递归(dfs)
力扣21.合并两个有序链表
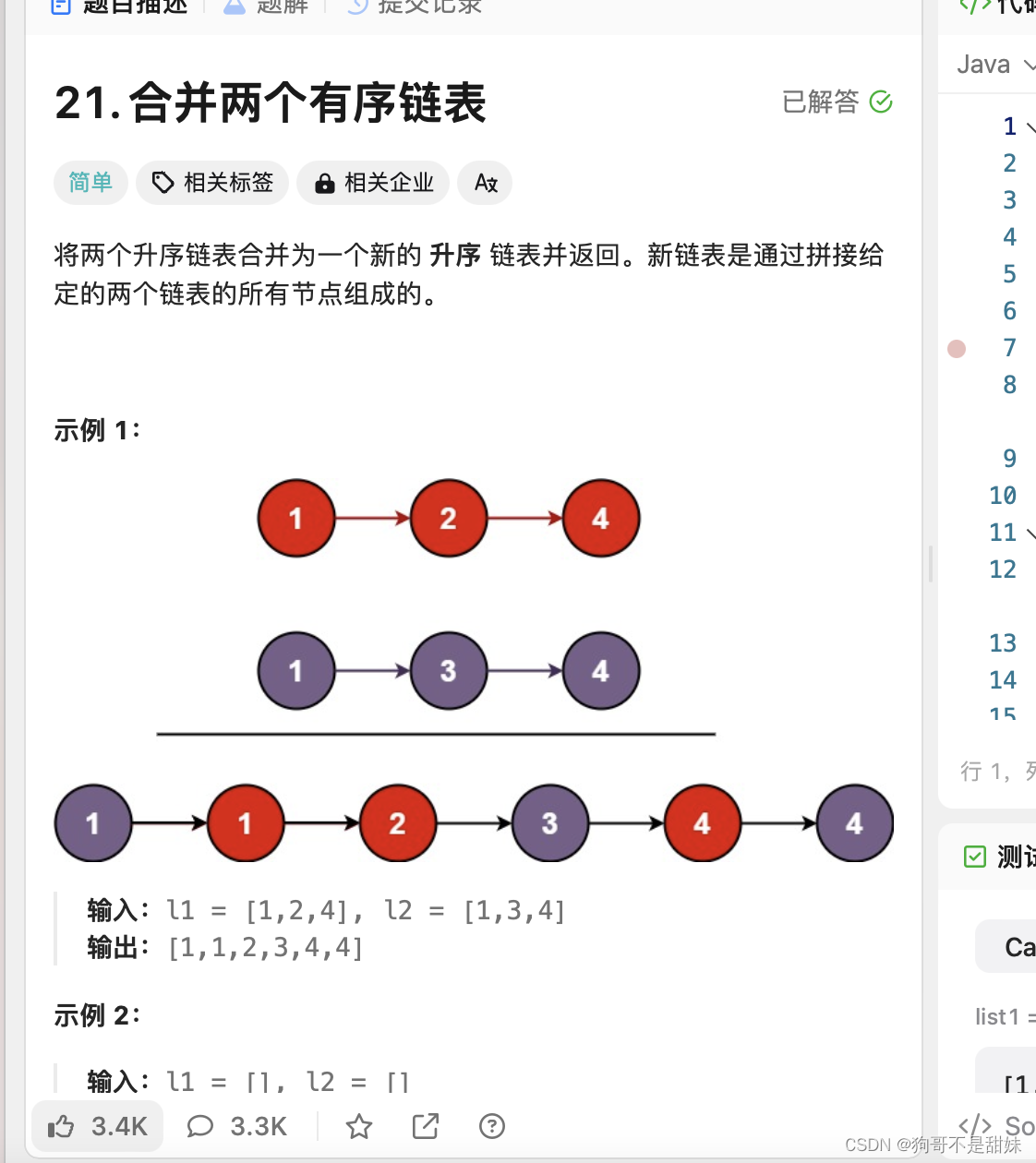
我们要相信dfs()一定能给我做到这个事情
重复子问题+宏观看待递归问题
1.找到重复的子问题->函数头的设计
合并两个有序链表?
2.只关心某一个子问题在做什么事情-函数体的设计
选择较小的,然后连接剩下的两个部分 l1->next=dfs(l->next,l2)
3.return l1;
递归的出口 谁为空,返回另一个即可。
循环vs递归
递归的核心是找到一个重复的子问题,找到重复子问题
递归vs深度搜索dfs
递归展开图的顺序,其实细细一想就是深度优先搜索的顺序一样,递归的执行逻辑就是一颗树的深度优先(dfs)
当递归展开图很麻烦,用递归会比较好
当递归展开很简单,用循环就会很简单
中序遍历(只在二叉树中才有)
先序遍历vs后续遍历
本质都是深度优先遍历
这个题我之前使用循环做,得有20多行代码
递归的代码之美也体现在这里
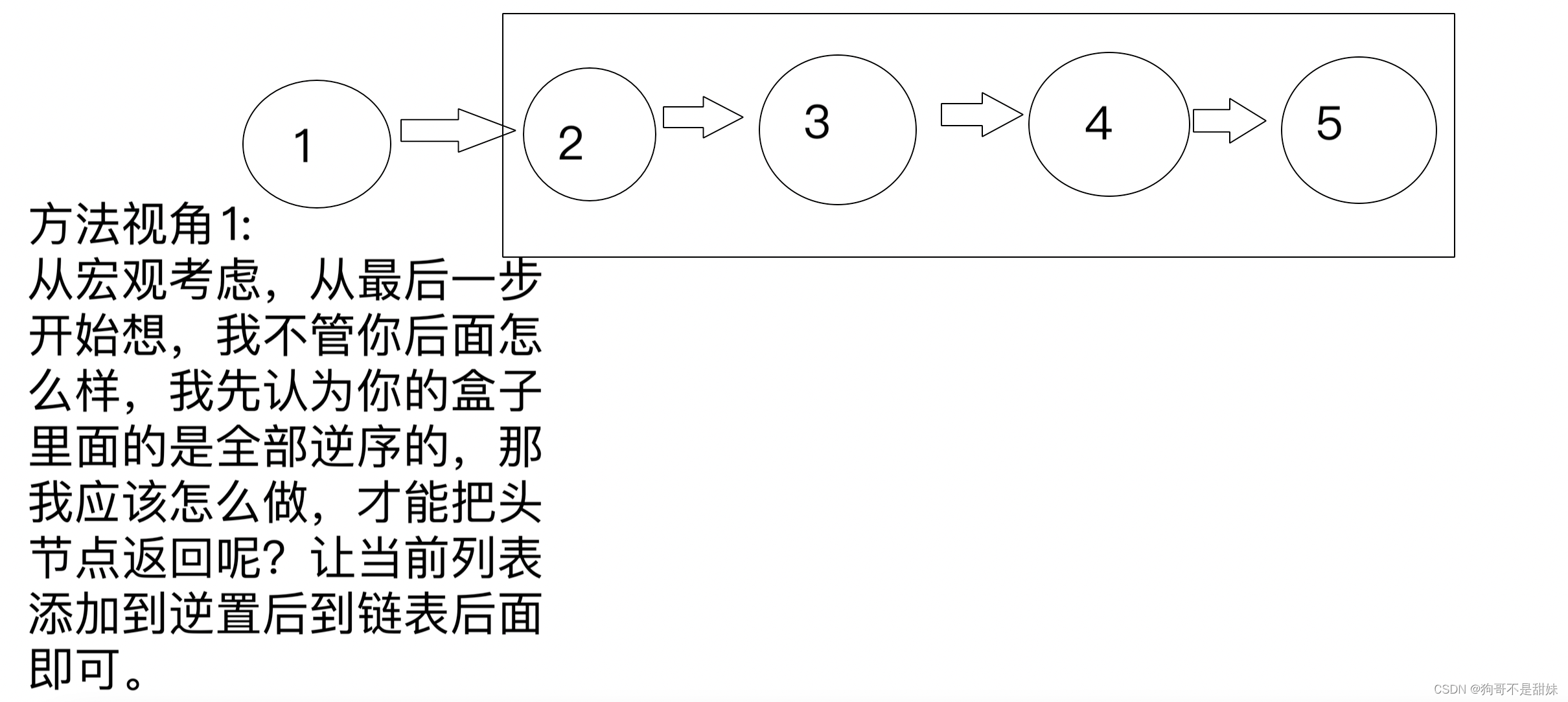
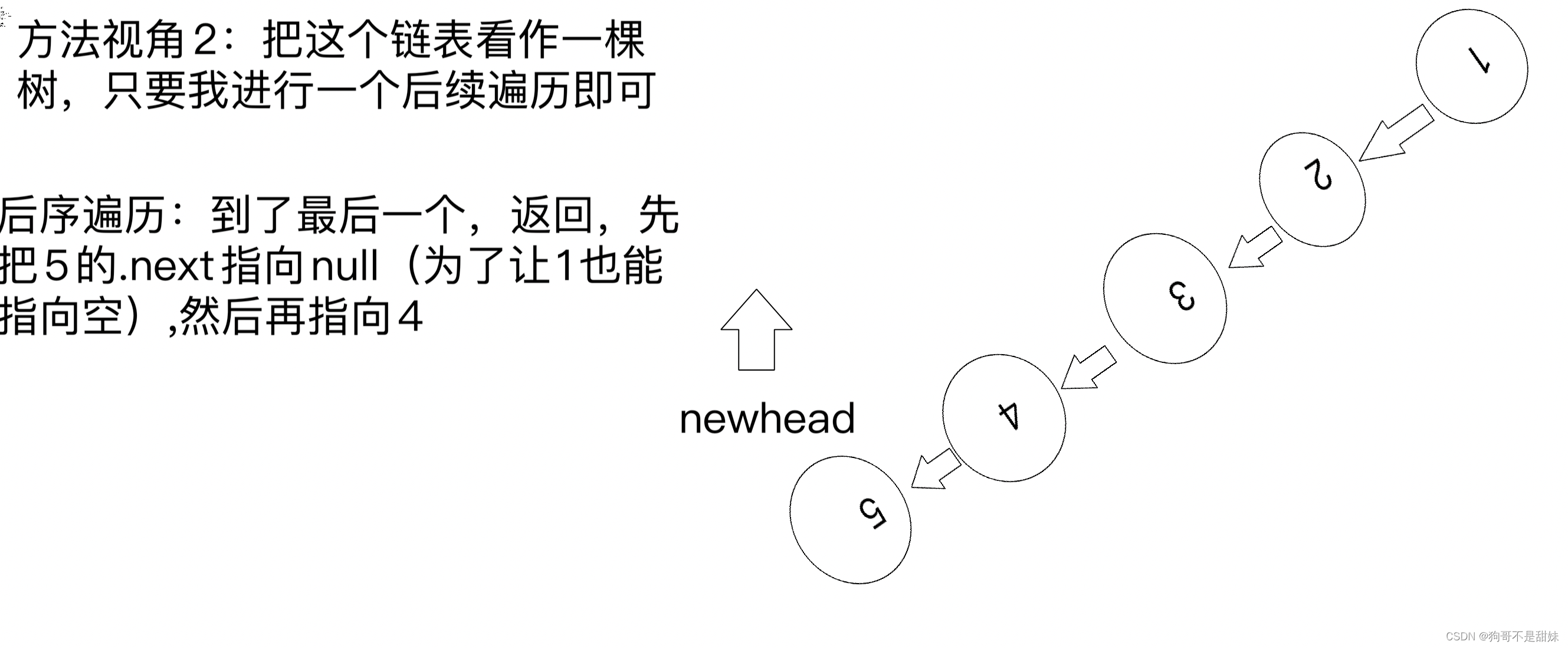
力扣206反转链表(递归)

两种思想一致,只是视角不一致。
class Solution { public ListNode reverseList(ListNode head) { if(head==null||head.next==null) return head; ListNode newHead=reverseList(head.next); head.next.next=head; head.next=null; return newHead; } }
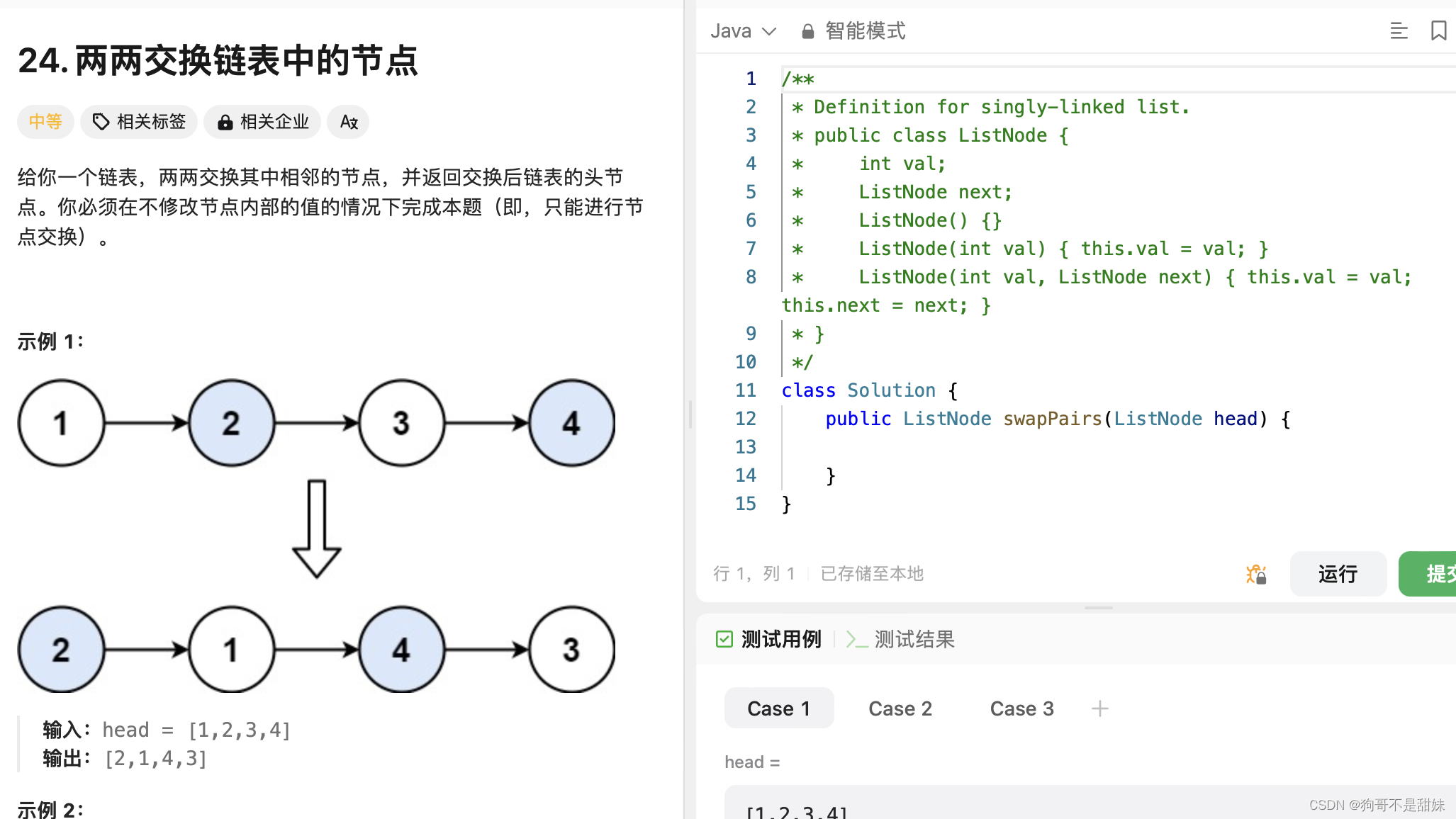
力扣24.两两交换链表中的节点
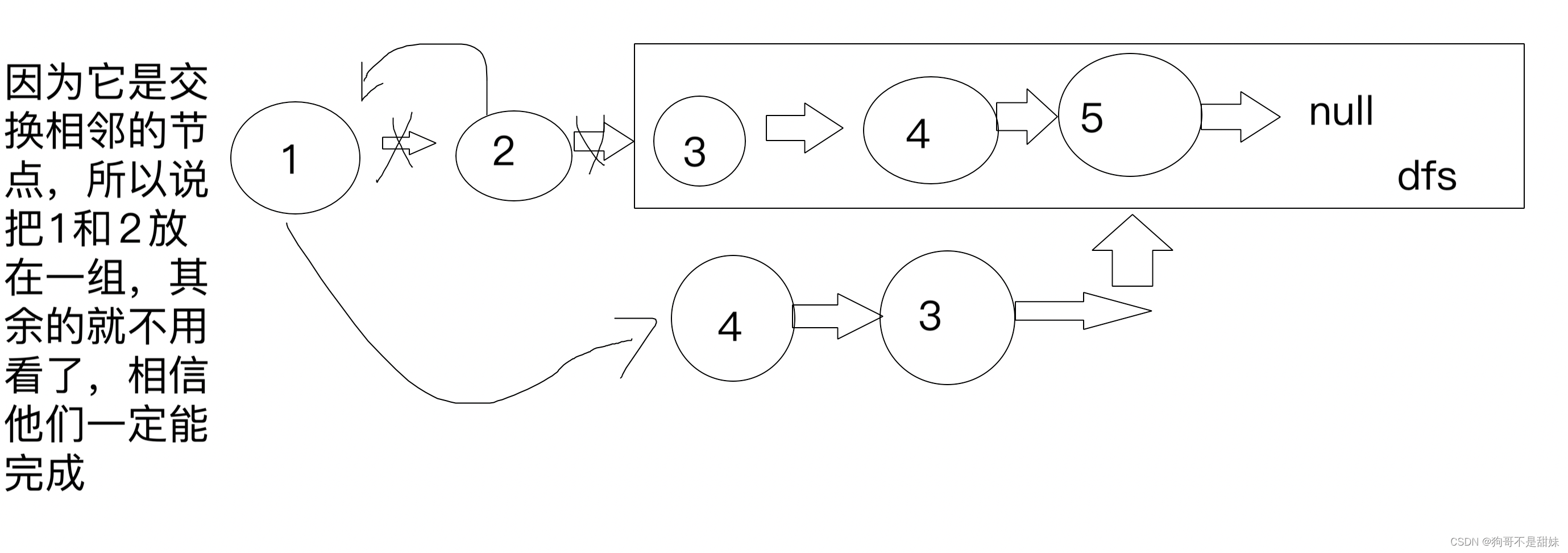
这道题核心和反转链表都是相同,而且注意他是1和2是一组,所以说节点这方面也是把1和2放一起,只考虑12,要相信后面的事情一定能够完成
public ListNode swapPairs(ListNode head) { if(head==null||head.next==null) return head; ListNode newhead=swapPairs(head.next.next); head.next.next=head; head.next=newhead; return head.next; }第一个是我刚开始写的代码,后面看题解发现出现空指针,然后怎么也没发现错误,到了现在明白终于为什么了
public ListNode swapPairs(ListNode head) { if(head==null||head.next==null) return head; ListNode newhead=swapPairs(head.next.next); ListNode ret=head.next; ret.next=head; head.next=newhead; return ret; }是因为假如第一种写法返回的head.next已经被我后面的代码修改了,所以说head的next是不对的,但是下面这个写法是先保存了head.next这个节点,后面返回的时候就直接返回这个节点就可以了
力扣50.Pow(x,n)

快速幂
public static double myPow(double x, long n) { if (n == 0) { return 1.0; } if (n == 1) { return x; } if (n < 0) { x = 1 / x; n = -n; } //这个快速幂有个问题-必须是一半一半的,因为假如是一个一个那么递归n-1这样那么就会出现栈溢出的问题, double tmp = 1.0; tmp = myPow(x, n / 2); //一个一个%2这样只有两种结果,要么偶数,要么奇数,奇数就+1 return n%2==0?tmp*tmp:tmp*tmp*x; }但是在这个时候,我的脑子里突然涌出一个问题n%2==0,我们判断他是奇数还是偶数,是用来做这个的,但是我们奇数为什么不能是前一个而是后一个呢。
因为上面的代码是/2,假如n是21,他的tmp对应的是10,所以10+10+1,才能构成21,或者我可以这么理解,因为n/2是一个向下取整的数,所以此时n%2可以让他向上取整,也就是+1
因为假如正常做 例子 n=21 是要先/2 然后变成10+10+1 ? ,假如说我那个减法这么算就应该是,(21+1)/2,然后因为tmp代表的是x的11次幂,所以11+11最后需要减1
public static double myPow(double x, long n) { if (n == 0) { return 1.0; } if (n == 1) { return x; } if (n < 0) { x = 1 / x; n = -n; } double tmp = 1.0; tmp = myPow(x, (n+1)/2); return n%2==0?tmp*tmp:tmp*tmp/x; }
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- DL Homework 11
- UVa12304 2D Geometry 110 in 1!
- NestJS 支持自定义CLI命令行?一篇文章深入Command装饰器使用
- Spring见解
- 【MySQL】数据库中为什么使用B+树不用B树
- JVM运行时数据区(下篇)
- 【python爬虫】爬取学习网站的文章,实战教程!
- Java版本spring cloud + spring boot企业电子招投标系统源代码
- 美军杀伤网概念研究及对我防空作战装备体系的启示
- ruoyi后台管理系统部署-4-安装nginx