连续语义分割(CSS)24种最新经典方法汇总,包含数据回放、自监督、正则化等5个细分方向
连续语义分割(CSS)是计算机视觉中的一个新兴领域,其基本任务是在某一时刻学习预测特定类别的图像分割,并在随后需要的时候连续增加学习类别的数量,同时保持对已有类别的分割能力。这个过程中需要解决的主要挑战包括灾难性遗忘和语义漂移。
为解决以上问题,我们根据是否需要存储旧数据,将当前的CSS分为基于回放的方法和不依赖旧数据的方法2大类。我这次就从这两类入手,帮同学们整理了24种连续语义分割方法,并且细分了5个小方向,包含数据回放、自监督、正则化等。
每种方法的论文原文以及代码都附上了,另外我还整理一部分连续语义分割通用数据集,需要的同学看文末
基于回放的方法
代表性数据回放
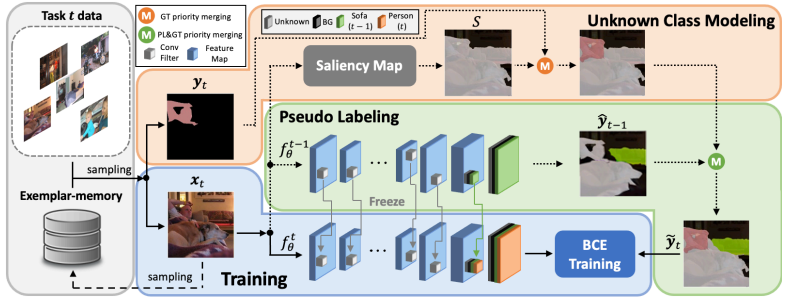
1.Ssul: Semantic segmentation with unknown label for exemplar-based class-incremental learning
基于样例的类增量学习的未知标签语义分割
「方法简述:」论文提出了一个针对类增量语义分割问题的新方法SSUL-M。该方法旨在解决导致灾难性遗忘的关键挑战,包括背景类的语义漂移和多标签预测问题,主要有三个贡献:1) 在背景类中定义未知类以帮助学习未来类;2) 通过冻结主干网络和过去的分类器,克服灾难性遗忘;3) 在CISS中首次利用小型样例内存,提高可塑性和稳定性。实验表明,该方法在标准基准数据集上取得了显著优于最新最先进基线的性能。
2.Continual semantic segmentation with automatic memory sample selection
自动记忆样本选择的连续语义分割
「方法简述:」CSS通过逐步引入新类别来持续改善模型性能,为了缓解灾难性遗忘问题,作者提出了一种新的记忆样本选择机制,自动选择信息丰富的样本进行有效的重放。该方法考虑了全面的因素,包括样本多样性和类别表现等,并通过学习最佳选择策略来最大化验证性能奖励集。在Pascal-VOC 2012和ADE 20K数据集上进行的实验表明,该方法具有最先进的性能,比第二名高出12.54%。

3.Rethinking exemplars for continual semantic segmentation in endoscopy scenes: Entropy-based mini-batch pseudo-replay
4.Improving replay-based continual semantic segmentation with smart data selection
5.Pin the memory: Learning to generalize semantic segmentation
生成式回放
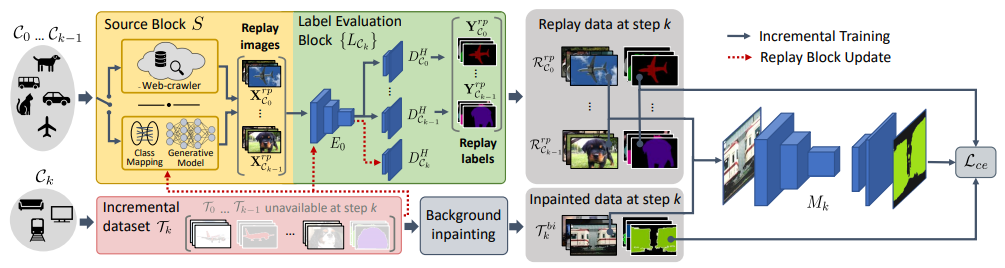
1.Recall: Replay-based continual learning in semantic segmentation
基于回放的连续语义分割方法
「方法简述:」Deep networks在语义分割任务中表现优异,但需要大量数据进行一次性训练。连续学习设置(新类别以增量步骤学习,先前的训练数据不再可用)具有挑战性,因为存在灾难性遗忘现象。现有的方法通常无法处理多个增量步骤或背景类别分布转移的情况。作者提出了一种名为RECALL的方法,通过重新创建旧类别的数据和使用网络爬行数据来获取重放数据,解决了这些问题。
2.Prototype-guided continual adaptation for class-incremental unsupervised domain adaptation
类增量无监督域适应的原型引导连续适应
「方法简述:」本文研究了一个新问题:类增量无监督域适应(CI-UDA),即源域包含所有类别,但目标域中的类别是顺序增加的。由于源和目标标签集不一致,以及对之前知识的遗忘,该问题具有挑战性。为此,作者提出了一种新的ProCA方法,包括标签原型识别和基于原型的对齐和回放。通过这两种策略,ProCA能够有效地将源模型适应于类增量无标签的目标域。

3.Alife: Adaptive logit regularizer and feature replay for incremental semantic segmentation
4.Diffusepast: Diffusion-based generative replay for class incremental semantic segmentation
5.Dynamic prototype convolution network for few-shot semantic segmentation
不依赖旧数据的方法
基于自监督
1.Continual semantic segmentation via repulsion-attraction of sparse and disentangled latent representations
通过稀疏和松散的潜在表示的排斥-吸引实现连续语义分割
「方法简述:」论文研究了在语义分割中进行类别增量连续学习的问题,即在不保留先前训练数据的情况下,随时间提供新的类别。所提出的连续学习方案通过整形潜在空间来减少遗忘并提高对新类别的识别。该方法包括三个新颖组件:原型匹配、特征稀疏化和对比学习。这些组件可以很容易地结合到现有技术中。实验结果表明,该方法在Pascal VOC2012和ADE20K数据集上非常有效,比现有方法表现更好。

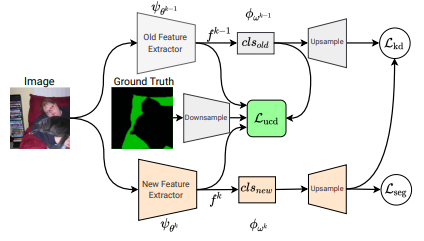
2.Uncertainty-aware contrastive distillation for incremental semantic segmentation
用于增量语义分割的不确定性感知对比蒸馏方法
「方法简述:」论文介绍了一个解决深度学习中灾难性遗忘问题的新方法,称为不确定性感知对比蒸馏。该方法通过引入新的蒸馏损失,强制相同类别的像素特征相似,并使不同类别的像素特征分离。此外,新模型的特性与前一个增量步骤中学到的冻结模型的特性进行对比,以缓解灾难性遗忘。实验表明,该方法可以提高在增量语义分割基准上的性能。
3.Sats: Self-attention transfer for continual semantic segmentation
4.Prototype-based Incremental Few-Shot Semantic Segmentation
5.A contrastive distillation approach for incremental semantic segmentation in aerial images
基于正则化
1.Modeling the background for incremental learning in semantic segmentation
语义分割中增量学习的背景建模
「方法简述:」论文针对语义分割中的灾难性遗忘问题提出了一种新的基于蒸馏的方法。该方法考虑了背景类的特殊性质,通过显式地考虑语义分布的转移来提高增量学习的效果。同时,作者还提出了一种初始化分类器参数的策略,以防止对背景类的有偏预测。在Pascal-VOC 2012和ADE20K数据集上的实验表明,该方法比现有的增量学习方法表现更好。

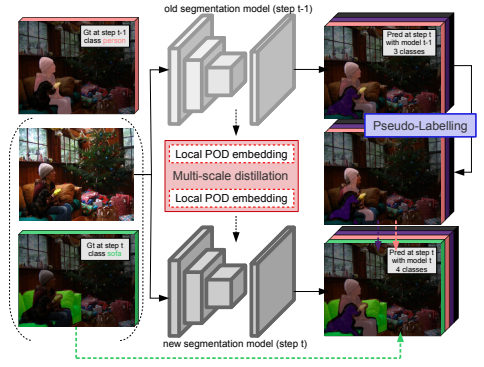
2.Plop: Learning without forgetting for continual semantic segmentation
用于连续语义分割的无遗忘学习
「方法简述:」本文提出了一种名为Local POD的多尺度池化蒸馏方案,用于解决语义分割中的连续学习问题。该方法通过保留特征层面上的长范围和短范围空间关系来防止灾难性遗忘。此外,作者还设计了一种基于熵的背景伪标签生成方法,以处理背景转移并避免旧类别的灾难性遗忘。该方法被称为PLOP,在现有的CSS场景中以及新提出的具有挑战性的基准测试中表现出色,优于现有的最佳方法。
3.Representation compensation networks for continual semantic segmentation
4.Inherit with distillation and evolve with contrast: Exploring class incremental semantic segmentation without exemplar memory
5.Advancing incremental few-shot semantic segmentation via semantic-guided relation alignment and adaptation
基于动态结构
1.Decomposed knowledge distillation for class-incremental semantic segmentation
分解知识蒸馏用于类增量语义分割
「方法简述:」论文提出了一种名为分解的知识蒸馏(DKD)的框架,用于类增量语义分割。该方法通过将分类器的logit分解为两个项来减轻遗忘问题,并有效地学习新类别。该框架还引入了一种新颖的初始化方法,用于训练新分类器以识别新类别。此外,该方法使用辅助分类器将负面样本知识逐步转移到分类器中,以解决新类别数量不足的问题。在标准CISS基准测试上的实验结果表明,该方法非常有效。

2.Attribution-aware weight transfer: A warm-start initialization for class-incremental semantic segmentation
3.Dynamic extension nets for few-shot semantic segmentation
4.Deep model reassembly
通用数据集
1.The pascal visual object classes challenge: A retrospective
PASCAL视觉对象类挑战赛
「简述:」Pascal视觉对象类(VOC)挑战赛是一个包括公开可用的图像数据集、真实标注和标准化评估软件的比赛和研讨会。挑战赛有五个方面:分类、检测、分割、动作分类和人物布局。本文回顾了2008年至2012年的挑战赛,并介绍了几种新颖的评估方法来分析提交算法在VOC数据集上的性能。

2.Scene parsing through ade20k dataset
通过ADE20K数据集进行场景解析
「简述:」本文介绍了一个名为ADE20K的图像数据集,该数据集包含各种场景、物体和物体部分的详细注释。基于ADE20K数据集,作者构建了一个包含150个物体和物体部分类别的场景解析基准测试,并评估了几种分割基线模型。作者提出了一种名为级联分割模块的新网络设计,用于将场景解析为物体、物体部分和物体部分。进一步展示了训练好的场景解析网络可以应用于图像内容去除和场景合成等应用。

3.Playing for data: Ground truth from computer games
4.The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes
5.The cityscapes dataset for semantic urban scene understanding
6.Semantickitti: A dataset for semantic scene understanding of lidar sequences
7.Isprs test project on urban classification and 3d building reconstruction
8.Multimodal remote sensing benchmark datasets for land cover classification with a shared and specific feature learning model
9.Mcanet: A joint semantic segmentation framework of optical and sar images for land use classification
关注下方《学姐带你玩AI》🚀🚀🚀
回复“连续语义分割”获取论文+代码+数据集
码字不易,欢迎大家点赞评论收藏
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python之归并排序
- JavaWeb——新闻管理系统(Jsp+Servlet)之jsp新闻新增
- java通用实现List<自定义对象>中指定字段和指定排序方式
- 【以题代复习】计算机网络 第五章
- NOIP2003提高组T4:传染病控制
- (c语言)求两个数二进制中不同位的个数
- 网神SecGate 3600防火墙app_av_import_save任意文件上传漏洞
- 爬虫之牛刀小试(三):爬取中国天气网全国天气
- 【扩散模型】9、Imagen | 借用语言模型的能力来实现文生图(NIPS2022 Oral)
- 2023最新版JavaSE教程——第14天:数据结构与集合源码详解