【python】正则表达式-快速信息匹配,过滤与检测
前言
菜某的总结,希望能够帮到大家。
正则表达式的概念
简单来说就是匹配信息,创建一个规则,匹配文本中符合这个规则的内容
作用领域
单单看他的概念可能觉得他的用途也就是查找,实际上他的用途很广泛
1.信息筛选,过滤不符合规则的内容
2.输入信息验证,匹配用户输入的信息
3.匹配文本中的内容位置
4.辅助爬虫,去爬符合条件的网站,而不是指定具体的网站
常用方法
正则表达式需要使用re库。
| 函数 | 描述 |
| complie() | 编译正则表达式 |
| escape() | 正则符号转义处理 |
| findall() | 匹配正则符号,以列表形式返回 |
| finditer() | 匹配正则符号,以迭代形式返回 |
| match() | 从头开始匹配 |
| purge() | 清除缓存中的正则表达式 |
| search() | 在任意位置上进行匹配(只找一个) |
| split() | 按照给定匹配符号拆分字符串 |
| sub() | 正则匹配替换 |
| subn() | 正则匹配替换并返回替换结果 |
案例在下方配合字符使用
字符
正则表达式实际上就是匹配对应的字符,只不过这个字符分为两种
普通字符:顾名思义就是匹配要匹配的那个字
元字符:是符合相应规则的字。
常见元字符:. * + ? \ | { } [ ] ( )
+代表匹配重复出现的内容
?会生成一个列表,满足条件为匹配内容,不满足为空(一个字符一个字符的匹配)
*会生成一个列表,跟?一样,不同的是如果有重复相邻的会作为一个元素
.代表任意字符
{}代表匹配重复的类字符个数
[]指定匹配的内容
|类似于or,后面跟另一个表达式他也会匹配另一个
()分组,把匹配内容进行分组
\数字,规定本组的内容跟第几组的内容一样
某一类别字符:
标识符 描述 \b 匹配开始或结束位置的空字符 \B 匹配不在开头结尾的空字符 \d 匹配数字 \D 匹配非数字 \s 匹配空格 \S 匹配非空格 \w 匹配字母 \W 匹配非字符
可以观察到基本上小写是匹配这一类,大写是匹配不是这一类。
位置匹配符
^规定匹配在文本开头的相应字符
$规定匹配在末本尾的相应字符
\A等价于^
\Z等价于$
\b单词边界
\B非单词边界
。。(?=...)匹配出现在...之前的。。
。。(?!...)匹配不是在...之前的。。
(?<=...)。。匹配出现在...之后的。。
(?<!...)。。匹配不在...之后的。。
其他特殊功能
我从网上找的别人整理的图。

普通字符匹配
案例:

我们可以看到他已经匹配到了相应的字符。

这里findall里的r代表的是把一些转义字符当做普通字符用
某一类别字符匹配与
找数字类字符


找空格类字符


元字符的应用
+字符的应用
+代表了匹配规定字符出现了一次或者多次

这里第一个匹配是匹配连续的数字,第二个匹配是匹配连续的5

?字符的应用
?字符代表的是匹配字符出现0,1。其实就是单个字单个字的匹配。不符合规定的就会返回空字符

?
可以看到这个?是单个字符匹配,匹配到符合的就显示出来,不符合就是空字符
*字符的应用
*的作用与?相类似,不过他会找出重复的作为一个元素,而?是单个字符单个字符的匹配


这里的15和555已经被当做了一个元素放到了列表中。
[ ]的用法
[ ]是用来规定匹配范围的。
[1-5]就代表了匹配其中含有1-5之间的数字的内容
[你好啊]就代表匹配其中含有这三个字之一的内容
[a-zA-Z]就代表匹配所有的字母


{ }的用法
{ }的作用是规定匹配的数量
一些用法举例
\d{1,4}匹配一个或者4个连在一起的数字
\d{,4}匹配小于等于四个的数字
\d{3,}匹配大于等于三个的数字

 注意,0个也是小于三个
注意,0个也是小于三个
|符号的用法
|符号前后连接两个表达式,他匹配到任意一个就会记录下来。
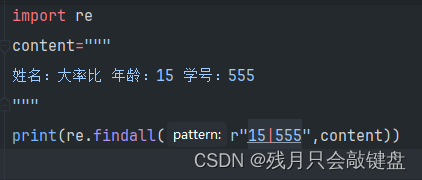

这里寻找15或者555,就是既匹配前面的,又匹配后面的。
\与()的用法
先用()进行分组,然后用\规定与哪一组相同


位置匹配符的使用
^与$的使用

^代表只能匹配开头的hello
$代表只匹配句子末尾的hello

?当然如果^放到了[]里面的话就代表了取反的意思
例如[^a-z]就是匹配不是a-z的字符
\b与\B的使用
\b代表匹配字符在单词的前面
\B代表匹配的字符在单词的中间


\b写在前面代表匹配字符需要在单词前方,在后面代表匹配字符需要再单词后方
(?)的使用方法


re模块的方法的使用
查找功能
查找功能有四个
search只返回一个
match从头开始匹配
findall列表形式返回所有
finditer迭代形式返回
值得注意的是,这里的查找功能除了findall是返回列表之外,其他的都是返回一个对象。
先来个案例看一下他们返回的形式

他们返回的就不是列表了

输出他们匹配的内容
输出是需要用到一个group()的,但是他还有一些更高级的用法。
我们可以对匹配的字符进行分组,然后通过在group中添加参数进行规定输出什么内容

?
?以元组的形式返回内容


返回的内容就是元组了
文本替换功能
文本替换功能常用这两个函数
sub()返回被替换后的内容
subn()以元组形式返回替换后的内容和替换的个数

结果如下

?文本分割功能
文本分割通常使用
split()函数
作用就是根据分割的符号,把分割出来的内容以列表的形式表现出来。
这种是排除法,去除不要的,留下要的,之前的是找出要的。


模式设定
?其实在re的参数中还有一个规定模式的参数可以添加,基本上用的最多的是I,可以忽略大小写进行匹配。


其他的模式在上面总结了。
实战案例
校验用户输入合法案例
利用正则表达判断用户是否攻击我方网站(写的简陋能被绕过。。水平有限)


?提取文本中的重要信息


使用起来十分的爽呢
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 二极管解读:封装与外观、参数意义、发展历史与未来趋势
- 细数语音识别中的几个former
- 浅谈VUE2中实现响应式的原理
- YOLOv8改进 | 融合改进篇 | 轻量化CCFM + SENetv2进行融合改进涨点 (全网独家首发)
- MIML-DA
- 2.4 网络层02
- 数据结构之str类
- 数组排序(从大到小),选择排序法和冒泡排序法
- 【论文简述】Multi-View Guided Multi-View Stereo(IROS 2022)
- 【matlab】绘制竖状单组渐变柱状图