Tensorflow和飞桨Paddle的控制流算子设计
一、概览
注:整体方案上尚存在技术疑点,需进一步小组内讨论对齐,避免方案设计上存在后期难以扩展(或解决)的局限性
| 框架 | TensorFlow 1.x | TensorFlow 2.x | Paddle |
|---|---|---|---|
| cond/while | √ | √ | √ |
| 实现机制 | 组合OP (DataFlow) | 函数式 (Functional) | 函数式 (Functional) |
| 高阶微分 | × | √ | × |
| 并行执行 | √ | × | × |
| 图构造 | 复杂 | 简单 | 简单 |
| 互相嵌套 | √ | √ | √ |
| 维护成本 | 高 | 低 | 低 |
| 执行性能 | 快 | 一般 | 一般 |
| 中间变量保存 | stack | - | step_scope |
| 辅助数据结构 | Frame | - | ConditionBlock |
从接口形态、实现机制上,TensorFlow2.x 的 V2 版本的设计与Paddle 当前的控制流实现非常相似。
以tf.cond为例:
- V2版会通过atuograph模块将true_fn和false_fn分别转为两个FuncGraph子图
- 调用gen_functional_ops模块中 If Op去执行
- If、While的Op注册文件在:
tensorflow/core/ops/functional_ops.cc
二、Paddle 现状
1. 上层 API 接口
1.1 cond 接口
接口形态:def cond(pred, true_fn=None, false_fn=None, name=None):
执行逻辑:
**
Python
# true 分支子block
true_cond_block = ConditionalBlock([pred], is_scalar_condition=True)
with true_cond_block.block():
origin_true_output = true_fn()
# false 分支子block
false_cond_block = ConditionalBlock([logical_not(pred)], is_scalar_condition=True)
with false_cond_block.block():
origin_false_output = false_fn()
# 获取输出
mask = cast(pred, dtype='int32')
merge_func = lambda false_var, true_var : select_input([false_var, true_var], mask)
# 多次的TensorCopy
merged_output = map_structure(merge_func, false_output, true_output)
1.2 switch_case 接口
接口形态:def switch_case(branch_index, branch_fns, default=None, name=None):
执行逻辑:
**
Go
# 原理:借助多个cond的组合
pred_fn_pairs, default = _check_args(branch_index, branch_fns, default)
false_fn = default
for pred, true_fn in pred_fn_pairs:
false_fn = partial(cond, pred=pred, true_fn=true_fn, false_fn=false_fn)
final_fn = false_fn
return final_fn()
1.3 While_loop 接口
接口形态:def while_loop(cond, body, loop_vars, is_test=False, name=None):
执行逻辑:
**
Python
# 构建program
while_loop_block = While(pre_cond, is_test, name)
with while_loop_block.block():
output_vars = body(*loop_vars)
now_cond = cond(*output_vars)
map_structure(assign_skip_lod_tensor_array, output_vars, loop_vars)
assign(now_cond, pre_cond)
return loop_vars
2. 存在的问题
2.1 执行性能尚可优化
对于?conditional_block_op:
-
pred 变量存在 GPU→ CPU 的拷贝(执行期 pred 必须在CPU上)
-
pred 会多余地被cast成一个int32类型的 mask Tensor,用于select_input
- mask 存在 GPU → CPU 的拷贝(执行期 mask 必须在 CPU 上)
-
每次select_input 都存在一个input → output 的数据copy
- 对于中间(将亡值)的Tensor,可以直接move Holder来提升性能
对于?switch_case:
- 由于是通过
cond接口组合实现,则cong存在的问题,switch_case 都存在
对于while_loop:
-
cond 变量存在 GPU→ CPU 的拷贝(执行期 pred 必须在CPU上)
- 若cond的更新是在GPU上,则每个step都会触发一次拷贝
-
Executor子图执行效率待提升,存在重复的Prepare,且不能复用Pass和Fuse
2.2 细粒度调度执行
目前控制流所有的基础算子OP执行时,都依赖于内部的一个Executor,形式上更像一个大Op,与TF V2版本中的If、While、Case Op比较类似。不支持类似TF V1版本中的细粒度组合算子执行。
局限性在于:
- 控制流Block内部的OP无法灵活地复用最外层执行器的调度策略
- 对于多设备、多机扩展性较差,比较难拆分和插入通信Op
三、竞品调研
1. TensorFlow
在 TF 1.x 版本中,主推的是 V1 版本的控制流OP。此版本的?tf.cond、tf.while?的API是借助多个底层核心的 Low-level Op 来实现的,主要包括:
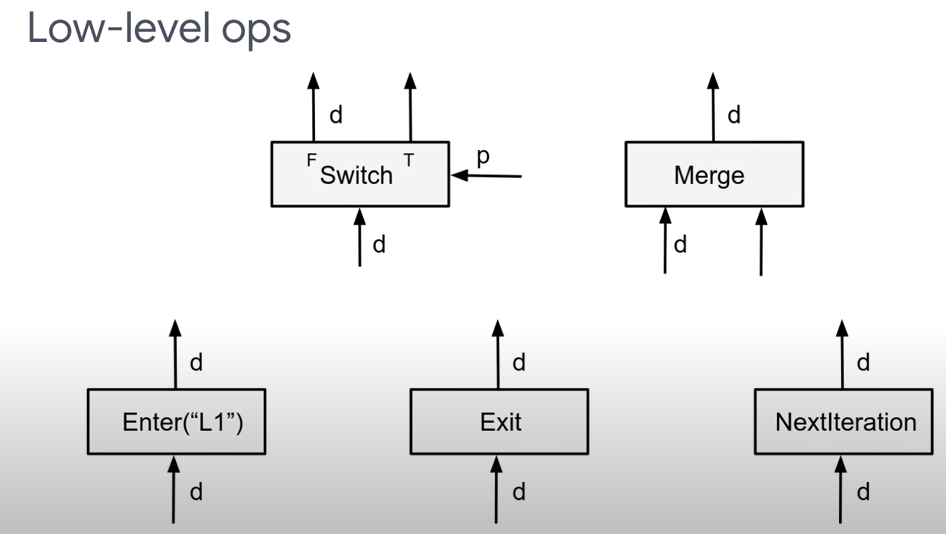
- Op的注册源代码文件:
tensorflow/core/ops/control_flow_ops.cc - OpKernel 定义的文件:
tensorflow/core/kernels/control_flow_ops.h
优点:
- while_loop 支持迭代间的并行执行
- 适合基于DataFlow的执行模型
缺点:
- 图构造时非常复杂,尤其在反向、嵌套控制流的场景;Bug不断,维护成本高
- 无法支持高阶微分
- 存在一定的性能问题;Dead Tensor 和 Frame引入了额外的开销
- 很难做图分析(如 auto-clustering)
- 很难在XLA中进行模式匹配
基于上面的考量,TF引入了 V2 版本的控制流实现:
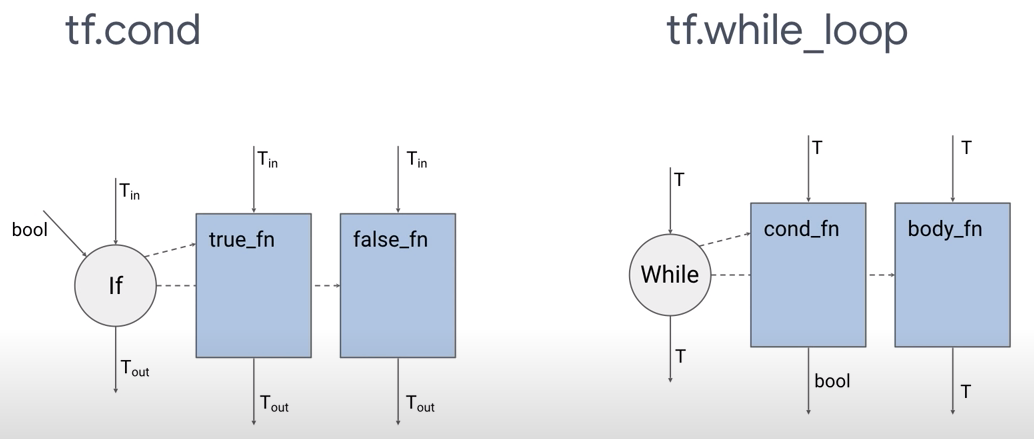
V2版本的API接口源码文件:tensorflow/python/ops/cond_v2.py
Kernel 定义的源文件:tensorflow/core/kernels/functional_ops.cc
- IfOp
- State
优点:
-
支持高阶微分
-
更方便地集成XLA/TPU
-
更简洁的图构造逻辑
- 更好的错误信息提示和管理
- BUG更少,更易于维护
-
简化执行(Simpler execution)
缺点:
-
基于函数式的Op性能比DataFlow方式要略差(解决方案:lower to V1 版本)
- 严格执行:即所有的输入必须都是Ready状态后才会触发执行
- 无迭代间的并行机制
- 需要特殊逻辑实现剪枝
1.1 核心Op功能
1.1.1 Switch Op
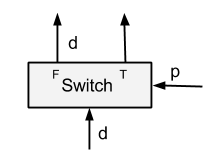
功能:根据?
P?值(False/True)将单输入的Tensor?d?从某个分支输出,另一个分支输出?Dead Tensor。
- 输入:P (判断量) 、d(输入Tensor)
- 输出:两个Tensor(分别对应 T、F分支)
- 反向:
Merge(For cond),NextIteration+Merge?(For while)
**
Switch(p, d) = (r1, r2) :
r1 = (value(d), p || is_dead(d), tag(d))
r2 = (value(d), !p || is_dead(d), tag(d))
Kernel 实现:
**
C++
void SwitchOp::Compute(OpKernelContext* context) {
const Tensor& outputPorts = context->input(1);
bool pred = outputPorts.scalar<bool>()();
int port = (pred) ? 1 : 0;
if (context->input_is_ref(0)) { // 传递引用
context->forward_ref_input_to_ref_output(0, port);
} else { // 数据copy
context->set_output(port, context->input(0));
}
}
1.1.2 Merge Op

功能:接受多个输入Tensors,输出其中的一个非Dead Tensor。
- 输入:多个Tensors,但要求有且仅有一个非Dead Tensor(否则存在未定义行为)
- 输出:唯一的 非Dead Tensor
- 反向:
Switch
**
Bash
Merge(d1, d2) = r :
r = if is_dead(d1) then d2 else d1
1.1.3 Enter Op
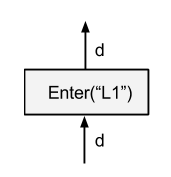
功能:将一个输入Tensor 添加到一个执行Frame中(异步地;一个Frame可对应多个Enter,当第一个Enter被执行时,会触发此Frame的实例化)
- 输入:一个Tensor,将被传入 Execution Frame中使用
- 输出:一个Tensor
- 反向:
Exit
**
Enter(d, frame_name) = r :
value(r) = value(d)
is_dead(r) = is_dead(d)
tag(r) = tag(d)/frame_name/0
kernel实现:
**
CSS
void EnterOp::Compute(OpKernelContext* context) {
if (IsRefType(context->input_dtype(0))) {
context->forward_ref_input_to_ref_output(0, 0);
} else {
context->set_output(0, context->input(0));
}
}
1.1.4 Exit Op

功能:将一个执行Frame 中的Tensor 传出到上级父Frame中,常用于子Frame中传递Tensor到父Frame(一个Frame可以对应多个Exit,当其输入是available时,会立即触发Exit的执行)
- 输入:子Frame中的源Tensor
- 输出:传入到父Frame中的 Tensor(对应于更新后的
loop_vars中的各个Tensor) - 反向:
Enter Op
**
Bash
Exit(d) = r :
value(r) = value(d)
is_dead(r) = is_dead(d)
tag(r) = tag1 where tag(d) = tag1/frame_name/n
Kernel实现:
**
CSS
void ExitOp::Compute(OpKernelContext* context) {
if (IsRefType(context->input_dtype(0))) {
context->forward_ref_input_to_ref_output(0, 0);
} else {
context->set_output(0, context->input(0));
}
}
1.1.5 NextIteration Op

功能:将当前的执行Frame的 Tensor 传递到下一个迭代(一个执行Frame中可能会有多个NextIteration;当Frame执行第N轮时的第一个NextIteration时,TF就可以开始执行N+1轮的迭代了)
- 输入:Frame的上一轮待迭代的 Tensor(对应于
loop_vars中的各个Tensor) - 输出:Frame的下一轮需要的 Tensor
- 反向:
Identity
**
Bash
NextIteration(d) = d1:
value(d1) = value(d)
s_dead(d1) = is_dead(d)
tag(d1) = tag1/frame_name/(n+1) where tag(d) = tag1/frame_name/n
Kernel实现:
**
CSS
void NextIterationOp::Compute(OpKernelContext* context) {
if (IsRefType(context->input_dtype(0))) {
context->forward_ref_input_to_ref_output(0, 0);
} else {
context->set_output(0, context->input(0));
}
}
1.1.6 Dead Tensor的作用
在TF中,OpKernel的输入是通过?OpKernelContext::Params?来管理的:
**
C++
class OpKernelContext{
struct Params {
// ... (省略其他)
// Inputs to this op kernel.
const gtl::InlinedVector<TensorValue, 4>* inputs = nullptr;
bool is_input_dead = false;
// ....
};
// For control flow.
FrameAndIter frame_iter() const { return params_->frame_iter; }
bool is_input_dead() const { return params_->is_input_dead; }
};
// Graph Node 相关
struct NodeItem {
// The index of this node's item in its GraphView.
int node_id = -1;
bool is_merge : 1; // True iff IsMerge(node)
bool is_enter : 1; // True iff IsEnter(node)
// ...
};
// 执行器相关:ExecutorState::PrepareInputs
// Before invoking item->kernel, fills in its "inputs".
{
switch (entry->state) {
case Entry::State::NO_VALUE:
// 把的第 i 个输入设置为 空Tensor对象:new Tensor, 1-D, 0 element tensor.
inp->tensor = const_cast<Tensor*>(kEmptyTensor);
*is_input_dead = true;
}
}
// 执行器执行流程 ExecutorState::Process, 拓扑序执行
Procss(){
while(){
// ..(省略)
// Only execute this node if it is not dead or it is a send/recv
// transfer node. For transfer nodes, we need to propagate the "dead"
// bit even when the node is dead.
bool launched_asynchronously = false;
if (tagged_node.get_is_dead() && !item.is_transfer_node) {
if (outputs.size() < item.num_outputs) outputs.resize(item.num_outputs);
} else if (TF_PREDICT_FALSE(item.is_noop)) {
ProcessNoop(stats);
} else if (item.const_tensor != nullptr && !params.track_allocations) {
ProcessConstTensor(item, &outputs, stats);
} else {
// Prepares inputs.
bool is_input_dead = false;
s = PrepareInputs(item, first_input, &inputs, &input_alloc_attrs, <-------这里
&is_input_dead);
if (!s.ok()) {
// Clear inputs.
const int num_inputs = item.num_inputs;
for (int i = 0; i < num_inputs; ++i) {
(first_input + i)->ClearVal();
}
propagator_.MaybeMarkCompleted(tagged_node);
// Continue to process the nodes in 'inline_ready'.
completed = NodeDone(s, &ready, stats, &inline_ready);
continue;
}
if (item.kernel_is_async) { <----异步
ProcessAsync(item, params, tagged_node, first_input, stats);
launched_asynchronously = true;
} else { <------- 同步
s = ProcessSync(item, ¶ms, &outputs, stats);
}
}
}
对于所有 非控制流的OP,执行的逻辑是:
**
Python
Op(d1, …, dm) = (r1, …, rn) :
value(ri) = Op.Compute(value(d1), …, value(dm)) if !is_dead(ri)
is_dead(ri) = any(is_dead(d1), … is_dead(dm)), for all i
tag(ri) = tag(d1), for all i
优点:
- Tensor的 Dead 状态可以传递,利于支持多机的控制流实现
- 非控制流的Op的输入必须满足都不是Dead Tensor才会真正执行
缺点:
- is_dead() 会引入额外的判断开销,有损性能
- 所有的OP都要维护 is_dead 逻辑,耦合性强
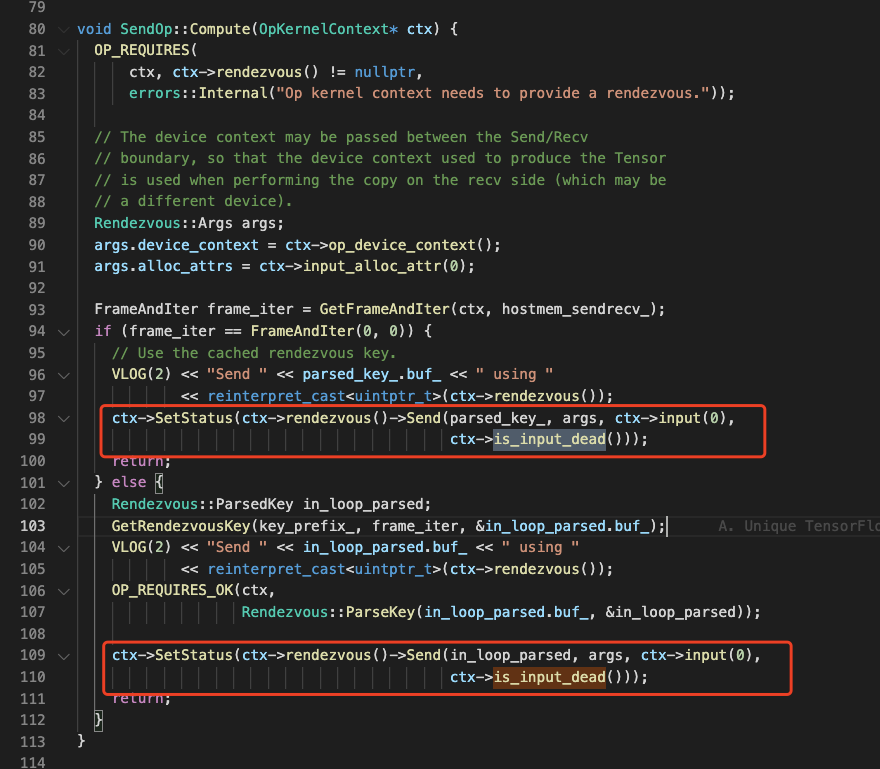
对于多机的?Send?和?Recv?两个OP,也会对 Dead Tensor 进行处理(只有Send处理了):
1.2 Cond 高层API实现
接口源码实现:tensorflow/python/ops/control_flow_ops.py
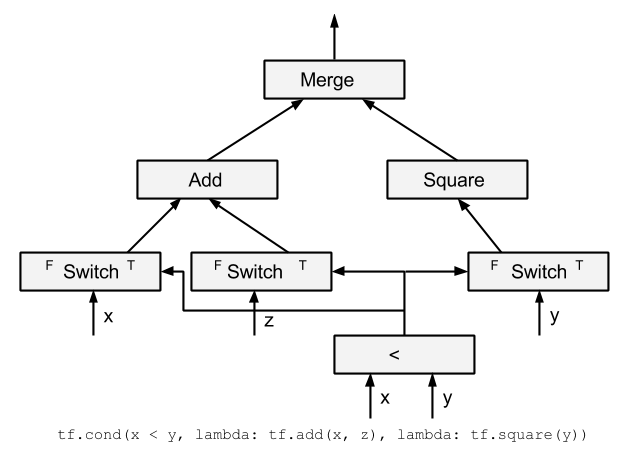
**
CSS
def cond(pred, true_fn, false_fn, name):
with ops.name_scope(name, "cond", [pred]):
p_2, p_1 = switch(pred, pred)
pivot_1 = array_ops.identity(p_1, name="switch_t")
pivot_2 = array_ops.identity(p_2, name="switch_f")
pred = array_ops.identity(pred, name="pred_id")
context_t = CondContext(pred, pivot_1, branch=1)
try:
context_t.Enter()
orig_res_t, res_t = context_t.BuildCondBranch(true_fn)
if orig_res_t is None:
raise ValueError("'true_fn' must have a return value.")
context_t.ExitResult(res_t)
finally:
context_t.Exit()
context_f = CondContext(pred, pivot_2, branch=0)
try:
context_f.Enter()
orig_res_f, res_f = context_t.BuildCondBranch(false_fn)
if orig_res_f is None:
raise ValueError("'false_fn' must have a return value.")
context_f.ExitResult(res_f)
finally:
context_f.Exit()
res_t_flat = nest.flatten(res_t, expand_composites=True)
res_f_flat = nest.flatten(res_f, expand_composites=True)
merges = [merge(pair)[0] for pair in zip(res_f_flat, res_t_flat)]
return merges
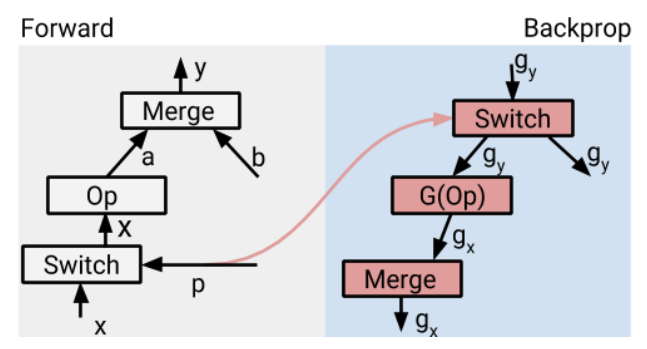
1.2.1 Auto-Gradient
反向的形式:cond(p, g_fn1, g_fn2)
1.2.2 V2 版本的If Op
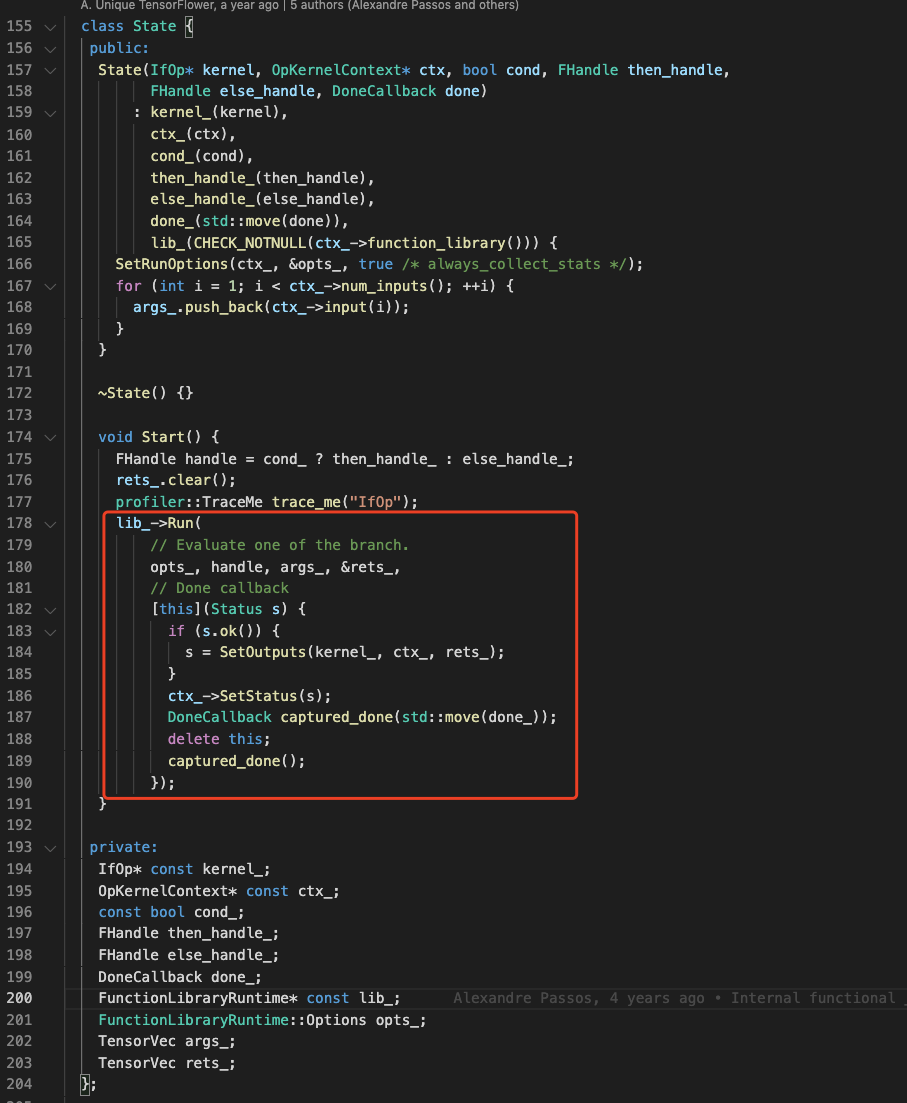
V2 版本中,TF在后端实现了一个IfOp,用于执行前端传递过来的 true_fn 和 false_fn。
Kernel 源码定义文件:tensorflow/core/kernels/functional_ops.cc
- 继承自?
AsyncOpKernel,重写了ComputeAsync?函数 - 实际执行逻辑封装在?
State->Start()中
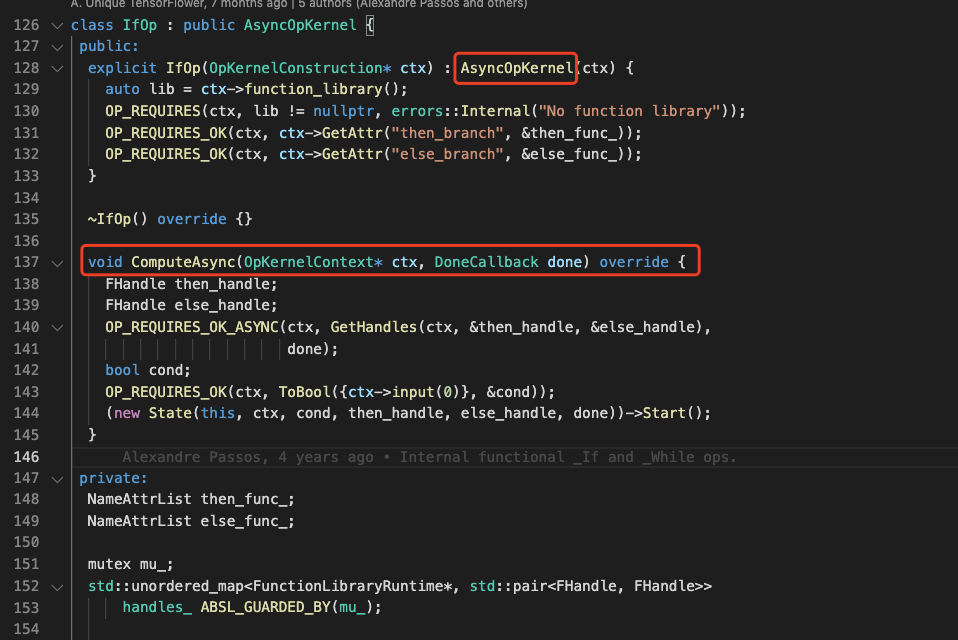
State 是一个内部类,用于If/While/Case Op的实际执行:FunctionLibraryRuntime
1.3 While 高层API实现
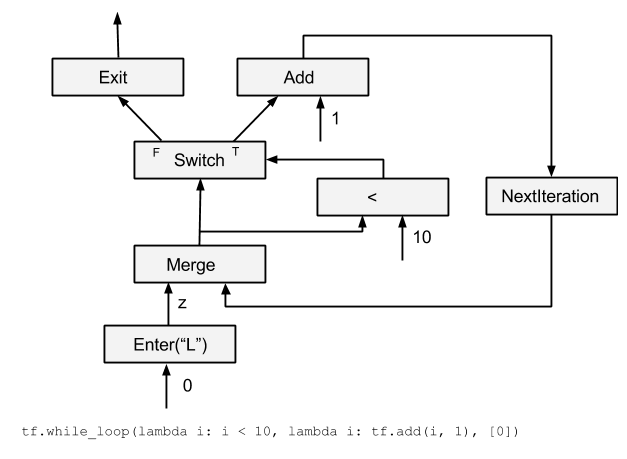
1.3.x Auto-Gradient
反向的形式:
**
Python
def pred(i,_): return i < N
while_loop(pred, g_body, [0] + g_vars)
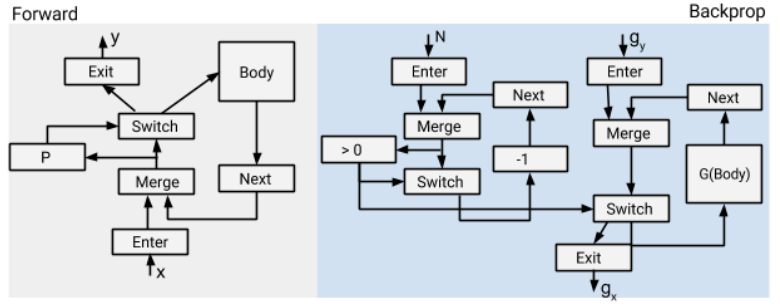
需要处理的关键点:
-
反向G(Body)中可能会用到前向产生的中间Tensor,需要把每一步的中间Tensor都记录下来
- 引入了异步的内存交换技术,解决GPU上内存资源过度占用问题
-
在静态组网期间,N是未知的(这个会影响什么呢?)
对与上述第一点,TF引入了stack的概念,将反向必须的中间变量随着iter入栈。(TF 将push与Op执行异步了起来,避免stack引入过多的性能开销)

对于上述第二点,TF在while_loop的前向中引入了子图,专门做N的动态计算,然后可以自动生成反向:

1.4 多硬件的支持
TF 借助?device placement自动地对graph进行子图切分,每种设备上一个子图。在不同设备上子图的有连接的边上,分别插入成对的send?和?recv算子(通过unique key关联)
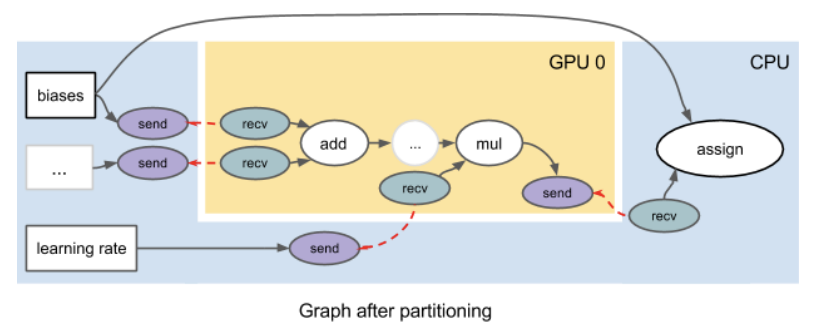
对于不含控制流的Graph,只要按照拓扑序将所有的OpNode都执行一遍即可。但是控制流引入了一些新的变化:
-
每个Op可能被执行多次,也可能被执行0次
-
Tensor 需要额外的信息标记,在TF中被表示为元组:
(value, is_dead,tag)- value:Tensor实际的数据
- is_dead:是否来自一个未被执行的分支
- tag:唯一标识?也用来标记send/recv的成对信息(因为他俩可能要执行多次,必须保证执行的次数是对应的)
1.5 多机的支持
1.5.1 Switch 多机
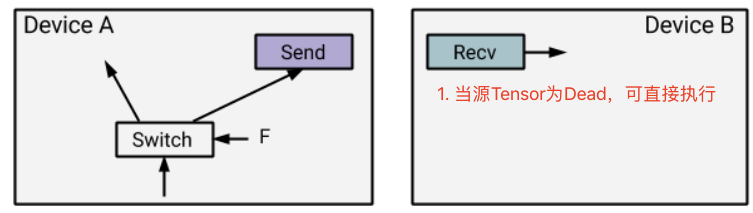
如下图的Switch,设备A中若Send是False分支,则直接可以产出一个Dead Tensor,只需要将Dead状态传递到设备B。此时设备B上Recv Op的下游Op可以立即执行(传递Dead)
1.5.2 While 多机
对于多机While_loop,简单的插入成对的 Send-Recv 算子并不能实现多机间执行。因为设备B并不知道Op是来自一个while的body_func,因此可能只会执行一次就退出了,无法实现循环的效果。

解决方案:TF在设备B中引入了一个
控制流状态机,其中Enter固定接受输入0。
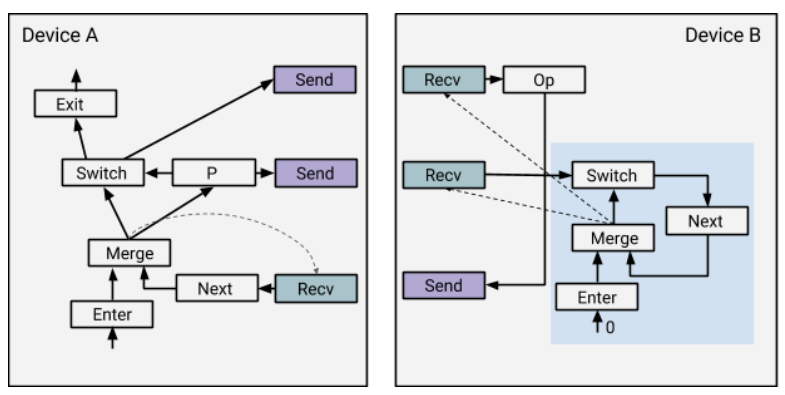
下面举一个执行 0 次的栗子:
- 在
设备A上,从Enter开始执行,因为 P 是False,所以Switch的False分支直接输出loop_vars到Exit,退出循环。同时Switch的True分支关联一个Send,发送Dead Tensor;P 也关联一个Send,发送值为False的 非Dead Tensor - 在
设备B上,也开始从Enter开始执行,继而执行Merge(随后触发两个Recv的执行),Switch的Recv接受False Tensor,导致Next为Dead Tensor;Op的Recv接受Dead Tensor,传播状态到Send。此时设备B已无Op可执行 - 回到
设备A, Next的Recv接受Dead Tensor,开始执行Next,此时设备A已无Op可执行 - 注意:图中的虚线表示依赖边;
Next遇到Dead Tensor后会停止此状态的传播
嵌套的while如何插入control-loop状态机?
TODO: 需要厘清方案

1.5.3 对于并行机制的优势
- 上述设备B一旦接受到传过来的 P 变量就可以开启下一轮迭代或执行Exit。
- 两个设备可以同时执行同一个Loop的不同轮次的body_fn
- 多机之间开销主要在于需要等待前序设备产出的 P 变量;由于并行机制,这个部分等待可以overlap起来(???)
四、技术方案
此方案主要涉及对底层的控制流Op执行机制重新设计,拆分为细粒度的组合Op
1. Switch
1. 基础算子 OP 扩展
新方案依赖 6 个基础的算子 OP:
| 前向算子 | 特点 | 反向 | 需求的Op | 计划 |
|---|---|---|---|---|
| enter | 单输入、单输出 | exit | cond、while | 一期 |
| exit | 单输入、单输出 | enter | cond、while | 一期 |
| switch | 双输入、双输出 | merge 或 next_iteration + merge | cond、while | 一期 |
| merge | 多输入、单输出 | switch | cond、while | 一期 |
| next_iteration | 单输入、单输出 | identity | while | 二期 |
| identity | 单输入、单输出 | - | next_iteration | 二期 |
2. Dead Tensor 引入?
由于 switch 和 merge 算子的引入,导致Op的输出类型新增了一个 Dead 状态,用于下游False 分支的?伪执行。
但若在框架侧所有的OP执行中都引入一个Dead Tensor,影响面巨大。且从TF的历史经验来看,这个会引入些许性能开销。
Question:是否可以在满足现有技术方案设计需求的前提下,避免对 Dead Tensor的引入?
TODO:调研中(目前暂无明确的替代方案)
3. 互相嵌套机制
支持不同控制流相互嵌套是框架完备性的重要诉求。Paddle目前的实现是通过Block的嵌套机制来实现的,逻辑简洁,易于维护。
从目前TF的材料和经验来看,V1 版本虽然也支持了互相嵌套机制,但付出了比较大的代价。V1版本在遇到嵌套 case的场景时,维护成本与嵌套层级非线性递增,BUG可能性较高(TF内部视频提到此点)
4. 接口实现
以?cond_op?为例:
CSS
def cond(pred, true_fn, false_fn, name):
with static.name_scope(name):
p_2, p_1 = control_flow.switch(pred, pred)
pivot_1 = control_flow.identity(p_1, name="switch_t")
pivot_2 = control_flow.identity(p_2, name="switch_f")
pred = control_flow.identity(pred, name="pred_id")
context_t = CondContext(pred, pivot_1, branch=1)
with context_t:
orig_res_t, res_t = context_t.BuildCondBranch(true_fn)
context_t.ExitResult(res_t)
context_f = CondContext(pred, pivot_2, branch=0)
with context_f:
orig_res_f, res_f = context_t.BuildCondBranch(false_fn)
context_f.ExitResult(res_f)
res_t_flat = nest.flatten(res_t, expand_composites=True)
res_f_flat = nest.flatten(res_f, expand_composites=True)
merges = [control_flow.merge(pair)[0] for pair in zip(res_f_flat, res_t_flat)]
return merges
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!