【阅读笔记】Chain of LoRA
一、论文信息
1 论文标题
Chain of LoRA: Efficient Fine-tuning of Language Models via Residual Learning
2 发表刊物
arXiv2023
3 作者团队
Department of Computer Science, Princeton University
School of Computer Science and Engineering, Nanyang Technological University
4 关键词
LLMs、LoRA
二、文章结构
三、主要内容
论文探讨了如何通过残差学习来提高大型语言模型(LLMs)在特定任务上的微调效率。作者提出了Chain of LoRA (COLA) 方法,这是一种迭代优化框架,灵感来源于Frank-Wolfe算法,旨在在不增加额外计算成本或内存开销的情况下,缩小LoRA(低秩适应)与全参数微调之间的泛化误差差距。
四、相关研究
相关研究包括LoRA(低秩适应)及其变体,它们通过训练较小的低秩矩阵来近似权重更新,以提高微调效率。此外,还有参数高效的微调方法(PEFT),如Prefix tuning和Adapter-based方法,它们通过修改模型参数的较小部分来适应特定任务。
五、解决方案
COLA通过迭代地微调、合并和扩展LoRA模块来构建一个LoRA链。这种方法通过学习残差信息来逐步逼近最优权重更新,而不是从头开始学习整个权重更新。COLA在微调过程中,将学习到的LoRA模块合并到预训练的语言模型参数中,并为新生成的LoRA模块重置优化器状态。
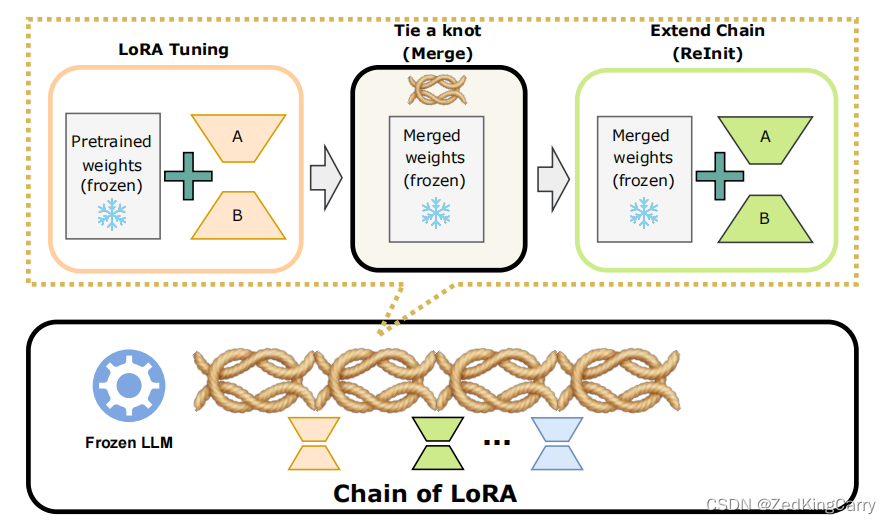
六、实验环节
论文在OPT-1.3B和Llama2-7B两个大型语言模型上进行了实验,并在七个基准任务(SST-2, WSC, CB, WIC, BoolQ, MultiRC, RTE)上进行了评估。实验结果表明,COLA在保持相同或更低的计算成本的同时,能够持续地优于LoRA。
七、进一步探索点:
- 应用COLA与不同的基础优化器。
- 在更大的语言模型上进行进一步实验。
- 在分类任务之外,探索COLA在生成、摘要和多选任务上的应用。
八、总结
Chain of LoRA (COLA) 是一种新的微调框架,它通过迭代优化和残差学习来提高大型语言模型在特定任务上的性能。与现有的LoRA方法相比,COLA在不增加计算成本的情况下,能够实现更好的泛化性能。通过实验验证,COLA在多个模型和任务上都显示出了其有效性,并为未来的研究提供了新的方向。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Vue和React的运行时,校验引入包的上下文差异
- springboot集成钉钉通知
- 计算机缺失api-ms-win-crt-runtime-l1-1-0.dll要怎么解决
- 【ARM 嵌入式 编译 Makefile 系列 2.2 - Makefile: 打印Makefile 中的行号】
- 多目标优化中常用的多目标遗传算法NSGA2【3】
- linux更新内核
- 测试必备 | 测试工程师必知的Linux命令有哪些?
- stm32学习笔记:TIIM-输入捕获
- 裸机开发(2)-裸机实战
- Vue中Render函数、_ref属性、_props配置的使用