论文阅读:Attention is all you need
【最近课堂上Transformer之前的DL基础知识储备差不多了,但学校里一般讲到Transformer课程也接近了尾声;之前参与的一些科研打杂训练了我阅读论文的能力和阅读源码的能力,也让我有能力有兴趣对最最源头的论文一探究竟;我最近也想按照论文梳理一下LLM是如何一路发展而来的,所以决定阅读经典论文。本文是这个系列的第一篇。】
Attention is all you need?这篇文章提出了一个新的“简单的”架构、LLM的基石——Transformer,主要是针对机器翻译任务,当然后来就出圈了。在这篇文章之前,机器翻译的做法是Encoder+Decoder(端到端),其中Encoder和Decoder都是循环神经网络+Attention。这篇文章所做的是把循环神经网络去掉,整个端到端是纯Attention的。
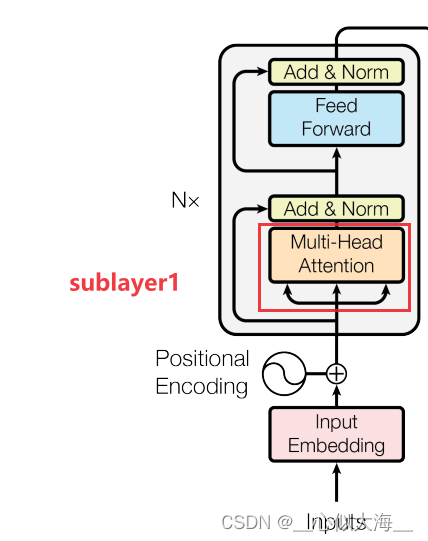
图解整体架构
论文中的这张图就可以说明Transformer的架构。左下方的inputs是传入的单词组成的句子,所以要经过一个embedding层,这是常规操作;然后通过N个编码块(论文中叫‘层’),每个编码块包括Multi-Head Attention(positional Encoding后面讲),归一化,前馈网络和残差连接(需要有resnet基础);编码器的输出给到解码器,但是是拦腰给进去的,不是在outouts的位置;解码器是"shifted right"的,意思是逐字生成的;解码块比编码块就多了一个Masked Multi-Head(后面讲),别的都和编码器一样。最后编码器通过一个softmax,就得到一个概率分布(即对字典里的每一个字都输出一个概率,一般概率最高的字作为这一步输出的字)。

接下来逐个详解模型中的每一个部分:
这个子层连同上面的norm,表示成公式就是![]()
LayerNorm
为什么要用LayerNorm而不是batchNorm?因为每一个seq的长度是不同的,使用batchNorm是把多个序列在某一个embedding维度上做归一化,而使用LayerNorm是在一个对一个序列在所有embedding维度上做归一化。前者当序列长度波动大时,每个batch的均值和方差也波动较大,预测不稳定。
Attention
q, k, v 是三种向量,Attention输出是多个v向量的加权平均,具体权重是多少呢?按q和k的相似度来决定。k-v是成对的; 新来了一个q,计算q和每个k的相似度,相似度高的,k对应v的权重就高。
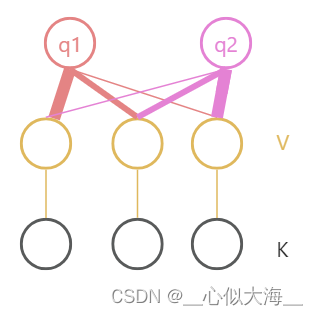
scaled dot-product attention
既然注意力机制要计算相似度,那么Transformer用的是哪一种相似度计算方式呢?
使用了最简单的内积相似度。
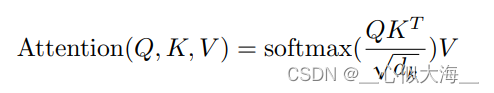
除以dk是为了防止值过大或过小,梯度消失。
Mask
在输出的到t时刻时,应该只看k1, k2, ... kt-1,所以之后的都被置为很小的负数,通过softmax后就会变为0。
多头注意力机制

就是把上面的Attention做多次,最后把结果拼起来,而每次都维度小一点。为什么要用多头?增加可学习的变量W,否则没有什么可学参数。
在Transformer中,输入输出的地方q, k, v是相同的,一个向量复制3份;但编码器传给解码器的向量是作为K,V,而Q来自解码器下一个输入。也就是解码器在解码器中通过控制权重挑出自己感兴趣的东西。
feed forward
就是mlp
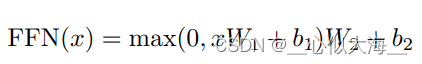
embedding
在Transformer中,embedding是共享权重的。
位置编码
注意到加权是顺序无关的,词序列打乱之后,加权结果不会变。为了解决这个问题,做如下位置编码并和embedding相加
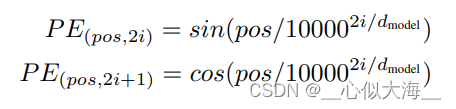
训练
训练部分在论文中也有详细交代,步长也比较讲究。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 某大型车辆检测维修公司降本增效项目纪实
- 微服务Redis-Session共享登录状态
- 2016-2020中国30m精细空间分辨率总初级生产力GPP
- 2. 两数相加(java)
- 美易平台:达沃斯论坛上谈论公司架构与未来发展
- 挑选富集分析结果 enrichments
- vue中引入路径@的用法及说明
- 【Vue2+3入门到实战】(7)Vue基础之 生命周期介绍 生命周期的四个阶段 生命周期钩子 详细示例
- 【OAuth2】用户授权第三方应用,使用授权码模式实例案例进行详解(源代码)
- 四款坚固耐用、小尺寸、1EDB9275F、1EDS5663H、1EDN9550B、1EDN7512G单通道栅极驱动器IC