3.4.1-欠拟合 与 过拟合(Bias and variance) + 相关解决方案
3.4.1 欠拟合与过拟合 + 相关解决方案
1、定义
我们给出过拟合的定义:
Overfitting : If we have too many features, the learned hypothesis may fit the training set vey well, but fail to generalize to new examples.
例子1:线性回归(房价预测)
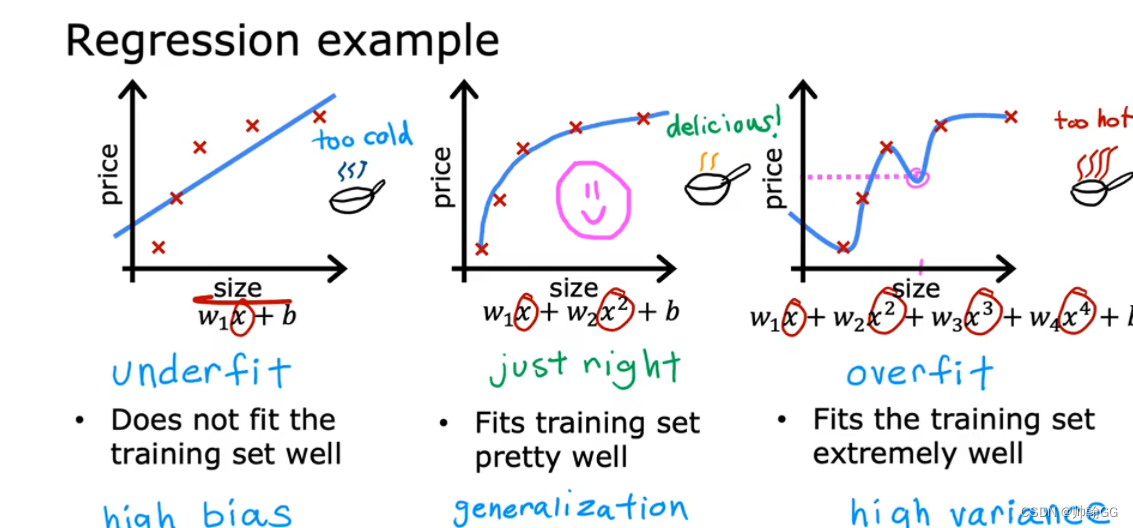
?
- 第一个图:是**“欠拟合”** (训练的特征输入较少(X1,X2,X3…房屋面积,房屋层数,房屋年龄)或缺乏复杂性而导致欠拟合),预测出来的数据有很大的误差,拟合不足(underfit)(尤其是在最后几个数据中,实际数据趋于平缓,而我们的预测线还是升高的)—— 展示出来的结果就是:数据具有 “高偏差”
- 第二个图:是我们合理假设的一个模型。可以看到,选取了合理的模型后,图像大致穿过了样本点。像极了做物理实验时,最后用一条曲线大致地穿过既定的样本点;和第一张图比起来,至少损失值大大下降了。 具有很好的 ——“泛化能力”
- 第三个图:是 “过拟合”,过拟合是指训练误差和测试误差之间的差距太大。换句话说,就是模型复杂度高于实际问题,模型在训练集上表现很好,但在测试集上却表现很差。模型对训练集"死记硬背"(记住了不适用于测试集的训练集性质或特点),没有理解数据背后的规律,泛化能力差。
例子2:Logistic回归

Fig2.Logistic regression(截屏自吴恩达机器学习)
三幅图哪个更好呢?不多说,第二张图应该是合理的划分方式,而不是像第三张图那样一板一眼。
为什么会出现过拟合现象?
造成原因主要有以下几种:
1、训练数据集样本单一,样本不足。如果训练样本只有负样本,然后那生成的模型去预测正样本,这肯定预测不准。所以训练样本要尽可能的全面,覆盖所有的数据类型。
2、训练数据中噪声干扰过大。噪声指训练数据中的干扰数据。过多的干扰会导致记录了很多噪声特征,影响了真实输入和输出之间的关系。
3、**模型过于复杂。**模型太复杂,已经能够“死记硬背”记下了训练数据的信息,但是遇到没有见过的数据的时候不能够变通,泛化能力太差。我们希望模型对不同的模型都有稳定的输出。模型太复杂是过拟合的重要因素。
如何解决 过拟合 + 欠拟合 问题
为什么会出现过拟合现象?
造成原因主要有以下几种:
1、“训练数据集样本单一,样本不足”:
如果训练样本只有负样本,然后那生成的模型去预测正样本,这肯定预测不准。所以训练样本要尽可能的全面,覆盖所有的数据类型。
2、训练数据中噪声干扰过大:
噪声指训练数据中的干扰数据。过多的干扰会导致记录了 很多噪声特征 ,忽略了真实输入和输出之间的关系。
3、模型过于复杂:
模型太复杂,已经能够“死记硬背”记下了训练数据的信息,但是遇到没有见过的数据的时候不能够变通,泛化能力太差。我们希望模型对不同的模型都有稳定的输出。模型太复杂是过拟合的重要因素。
我们会从 以上三种情况分别提出解决方案
- 吴恩达给出的解决方案概要:

3.4.2 解决过拟合+欠拟合问题(包含正则化方法)
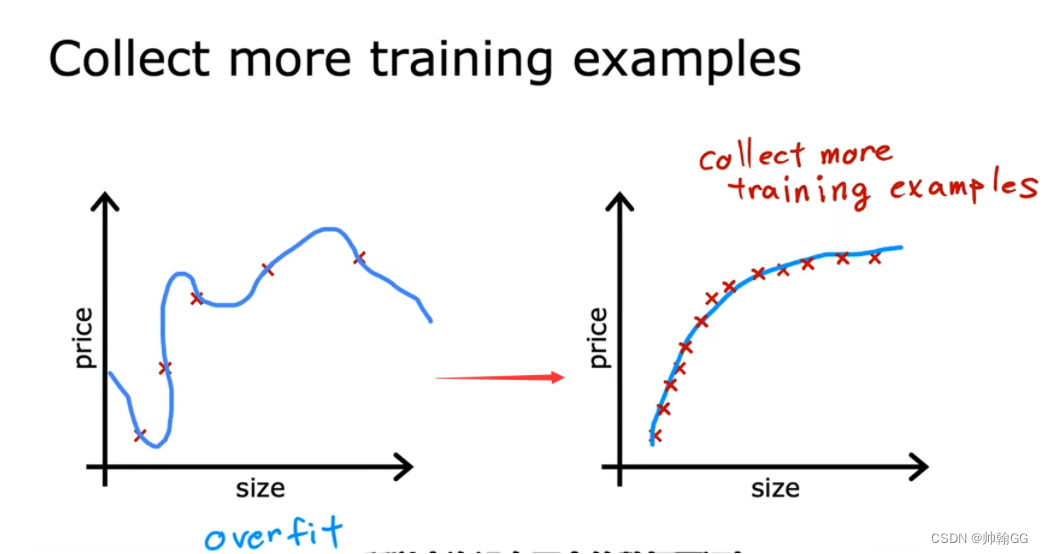
方法一:增大训练集数据的数量
像打钉子一样,钉子(训练集中的数据)多了,绳子(拟合后的回归线)怎么缠绕都是这样的。第一个图钉子打少了,绳子可能出现其他缠绕的方式了
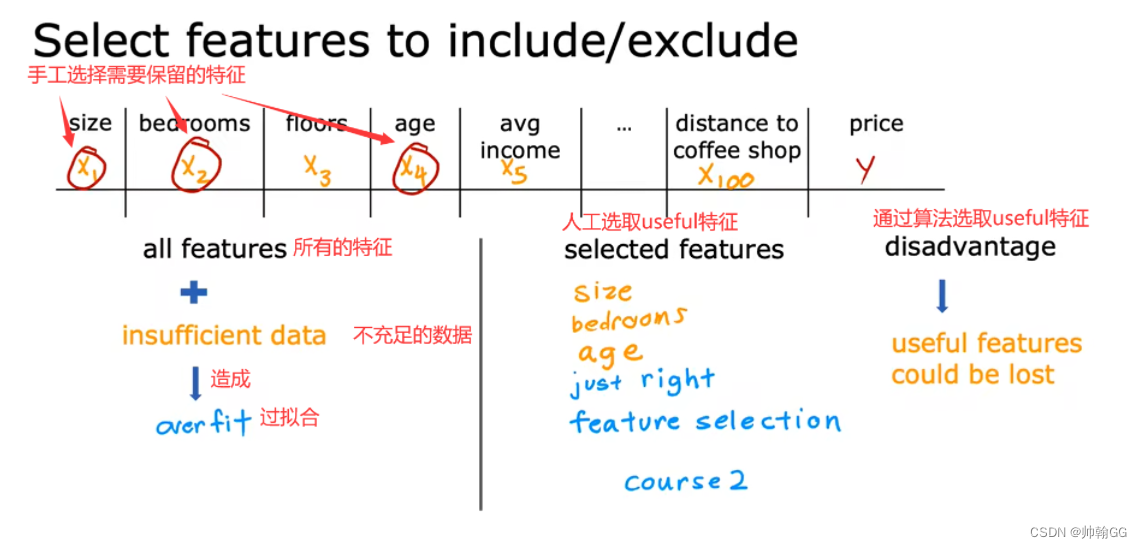
方法二:减少属性值(特征值)的数量
- 人工选择哪些特征需要保留。
- 使用模型选择算法。
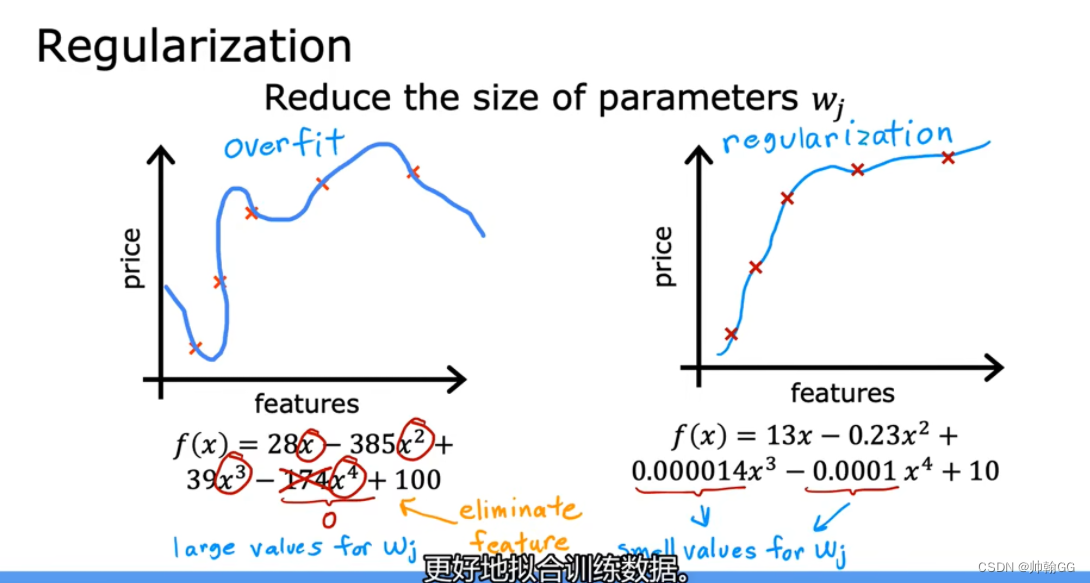
※方法三:正则化
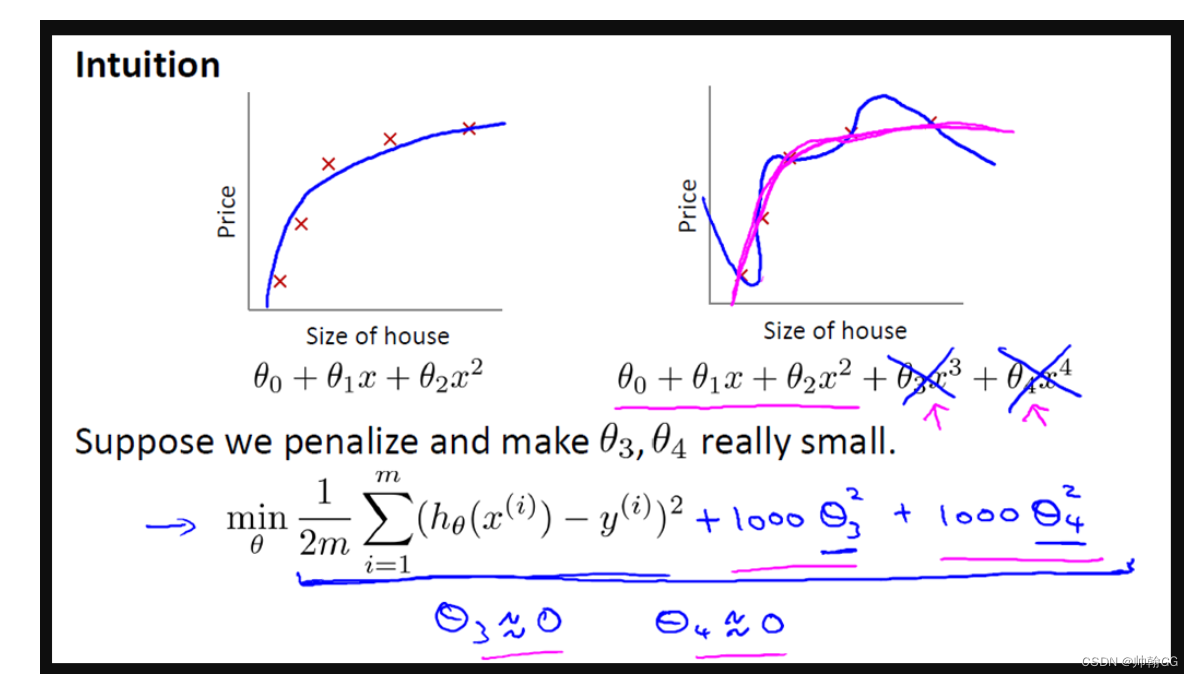
- 正 则化是更温和的减少某些特征的影响的(不是直接把参数w赋值为0的)
- 如下图,X^4的影响是很大的,想要减少这样的影响,正则化不是直接把他的系数W赋值为0,而是如0.0001,防止它产生过大的影响
- 正则化背后的想法:
- 1000 只是我随便写的某个较大的数字而已。现在,如果我们要最小化这个函数,那么为了最小化这个新的代价函数,我们要让 θ3 和 θ4 尽可能小。因为,如果你在原有代价函数的基础上加上 1000 乘以 θ3 这一项 ,那么这个新的代价函数将变得很大,所以,当我们最小化这个新的代价函数时, 我们将使 θ3 的值接近于 0,同样 θ4 的值也接近于 0,就像我们忽略了这两个值一样。如果我们做到这一点( θ3 和 θ4 接近 0 ),那么我们将得到一个近似的二次函数。
- 如果参数的值更小,那么这一点就有点像有一个更简单的模型(或许是特征少一个),因此不容易过度拟合
- 使过拟合的线变得 平滑
- 正则化惩罚的特征是所有的特征参数 W0 ~ Wn
[实际上,这些参数的值越小,通常对应于越光滑的函数,也就是更加简单的函数。因此 就不易发生过拟合的问题。]:
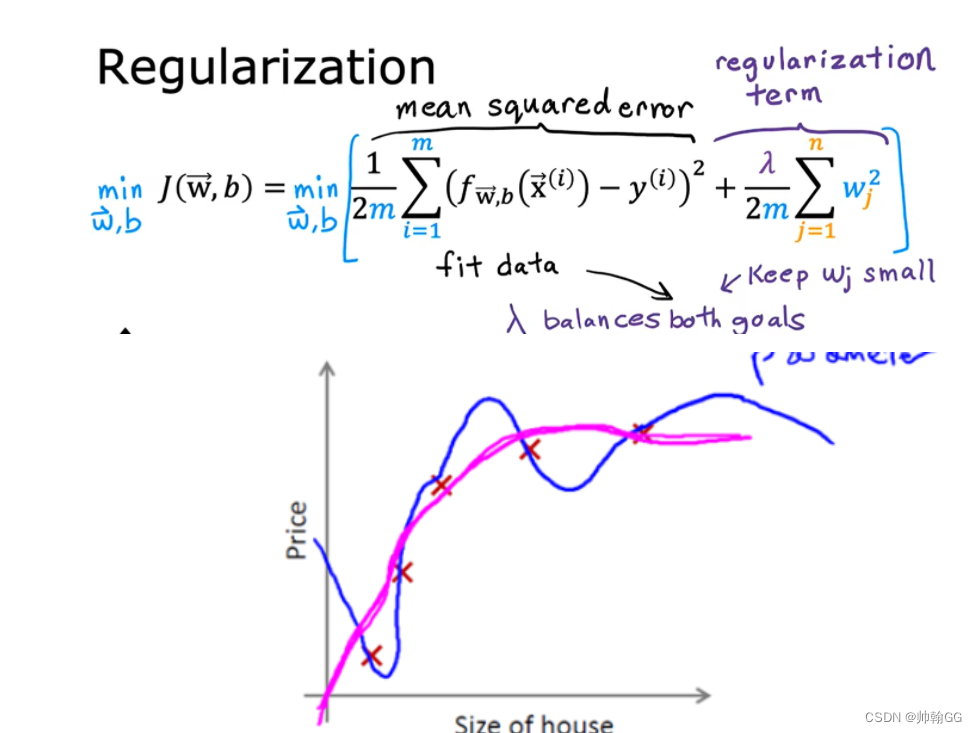
- 损失函数如下:
- 但是按照惯例,通常情况下我们还是只从 θ1 到 θn 进行正则化。
- J(S)是损失函数
-
下面的这项就是一个正则化项
-
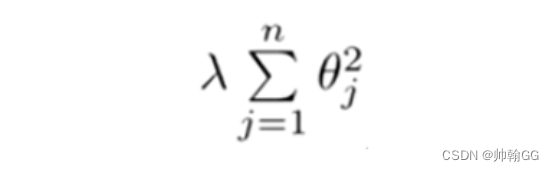
-
并且 λ 在这里我们称做正则化参数。
λ 要做的就是控制在两个不同的目标中的平衡关系。
-
**第一个目标就是我们想要训练,使假设更好地拟合训练数据。**我们希望假设能够很好的适应训练集。
-
而第二个目标是我们想要保持参数值较小。(通过正则化项)
-
-
**极端一:λ特别小的时候:例如 λ = 0 **
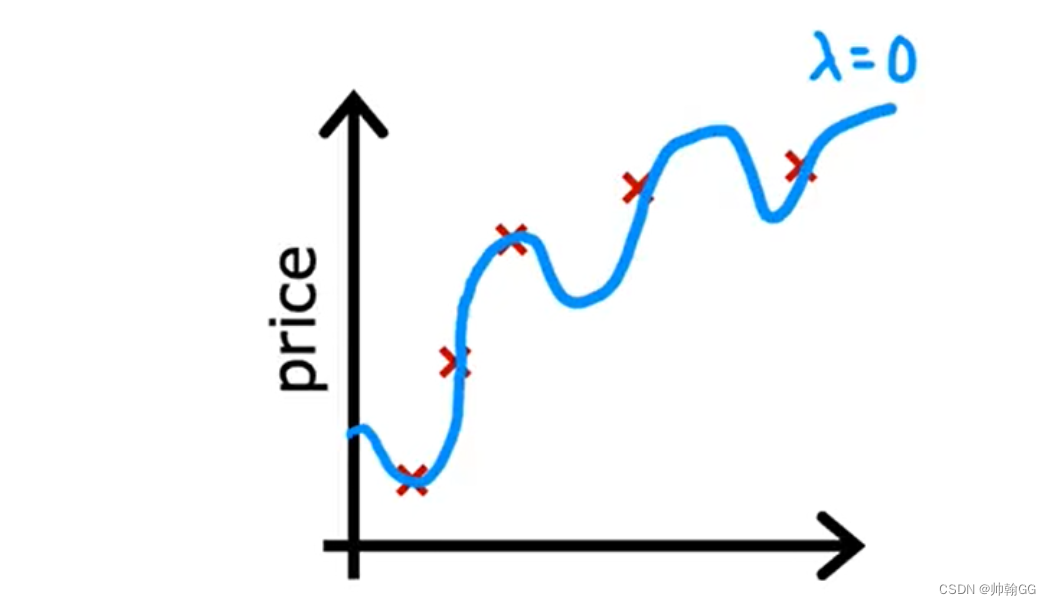
-
极端一:λ特别小的时候:例如 λ = ∞
- 这时候 为了减少λ带来的影响,W0 ~ Wn 都近似0。那么就变成了一条 y = b 的直线
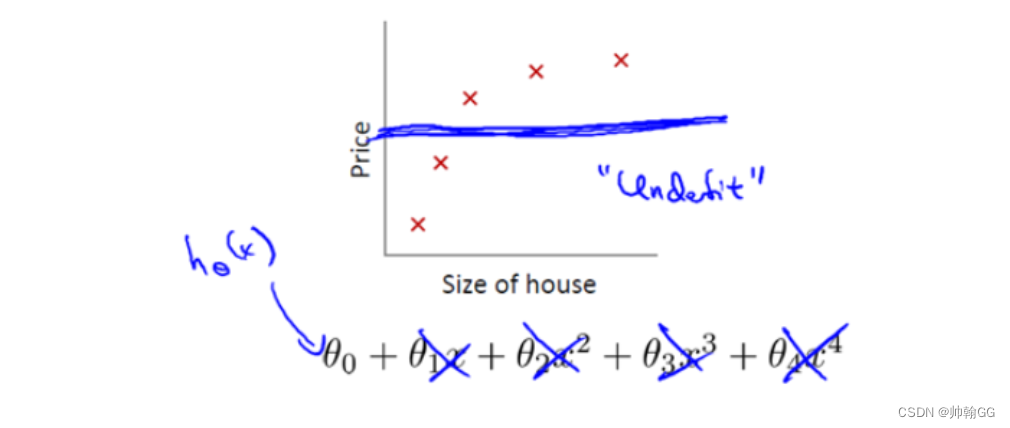
2、解决欠拟合问题
- 方法一:增加 更多的输入特征
- 方法二:增加多项式特征(x1^2 ; x2^2 ; x1*x2 )
- 方法三:在正则化中,增大λ的值
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【VS Code开发】使用Live Server搭建MENJA小游戏并发布至公网远程访问
- 迭代器与生成器
- 脑耗材销售系统(JSP+java+springmvc+mysql+MyBatis)
- 【添加墨水注意事项]
- PHP新潮流:教你如何用Symfony Panther库构建强大的爬虫,顺利获取TikTok网站的数据
- 市场复盘总结 20240113
- HarmonyOS —— SM3 摘要计算
- 韵达速递查询,韵达速递单号查询,并进行揽收中转延误分析
- 系统设计 - 我们如何通俗的理解那些技术的运行原理 - 第三部分:缓存
- 第四节TypeScript 声明变量