【python爬虫】爬取学习网站的文章,实战教程!
发布时间:2024年01月17日
前言:
- 本教程所爬取的数据仅用于自己使用,无任何商业用途,若有侵权行为,请联系本人,本人可以删除,另外如果转载,请注明来源链接。
两种方式:
- 采用scrapy框架的形式。
- 采用非框架的形式,具体是采用requests和etree。
正题:
- 首先介绍的是非框架的形式。这种形式便于部署到服务器上,定时批量的爬取数据。
- 以此网站为例,当然最好用谷歌打开此网站,这样可以更好的上手爬虫。
- 废话不多说,开始干货了。
- 谷歌浏览器打开http://stock.stcn.com/,鼠标右击“检查”,出现如下图所示画面
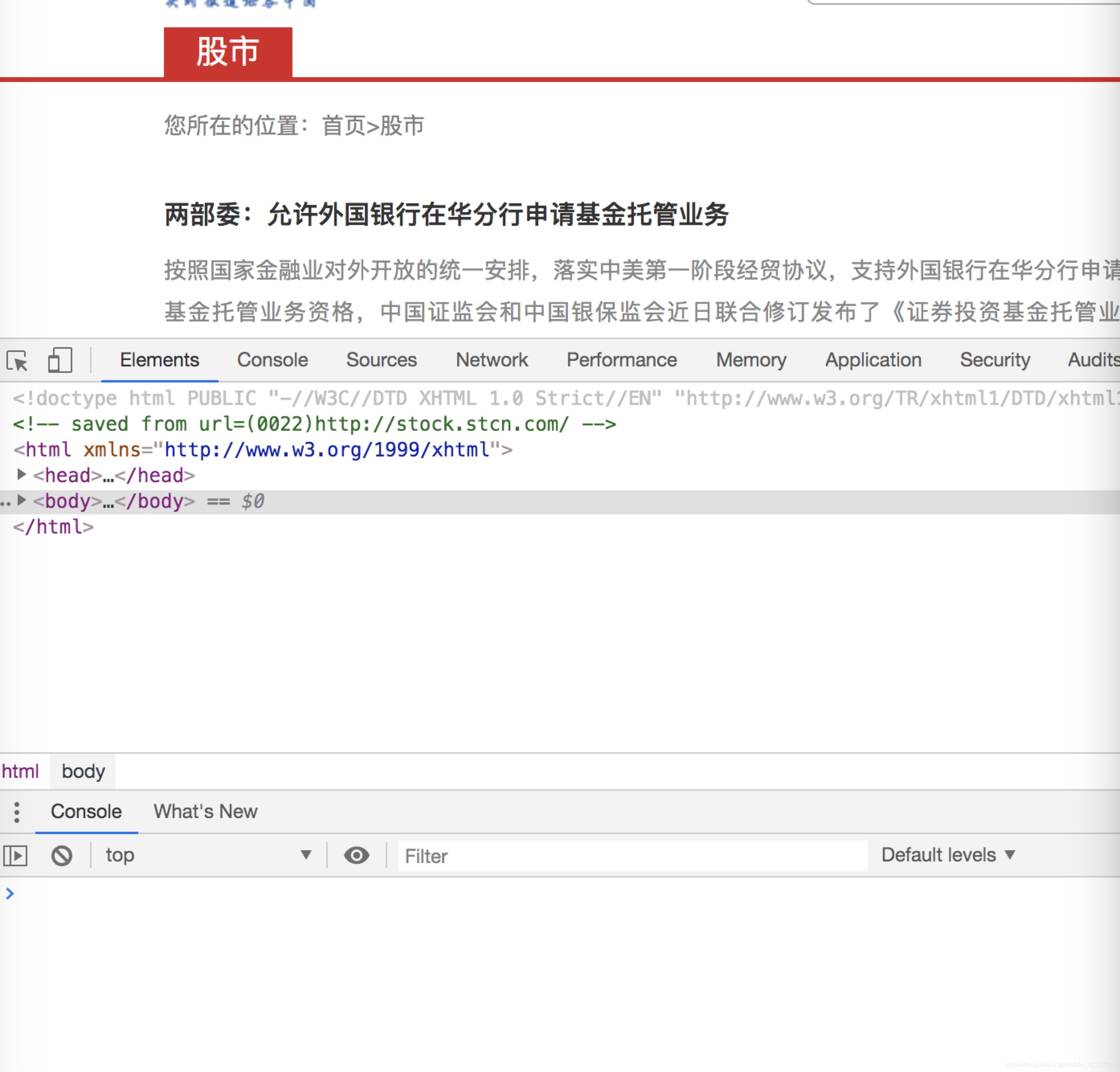
- windows用户同时使用“ctrl”和“f”,mac用户同时使用“win”和“f”,调出搜索框, 如下图所示。
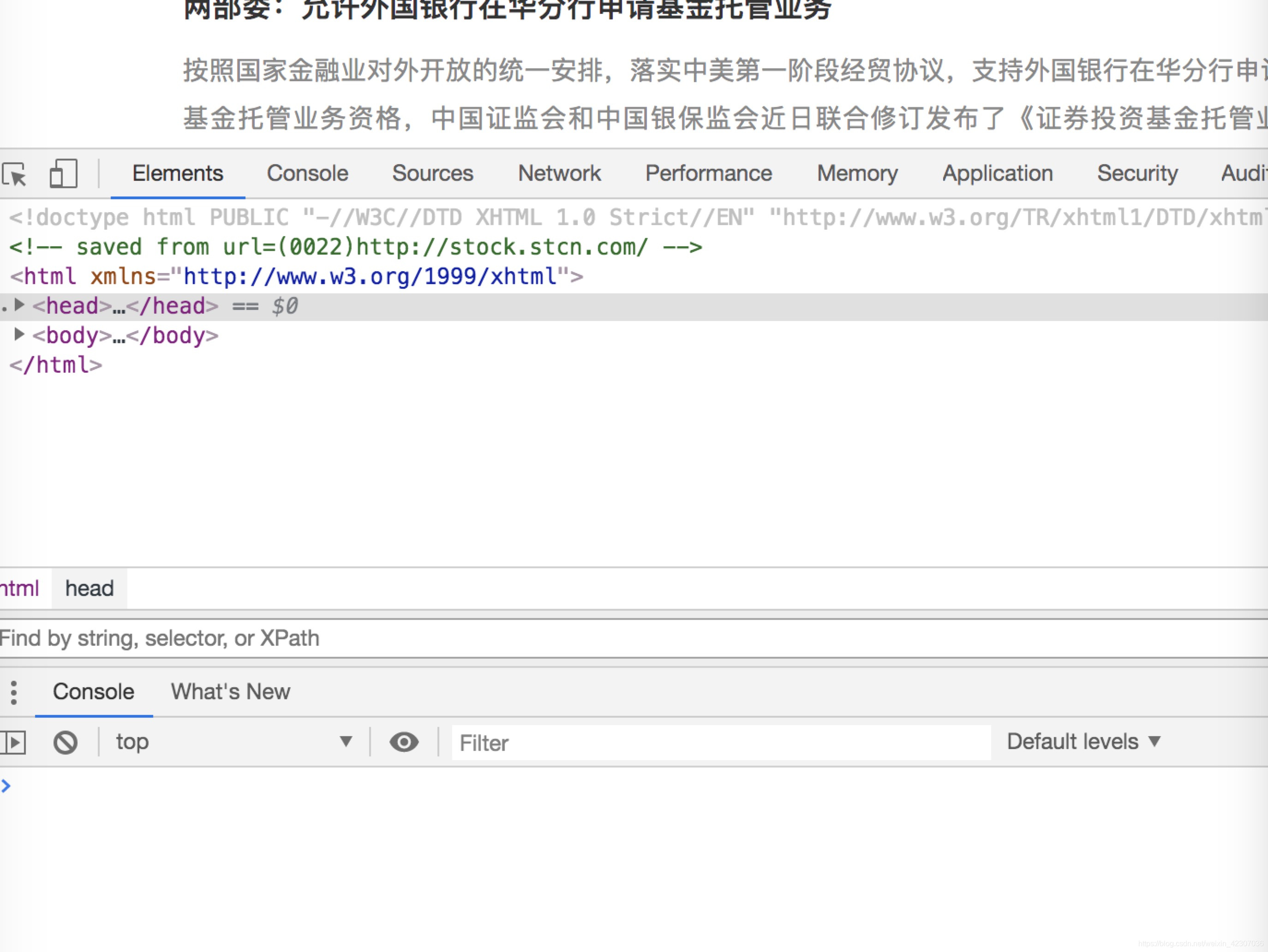
- 这个搜索框用于输入xpath,就可以定位到本页面的任何位置,得到你所需要爬取的数据,这其实是爬虫任务上最繁琐耗时的事情,而且也会出现所爬页面样式改变的情况(例如该网站前端开发人员由于版本迭代将前端样式改变),你就得重新找到爬取数据的新的xpath。
- 那么如何得到xpath呢,首先你得知道xpath是什么,参考教程xpath用法,
- 了解了是什么以及怎么用之后就可以教你怎么得到所爬数据的xpath了,例如要爬取文章的标题,那么首先要点击箭头,然后鼠标移动到文章的标题上去,就可以看到文章所处的位置,从而找到xpath。
- 箭头以及本人找到的xpath如图所示。

- 当然下一步你就要进入具体的文章,把文章的内容、作者、发行时间等爬取下来,你在浏览器上点击文章标题就会进入文章的详情页,那代码怎么操作呢,实质上上述操作只是从一个网页进入了另一个网页,还记得我们已经找到了文章的标题,一般文章的标题和文章详情页的链接是在一块的,所以这两个的xpath一般只是后面的部分有少许不同,具体参见代码部分“parse_links函数”。
相关代码如下
def parse_links():
link_list = []
links_xpath_1 = '//div[@class="box_left"]//li//a/@href'
titles_xpath_1 = '//div[@class="box_left"]//li//a/@title'
for url in URL_LIST:
try:
res = requests.get(url, timeout=20)
sel = etree.HTML(res.text)
links = sel.xpath(links_xpath_1)[:10]
titles = sel.xpath(titles_xpath_1)[:10]
assert len(links) == len(titles)
if links and titles:
for l, t in zip(links, titles):
join_l = urljoin(url, l)
link_list.append((t, join_l))
except Exception as e:
logger.error("get links error: %s", e, exc_info=True)
return link_list
- 接下来就是爬取文章详情页的内容,具体参见代码部分"parse_details"
相关代码如下
def parse_details(link_list):
publ_date_xpath = '//div[@class="info"]/text()'
author_xpath = '//div[@class="info"]/span[1]/text()'
content_xpath = '//div[@class="txt_con"]/p//text()'
res_list = []
count = 0
def convert(s):
return s.strip()
for t, l in link_list:
try:
res = requests.get(l, timeout=20)
sel = etree.HTML(res.text)
publ_date = sel.xpath(publ_date_xpath)
if not publ_date:
continue
publ_date = datetime.strptime(publ_date[0].strip(), '%Y-%m-%d %H:%M')
if publ_date < datetime.now() - timedelta(days=2):
continue
author = sel.xpath(author_xpath)
author = author[0].split(':')[1].strip()
content = sel.xpath(content_xpath)
content = ' '.join(map(convert, content))
except Exception as e:
logger.error("failed to parse detail: %s", e, exc_info=True)
count += 1
else:
res_list.append((t, l, publ_date, author, content))
print(t, l, publ_date, author, content)
if count == len(link_list) and len(link_list) > 0:
return [], False
return res_list, True
- 还有一些具体的小处理,自己看看代码就好了。
完整代码分享如下:
# !/usr/bin/python
# -*- coding: utf-8 -*-
from __future__ import absolute_import, print_function, unicode_literals
import logging
from datetime import datetime, timedelta
import requests
from lxml.html import etree
# python2 and 3
try:
from urlparse import urljoin
except ImportError:
from urllib.parse import urljoin
logger = logging.getLogger(__name__)
URL_LIST = [
'http://stock.stcn.com/'
]
def parse_links():
link_list = []
links_xpath_1 = '//div[@class="box_left"]//li//a/@href'
titles_xpath_1 = '//div[@class="box_left"]//li//a/@title'
for url in URL_LIST:
try:
res = requests.get(url, timeout=20)
sel = etree.HTML(res.text)
links = sel.xpath(links_xpath_1)[:10]
titles = sel.xpath(titles_xpath_1)[:10]
assert len(links) == len(titles)
if links and titles:
for l, t in zip(links, titles):
join_l = urljoin(url, l)
link_list.append((t, join_l))
except Exception as e:
logger.error("get links error: %s", e, exc_info=True)
return link_list
def parse_details(link_list):
publ_date_xpath = '//div[@class="info"]/text()'
author_xpath = '//div[@class="info"]/span[1]/text()'
content_xpath = '//div[@class="txt_con"]/p//text()'
res_list = []
count = 0
def convert(s):
return s.strip()
for t, l in link_list:
try:
res = requests.get(l, timeout=20)
sel = etree.HTML(res.text)
publ_date = sel.xpath(publ_date_xpath)
if not publ_date:
continue
publ_date = datetime.strptime(publ_date[0].strip(), '%Y-%m-%d %H:%M')
if publ_date < datetime.now() - timedelta(days=2):
continue
author = sel.xpath(author_xpath)
author = author[0].split(':')[1].strip()
content = sel.xpath(content_xpath)
content = ' '.join(map(convert, content))
except Exception as e:
logger.error("failed to parse detail: %s", e, exc_info=True)
count += 1
else:
res_list.append((t, l, publ_date, author, content))
print(t, l, publ_date, author, content)
if count == len(link_list) and len(link_list) > 0:
return [], False
return res_list, True
def process():
link_list = parse_links()
res_list, ret = parse_details(link_list)
if res_list:
logger.info('get %d news', len(res_list))
if ret:
logger.info('successfull save news')
if __name__ == "__main__":
process()
- 上述代码你可以放到以“crawl1.py”命名的文件里,然后在命令行输入“python3 crawl1.py > ttt”那么爬虫结果就会自动写入到ttt文件中,当然如果winows命令行不能用输出流’>’,则可以直接在windows的命令行输入“python3 crawl1.py”结果就直接打在了屏幕上,windows命令行进入的方式是“win+r”,然后cmd回车就可以进入命令行了,然后“cd Desktop”就进入桌面了,你可以把crawl.py文件放到桌面上,就可以保证运行了。
- 完整代码亲测可以运行,请放心学习,有问题可以评论
- 本博客的爬虫结果直接存储到文件中,当然最好可以放到数据库中,这样可以查重,避免重复爬取,如有读者需要数据库存储爬虫数据的可以评论留言,人多就会发怎么样设置数据库,以及怎么样查重避免重复抓取数据。
如果你对Python感兴趣,想要学习python,这里给大家分享一份Python全套学习资料,都是我自己学习时整理的,希望可以帮到你,一起加油!
😝有需要的小伙伴,可以V扫描下方二维码免费领取🆓
?
1??零基础入门
① 学习路线
对于从来没有接触过Python的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

② 路线对应学习视频
还有很多适合0基础入门的学习视频,有了这些视频,轻轻松松上手Python~

③练习题
每节视频课后,都有对应的练习题哦,可以检验学习成果哈哈!

2??国内外Python书籍、文档
① 文档和书籍资料

3??Python工具包+项目源码合集
①Python工具包
学习Python常用的开发软件都在这里了!每个都有详细的安装教程,保证你可以安装成功哦!

②Python实战案例
光学理论是没用的,要学会跟着一起敲代码,动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。100+实战案例源码等你来拿!

③Python小游戏源码
如果觉得上面的实战案例有点枯燥,可以试试自己用Python编写小游戏,让你的学习过程中增添一点趣味!

4??Python面试题
我们学会了Python之后,有了技能就可以出去找工作啦!下面这些面试题是都来自阿里、腾讯、字节等一线互联网大厂,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


上述所有资料 ?? ,朋友们如果有需要的,可以扫描下方👇👇👇二维码免费领取🆓
?
文章来源:https://blog.csdn.net/bagell/article/details/135641922
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【80211-2022】【学习记录】【第九章】帧类型格式【1】
- Hive数据定义(2)
- python定义代码块的符号,python中代码块所属关系
- 安装docker-compose
- 【MySQL】WITH AS 用法以及 ROW_NUMBER 函数 和 自增ID 的巧用
- 折磨人的回文数
- 基于Java SSM框架实现医院挂号上班打卡系统项目【项目源码+论文说明】计算机毕业设计
- 重学Java 4 进制转换和位运算
- 【C++】最少知识原则
- QT QIFW Linux下制作软件安装包