高性能索引策略
前言
某开发曾说过,建好索引是高效的第一步,然而没用好索引,就等于第一步白费了。下面我们针对索引的使用策略进行简单介绍。
一. 独立的列
如果查询中的列不是独立的话,Mysql 就无法使用索引。“独立的列” 是指索引列不能是表达式的一部分,也不能是函数参数。
例如,下面这个查询就无法使用 actor_id 列的索引:
SELECT actor_id FROM actor Where actor_id + 1=5;
虽然我们很容易就知道 Where 中的表达式其实等价于 actor_id = 4, 但是Mysql 无法自动解析这个方程式。这完全是用户行为。我们应该简化 Where 条件的习惯,始终将索引列单独放在比较符号的一侧。
下面的日期比较也是常见的错误 (函数参数):
SELECT ... WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(date_col) <= 10;
二. 前缀索引和索引选择性
有时候需要索引很长的字符列,这会让索引变的大且慢。一种方法是使用前面说的模拟哈希索引的方式, 但是这种方式比较单一,对于多变的问题往往是不够的。那我们改如何处理呢?
2.1 概念
前缀索引是指截取字符串的开始部分,这样可以大大节约索引空间,从而提高索引效率。但如何选择合适的索引长度呢,这就牵扯到了索引选择性的问题。选择性是指,不重复的索引值 (也称为基数) 和数据表的记录总数 (T) 的比值,范围从 1/T 的 1 之间。索引的选择性越高则查询效率越高,因为选择性高的索引可以让 Mysql 在查找时过滤掉更多的行。唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
2.2 案例
前缀索引的最佳实践可以总结为选择足够长的前缀以保证较高的选择性,同时又不能太长 (以便节约空间)。就是前缀索引的选择性要接近于索引整个列。
构建数据
CREATE TABLE sakila.city_demo(city VARCHAR(50) NOT NULL);
-- 随机插入一些城市(其中每个城市会存在多个,且次数是不同的)
查询每个城市出现次数
SELECT COUNT(*) AS cnt, city FROM sakila.city_demo
GROUP BY city
ORDER BY cnt DESC
LIMIT 10;
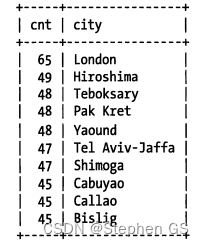
可以看到,上面每个值都出现了45~65次。现在查找最频繁出现的城市前缀,先从3个字母前缀开始:
SELECT COUNT(*) AS cnt, LEFT(city,3) AS pref
FROM sakia.city_demo
GROUP BY pref ORDER BY cnt DESC
LIMIT 10;
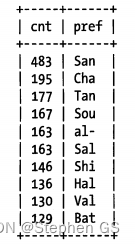
可以看出每个前缀都比原来的城市出现次数更多了,那么这样的选择性肯定是不达标的。我们增加前缀程度,直到这个前缀的选择性接近完整列的选择性。经过实现,我们直到增加到长度为7时,才发现比较合适:
SELECT COUNT(*) AS cnt, LEFT(city,7) AS pref
FROM sakia.city_demo
GROUP BY pref ORDER BY cnt DESC
LIMIT 10;
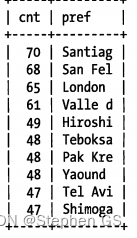
从上面城市前缀出现的次数,不难看出长度为7较为合适。
但每次循环地去看某个前缀长度出现的值均不均匀还是比较麻烦的,有什么通用的方式吗?
2.3 计算前缀索引长度的通用方式
我们可以先计算出完整列的选择性,并通过比较不同长度前缀列的值,选出最逼近这个选择性的长度。
完整列的选择性
SELECT COUNT(DISTINCT city) / COUNT(*)
FROM sakila.city_demo;

通常来说,这个例子中如果前缀的选择性能够接近于 0.031, 基本上就可用了。可以在一个查询中针对不同前缀长度进行计算,这对于大表非常有用。
不同前缀长度的选择性
SELECT COUNT(DISTINCT LEFT(city,3)) / COUNT(*) AS sel3,
COUNT(DISTINCT LEFT(city,4)) / COUNT(*) AS sel4,
COUNT(DISTINCT LEFT(city,5)) / COUNT(*) AS sel5,
COUNT(DISTINCT LEFT(city,6)) / COUNT(*) AS sel6,
COUNT(DISTINCT LEFT(city,7)) / COUNT(*) AS sel7,
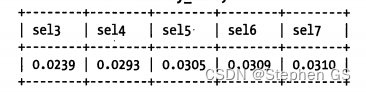
查询显示当前缀长度到达7的时候,再增加前缀长度,选择性提升的幅度已经很小了。
只看平均选择性是不够的,也有例外的情况,需要考虑最坏情况下的选择性。平均选择性让你认为前缀当度为4或者5的索引已经足够了,但如果数据分布很不均匀,可能就会有陷阱。如果观察前缀为4的最常见出现城市的次数,可以看到明显不均匀
SELECT COUNT(*) AS cnt, LEFT(city, 4) AS pref
FROM sakila.city_demo
GROUP BY pref ORDER BY cnt DESC
LIMIT 5;

如果前缀是4个字节,则最常见的前缀的出现次数比最少出现的前缀次数大了很多。如果有比这个随机生成的示例更真实的数据,就更有可能看到这种现象。例如在真实的城是名上建一个长度为4的前缀索引,对于以 “San” 和 “New” 开头的城市选择性就会非常糟糕,因为很多城市都以这两个词开头。
上面已经选择了合适的长度,那么如何创建前缀索引
ALTER TABLE sakila.city_demo ADD KEY (city(7));
前缀索引是一种能使索引更小,更快的有效办法,但另一方面也有其缺点:Mysql 无法使用前缀索引做 ORDER BY 和 GROUP BY, 也无法使用前缀索引做覆盖扫描。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!