Pandas数据爬虫,爬取网页数据并存储至本地数据库
read_html函数是最简单的爬虫,可爬取静态网页表格数据,但只适合于爬取table 表格型数据,不是所有表格都可以用read_html爬取,有的网站表面上看起来是表格,但在网页源代码中不是table格式,而是list列表格式,这种表格就不适用read_html爬取。
pymysql库可以将Python与SQL数据库建立完美连接,而read_sql在pymysql库建立连接后将SQL数据库的数据读取进来,整个流程如下:read_html抓取网页数据?pymysql库建立连接存储数据?read_sql读取数据库中的数,下面一起来操作一下。
1. read_html抓取数据
下面先学习一下read_html() 函数的参数,在代码行中写入
import pandas as pd
df=pd.read_html()在括号中使用Shift+Tab组合键调用代码提示功能,可以看到read_html都包含以下参数。

这里例举常用的一些参数。
- io:url、html文本、本地文件等
- header:标题行
- flavor:解析器
- skiprows:跳过的行
- attrs:属性,例如:attrs = {'id':'table'}
- parse_dates:解析日期
下面我们使用代码实际爬取网页表格数据,比如下面的新浪财经数据中心。
http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml

在该数据中心界面右键点击检查。

查找元素的时候我们发现新浪财经数据中心的数据即为表格型数据,如下图所示在检查元素里面有table的字样。
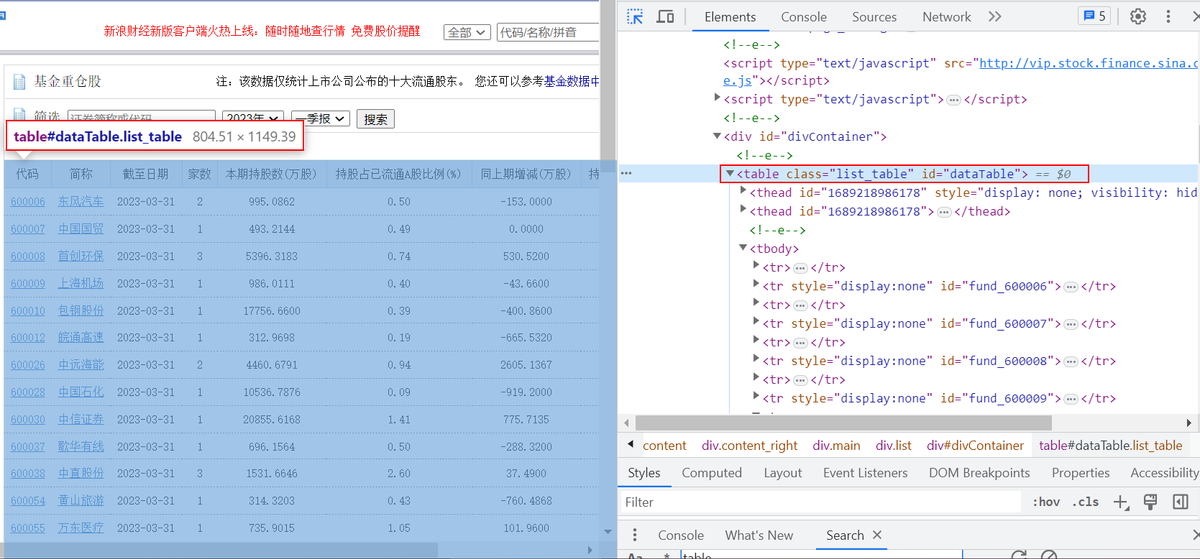
检查发现上面的数据为表格型数据,使用read_html爬取网页数据,返回的结果是DataFrame组成的list ,在最后加上一个索引[0]即可得到爬取的表格数据。
import pandas as pd
df=pd.read_html('http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml')[0]
df.head()
下拉到网页的最后,发现该数据中心包含多个页面,点击下一页即可看到。

点击到第二页,发现网页网址的后缀变为?p=2。
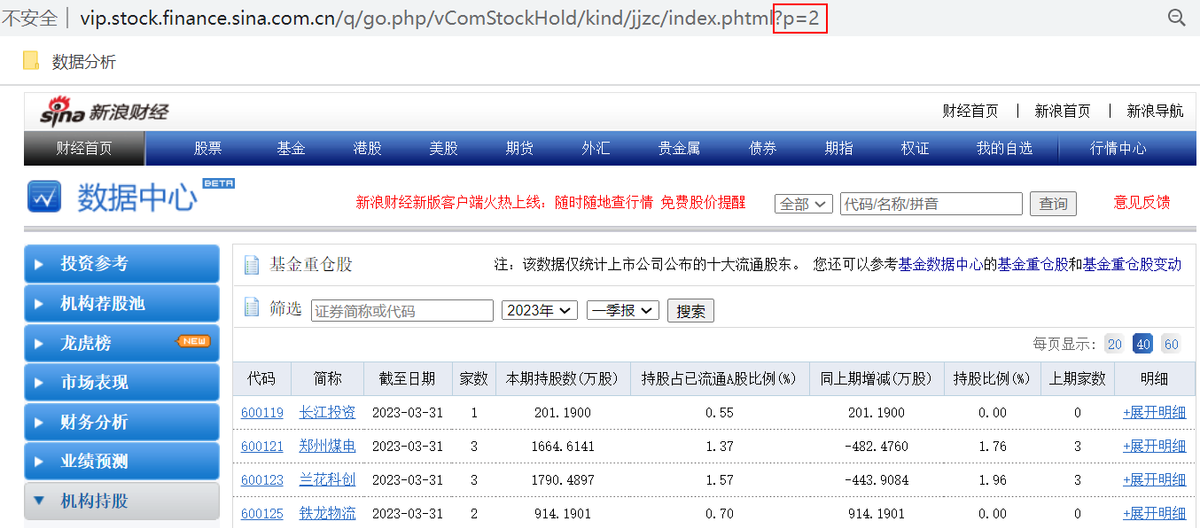
点击到第三页,发现网页网址的后缀变为?p=3。

看到这里我们是不是发现了规律,就是每次点击下一页,对应的页面后面的网址会跟着变化,下面我们构造一个list,用于存储各个页码下的网址,比如我们爬取前6页网页表格数据。
url_str='http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml?p='
for i in range(6):
url=str(url_str)+str(i+1)
print(url)
构造好网址链接后,使用for循环遍历出来,依次使用read_html将数据爬取下来,并用concat函数将表格数据全部合并起来。
import pandas as pd
df = pd.DataFrame()
url_str='http://vip.stock.finance.sina.com.cn/q/go.php/vComStockHold/kind/jjzc/index.phtml?p='
for i in range(6):
url=str(url_str)+str(i+1)
#print(url)
df = pd.concat([df,pd.read_html(url)[0]])
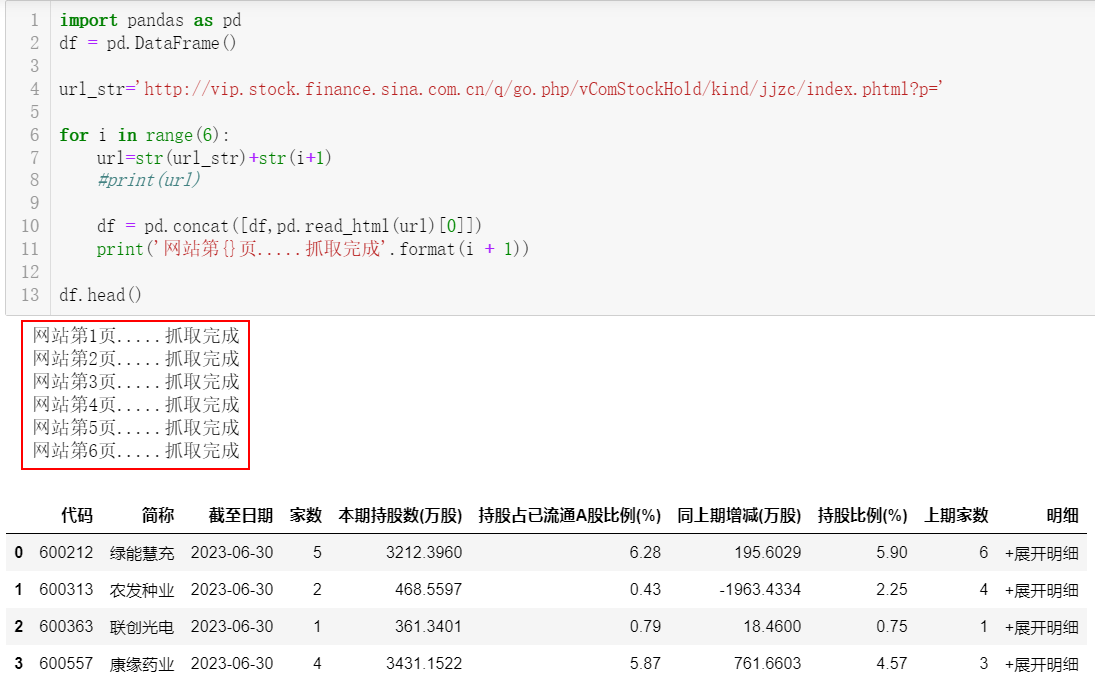
print('网站第{}页.....抓取完成'.format(i + 1))
df.head()如下就是我们数据爬取的结果,将新浪财经数据中心的每一页表格数据抓取下来。
2. pymysql建立连接
将数据导入数据库,这里还是使用上面的数据文件,连接数据库使用的模块为pymysql。
#导入需要使用到的数据模块
import pymysql数据库连接,host为数据库地址、user为用户名、password为密码、db为数据库的名字、port为端口,默认为3306。
# 建立数据库连接
con = pymysql.connect(host='127.0.0.1',
user='root',
password='123456',
db='demo',
port=3306)获取游标对象。
# 获取游标对象
cursor = con.cursor()用数据库demo,'USE demo' 也是数据库内的SQL语言。
#使用数据库demo
cursor.execute('USE demo')构造一个test_table表,包含代码、简称、截至日期等多个字段,执行代码命令后,在Navicat里面刷新即可看到如下的一张空表。
#创建一个SQL表
cursor.execute('create table if not exists test_table(代码 char(10) primary key,
简称 char(10),
截至日期 char(10),
家数 int(10),
本期持股数 float,
持股占已流通A股比例 float,
同上期增减 float,
持股比例 float,
上期家数 int(10))')
关于创建一张空表,下面的SQL语法等同于上面的Python生成一张空的表。
CREATE TABLE `test_table` (
`代码` char(10) NOT NULL,
`简称` char(10) DEFAULT NULL,
`截至日期` char(10) DEFAULT NULL,
`家数` int(10) DEFAULT NULL,
`本期持股数` float DEFAULT NULL,
`持股占已流通A股比例` float DEFAULT NULL,
`同上期增减` float DEFAULT NULL,
`持股比例` float DEFAULT NULL,
`上期家数` int(10) DEFAULT NULL,
PRIMARY KEY (`代码`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;接着向test_table表内插入从网页爬取的数据。
#插入数据语句
query = "insert into test_table(代码,简称,截至日期,家数,本期持股数,持股占已流通A股比例,同上期增减,持股比例,上期家数)
values (%s,%s,%s,%s,%s,%s,%s,%s,%s)"迭代读取每行数据,转化数据类型,将其保存在values内。
#迭代读取每行数据,values中元素有个类型的强制转换,否则会出错
for r in range(0, len(df)):
代码 = df.iloc[r,0]
简称 = df.iloc[r,1]
截至日期=df.iloc[r,2]
家数=df.iloc[r,3]
本期持股数=df.iloc[r,4]
持股占已流通A股比例=df.iloc[r,5]
同上期增减=df.iloc[r,6]
持股比例=df.iloc[r,7]
上期家数=df.iloc[r,8]
values = (代码,简称,截至日期,家数,本期持股数,持股占已流通A股比例,同上期增减,持股比例,上期家数)
#print(values)
cursor.execute(query, values)关闭游标,提交,关闭数据库连接,在Navicat里面刷新即可看到已经存储到本地数据库中的数据。
#关闭游标,提交,关闭数据库连接,如果没有这些关闭操作,执行后在数据库中查看不到数据
cursor.close()
con.commit()
con.close()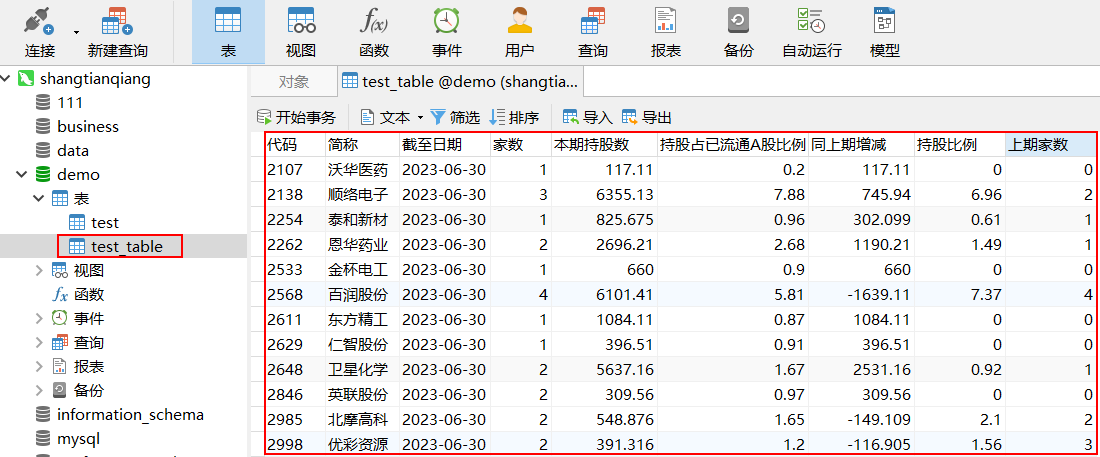
3. read_sql数据库查询
利用Python从数据库查询数据只需要两步,第一步使用pymysql库将Python与数据库进行连接,第二步使用read_sql命令将数据库数据读取进来。
#导入需要使用到的数据模块
import pymysql
import pandas
# 建立数据库连接
con = pymysql.connect(host='127.0.0.1',
user='root',
password='123456',
db='demo',
port=3306)read_sql函数中有个sql参数用于使用SQL语法查询数据,数据查询后的结果如下。
#SQL语句查询
sql='select * from test_table'
df_sql=pd.read_sql(sql,con)
df_sql.head()
以上借助新浪财经案例使用read_html命令将网页表格数据抓取下来,并使用pymysql库将抓取下来的数据存储至本地数据库,如果要加载数据库内的数据,可以使用read_sql命令将数据读取,以上案例需要读者活学活用,如果对这方面的知识感兴趣,不妨关注我,持续分享数据分析知识~
本文首发于公众号:大话数据分析,专注于数据分析的实践与分享,掌握Python、SQL、PowerBI、Excel等数据分析工具,擅长运用技术解决企业实际问题,欢迎一同探索数据的世界,解锁业务背后的秘密。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!