SHELL循环与结构化命令应用实战
1.?for?循环
1.1.?列表for循环
- 语法:
for variable in list # 每一次循环,依次把列表 list中的一个值赋给循环变量
do # 循环体开始的标志
commands # 循环变量每取一次值,循环体就执行一遍
done # 循环结束的标志,返回循环顶部- 说明:
- 列表 list可以是命令替换、变量名替换、字符串和文件名列表 ( 可包含通配符 ),每个列表项以空格间隔;
- for循环执行的次数取决于列表 list 中单词的个数;
- 可以省略 in list,省略时相当于 in "$@" 。
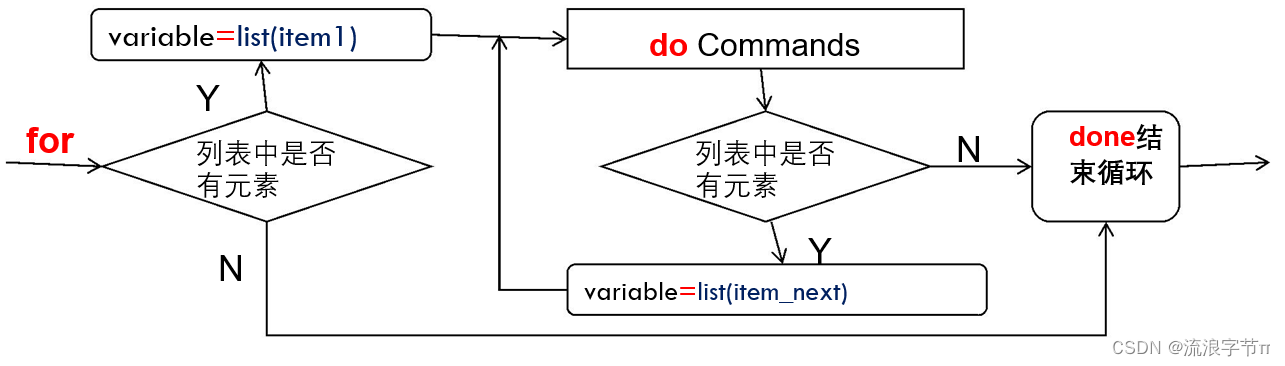
1.2.?列表for循环流程
- 首先将 list 的 item1 赋给 variable;
- 执行do和done之间的 commands;
- 然后再将 list 的 item2 赋给 variable;
- 执行do和done之间的 commands;
- 如此循环,直到 list 中的所有 item 值都已经用完。
1.3.?不带列表for循环
不带列表的 for 循环执行时由用户指定参数和参数的个数,下面给出了不带列表的for循环的基本格式:
for variable
do
command
command
…
done其中 do 和 done 之间的命令称为循环体,shell会自动的将命令行键入的所有参数依次组织成列表,每次将一个命令行键入的参数显示给用户,直至所有的命令行中的参数都显示给用户。
- For Example
#!/bin/bash
# filename: for_nolist.sh
# 使用位置参数变量 $@ 作为 WordList, in $@ 可以省略
i=1
for day [ in $@ ] ; do
echo -n "Positional parameter $((i++)): $day "
case $day in
[Mm]on|[Tt]ue|[Ww]ed|[Tt]hu|[Ff]ri)
echo " (weekday)" ;;
[Ss]at|[Ss]un)
echo " (WEEKEND)" ;;
*) echo " (Invalid weekday)" ;;
esac
done# 执行
$ ./for_nolist.sh Mon Tue wed Thu Fri sat Sun lundi2. while 循环语句
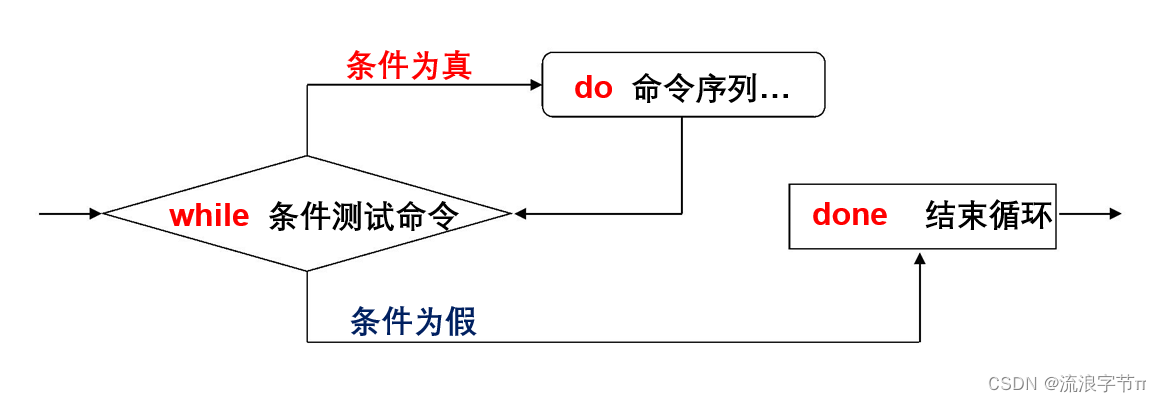
2.1. 语法结构
while expr # 执行 expr
do # 若 expr 的退出状态为0,进入循环,否则退出while
commands # 循环体
done # 循环结束标志,返回循环顶部break [n]- 用于强行退出当前循环;
- 如果是嵌套循环,则 break命令后面可以跟一数字 n,表示退出第 n 重循环(最里面的为第一重循环)。
continue [n]- 用于忽略本次循环的剩余部分,回到循环的顶部,继续下一次循环;
- 如果是嵌套循环,continue命令后面也可跟一数字 n ,表示回到第 n 重循环的顶部。
2.2. 执行过程
先执行 expr,如果其退出状态为 0,就执行循环体。执行到关键字 done 后,回到循环的顶部,while 命令再次检查 expr 的退出状态。以此类推,循环将一直继续下去,直到 expr的退出状态非 0为止。
 ?2.3.?while?循环注意点
?2.3.?while?循环注意点
为了避免死循环,必须保证在循环体中包含循环出口条件,即存在expression的退出状态为非0的情况。
3.?until 循环语句
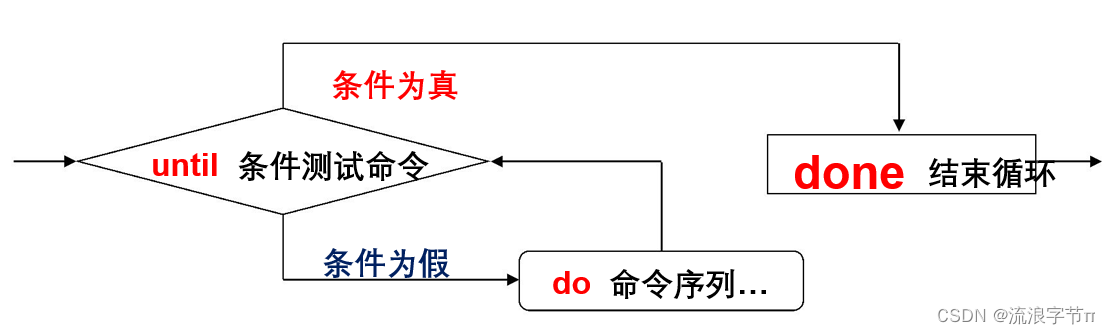
3.1.?语法结构
until expr # 执行 expr
do # 若expr的退出状态非0,进入循环,否则退出until
commands # 循环体
done # 循环结束标志,返回循环顶部3.2. 执行过程
在执行while循环时,只要是expr的退出状态为0将一直执行循环体。until命令和while命令类似,但区别是until循环中expr的退出状态不为0时循环体将一直执行下去,直到退出状态为0时退出循环。
4. AWK的用法
4.1. AWK功能介绍
awk是一种可以处理数据、产生格式化报表的语言,功能相当强大。awk的工作方式是读取数据文件,将每一行数据视为一条记录(record),每笔记录以字段分隔符分成若干字段,然后输出各个字段的值。
awk对每一条记录,都会套用一个“条件类型{操作动作}”,如果该行符合样式,就执行指定的操作。条件类型或操作动作之一,可以省略。如果只有条件类型,表示要显示符合条件的数据行;如果只有操作动作,表示对每一数据行都执行该动作操作。
4.2.?awk作用格式
- awk “条件类型” 文件:把符合条件类型的数据行显示出来;
- awk '{操作动作}' 文件:对每一行都执行{}中的操作;
- awk '条件类型{操作动作}' 文件:对符合条件类型的数据行,执行{}中的操作;
- awk '条件类型1{操作动作1} 条件类型2{操作动作2} ...' 文件。
4.3.?awk处理流程
- 读入第一行,并将第一行的数据填入 $0, $1, $2.... 等变量当中;
- 依据 "条件类型" 的限制,判断是否需要进行后面的 "动作";
- 做完所有的动作与条件类型;
- 若还有后续的『行』的数据,则重复上面1~3的步骤,直到所有的数据都读完为止。
4.4.?AWK内部变量
| 变量名称 | 变量说明 |
| NF | 每一行 ($0) 拥有的栏位(分割域)总数 |
| NR | 目前 awk 所处理的是第几行的数据 |
| FS | 目前的分隔字节,默认是空白键 |
| $number | 表示记录的字段。比如,$1表示第1个字段,$2表示第2个字段,如此类推。而$0比较特殊,表示整个当前行 |
5.?SED介绍与基础用法
sed 是一种非交互式的流编辑器,可动态编辑文件。所谓非交互式是说,sed 和传统的文本编辑器不同,并非和使用者直接互动,sed处理的对象是文件的数据流。sed 的工作模式是,比对每一数据行,若符合样式,就执行指定的操作。
5.1. 基础用法
sed [-nefr] [动作]
选项与参数:
-n :使用安静(silent)模式。在一般 sed的用法中,所有来自STDIN的数据一般都会被列出到屏幕上。但如
果加上-n参数后,则只有经过sed特殊处理的那一行(或者动作)才会被列出来。
-e :直接在命令列模式上进行sed的动作编辑;
-f :直接将sed的动作写在一个文件内,-f filename则可以运行filename内的sed动作;
-r :sed的动作支持的是扩展型正则表示法的语法。(默认是基础正则表示法语法)
-i :直接修改读取的文件内容,而不是由屏幕输出。
[n1[,n2]] function
n1, n2 :不见得会存在,一般代表选择进行动作的行数,举例来说,如果我的动作是需要在10到20行之间进行的,则10,20 [动作行为]
a:新增,a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)
c:取代,c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行
d:删除,因为是删除啊,所以 d 后面通常不接
i:插入,i的后面可以接字串,而这些字串会在新的一行出现(目前的上一行)
p:打印,将某个选择的数据打印出来。通常p会与参数sed -n一起运行
s:取代,可以直接进行替换!通常这个s的动作可以搭配正则表示法!例如 1,20s/old/new/g
5.2. SED应用举例
sed '1,4d' test.txt #把第 1 到第 4 行数据删除,剩下的显示出来。d是sed的删除命令
sed '/Test/d' test.txt #把含有 Test 的行删除,剩下的显示出来。其中,/ / 代表搜索
sed '/Test/!d' test.txt #把不含有 La 的行删除,剩下的显示出来。这里的!是否定的意思
sed '/^$/d' test.txt #删除 test.txt 的空白行。^ 表开头,$ 表尾部,这两者之间没有任何字符,代表该行是一空白行
sed 's/^...//' test.txt #把每一行开头的3个字符删除
sed 's/...$//' test.txt #把每一行末尾3个字符删除本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- uniapp中如何使用image图片
- 安装虚拟机&在虚拟机里面安装WindowsServer2012与步骤
- 韩国LG集团在 CES2024 消费电子展上发布的的无线透明OLED屏幕
- Docker数据持久化与数据共享
- python------Pymysql模块
- 最新ChatGPT源码,AI绘画Midjourney绘画系统,GPT-4V识图理解+GPT语音对话+ChatFile文档对话总结+DALL-E3文生图+自定义知识库一站式解决方案
- 一条命令去除PVE8烦人的无有效订阅提示
- 新时代研究生学术英语综合教程2unit6课文中英文翻译
- 创建审批流程极简培训教程
- 用go语言删除重复文件