存储和读取模型:
import os
import torch
from torchvision import models
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2' #这里替换成希望使用的GPU编号
model = models.resnet152(pretrained=True)
model = nn.DataParallel(model).cuda()
# 保存+读取模型权重,强烈建议!!
torch.save(model.state_dict(), save_dir)
loaded_model = models.resnet152() #注意这里需要对模型结构有定义
loaded_model.load_state_dict(torch.load(save_dir)))
loaded_model = nn.DataParallel(loaded_model).cuda()
如果只有保存的整个模型,也可以采用提取权重的方式构建新的模型:
# 读取整个模型
loaded_whole_model = torch.load(save_dir)
loaded_model = models.resnet152() #注意这里需要对模型结构有定义
loaded_model.state_dict = loaded_whole_model.state_dict
loaded_model = nn.DataParallel(loaded_model).cuda()
另外,上面所有对于loaded_model修改权重字典的形式都是通过赋值来实现的,在PyTorch中还可以通过"load_state_dict"函数来实现。因此在上面的所有示例中,我们使用了两种实现方式。
loaded_model.load_state_dict(loaded_dict)
如何保存和加载模型的其它参数?
在深度学习项目里,有时候我们不仅仅需要保存模型的权重,还需要保存一些其他的参数,比如训练的epoch数、训练的loss,优化器的参数,动态调整学习策略的参数等等。这些参数可以通过字典的形式保存在一个文件里,然后在读取模型时一起读取。这里我们以下方代码为例:
torch.save({
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
'lr_scheduler': lr_scheduler.state_dict(),
'epoch': epoch,
'args': args,
}, checkpoint_path)
这些参数的读取方式也是类似的:
checkpoint = torch.load(checkpoint_path)
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
lr_scheduler.load_state_dict(checkpoint['lr_scheduler'])
epoch = checkpoint['epoch']
args = checkpoint['args']
总结
本文列举了pytorch初学者常见的问题,大家可以按需求进行查阅,或者对自己的pytorch的基础知识进行测试。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 在 CentOS 7.8 上安装 Node.js
- oracle中imp命令详解
- Unity Shader Early-Z技术
- 通过IService中提供的Lambda方法,简化复杂/动态sql语句的编写
- R语言生物群落(生态)数据统计分析与绘图
- 数字IC后端实现之物理验证Calibre LVS常见错误案例解析
- Fourier transform笔记
- 【Proteus仿真】【51单片机】超声波测距系统
- goland错误:该版本的1%与您运行的windows版本不兼容
- Vue2面试题:说一下什么是路由守卫?