【C++笔记】C++11一些重要的新特性
一、列表初始化
C++11第一个比较好用的特性就是”列表初始化",它可以大大的节省我们初始化对象的时间(特别是对象数组),虽然有些地方用起来有点儿奇怪,但是总的来说利大于弊。
1、列表初始化的使用方法
我们在使用C语言或者在C++11之前,可以使用“列表初始化"来对数组数组或结构体进行初始化:

但如果想让我们的vector对象有人这样初始化,就不支持了,因为我的vs已经是C++11的啦,所以我就在洛谷的编译器上来演示:
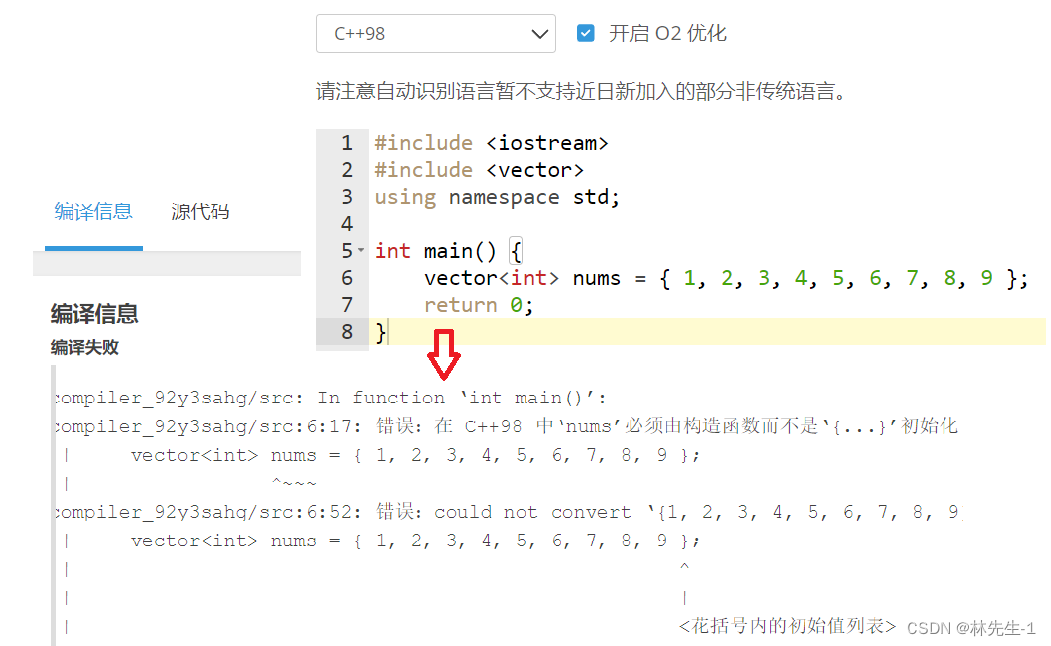
而C++11之后对列表初始化的使用范围进行了扩大,其他的其他的地方也可以用,最典型的就是vector:

直接在列表里面写,连设置大小都不用了。
不仅可以向上面一样使用,就连vector套vector的场景也可以这样使用:
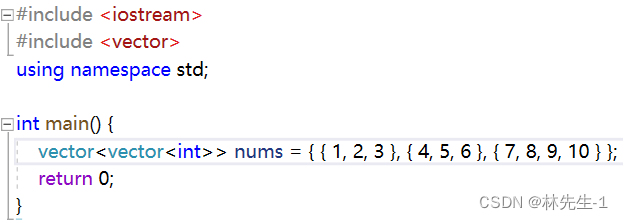
而且每个内部的vector的大小也是可以不一样的,简直不要太方便。
支持这个特性,其实在我们做一些接口型oj题也有很大的帮助,例如我们在做”矩阵"相关的题目时候,有一些测试用例的规模非常大,我们想进行调试就可以直接复制粘贴到我们自己的编译器上:

想想如果这是以前的C++98,我们可能还要一直resize,一直push_back,如果每个内部的vector的长度还不一样,那就更麻烦了。
不仅如此,就连我们在初始化一些键值对结构的容器时,也可以这样初始化:

其实C++是将这个”列表初始化"给统一了,即一切都可用列表初始化,包括我们以前的内置类型:

虽然这的确有点奇怪,但是并不影响我们使用,初始化内置类型的时候我们就按以前的方法初始化就行了。
更奇怪的是它还可以将赋值符号给省略掉:

其实我感觉这个实在太奇怪的话,不管就行了,喜欢用哪种就用那种,看得懂就行。
2、列表初始化的原理
那这个“列表初始化”到底是怎么实现的呢?
其实并不复杂,它的底层也还是调用构造函数,我么们可以用一个自定义类型来演示一下:
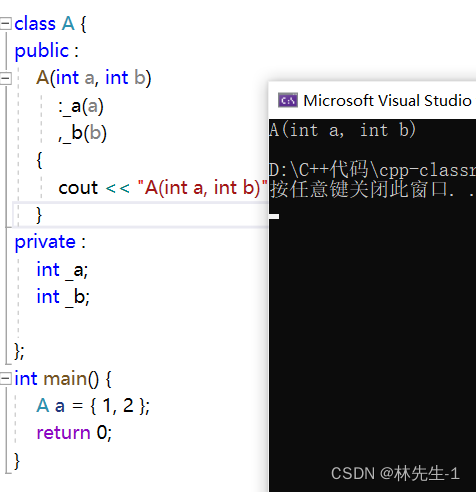
这里的本质其实是一个隐式类型转换,就像上面的示例中其实编译器是先将{ 1, 2 }构造成一个临时对象,再用这个临时对象去构造a,我们可以用一个方法来验证它确实是产生了临时对象:

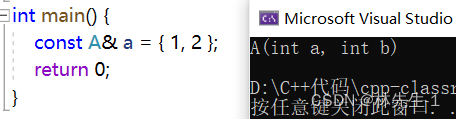
如上,如果这个a是一个引用的话就会报错,原因是临时对象具有常性,引用不能指向,属于是权限的放大。
如果再加上一个const就没事了:
但是,这好像也还没说清楚啊,这个临时对象是什么对象呢?又是怎么又能构造这个A呢?
先说为什么这里的这个临时对象可以构造别的对象,这里的本质其实是一个单参数构造函数的隐式类型转换。
为什么,这我们就得要去看一看容器的构造函数了,就拿我们常用的vector来说,我们会发现它的构造函数里面多了一个我们看不懂的构造函数:
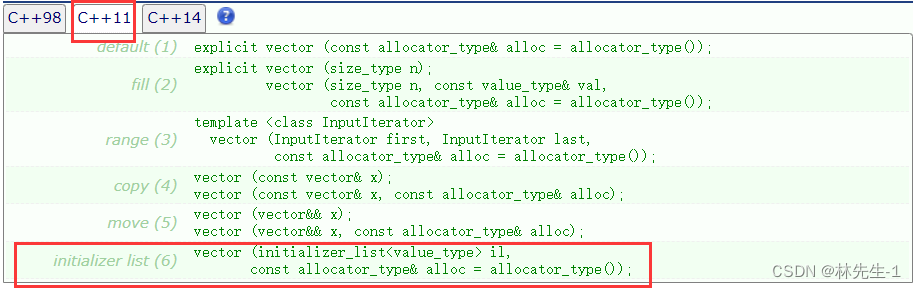
我们会看到在众多的构造函数里面有一个只有一个initializer_list参数的单参数构造函数,那我们现在就可以推断出,那个“临时对象”其实就是一个initializer_list对象!编译器在使用列表初始化的时候,其实是先去构造了一个initializer_list的临时对象,在根据单参数构造函数支持隐式类型转换的特性,去构造了其他的类!
不信的话,我们可以多看几个类,看看它们是否都有这样一个构造函数:
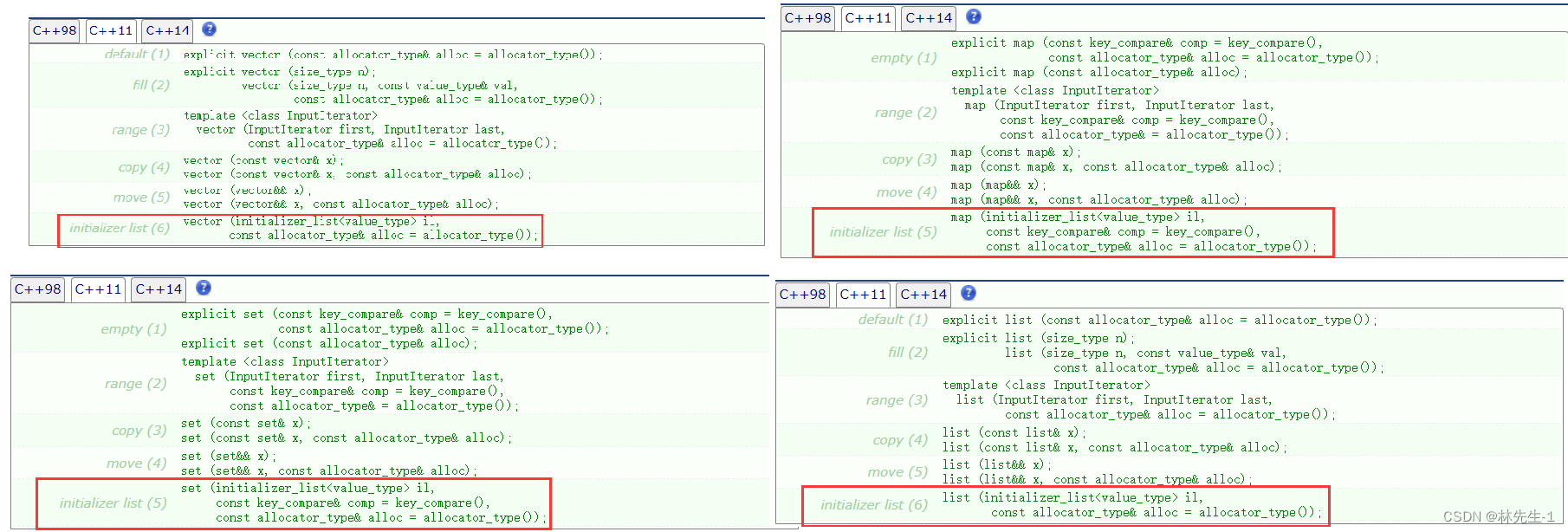
所以是因为C++11为每个容器都提供了这样一个构造函数,才使得所有的容器可以支持列表初始化。
其实我们只要是在列表中写几个数字,编译器都会将它识别成initializer_lis:

但也并不是所有的列表都会被识别成,initializer_lis,在匹配的时候,编译器其实还是遵循了“最匹配原则”,就比如上面写的自定义类型就会被识别成构造函数:

所以这些地方还是比较容易混,大家还是要小心一点。
至于这个initializer_lis的底层是怎么实现的,我们其实并不用关心,只需要懂得它是怎么可以转化成其他类的就行了。
二、右值引用与移动语义
1、左值引用与右值引用
左值和右值其实在C语言阶段就已经有概念了,这两个概念如果要细分的话就又得讲一大篇了,如果实在感兴趣的话可以看一看我以前写的一篇【C语言深入】细聊C语言中的“左值”和“右值”,简单总结的话就i是,左值是可以标识一个“空间”的,他是可以取地址的,而右值只是表示一个“字面量”或一个常量,它是不可以取地址的。左值是可以出现在赋值符号的左边的,右值是不能出现在赋值符号的左边的。
而左值引用和右值引用顾名思义就是,引用左值和右值的引用变量。
左值引用我们很熟悉,我们以前使用的引用都是左值引用,被引用的对象可以通过引用访问也可以通过引用修改,而且本体和引用是同步的:

而我们以前使用的左值引用是不能直接引用右值的:
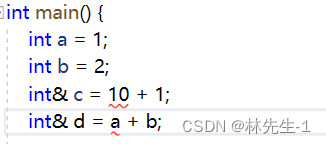
但是加上在前面加上一个const就可以了:

主要原因是右值是不能被修改的,如果左值引用直接引用就属于权限的放大,所以要加上const修饰。
而C++11之后出了一个新的引用——右值引用,它可以引用右值,它的语法其实很简单,就是比右值引用多了一个&:

同样的右值引用也不能引用左值:

但是右值引用可以给move后的左值取别名:

这个move其实就是让左值具有右值的属性,这个move后面还需要细讲。
2、为什么要有右值引用呢?
以前我们使用的左值引用其实大部分的场景都已经解决了,但是还有一个场景是左值引用无能为力的。
有些场景下我们要某个函数返回一个对象,但是我们都知道局部对象出了作用域就销毁了,所以如果是局部对象的话我们就不能使用左值引用返回,得传值返回,但传值返回又会发生临时拷贝,如果对象较大的话效率就低了。
那有一种方法就是在函数中new一个对象然后用指针返回:
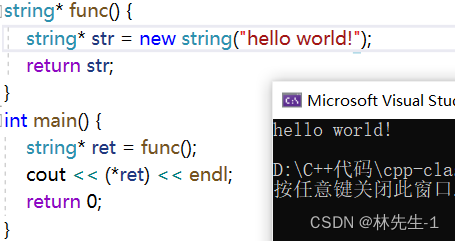
但这就会有一个风险,就是我们可能会忘了释放,这就造成内存泄漏问题了。
就是因为这样的场景,左值引用没法解决,就引出了右值引用,而右值引用又要结合"移动构造"和“移动赋值"来解决这里的问题。
三、移动构造与移动赋值
1、右值引用的分类
C++又将右值分为了"纯右值"和"将亡值",纯右值就是我们平时使用的常量和字面量,而将亡值则是快要被销毁的右值。
例如下面这个例子中,我们使用传值返回的方式,那这个str就是一个将亡值:

因为函数一返回它就销毁了,而实际返回的是它的一份拷贝,即临时对象。
而这个将亡值如果再要继续分析的话,我们会发现其实内置类型是没有将亡值的概念的,这是因为内置类型并没有额外的资源可被销毁,也就是不能被销毁。它们栈帧被回收时自动就会被回收,所以我们其实并不用管他们的销毁问题。
而倒是一些自定义类型,例如string,它们还额外的存储着一些在堆上开辟的资源。这些资源与栈帧没有关系,所以就算栈帧被回收了也不会自动被释放。
所以往细的讲,纯右值就是那些内置类型的右值,将亡值就是那些快要被销毁的自定义类型。
2、移动构造
而移动构造就是为了解决将亡值产生的,它所要做的就是将将亡值中的额外资源”转移",因为将亡值内的额外资源是有价值的,因为我们以前在做传值返回的时候其实要做的是深拷贝,而深拷贝主要还是要拷贝将亡值中的额外资源,至于将亡值中的内置类型是没有价值的。
下面用一个简单的例子来演示一个,如果没有移构造,下面的逻辑将会是怎样的:
class A {
public :
// 默认构造
A(int a = 0, const char* str = "")
:_a(a)
{
_str = new char[strlen(str) + 1];
strcpy(_str, str);
}
// 拷贝构造
A(const A& _A)
:_str(nullptr)
,_a(_A._a)
{
cout << "深拷贝:A(const A& _A) " << endl;
_str = new char[strlen(_A._str) + 1];
strcpy(_str, _A._str);
}
// 赋值重载
A& operator=(const A& _A) {
cout << "深拷贝:A& operator=(const A& _A)" << endl;
if (this != &_A) {
char* temp = new char[strlen(_A._str) + 1];
strcpy(temp, _A._str);
delete[] _str;
_str = temp;
_a = _A._a;
}
return *this;
}
private :
int _a;
char* _str;
};
A func1() {
A a(1, "hello");
return a;
}
int main() {
A ret;
ret = func1();
return 0;
}运行结果:
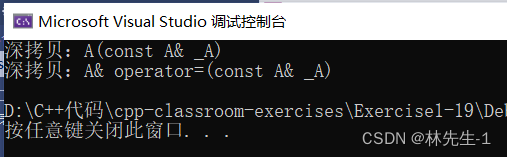
如果没有移动构造,这里就会进行两次深拷贝,一次是fun1函数返回时深拷贝临时对象,一次是赋值时的深拷贝。
如果这里是移动构造的话,就会省去这些繁琐的拷贝了。
那移动构造该怎么写呢?
移动构造其实要做的就是将将亡值的资源进行转移,那我们可以写一个右值引用版本的拷贝构造,将传过来的对象识别成将亡值,然后再对资源进行转移。同理移动拷贝也是如此:

同时为了验证,他们移动的是同一个对象,我们也可以加上一些打印输出,在构造函数中也需要打印一下:

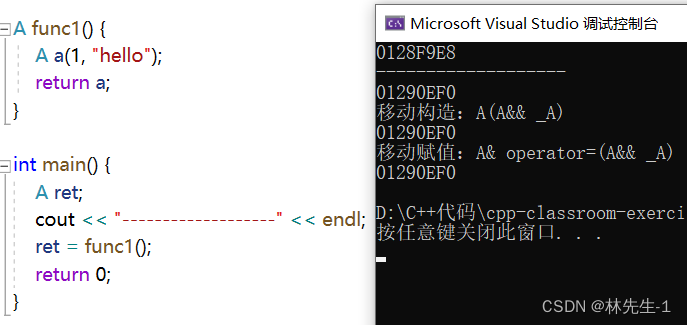
从结果中可以看出,出了第一个创建的ret对象之外,后面所转移的对象里面的_str都是同一份资源,这就很大的节省了我们拷贝的开销。
其实在C++11以后,各种容器增加了移动构造与移动赋值,这样我们就再也不怕传值返回了。
3、聊一下move
move的功能就是让一个左值具有右值的属性,比如下面这个例子:
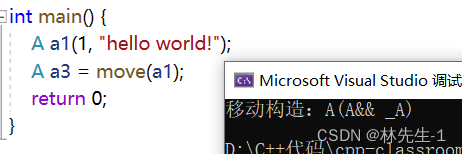
如果没有move(a1)那a1本身是一个左值,他应该匹配的是左值版本的拷贝构造,而如果move之后,a1就具有了右值属性,那它就会去匹配移动构造。
但是对于一个左值我们也不能随便move:
就拿上面的例子来说,我们如果打开监控就会发现,原来的a1的资源变空了:
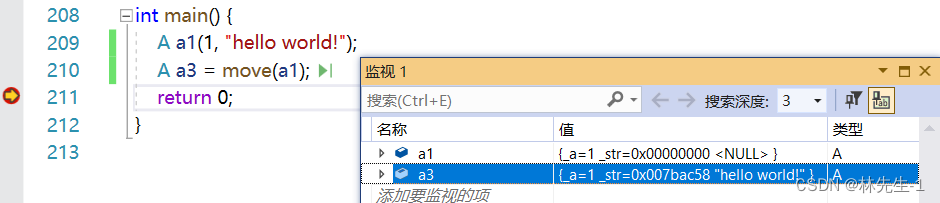
这是因为我们move之后,编译器就会将a1识别成将亡值,但是a1本身并没有”将亡",这就导致a1丢失了它本来的数据。
所以我们在使用move的时候也需要谨慎一些。
有一点需要注意的是move是左值具有右值属性其实指的是mover的返回值,而对于左值对象,它的属性其实并没有改变,例如:
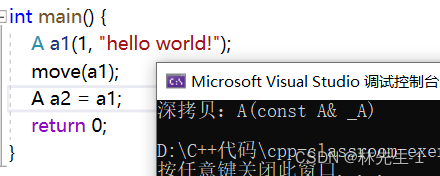
这里调用的还是拷贝构造,这说明a1的属性其实还是左值。
一个奇怪的现象:
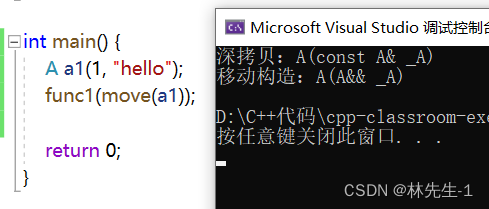
上面的这个场景,如果用我们之前的理解,这里的拷贝应该调的都是移动拷贝,但是为什么又会混进来一个深拷贝呢?
这是因为:一个右值被右值引用引用以后这个引用的属性是左值
所以上面的逻辑应该是这样的:
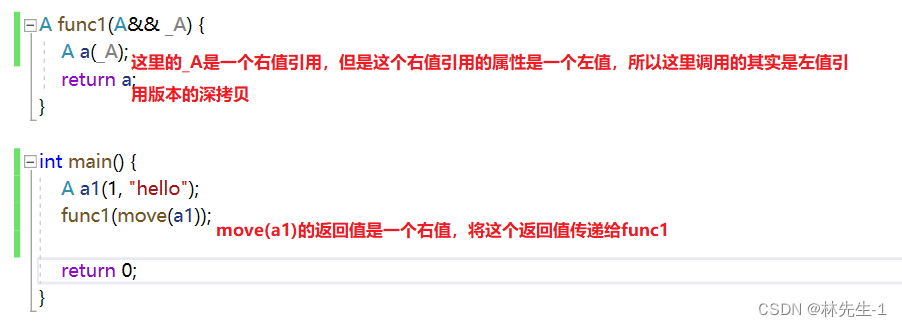
这里确实很绕,但是如果不是这样的话,前面的逻辑就说不清了。
例如我们前面实现的移动构造:

这里要执行一个交换,而交换也属于修改操作,实则是对对象做修改,如果这个引用对象的属性是右值的话不是就不能修改了吗?所以这里要支持修改就只有一种解释,那就是这个引用对象的属性是左值!
所以想要解决上面的问题,我们还需要在进行一次move:
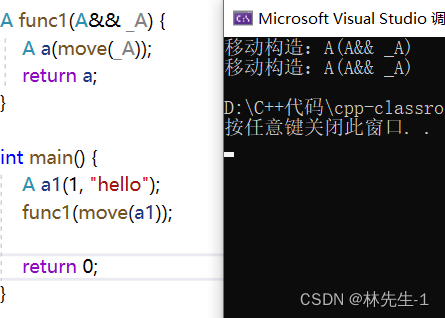
同理的如果有多层函数,如果当前层的函数的参数是一个右值引用,如果想将这个参数传到下一层并匹配上右值引用版本,也需要对当前层的参数进行move操作,但凡有一层没有move都会出问题。
四、lambda表达式
1、lambda表达式的用法和好处
在C++98中,如果们想要丢一个数组进行排序可以使用sort函数,sort函数默认是升序排序,如果想要实现降序排序,可以传入一个greater:
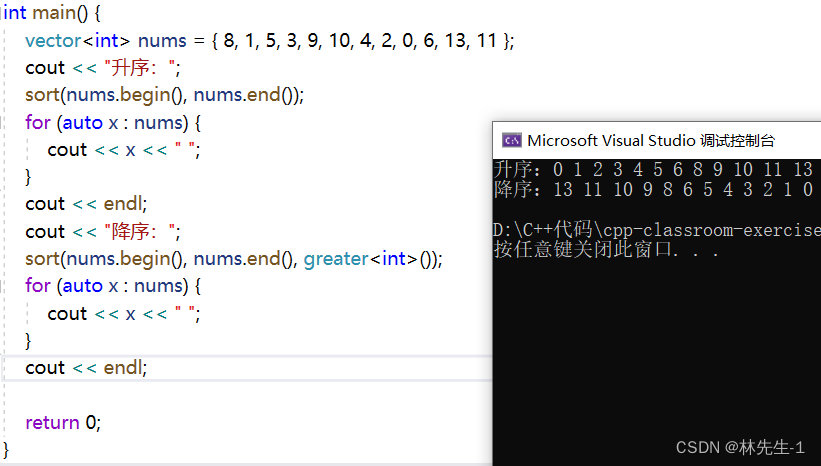
而这个greater其实是C++内置的一个仿函数,它可以支持C++中各种内置类型和库中的自定义类型的比较。
但如果是我们自己写的自定义类型它就比较不了了,如果我们想要让自己写的自定义类型支持比较,就得我们自己写仿函数或者重载一个运算符,而且还都只能在外部写。
但是这毕竟还是有点儿麻烦,如果有些场景的比较标准不同,那就更麻烦了,例如我们现在有这样一个日期类:
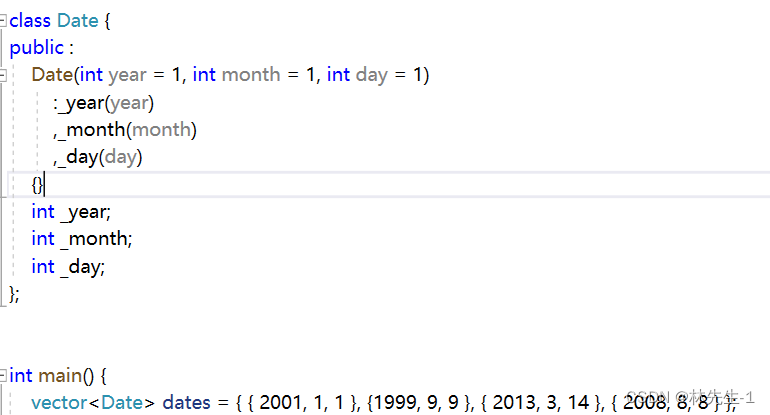
假设我们现在有这样一个日期类,而我们有一个日期类数组,我们想让这个数组一会儿按年排序来分析,一会儿按月排序来分析,一会儿又按日排序来分析。
这如果使用我们以前的仿函数来解决,那我们就要写三个仿函数,很麻烦。
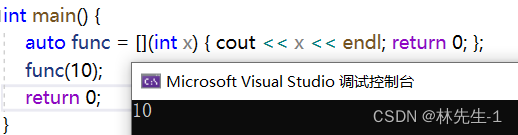
而有了lambda表达式之后就可以轻松解决
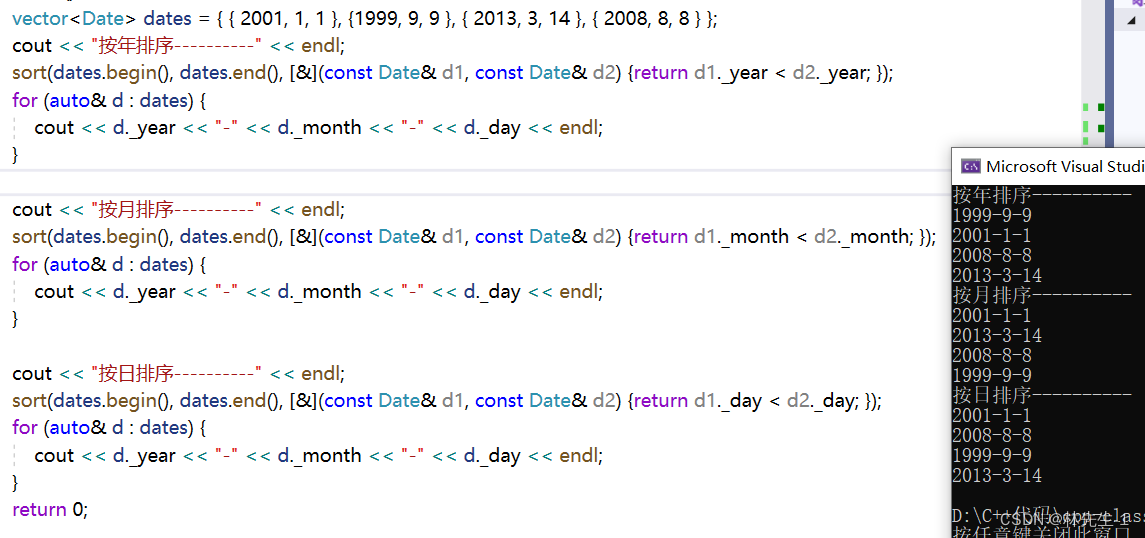
这样是不是我们想要怎样排序就怎样排序了,而且也不用再到外部去写了,直接在sort内写。
我们先来看看lambda表达式怎么用、有什么好处,后面再来讲解它的原理和语法。
2、lambda表达式的语法
lambda表达式的语法大致如下:
[capture-list] (parameters) mutable -> return-type { statement }
[capture-list]:捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。
(parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略
mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)。
->returntype:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导,这个大多数情况下可以不写。
{statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
?
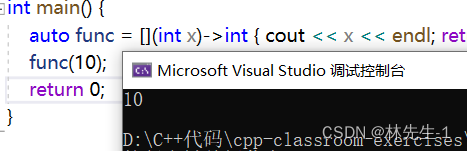
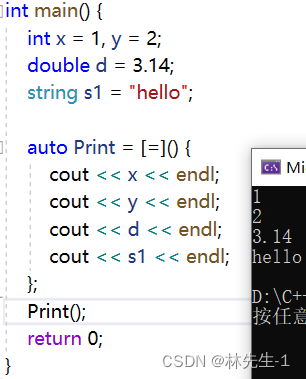
[var] :表示值传递方式捕捉变量 var[=] :表示值传递方式捕获所有父作用域中的变量 ( 包括 this)[&var] :表示引用传递捕捉变量 var[&] :表示引用传递捕捉所有父作用域中的变量 ( 包括 this)[this] :表示值传递方式捕捉当前的 this 指针

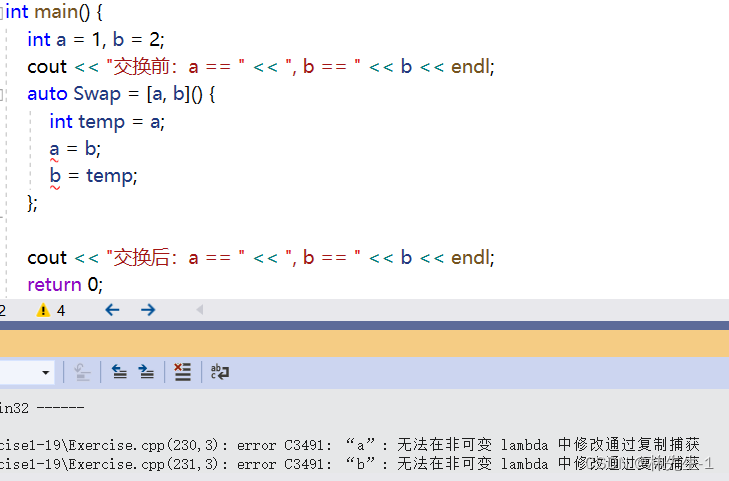
?但是加上了mutalbe也并不能达到交换的目的,这是因为被传值捕捉过来的变量已经变成了lambda对象的成员变量,成员变量的修改和外部没有关系。
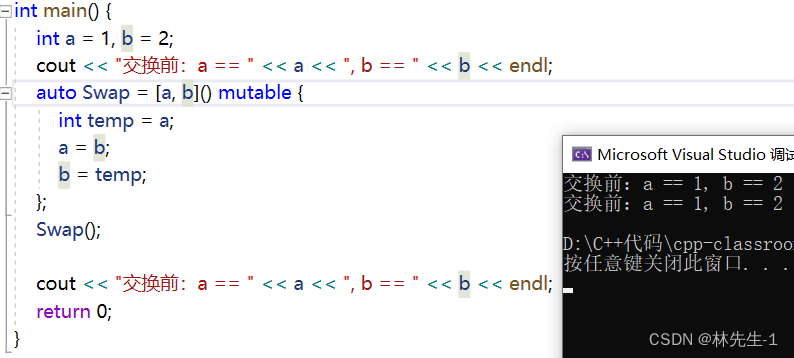
这时候就要用到第三个[&val]引用捕捉了:
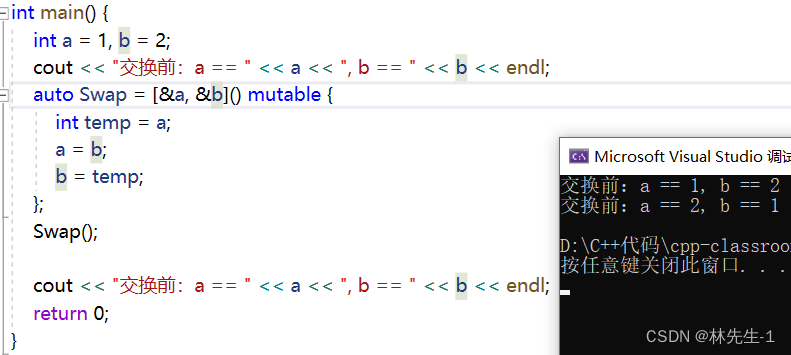
当然这里不加mutable也是可以的:
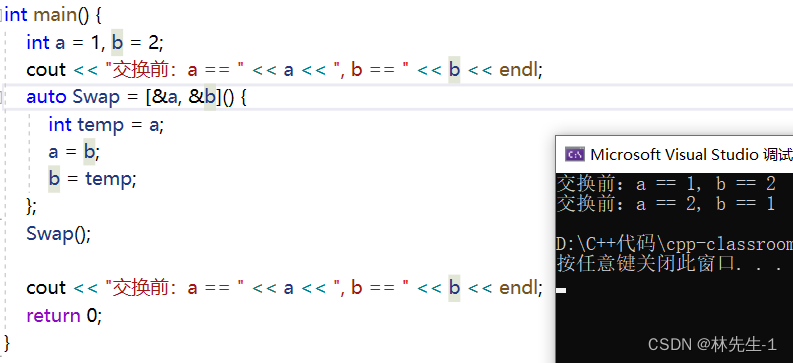
同理单独的[&]和单独的[=]逻辑是类似的。
还有一种比较特殊的场景是在类中使用lambda表达式的时候,
3、lambda表达式的原理
上面说了lambda有点类似于我们我们以前使用的仿函数和函数指针,其实它的底层也就是仿函数。
我们可以打印出某个lambda的类型出来看看:
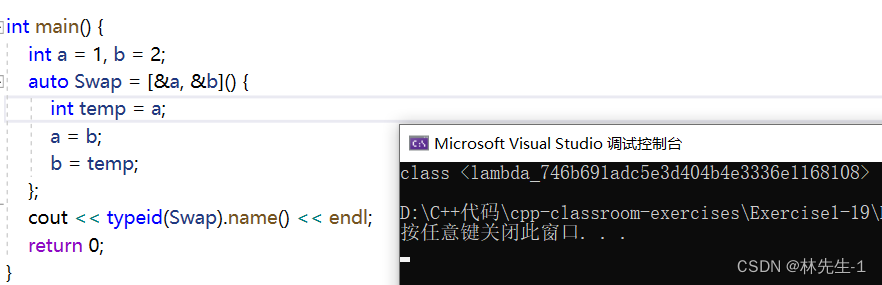
从这也可以看出lambda表达式其实也是一个类,而仿函数其实也是一个类。
我们还知道,仿函数其实是通过调用operator()来实现的,那我们就只需要证明lambda在底层调用了operator()就能证明,lambda表达式的底层其实也是仿函数了,这需要我们在汇编层才能看到:

从上面的汇编代码中我们可以看到,在调用了Swap之后,会转而去调用一个operator函数,而这个函数前面的类作用限定符就表明了这个函数是在这个lambda对象里面的。
所以,综上所述lambda的底层就是仿函数,它和我们以前使用的范围for一样,都是以前的东西再套了一个新“壳”,范围for的底层是迭代器,lambda的底层是仿函数。
五、包装器
包装器的头文件是<functional>
1、为什么要用包装器
我们之前所学到的函数指针、仿函数,再加上我们现在学到的lambda表达式,它们其实都是一些可调用对象。
它们或多或少都有一些问题,函数指针就不说了,设计太复杂了。仿函数的问题是需要用到的时候还得到外部去定义,而且如果比较的逻辑不一样的话还会造成代码的冗余。而lambda表达式就相当是一个匿名的仿函数对象,它的类型是匿名的,它也不能用来定义对象。
而包装器的产生就是为了统一它们三个,有了包装器之后我们可以用包装器将他们“包装"起来,然后使用的方法就很统一了,这就有点像我们以前学的”多态",而且用包装器将他们包装起来后,就都可以定义对象了。
比如我们现在有这样的场景,我们想实现根据对应的指令去调用对应的函数,而我们现在有以下这三个可调用对象:
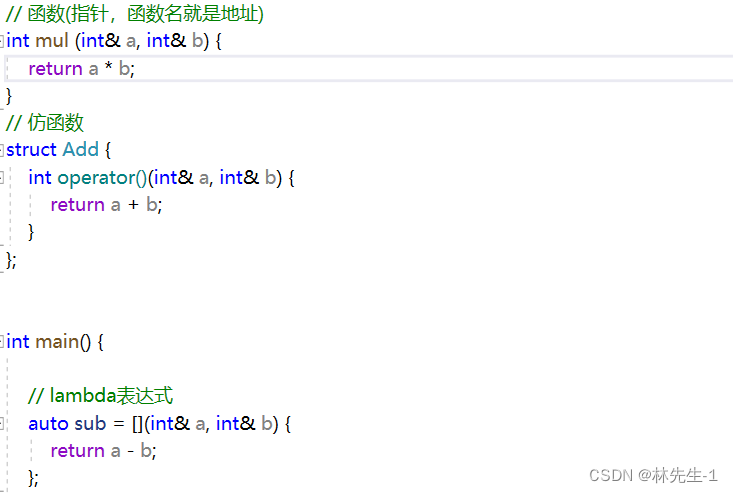
而我们想要将他们放入一个map对象中:

然后通过字符串去查询并调用它们,该怎么将他们统一起来呢?
这时候就该我们的包装器上场了:

这个包装器其实也是一个类模板,它就是专门来封装可调用对象的,它可以传函数指针、仿函数、lambda表达式,包装器可以将它们三者统一起来。但前提是它们的返回值类型参数类型和个数都一样。
所以我们就可以实现以下这样非常奇怪的玩法了:

这其实就是建立起了指令到函数的映射。
2、包装器包装成员函数
包装器在包装函数指针的时候有一个特殊情况,就是在包装成员函数的时,首先是要加类域,但是普通函数的函数名就是地址,而成员函数的函数名不表示地址,所以如果不对成员函数取地址的话,是会报错的:
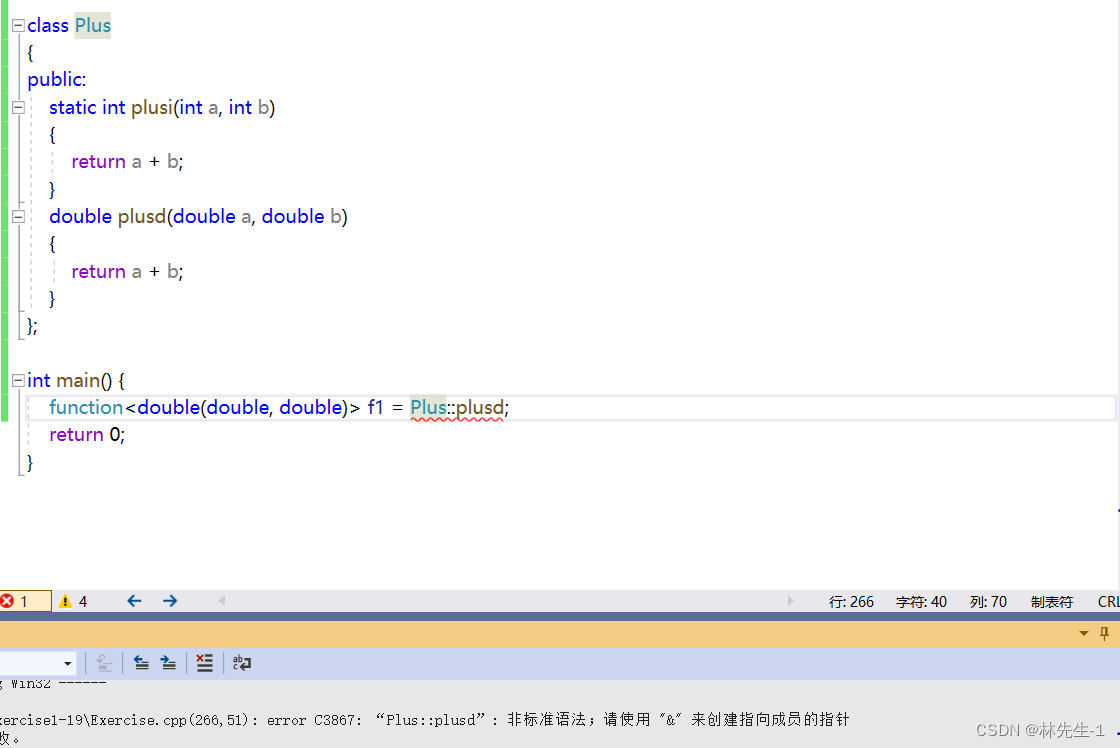
所以要加上取地址:
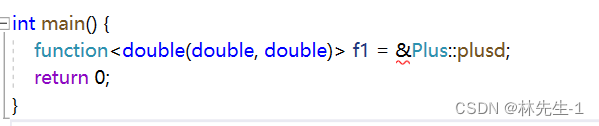
但是加了取地址还是会报错,这是因为成员函数都是需要对象来调用的,而我们外部并没有对象,并且成员函数内部都有一个隐藏的this指针,所以参数也是不匹配的。
所以我们还需要在参数列表中多加一个Plus*的参数,参数才能匹配。而且如果想要调用的话还需要先创建一个对象:

但是这些对于静态成员函数来说都不需要,静态成员函数在包装的时候只需要指定类域,它既不需要取地址,也不需要传递指针:
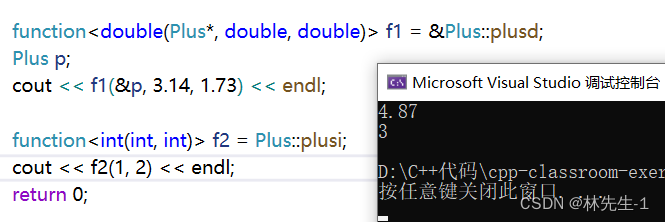
这是因为静态成员函数并没有this指针,可以说静态成员函数和普通成员函数是不一样的,至于为什么成员函数需要去取地址而静态成员函数不需要取地址其实也没什么原因,"规定“就是这样的。
3、包装器的参数控制——绑定包装器
上面对于普通成员函数包装时候总是要传入一个指针类型的形参和,调用的时候又要传入一个指针类型的实参,这其实是很麻烦的。
而我们在类里面调用成员函数和定义成员函数的时候并不需要显示的传入一个this指针,很方便。那我们在外层的包装器是否也能这样玩呢?
由于上面的这些问题,我们就引出了包装器的另一个新玩法——绑定包装器。
绑定包装器可以改变参数的个数也可以改变参数的顺序,也可以将某个参数”固定“,我们先来看看他的简单用法,比如我们现在有一个sub函数,我们可以用包装器对它进行包装并使用:
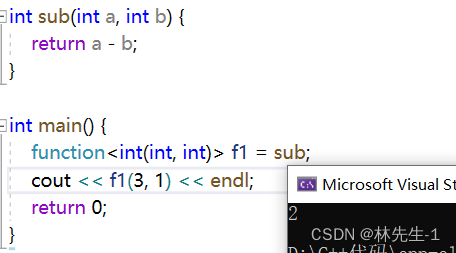
有了绑定包装器之后,我们就可以对他的参数位置进行调整:
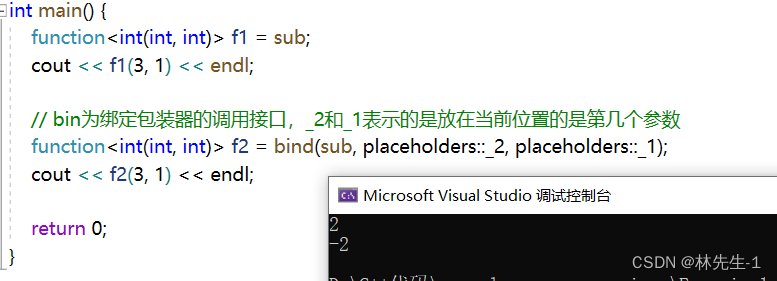
也就是说,传入的实参位置没有变,但是实参实际被传入到的形参的位置变了。
至于这个placeholders……这其实是一个命名空间,这些_1、_2就是在这个命名空间里面定义的。
唉……反正C++11有些语法用起来就是各种怪,其实没必要去深究。
它还有第二种玩法——调整参数个数(有点类似缺省参数):
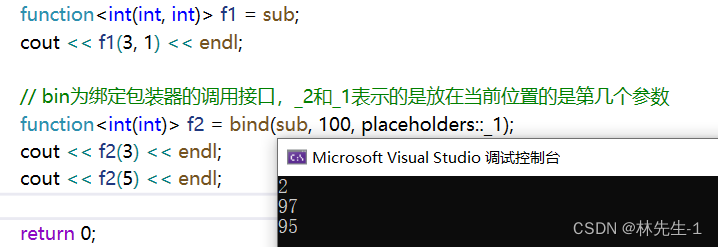
如上,我们是将第一个参数给固定成100了,那之后调用第一个参数就一直是100了,不需要在传了。
就因为这样的用法,我们可以对我们上面的例子进行改造,即将this指针设置成”隐含“

但是这里不应该传的是指针吗?怎么又传了一个匿名对象呢?
注意:这里的_1、_2并不是针对原来函数的形参位置,而是针对我们传入的实参的位置,或者是我们function内模板参数的位置。
没办法……这又是vs编译器的特殊处理,他竟然给我们特殊处理了,那我们就直接用就行了。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- [NOIP2009 普及组] 多项式输出#洛谷
- java获取已经发送谷歌邮件的打开状态
- three.js从入门到精通系列教程 - 《three.js第一个3D案例—创建3D场景》
- 如何制作自己的xposed模块
- 外包干了3个月,技术退步明显。。。。。
- labelme目标检测数据类型转换
- 数据库MySQL----索引及视图
- 图像分割实战-系列教程14:deeplabV3+ VOC分割实战2
- OpenFeign超时控制
- 四、基础篇 vue条件渲染